Why Migrate with AutoMQ?
Experience the only migration tool designed for zero downtime and absolute data consistency.
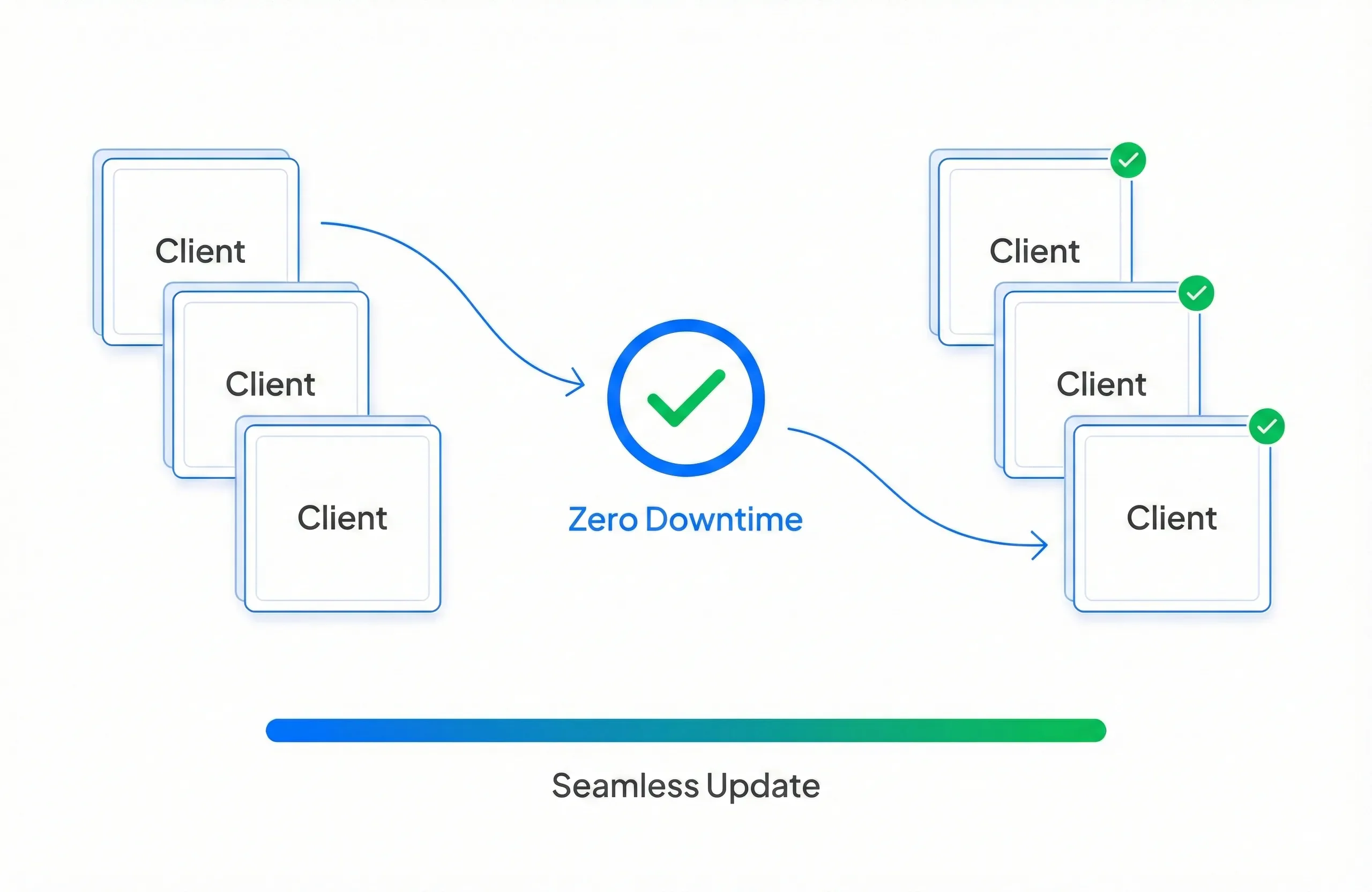
Zero Downtime Migration
With AutoMQ
Perform a standard rolling update. Update your cluster client-by-client, one-by-one. Traffic shifts seamlessly with zero service interruption.
The Alternative
Competitors like MirrorMaker require a "Stop the World" cutover, forcing you to halt production traffic and endure unpredictable downtime windows.
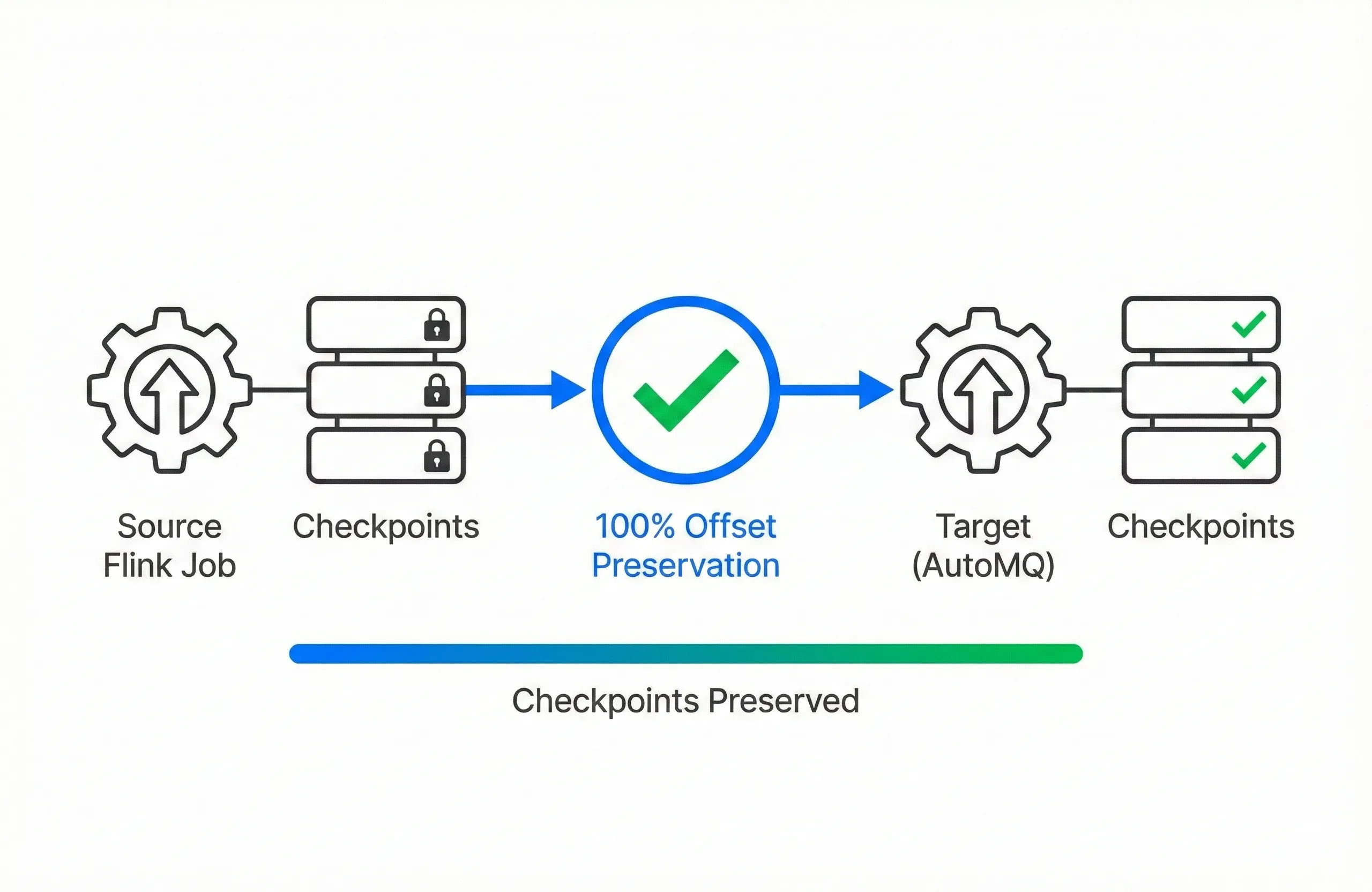
100% Flink State Retention
With AutoMQ
Our engine ensures bit-for-bit offset preservation. Your Flink jobs and stateful applications migrate instantly and resume from their last checkpoint.
The Alternative
Other tools break offset mapping, forcing you to discard Flink state, rewind consumer groups, and re-process terabytes of historical data.
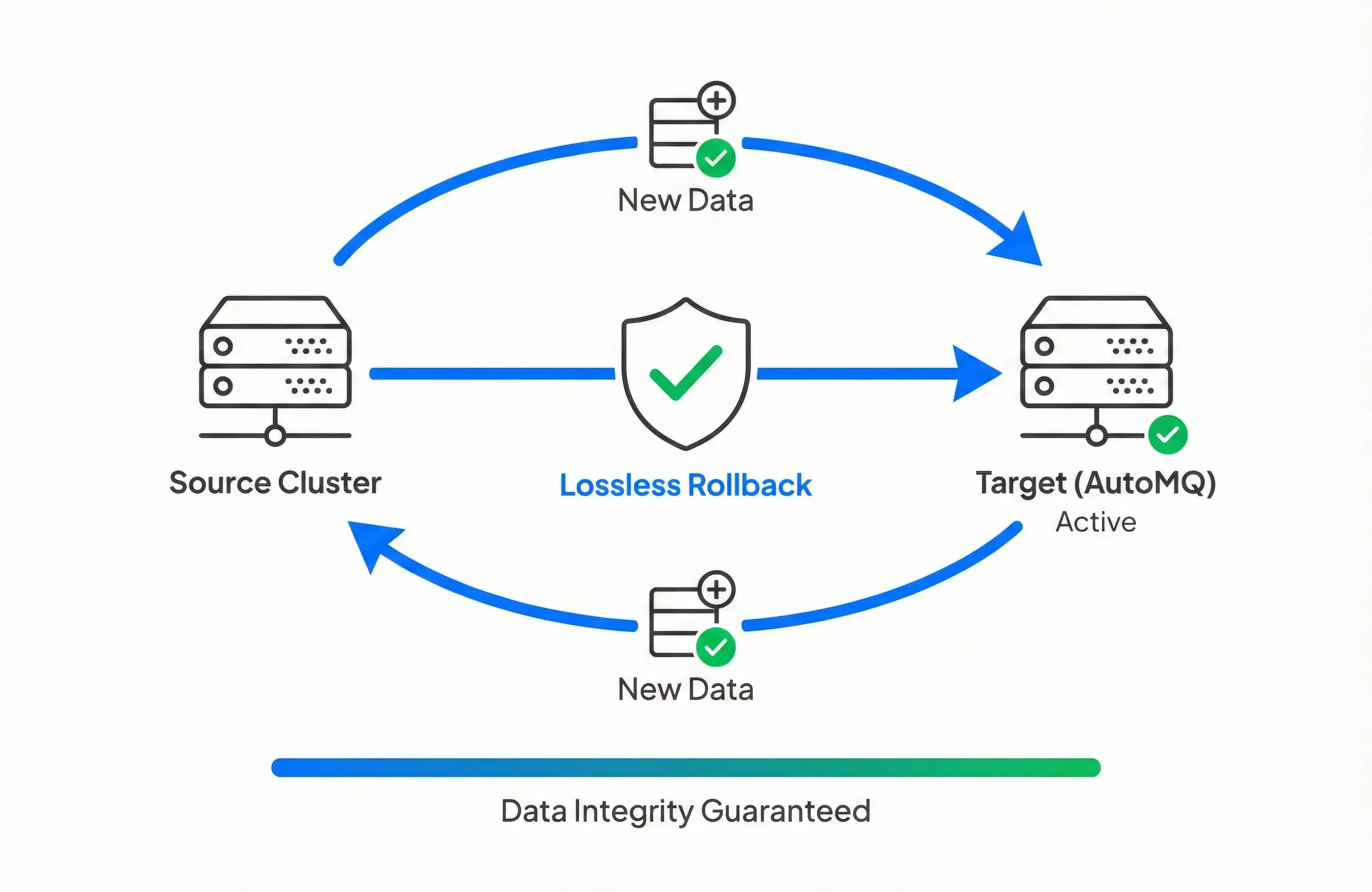
Lossless Rollback Safety
With AutoMQ
Change your mind at any stage. You can rollback to the source cluster instantly without losing new data generated during the cutover.
The Alternative
Standard tools reach a "point of no return". Rolling back often means losing data written to the new cluster or facing a messy manual reconciliation.
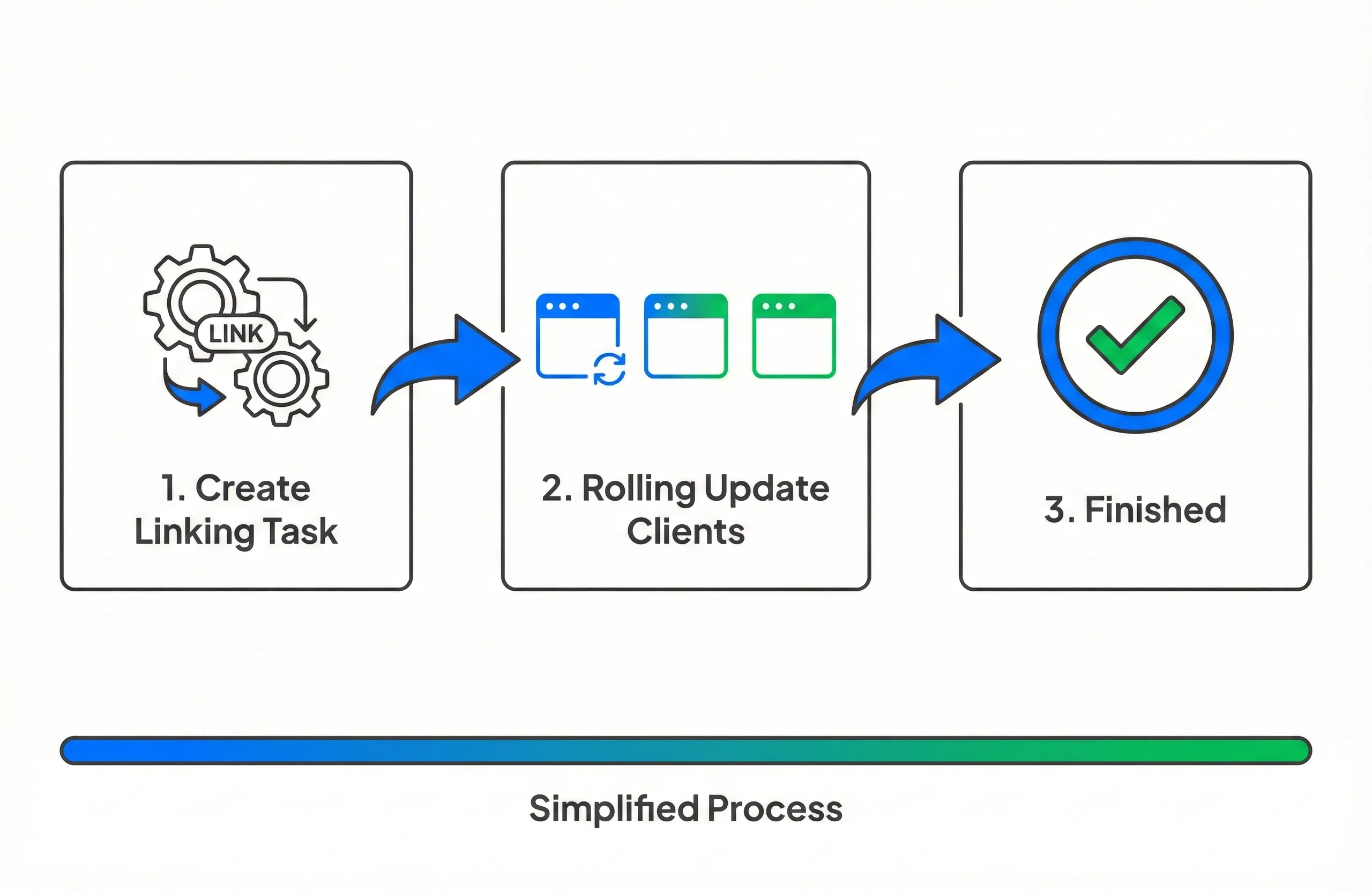
Zero Operational Complexity
With AutoMQ
Treat migration like a routine deployment. No complex replication setups or manual update/commit steps—just a rolling update.
The Alternative
Traditional migration tools demand high-risk manual operations, requiring strict coordination between infrastructure and application teams to avoid data gaps.
Finally, a Migration Solution That Checks Every Box
| Feature | Standard MirrorMaker 2 | Other Commercial Solutions (e.g., Confluent) | AutoMQ Linking for Kafka |
|---|---|---|---|
| Zero Downtime Cutover | |||
| 100% Flink State Retention | |||
| Lossless Rollback Safety | |||
| Zero Operational Complexity |
Under the Hood: The Architecture of AutoMQ Linking
Endpoint Configuration
Cluster
Endpoint Configuration
Cluster
Endpoint Configuration
Endpoint Configuration
Built-in Intelligence for Seamless Migration
AutoMQ Linking is a built-in capability, not an external tool. It automates complex synchronization and client coordination internally to guarantee strict consistency and safety.
Byte-Level Replication
Replicate the raw byte stream, ensuring strict 1:1 offset consistency. Your Flink checkpoints and application states remain valid.
Smart Write Forwarding
Writes are temporarily proxied back to the source during migration, enabling lossless rollbacks.
Consumer Coordination
Our coordinator ensures Exactly-Once semantics throughout the rolling update.
Granular Migration Control
Define tasks at the Topic + Consumer Group level. Migrate at your own pace.
Questions About the Architecture?
Our engineers can walk you through the technical details.
Talk to an EngineerEndpoint Configuration
Cluster
Endpoint Configuration
Cluster
Endpoint Configuration
Endpoint Configuration
Questions About the Architecture?
Want to understand how we achieve zero downtime and preserve Flink state? Our engineers can walk you through the technical details.
Built-in Intelligence for Seamless Migration
AutoMQ Linking is a built-in capability, not an external tool. It automates complex synchronization and client coordination internally to guarantee strict consistency and safety.
Byte-Level Replication
Replicate the raw byte stream, ensuring strict 1:1 offset consistency. Because the target offsets are identical to the source, your Flink checkpoints and application states remain valid—zero data re-processing required.
Smart Write Forwarding
To preserve ordering, writes to the new cluster are temporarily proxied back to the source during migration. This ensures new data lands on the source first, enabling lossless rollbacks if you revert without losing a single message.
Consumer Coordination
To prevent duplication, our coordinator blocks the new consumer's fetch requests until it confirms the old client has disconnected. This "handshake" ensures Exactly-Once semantics throughout the rolling update.
Granular Migration Control
Migration is not "all-or-nothing." You can define tasks at the Topic + Consumer Group level. Move non-critical workloads first to verify stability, then migrate core business lines at your own pace.
Currently in production at




















One-Click Kafka Migration
Experience how easy it is to migrate your Kafka workloads to AutoMQ with zero downtime. Watch the interactive demo below to see the migration process in action.
Loading Interactive Demo...
This may take a moment depending on your network connection
Get Started with AutoMQ Today
Start your 30-day free trial. No credit card required
Available on Cloud Marketplaces
Subscribe to AutoMQ directly from your preferred cloud platform



