
Author: JD.com R&D Engineer, Zhong Hou
About JD.com
JD.com (also known as JD Mall) is a leading e-commerce company. Its business has expanded into retail, technology, logistics, health, insurance, real estate development, industry, private brands, and international business. JD.com is ranked 52nd in the Fortune Global 500 and is the largest retailer in China by revenue. Serving nearly 600 million customers, JD.com has set the standard for e-commerce through its commitment to quality, authenticity, and competitive pricing. JD.com operates the largest fulfillment infrastructure of any e-commerce company in China, enabling 90% of retail orders to be delivered within the same or next day. Additionally, JD.com drives productivity and innovation by providing its cutting-edge technology and infrastructure to partners, brands, and various industries.
Introduction to the JDQ Platform
JD internally utilizes JDQ, which is built on Apache Kafka, to support its platform business. JDQ is the unified real-time data bus for JD Group's big data platform, enabling over 40 primary departments within the company, including JD Retail, Logistics, Technology, Health, and Allianz, to support more than 1400 business lines such as search recommendations, advertising, clickstreams, and real-time large screens. Currently, the JDQ platform consists of over 6000 nodes, generating up to 15 trillion records daily, with a peak outbound bandwidth reaching 1TB/s.

The JDQ platform uses Kubernetes for stateful service orchestration and the StatefulSet controller to manage the entire cluster. It supports various storage schemes and service access methods. The platform can be deployed on Private Cloud, Public Cloud, and JD's internal Kubernetes platform. As the company's overall technical architecture evolves towards Kubernetes-based cloud-native architecture, JDQ faces new challenges in efficiency, cost, and elasticity on Kubernetes.
CubeFS Overview
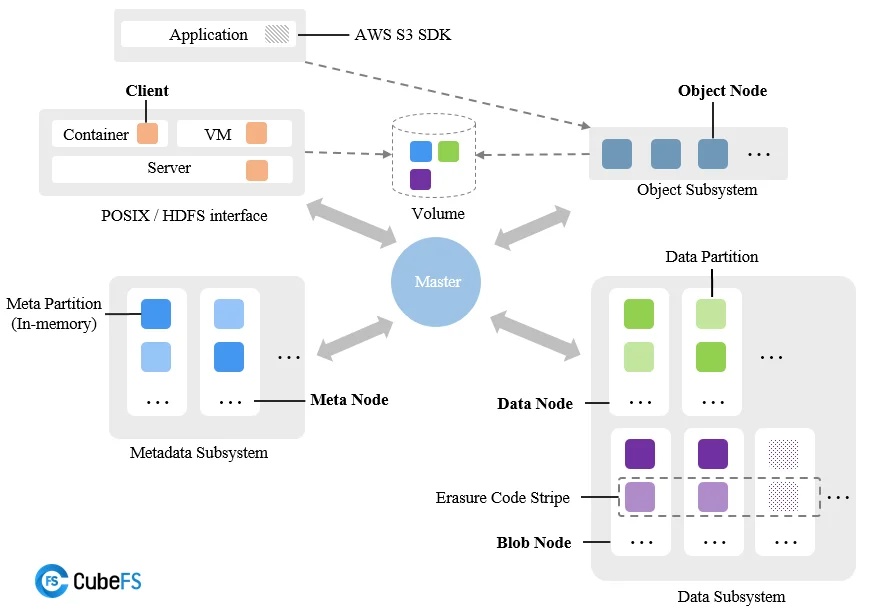
CubeFS is a next-generation cloud-native open-source storage system, originating from JD.com's internally developed ChubaoFS and donated to the Cloud Native Computing Foundation (CNCF). It supports various access protocols such as S3, HDFS, and POSIX. CubeFS is widely applicable in numerous scenarios, including big data, AI/LLMs, container platforms, storage and computing separation for databases and middleware, data sharing, and data protection.
CubeFS is composed of the Metadata Subsystem, Data Subsystem, Master (resource management node), and Object Subsystem, providing storage data access via POSIX/HDFS/S3 interfaces.
Challenges Brought by JD's Large-Scale Usage of Kafka
Wasting storage and network bandwidth leads to increased costs
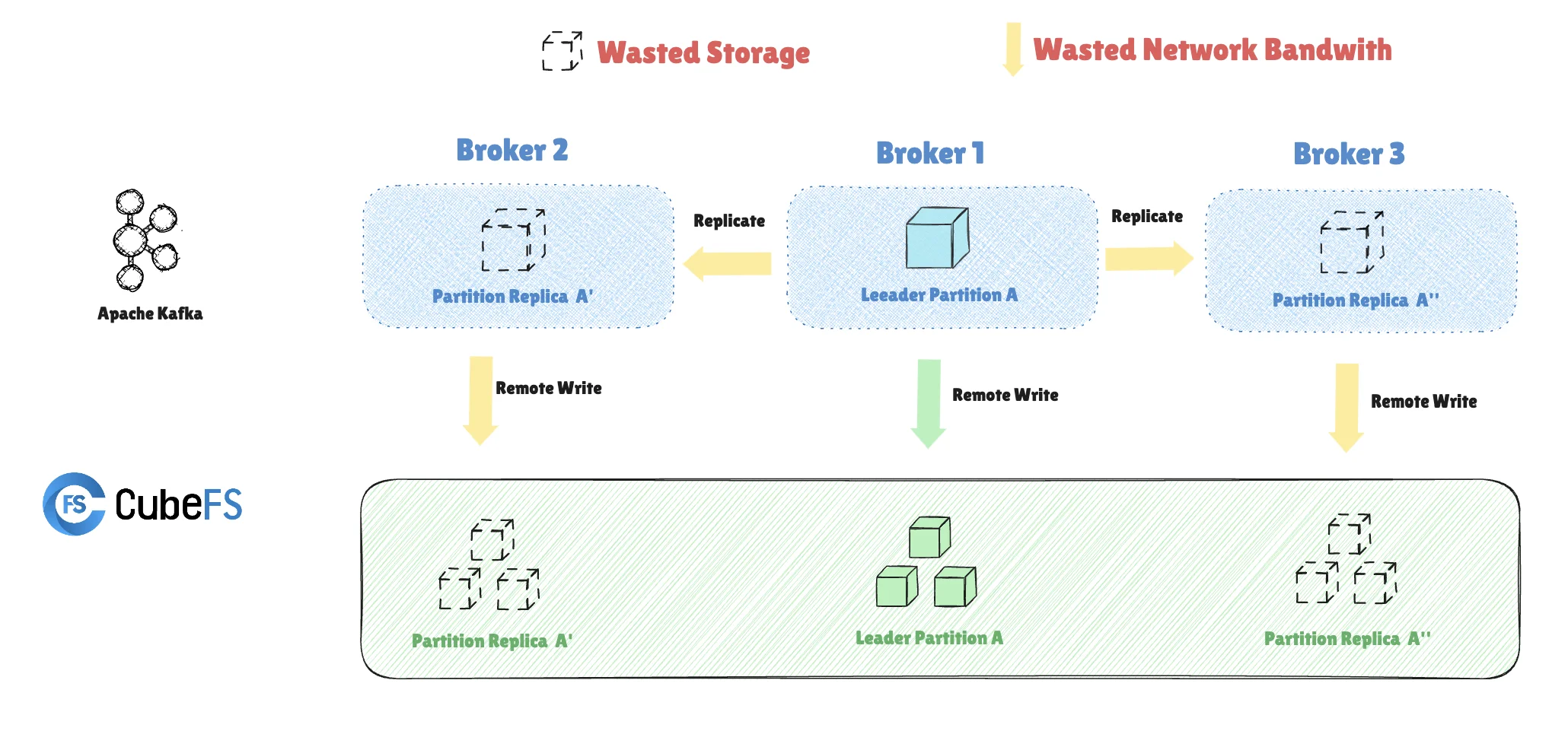
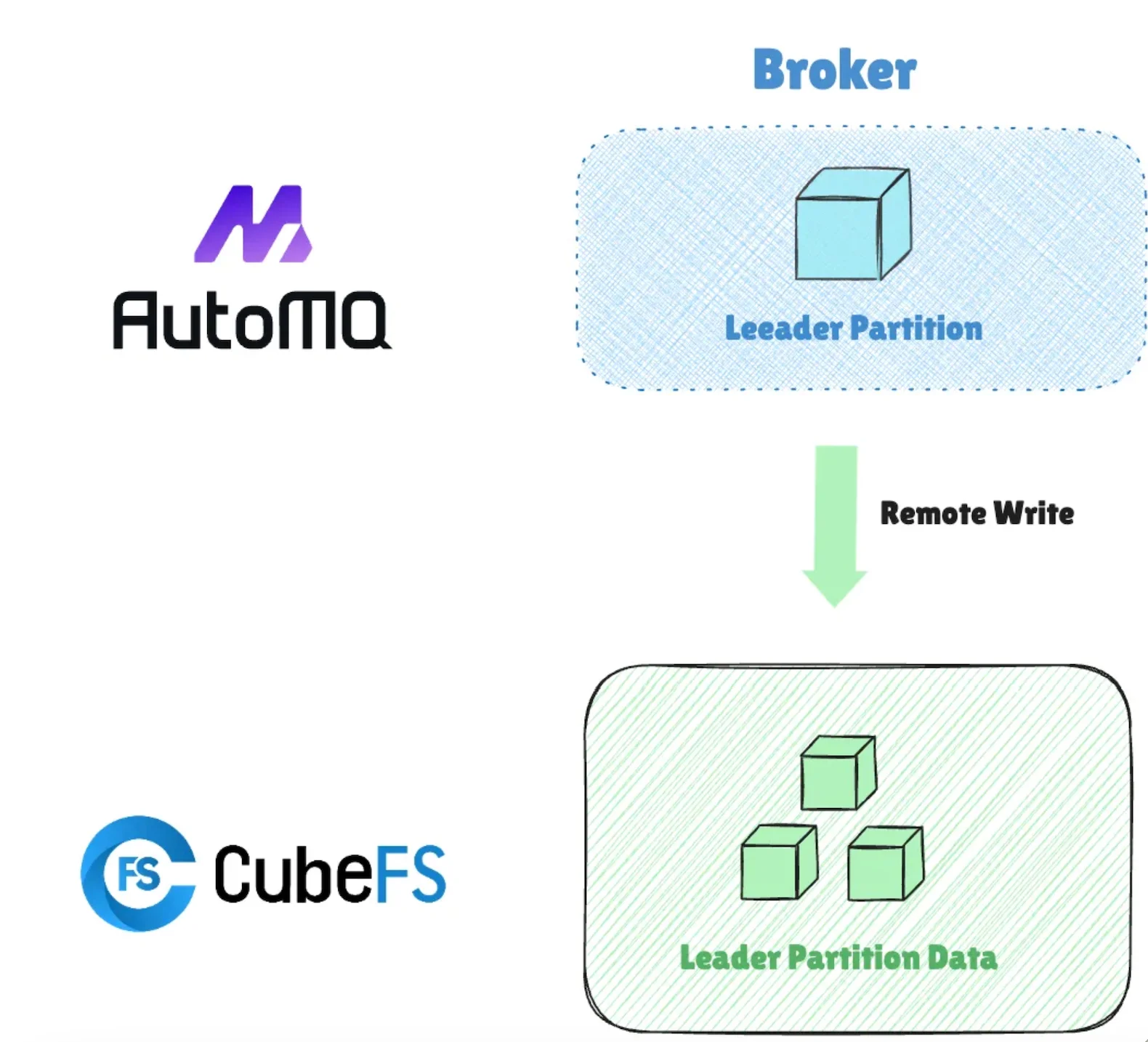
JDQ's underlying storage solution uses CubeFS object storage, which is compatible with the S3 protocol. CubeFS ensures data durability through a multi-replica mechanism, similar to how Kafka employs the ISR (In-Sync Replicas) mechanism to achieve the same goal. Apache Kafka, designed over a decade ago, features an architecture tailored for physical machine deployments in data centers (IDC). Kafka stores data on local disks and leverages the ISR mechanism to ensure data persistence. While this design was appropriate at the time, the advent of the cloud computing era has seen a rise in shared storage architectures based on object storage services like S3. Consequently, Kafka’s traditional architecture has shown limitations in this new context.
For instance, when Kafka is deployed directly on CubeFS at JD.com, a significant amount of data redundancy is introduced. A single piece of data written to Kafka is replicated by the ISR mechanism. Once stored on CubeFS, considering CubeFS’s internal multi-replica mechanism, the data ends up being stored nine times, with approximately 66.67% (6 out of 9) of the storage space occupied by unnecessary redundancy, leading to severe resource wastage. Moreover, Kafka’s replica duplication and remote writes to CubeFS consume additional network bandwidth. This results in excessive use of storage and network bandwidth resources under the current architecture, ultimately driving up the overall costs. The diagram below illustrates how redundant data is generated when Kafka is deployed on CubeFS, with dashed lines indicating redundant data replicas.
Apache Kafka architecture is not inherently cloud-native on Kubernetes
Kubernetes offers numerous benefits to enterprises, notably enhancing hardware resource utilization and reducing costs through containerization and Pod abstraction. In the context of widespread Kubernetes adoption, core infrastructure software like Apache Kafka also needs to be deployed on Kubernetes to fully leverage its resource optimization advantages. Internally, JD.com has migrated 50% of its physical node Kafka clusters to Kubernetes. Throughout this process, we have gained deep insights into the challenges of running Kafka's architecture on Kubernetes.
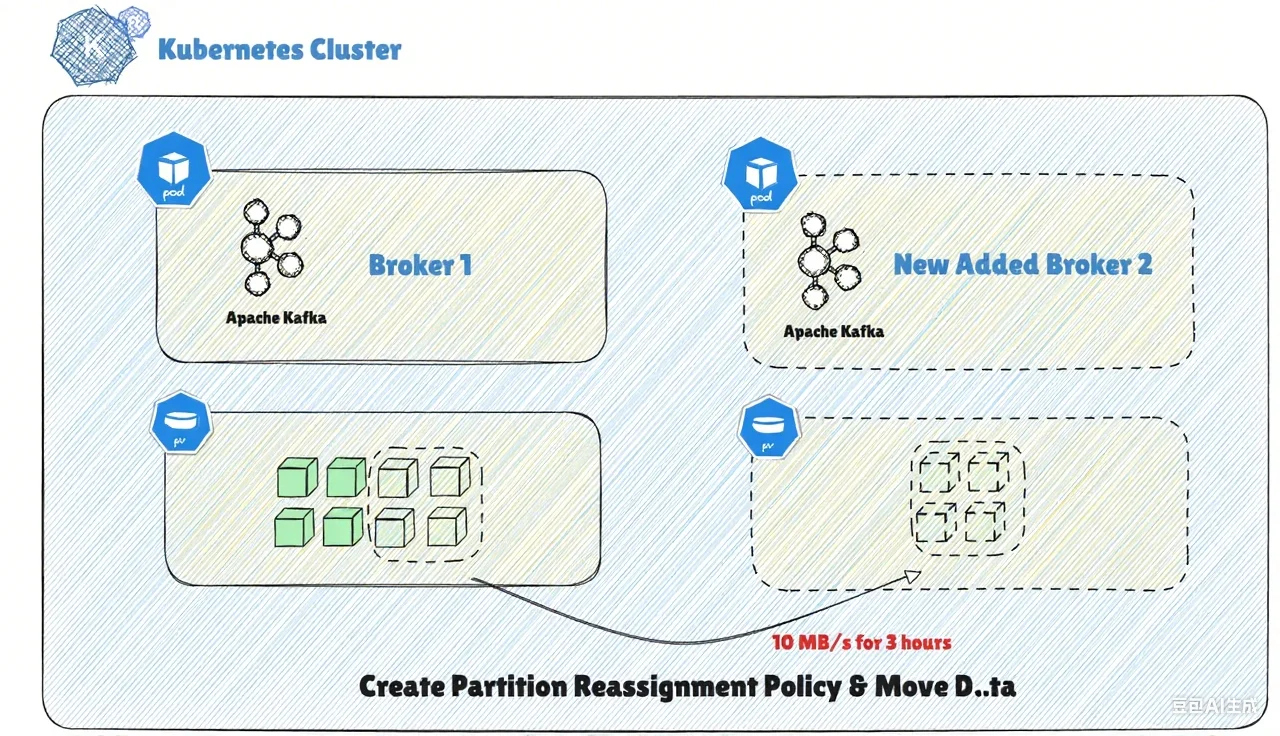
Apache Kafka employs a Shared-Nothing architecture that tightly couples its computing nodes (Brokers) with local storage, posing significant obstacles for flexible scaling on Kubernetes. For instance, during a scale-out, Apache Kafka must undergo the following steps:
-
Carefully develop a partition reassignment strategy to ensure overall traffic remains balanced across all Brokers.
-
Evaluate the impact of the reassignment, plan contingency measures, and notify Kafka upstream and downstream applications in advance.
-
Perform capacity expansion and partition data reassignment during off-peak business hours (the process may take from several minutes to several hours depending on the data volume).
-
After the partition reassignment is complete, check the cluster status to ensure traffic remains balanced across Brokers.
Due to Kafka's architecture not aligning with Kubernetes native design principles, its scaling operations on Kubernetes become high-risk operations requiring manual intervention. Under these constraints, Apache Kafka can only be deployed as static resources bound to Pods. Kubernetes cannot automatically scale nodes and schedule Pods based on cluster resource utilization, thus failing to leverage its advantages.
How AutoMQ Addresses JD's Kafka Challenges
During the research process to find a solution for JD's internal Kafka challenges, we discovered the remarkable product AutoMQ[1]. AutoMQ employs a shared storage architecture that separates computation and storage. While ensuring full compatibility with Apache Kafka®, it allows data to be stored in object storage compatible with the S3 protocol, significantly reducing costs and improving efficiency.
Specifically, AutoMQ addresses the main challenges in JD's cloud-native transformation process through technological innovations:
-
S3 API Protocol Adaptation with CubeFS: AutoMQ conforms to the standard S3 API protocol, making it adaptable to standard cloud object storage services. It also supports MinIO, Ceph, and CubeFS, which are S3 API-compatible object storage mediums. This enables AutoMQ to naturally integrate with JD's internal CubeFS service.
-
100% Full Compatibility with Kafka, Eases Reassignment: Given JD's extensive Kafka clusters and surrounding infrastructure, AutoMQ's complete compatibility ensures that existing services can be reassigned seamlessly without any code modifications or configuration changes. This allows full utilization of the existing Kafka ecosystem.
-
Data Offloading to Cloud Storage, Significantly Reducing Storage and Bandwidth Resources: AutoMQ's shared storage architecture is built on WAL and object storage, achieving a complete separation of compute and storage. Unlike Apache Kafka®'s ISR multi-replica mechanism, AutoMQ delegates data durability directly to object storage services like S3/CubeFS. This design results in only three replicas of data written to the Broker at the CubeFS level, significantly reducing storage resource consumption. With a single Leader Partition design, AutoMQ also saves the network bandwidth cost incurred by traditional Kafka Replica writing to remote CubeFS.
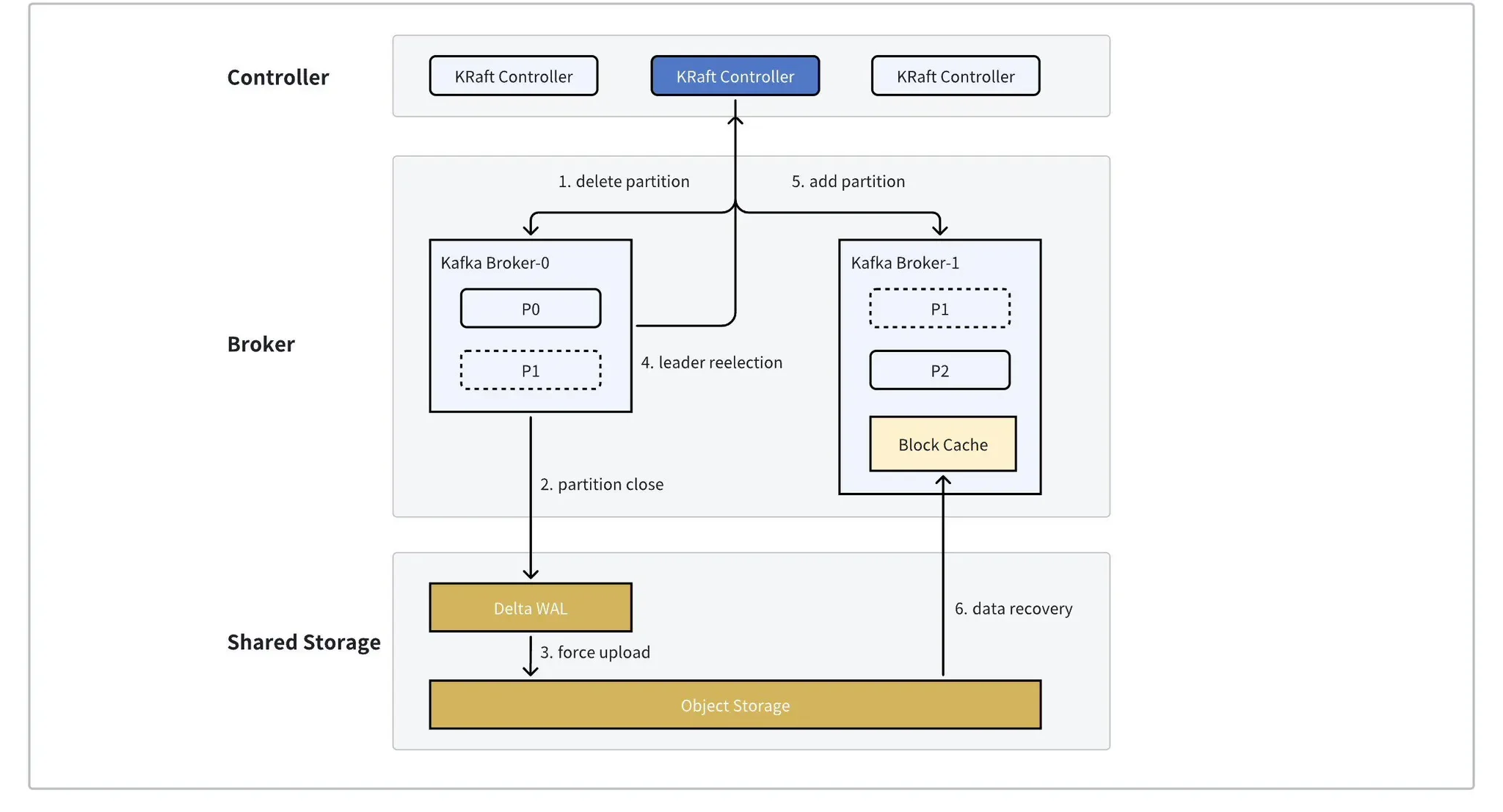
- Extreme Elasticity and Auto-balancing: The AutoMQ architecture allows for scaling without the need for data reassignment as required by Kafka. Reassigning partitions involves merely updating metadata, which can be completed in around 1 second. The built-in Self-Balancing component continuously monitors the cluster state, performing seamless partition reassignment and scheduling to ensure a balanced traffic and QPS distribution. This elasticity allows AutoMQ to work perfectly with Kubernetes tools like Autoscaler and Karpenter, enabling automatic cluster scaling based on load and fully leveraging Kubernetes' potential.
Optimized Practice of AutoMQ Based on CubeFS at JD.com
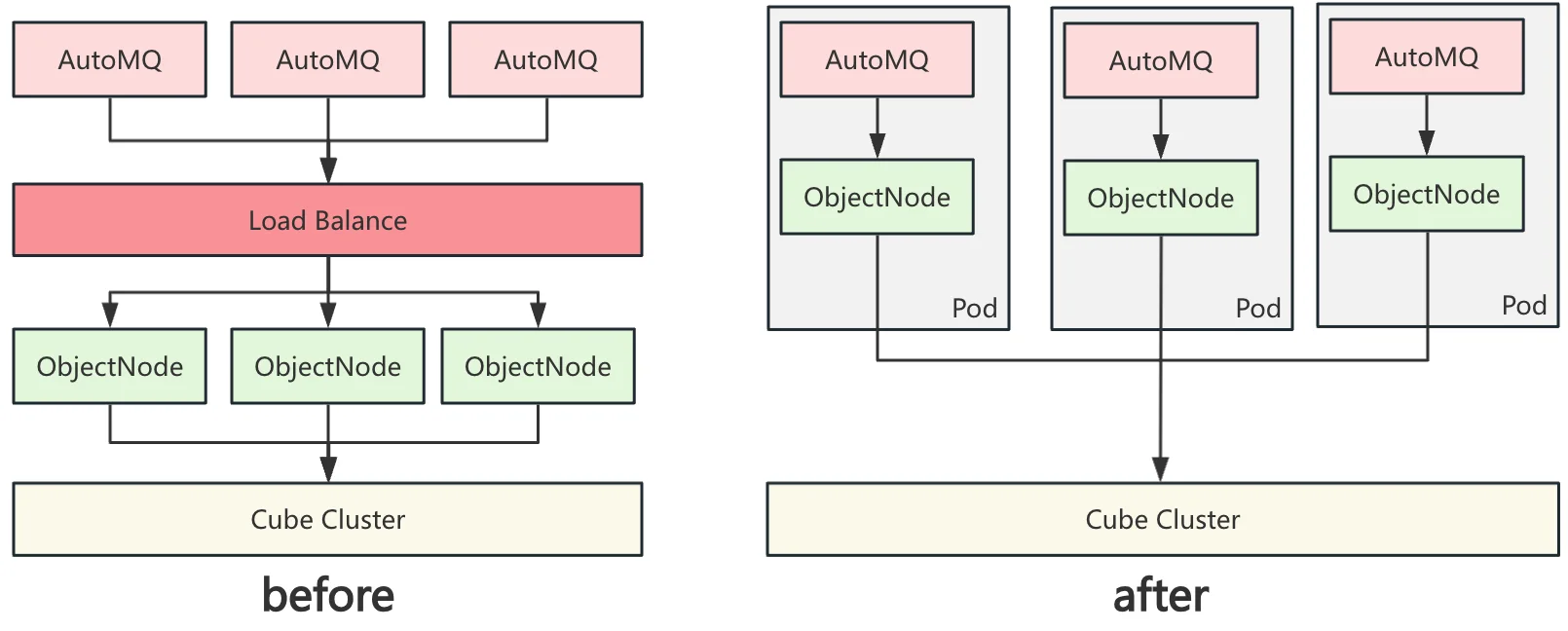
- CubeFS Object Node Service Deployment: CubeFS supports S3 protocol requests through its Object Node service, which interfaces externally. S3 protocol clients send requests to the Object Node service and receive responses without the S3 SDK communicating directly with CubeFS backend Meta Node and Data Node. JD.com's CubeFS Object Node service provides domain access uniformly through Load Balance. Running all Kafka traffic requests through Load Balance required thousands of machines, imposing unacceptable costs. JD.com optimized this by deploying the Object Node service and AutoMQ service in the same Pod. With both services in the same network namespace, AutoMQ gains direct localhost access, bypassing Load Balance and saving associated costs.
-
Optimization of Excessive Files in a Single Directory of CubeFS : CubeFS supports both S3 and Posix protocol access. Writing large amounts of data into CubeFS using AutoMQ through the S3 protocol can generate many subdirectories and files under a single directory. To maintain Posix protocol compatibility, this exerts considerable pressure on CubeFS backend cluster’s metadata management. Additionally, using the KEEP_DATA strategy during compaction to delete metadata in kraft, underlying object files remain, leading to an abundance of subdirectories. After optimizing the MINOR_V1 parameter, JD.com enabled physical merging during compaction, reducing the number of object files stored in CubeFS by 90%, thereby easing the burden on CubeFS backend cluster’s metadata management.
-
CubeFS Empty Directory Optimization: When CubeFS creates an object file, it converts the file prefix into a directory. Similarly, when AutoMQ creates a primary data storage object file, it also creates a prefix directory on the CubeFS cluster. However, after the object file is deleted, the corresponding prefix directory may not be removed, resulting in many uncleared empty directories on CubeFS. By optimizing the Object Node to mark the metadata of prefix directories, the corresponding prefix directories can be cascade deleted, thereby eliminating the issue of empty directories generated by AutoMQ based on CubeFS.
-
CubeFS S3 Request Interface Compatibility Expansion : Currently, CubeFS is compatible with read and write requests following the S3 protocol. However, certain S3 SDK interfaces are not yet supported, such as the S3 UploadPartCopy interface used by AutoMQ for multipart objects larger than 32MB. In the future, JD.com plans to add support based on business needs.
Effectiveness of AutoMQ in JD.com's Production Environment
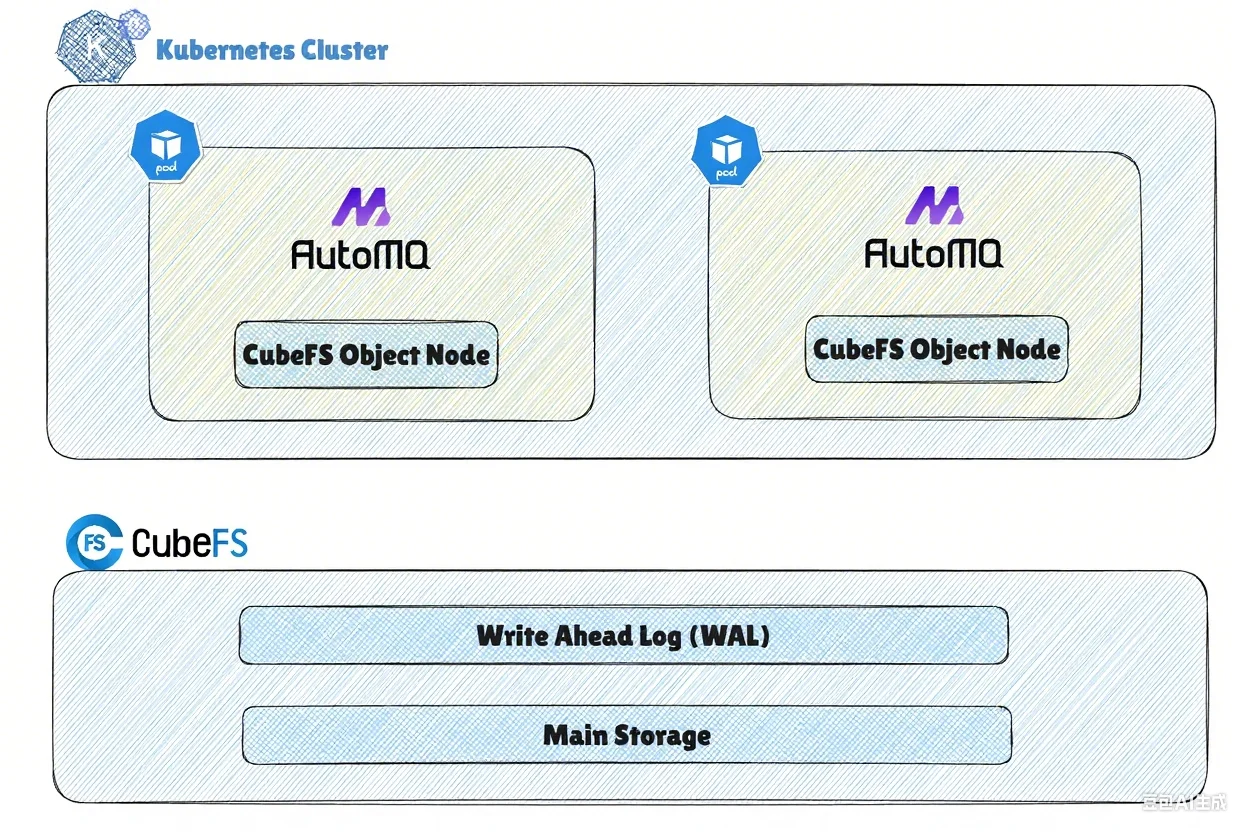
Currently, JD.com adopts the AutoMQ S3 WAL [2] model. In the architectural design of AutoMQ, WAL has been highly abstracted, allowing different storage media to be used as WAL. In JD.com's scenario, CubeFS itself is used as the WAL, eliminating the reliance on local storage, resulting in a highly simplified and efficient architecture.
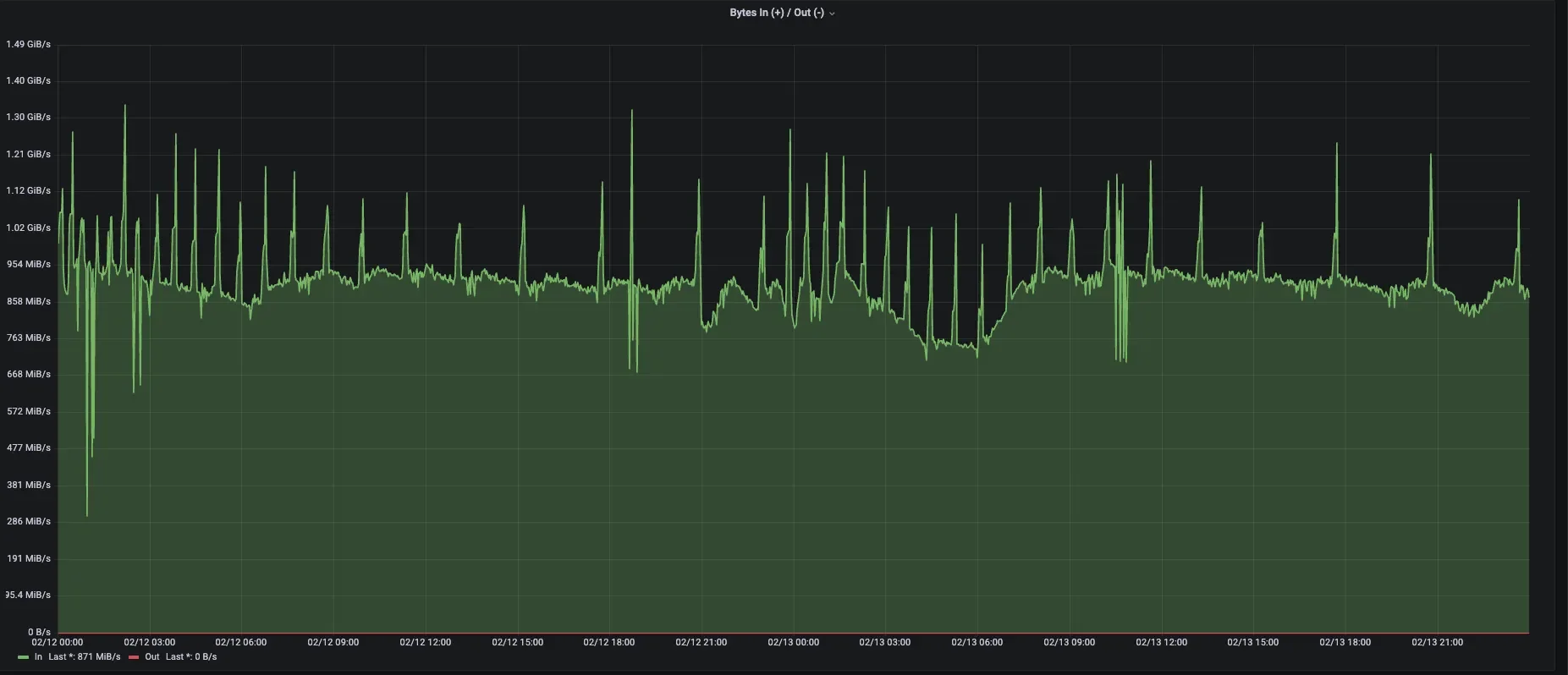
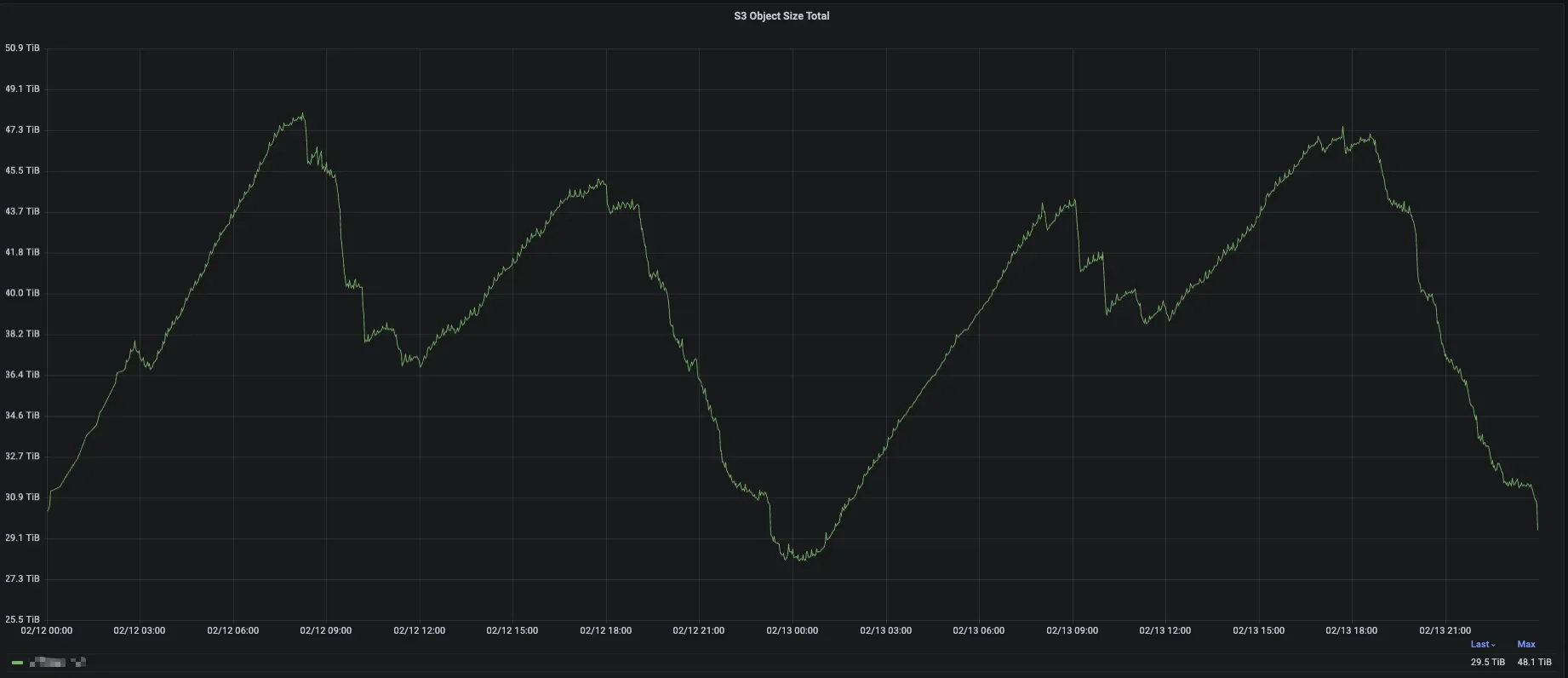
The following diagram shows the core metrics of an AutoMQ production cluster within JD.com. After adopting the new AutoMQ architecture, the cluster has achieved the following results:
-
Cluster storage costs reduced by 50%, bandwidth costs reduced by 33%: Thanks to AutoMQ's cloud-native architecture, the resource requirements for Kafka clusters in terms of storage and network bandwidth are significantly reduced, leading to substantial cost savings.
-
Cluster scaling efficiency on Kubernetes improved from hours to minutes: With AutoMQ, scaling Kafka on Kubernetes no longer requires extensive data copy reassignment, significantly reducing scaling times to the minute level. AutoMQ clusters can quickly and dynamically adjust capacity, effectively handling peak events such as large-scale promotions and flash sales in e-commerce scenarios. This not only reduces operational burdens but also prevents resource wastage due to over-provisioning for peak loads.
Future Outlook
AutoMQ, as a next-generation Kafka designed with a "cloud-first" concept, aligns perfectly with JD.com's comprehensive move to the cloud and cloud-native transformation. In the future, we will further promote and deepen the application of AutoMQ within JD.com, ensuring stable and high-availability clusters while advancing the full cloud- and cloud-native transition of data infrastructure. This will further lower data infrastructure costs and enhance efficiency.
References
[1] AutoMQ: https://www.automq.com/
[2] AutoMQ WAL Storage: https://docs.automq.com/automq/architecture/s3stream-shared-streaming-storage/wal-storage


