跳转到主要内容技术架构
Apache Kafka 诞生于 2011 年,面向传统的数据中心进行设计,以经典的 Shared Nothing 架构解决了横向扩展性问题,并逐渐演进至 Tiered Storage 架构以享受云存储带来的成本优势。到今天,AutoMQ 带来了一种更加纯粹的 Shared Storage 架构,能充分发挥出云原生的全部优势,相比较 Apache Kafka 有十倍的成本优势和百倍的运维效率提升。
Shared Nothing 架构
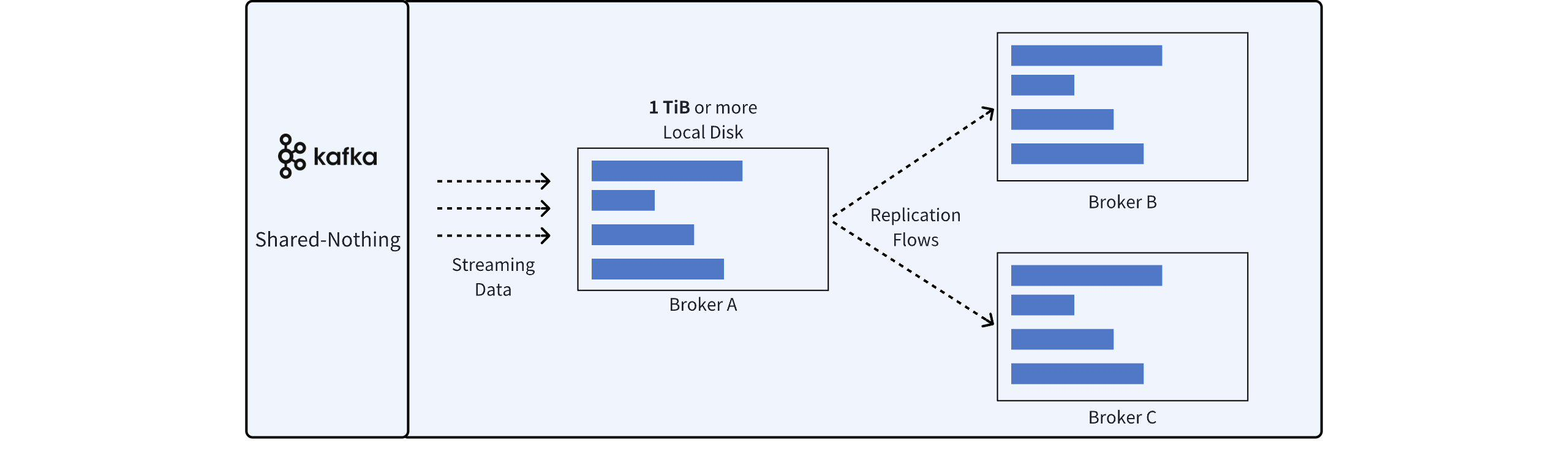 Shared Nothing 架构作为 Apache Kafka 最经典的架构,以存算一体的形式解决了传统数据中心环境下分布式存储软件的扩展性问题。Kafka 采用了一种基于 ISR[1] 的复制机制来提供数据的可靠性和系统的可用性。
随着云计算的逐渐成熟,催生了业务对弹性的需求,但经典的 Shared Nothing 架构无法满足这一诉求。Apache Kafka 的 Broker 节点在扩容时,需要复制大量的数据以完成分区的迁移,一般需要耗时数十个小时之久。
另一方面,Apache Kafka 需要进行三副本复制,用户在云上进行部署时,存储有两个选型:
Shared Nothing 架构作为 Apache Kafka 最经典的架构,以存算一体的形式解决了传统数据中心环境下分布式存储软件的扩展性问题。Kafka 采用了一种基于 ISR[1] 的复制机制来提供数据的可靠性和系统的可用性。
随着云计算的逐渐成熟,催生了业务对弹性的需求,但经典的 Shared Nothing 架构无法满足这一诉求。Apache Kafka 的 Broker 节点在扩容时,需要复制大量的数据以完成分区的迁移,一般需要耗时数十个小时之久。
另一方面,Apache Kafka 需要进行三副本复制,用户在云上进行部署时,存储有两个选型:
-
选择云存储 EBS 作为 Broker 的存储介质,但价格高昂。EBS 自带的三副本机制叠加 ISR 复制会导致数据被存储 9 份,有极大的存储空间浪费。
-
选择本地磁盘作为 Broker 的存储介质,成本相对可控,但用户需要付出高昂的运维成本,上云的优势不复存在。
Tiered Storage 架构
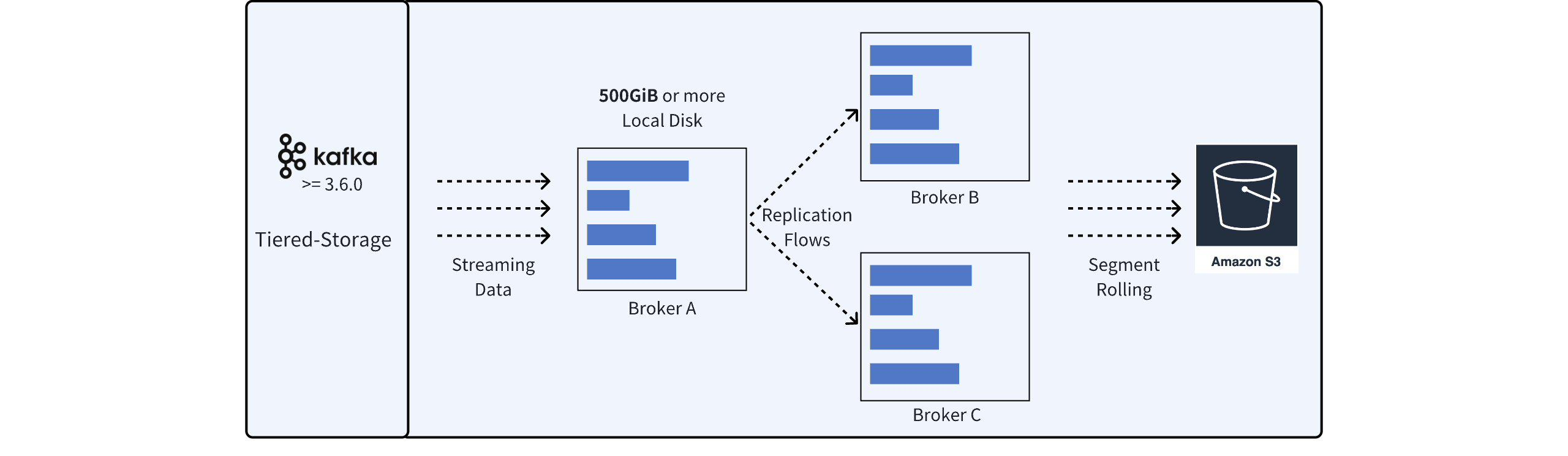 当云计算逐渐成熟,规模越来越大,最先受益的是对象存储。对象存储低廉的存储成本,按量付费的产品形态,催生了一大批存储软件演进至 Tiered Storage 架构。
顾名思义,该架构添加了一层二级存储,数据在存储到一级存储后,会异步地将数据转移至二级存储。该架构能够在一定程度上将对象存储的成本优势利用起来,同时,缓解 Shared Nothing 架构的弹性问题。
但 Tiered Storage 架构并没有从根本上解决 Apache Kafka 的问题,主要原因有几个方面:
当云计算逐渐成熟,规模越来越大,最先受益的是对象存储。对象存储低廉的存储成本,按量付费的产品形态,催生了一大批存储软件演进至 Tiered Storage 架构。
顾名思义,该架构添加了一层二级存储,数据在存储到一级存储后,会异步地将数据转移至二级存储。该架构能够在一定程度上将对象存储的成本优势利用起来,同时,缓解 Shared Nothing 架构的弹性问题。
但 Tiered Storage 架构并没有从根本上解决 Apache Kafka 的问题,主要原因有几个方面:
-
一级存储消耗的空间可以降低,但能降低多少因场景而异,还是需要进行严谨的容量评估,ISR 的复制带来的高昂的 EBS 成本也无法彻底解决。
-
无法快速扩缩容的问题依然存在,一级存储中的数据在扩容和缩容时都需要进行迁移复制,耗时可能从数十小时优化至了数小时。
简单来讲,Tiered Storage 架构中的一级存储相比较 Shared Nothing 架构并没有本质的变化,除了空间上有缩小外,文件系统上分区存储的布局以及 ISR 复制机制都没有发生变化。
Shared Storage 架构
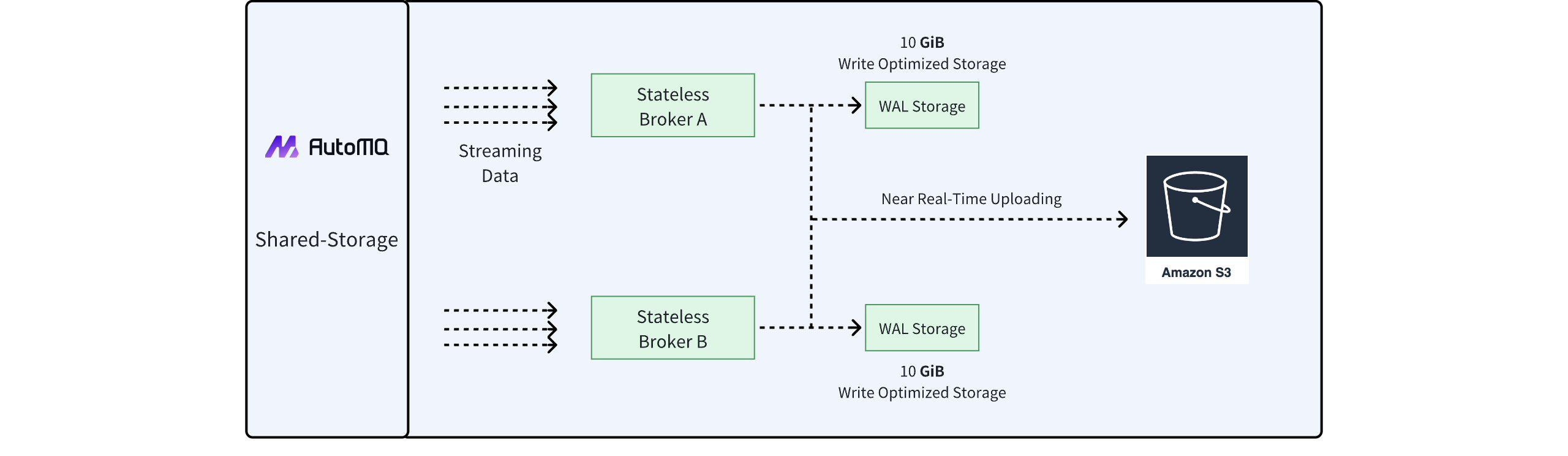 AutoMQ 推出的 Shared Storage 架构彻底替换了 Apache Kafka 的存储层,创新性地将数据卸载到云存储上后,将 Broker 变得无状态。AutoMQ 的共享存储架构由 WAL[2] 存储和对象存储构成,所有的数据会以近实时的方式存入到对象存储中,在该架构中:
AutoMQ 推出的 Shared Storage 架构彻底替换了 Apache Kafka 的存储层,创新性地将数据卸载到云存储上后,将 Broker 变得无状态。AutoMQ 的共享存储架构由 WAL[2] 存储和对象存储构成,所有的数据会以近实时的方式存入到对象存储中,在该架构中:
-
对象存储作为主要数据存储,提供弹性、按需付费、低成本的数据存储解决方案。
-
由于对象存储具有高延迟和低 IOPS 的特性,AutoMQ 引入了 WAL 存储层,提升数据写入效率并降低 IOPS 消耗。
-
WAL 存储在不同云厂商的平台上可以选择多种存储服务。可选方案包括具备多 AZ 容灾的 Regional EBS 服务,文件存储服务如 AWS EFS 和 FSx,甚至对象存储可同时用作 WAL 和数据主存。
AutoMQ 将上述存储模块封装为自研的流存储库——S3Stream, 然后将 Apache Kafka 原生的 Log 存储替换为 S3Stream,使得整个 Broker 节点变得完全无状态,从而非常易于实现秒级分区迁移,自动扩缩容,流量持续重平衡等特性。为此,AutoMQ 在内核中内置了一些 Controller 组件,比如 Auto Scaling 和 Auto Balancing 组件,分别负责集群的扩缩容以及流量的重平衡。
值得注意的是,对于 AutoMQ 开源版,仅支持采用 S3 兼容的存储服务作为 WAL 存储选项,也意味着 AutoMQ 开源版是一个仅依赖对象存储的云原生 Kafka 实现,拥有极简的部署架构。对于 AutoMQ 的商业版,在不同的云厂商上提供不同的 WAL 选型,以支持更多的工作负载。
[1]. Kafka ISR 复制机制:https://kafka.apache.org/documentation/#replication
[2]. WAL Wiki:https://en.wikipedia.org/wiki/Write-ahead_logging