.png)

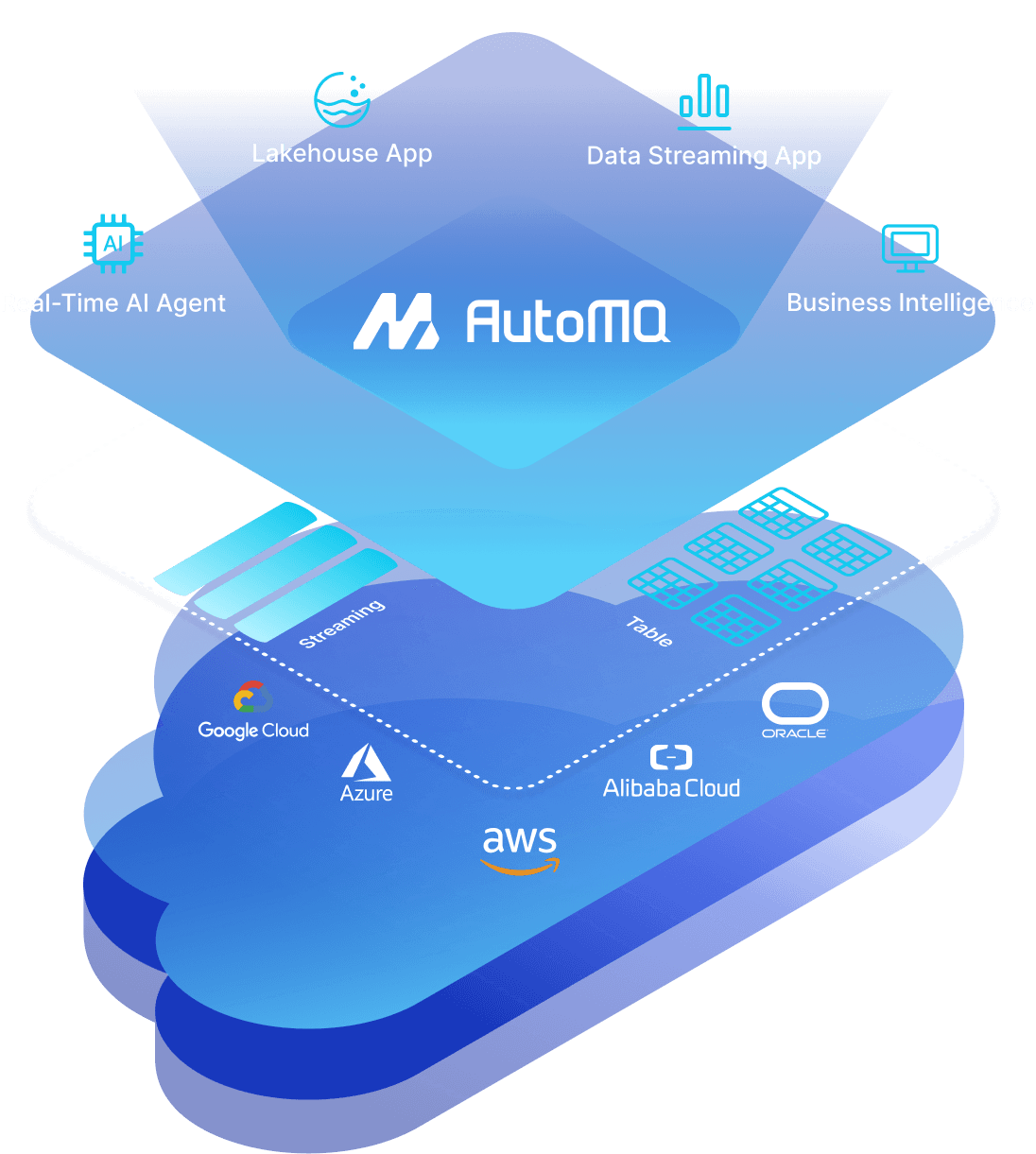
AutoMQ offers a comprehensive Kafka®-compatible streaming data platform, featuring built-in developer tools, a rapidly expanding connector ecosystem, seamless integration, effortless scalability, and robust security for any environment.







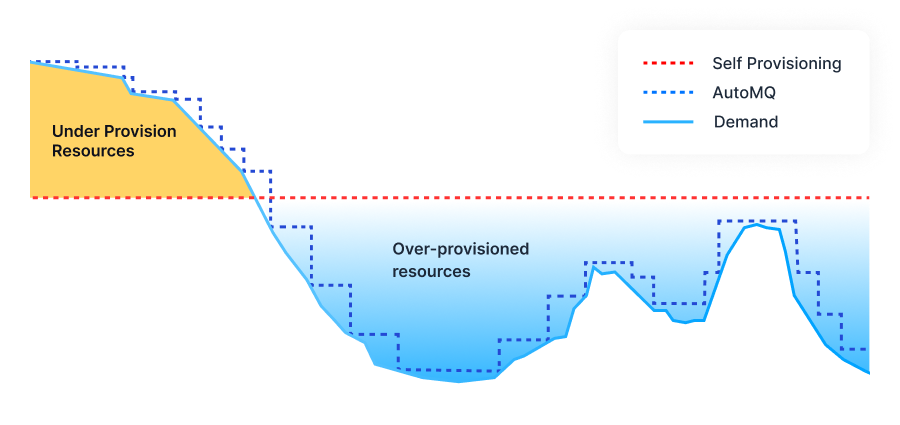
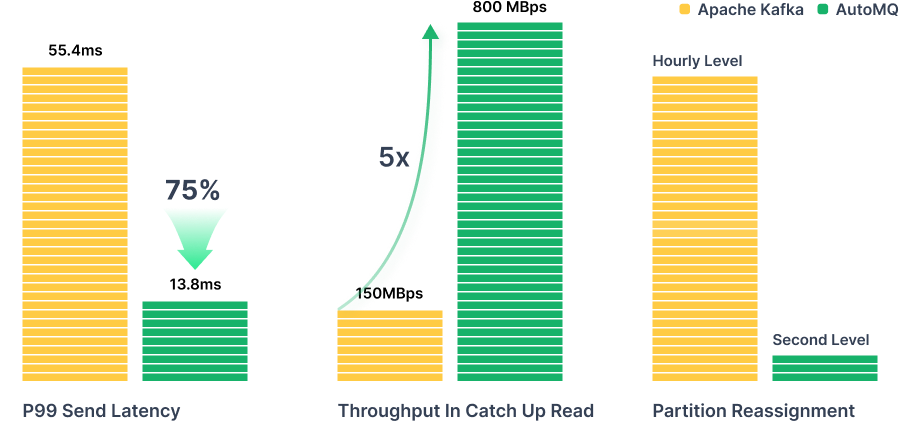
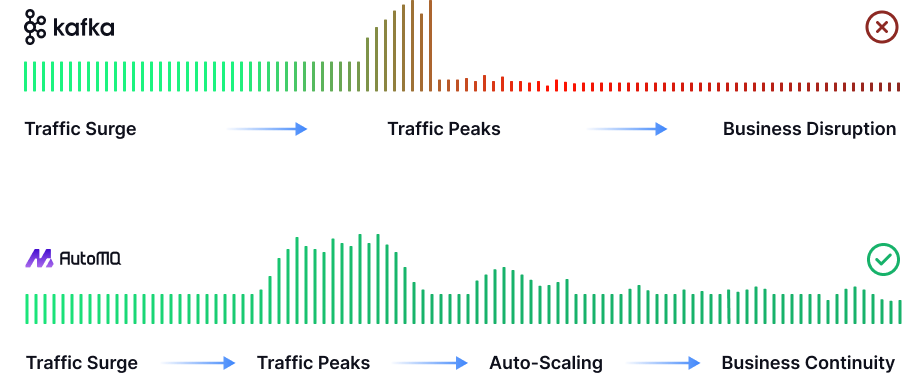

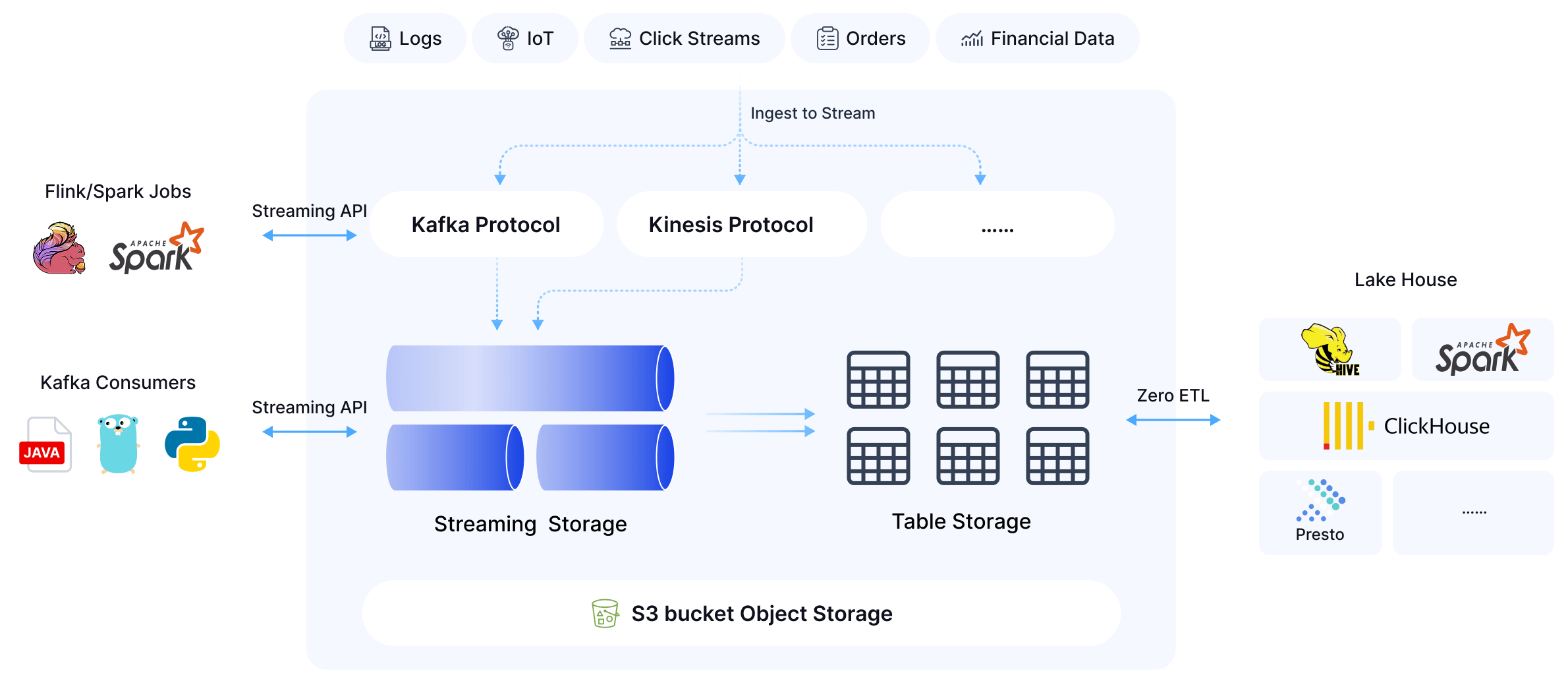
AutoMQ's shared storage architecture natively supports streaming data ingestion into data lakes, enabling real-time writing of Topic data into Iceberg tables. With built-in Schema Registry and Auto-Scaling capabilities, there's no need for traditional ETL tasks or manual schema management.