架构区别
参考 KIP-405 的设计,Apache Kafka 分级存储版本采用了两级存储的思路,存储模块依赖本地磁盘以及对象存储。消息数据首先写入本地磁盘,再通过转冷的策略异步上传到对象存储。由于本地磁盘介质存在损坏风险,因此根据副本策略,每一份消息需要经过 ISR 机制跨节点复制到多个磁盘上。 如今,在公共云环境部署分级存储版本,Apache Kafka 的架构并未改变,仍旧使用 EBS 作为本地磁盘的替代,消息仍旧需要复制到多份 EBS 上。总结而言,Apache Kafka 仍旧将 EBS 视作普通的块设备存储介质 ,跟本地机房的一块物理硬盘没有本质的区别。 AutoMQ 采用了对象存储作为主要存储方式,无存储分级概念。然而,为优化存储效率,如减少写入对象存储的延迟、提升海量分区的写入效率,AutoMQ 引入了 WAL 存储机制。具体架构对比如下: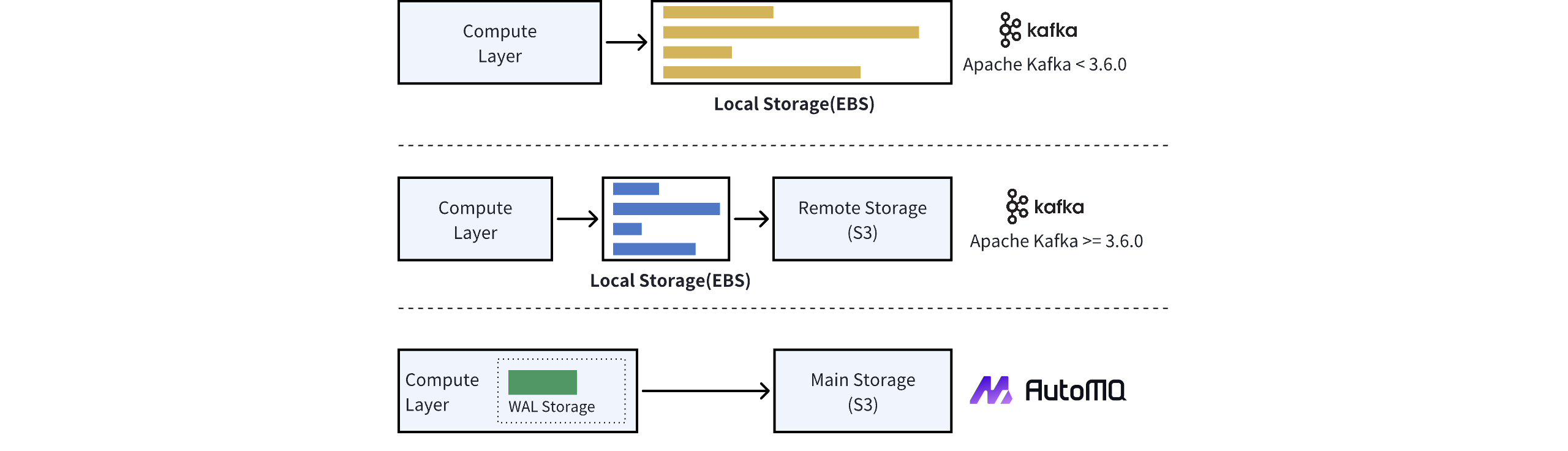
| - | WAL 存储 | Kafka Tier 1 Storage |
|---|---|---|
| 职责 | 类似数据库的 Binlog,用于快速的数据持久化写入和故障时数据恢复(Recovery)。 | 核心的数据存储,提供读、写和回放等职责。 |
| 存储效率 | 集中式存储,将节点所有分区的数据混合存储在一个 WAL 文件或对象中,提供高写入效率和低 IOPS 消耗。 | 分散式存储,系统采用独立的文件列表来存储各分区数据,导致写入效率低且 IOPS 消耗高。 |
| 存储空间 | 占用空间较少,如 10GiB,且具备确定性。 | 占用空间大且不确定,需要进行容量评估,单节点通常需要数百 GiB。 |
| 存储介质 | 根据延迟等级和持久性需求,可选择云厂商提供的块存储、对象存储或文件存储。 | 通常建议选择本地硬盘或云供应商提供的块存储服务。 |
| 持久性保证 | 利用云存储服务中的多副本或 EC(Erasure Coding)技术,数据持久性通常可达到 99.999% 至 99.999999999% 的可靠性。 | Apache Kafka 的 ISR 副本机制提供可靠性,但不保证持久性指标。 |
| 多 AZ 容灾 | 云厂商提供的 Regional EBS、对象存储和文件存储(如 AWS EFS 和 FSx)均具备多可用区(AZ)数据持久性,并且免除跨 AZ 复制流量费用。 | 使用 ISR 实现跨可用区 (AZ) 数据复制,并将产生跨 AZ 流量复制费用。 |
成本优势
Apache Kafka 分级存储版本架构中仍旧将第一级 EBS 存储作为主存储对外提供读写服务,每个 Kafka 分区至少需要在第一级存储上保留最后一个活跃的 Segment 。这会导致如下现象:- EBS 空间不确定,和集群分区数正相关。
- 生产环境需要预留较大的 EBS 空间,降低风险。
- EBS 预留成本高,分级存储降本空间有限。
举例:以 Apache Kafka 默认配置为例,每个 segment 大小默认为 1GB,如果活跃的分区数为 1000 个,则仍然需要预留 1TB 的 EBS。
运维优势
由于 Apache Kafka 多级存储架构中的一级存储空间不固定,每个分区遗留在 EBS 上的数据也不固定,所以在弹性伸缩、故障迁移等需要分区移动时,耗时也不确定,无法快速伸缩。 而 AutoMQ 的缓冲区里仅有不超过 500MB 的数据是在需要上传到对象存储中的,可以做到秒级完成上传,进而能支持秒级的分区转移。以 Confluent 的案例来看,在一个大流量集群,扩容操作在非多级存储架构需要耗时 43 小时,在多级存储架构仍然需要耗时 1.4 小时。