
If you are highly concerned about the latency of your streaming system, AutoMQ is an excellent choice.
Streaming systems are critical data infrastructures. AutoMQ [1] and WarpStream [2] are emerging forces in the streaming system field. They share similarities, such as using S3 as primary storage to reduce costs. However, they also have significant differences. This article comprehensively compares them across multiple dimensions, including performance, elasticity, availability, cost, ecosystem, and applicable scenarios, to help readers quickly understand their distinctions and choose the most suitable streaming system.
TL;DR
AutoMQ and WarpStream's differences can be summarized in the following figure. If you are interested in a detailed comparison, you can continue reading the subsequent content.
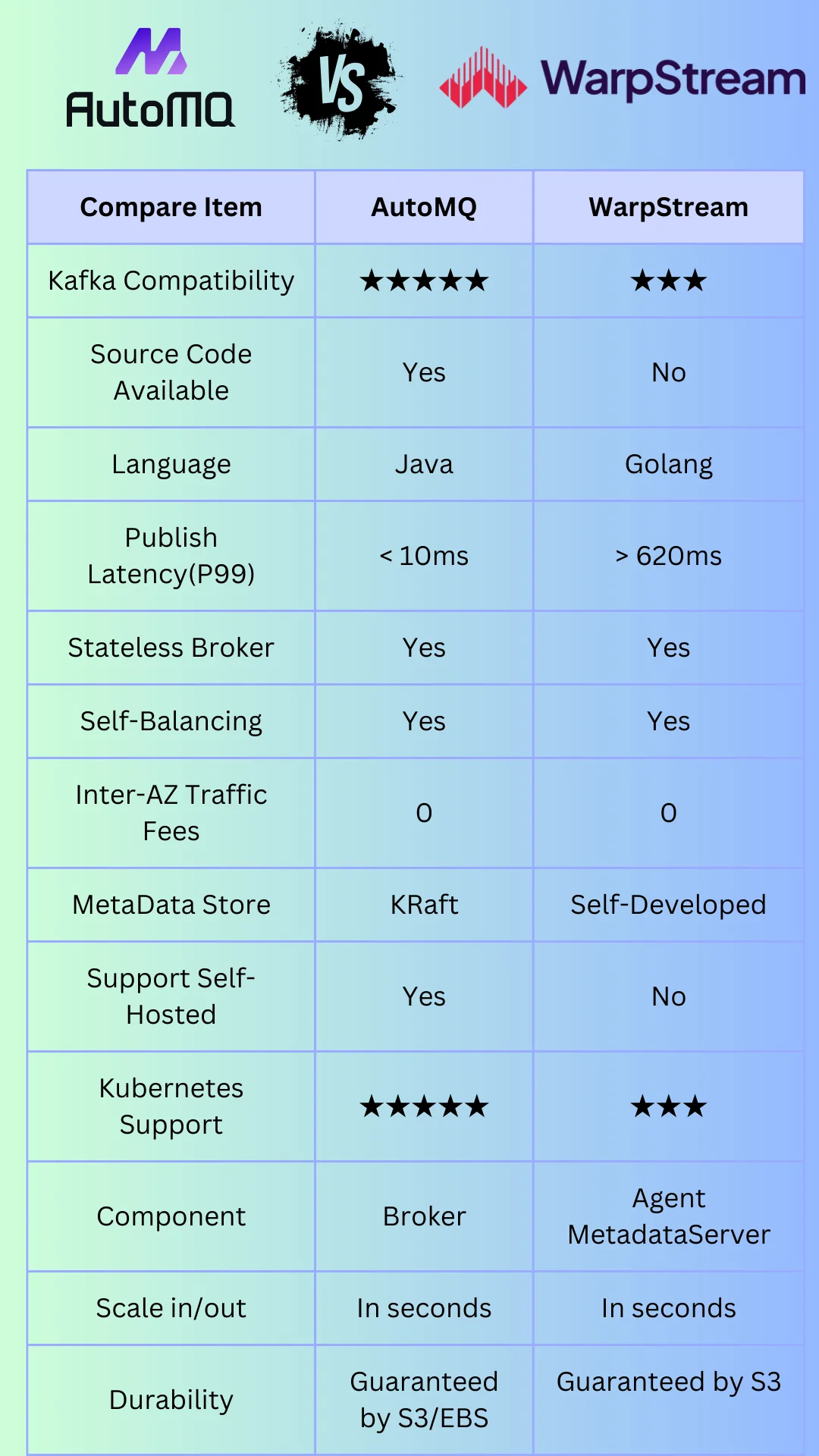
Native Kafka vs Kafka API Compatible
Apache Kafka® has been developing in the streaming system field for over a decade. To this day, its ecosystem has not weakened; instead, it has become more prosperous with the rise of AI and LLM. Kafka, with its robust ecosystem and vast existing market, has made the Kafka API the de facto standard in the streaming system field.
Kafka compatibility is extremely important.
Insufficient Kafka compatibility can lead to the following issues:
-
High migration costs : Migrating existing businesses to a new Kafka alternative involves extensive modifications and unknown risks. For example, if a business system strongly depends on a specific API behavior of Apache Kafka®, adopting a new Kafka alternative without considering this can cause business failures. Without sufficient Kafka compatibility, it is very challenging to fully and correctly assess migration risks and implement the migration.
-
Inability to leverage Kafka ecosystem benefits : To date, Apache Kafka® has accumulated a vast surrounding ecosystem that is still continuously developing. Without sufficient Kafka compatibility, it is impossible to fully utilize the value of the Kafka ecosystem. During subsequent usage, one often faces the need to redevelop related software, resulting in significant additional costs.
-
Detachment from the main Kafka community : Under the influence of Confluent and the broader open-source community, the Apache Kafka® community is still thriving. Lacking sufficient Kafka compatibility makes it difficult to leverage the power of the community. For instance, when significant features like KIP-932: Queues for Kafka[3] are launched in the future, merely achieving compatibility at the Kafka API protocol layer will not allow timely adoption of these major features. Even if one reimplements these features, they will initially lack sufficient community validation, requiring a long time to mature.
Number of compatible Kafka APIs: 73 (AutoMQ) vs 26 (WarpStream)
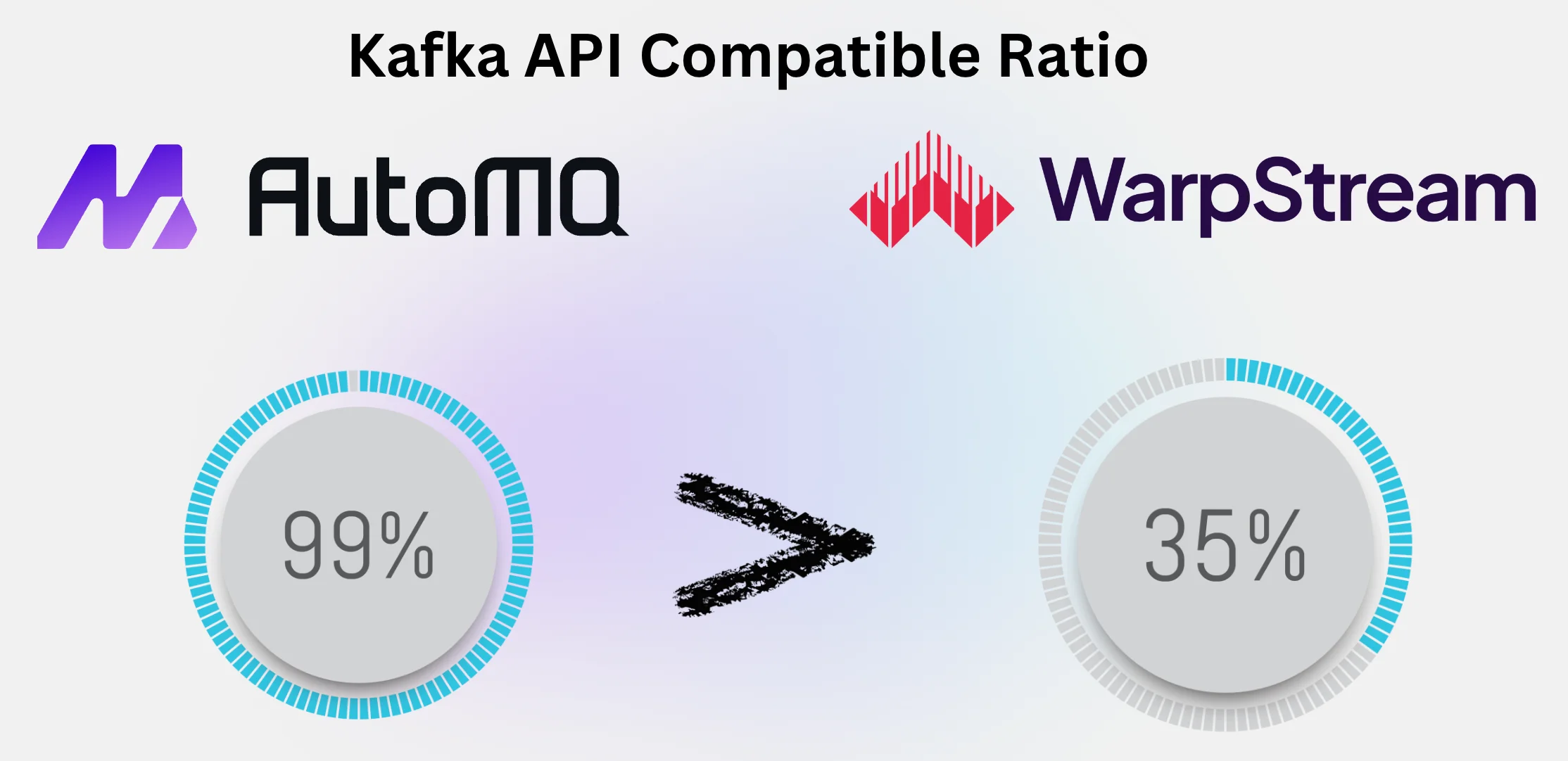
The official Apache Kafka Protocol documentation [4] defines a total of 74 Kafka APIs. Currently, WarpStream supports 26 Kafka APIs according to its official documentation [5], while AutoMQ supports 73 Kafka APIs. AutoMQ ensures data durability through a single replica by offloading persistence to EBS and S3, making the StopReplica API in Kafka inapplicable to AutoMQ. In terms of Kafka API compatibility, AutoMQ clearly surpasses WarpStream . Additionally, AutoMQ retains the entire implementation of the Apache Kafka compute layer, ensuring consistent behavior with Apache Kafka. In contrast, WarpStream re-implements these Kafka APIs, making it challenging to maintain consistency with the Apache Kafka community’s behavior.
-
Kafka Compatibility of WarpStream : WarpStream is a stream system re-implemented using Golang, which re-implements Kafka APIs and provides compatibility at the protocol level, supporting only 35.13% of Kafka APIs. Achieving complete compatibility with Apache Kafka APIs is difficult by merely providing protocol-level compatibility. As the Apache Kafka community trunk code continuously evolves and changes with new versions, solely protocol-level compatibility struggles to keep up with these changes and fixes, leading to discrepancies in the actual behavior of APIs compared to official APIs.
-
Kafka Compatibility of AutoMQ : As a community fork of Apache Kafka, AutoMQ has redesigned and re-implemented its storage layer while retaining the complete compute layer code of Apache Kafka. AutoMQ boasts 100% compatibility with Apache Kafka [6], having passed all 387 Kafka test cases (excluding Zookeeper-related tests, as AutoMQ only supports KRaft mode). Furthermore, AutoMQ can swiftly follow updates and fixes from the Apache Kafka community trunk due to its complete compatibility with the compute layer of Apache Kafka. For example, AutoMQ has already integrated the latest 3.8.x code from the Apache Kafka community. Future feature updates and fix releases from the Apache Kafka community will be promptly followed by AutoMQ, ensuring a divergence of no more than 2 months from the community trunk compute layer.
Overall, AutoMQ, as a code fork of Apache Kafka, falls into the category of Native Kafka [7], while WarpStream falls into the category of Kafka Protocol Compatible (non-fully compatible).
| - | AutoMQ | WarpStream |
|---|---|---|
| Kafka Compatibility | Native Kafka | Kafka Protocol Compatible |

Better K8s Support
Currently, WarpStream only supports deploying agents to Kubernetes [8], with its metadata services and other components requiring deployment outside of Kubernetes. WarpStream's Kubernetes support is presently limited, lacking comprehensive management of cluster lifecycle, permissions, authentication, networking, and metadata through Helm charts and YAML files.
Benefiting from its complete compatibility with Apache Kafka, AutoMQ can fully leverage the capabilities of the Bitnami Kafka Chart [9], deploying the entire AutoMQ data plane (including metadata services) to K8s for unified management. Additionally, the scaling challenges associated with multi-replica partition data replication in Apache Kafka, experienced while using Bitnami Kafka, are resolved with AutoMQ. AutoMQ provides users with a deeply integrated, low-cost, and highly elastic Kafka service on K8s.
Storage Architecture
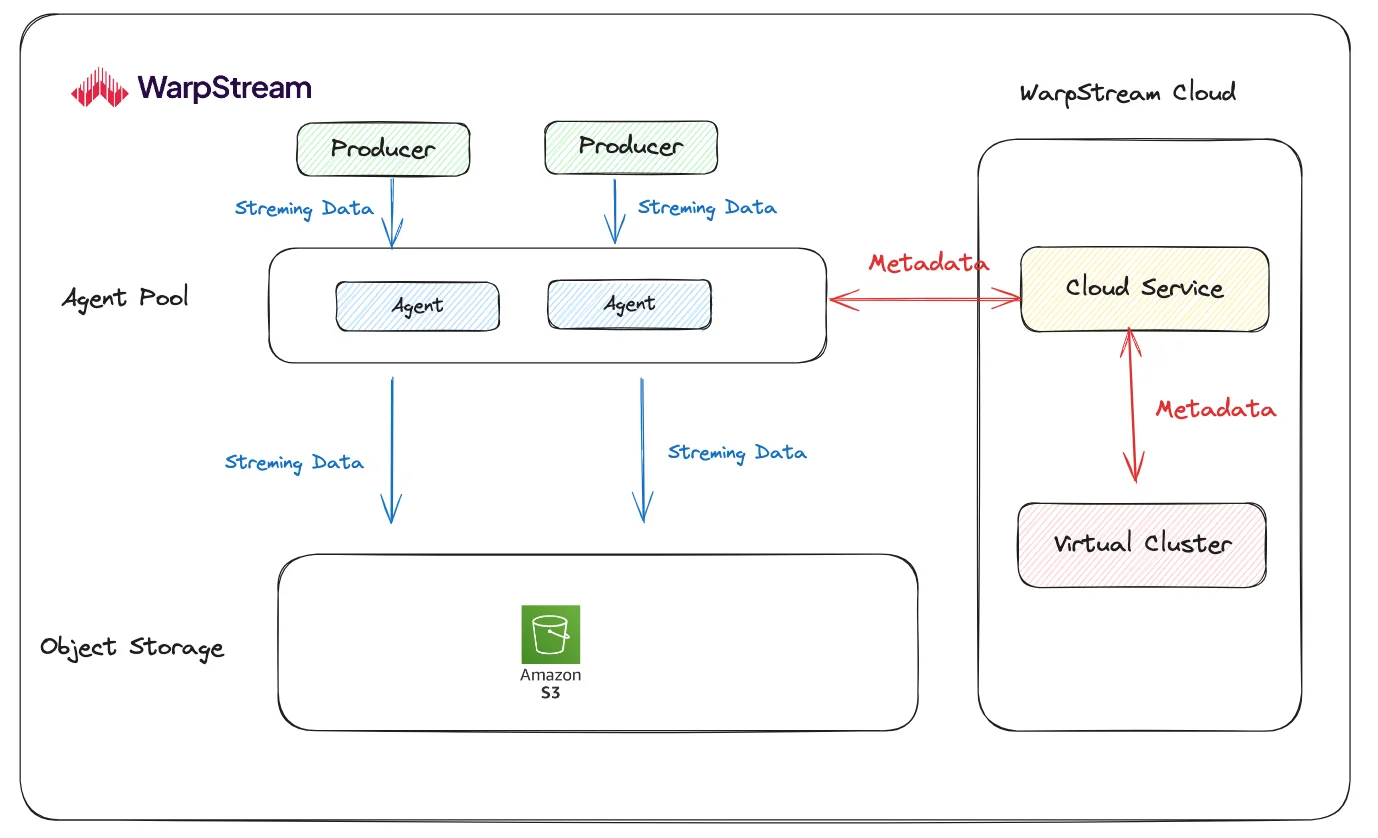
AutoMQ and WarpStream both utilize object storage services like S3 for their storage layer, achieving significantly higher cost efficiency compared to Apache Kafka. Both follow the shared storage architecture principle, but their design and implementation differ markedly . The following diagrams clearly illustrate the differences between AutoMQ and WarpStream:
-
Metadata Management Implementation : AutoMQ's computational layer implementation aligns closely with Apache Kafka. As a result, it provides 100% Kafka compatibility and reuses KRaft for metadata management. In contrast, WarpStream's metadata management heavily relies on its proprietary components, Cloud Service and Virtual Cluster, under WarpStream Cloud.
-
Storage Layer Implementation : WarpStream’s implementation is relatively straightforward. It employs an Agent to receive data from the Producer, which then writes the data to object storage. This approach only returns success to the Producer once the data is fully persisted in the object storage, before proceeding with subsequent data writes. The major drawback of this method is the loss of latency performance. WarpStream’s official evaluation shows a P99 latency of 620ms [10]. AutoMQ, on the other hand, supports a pluggable Write-Ahead Log (WAL) architecture. When configured with EBS WAL, AutoMQ uses a small EBS volume (10GB) as WAL, leveraging EBS’s low latency, high performance, and durability to ensure write performance. With EBS WAL, AutoMQ can provide single-digit millisecond P99 latency [11], making it significantly superior to WarpStream in terms of latency . AutoMQ Open Source defaults to S3 WAL, which writes WAL data directly to object storage for a fully diskless architecture. Additionally, since EBS inherently ensures high durability through multiple replicas, AutoMQ does not need to use additional replicas like Apache Kafka, thereby saving 2/3 of the storage costs and completely avoiding data replication between Brokers. As shown in Figure [4], AutoMQ can achieve millisecond-level failover using NVME Reservation and multiple EBS volume mounts, effectively treating EBS as shared storage.
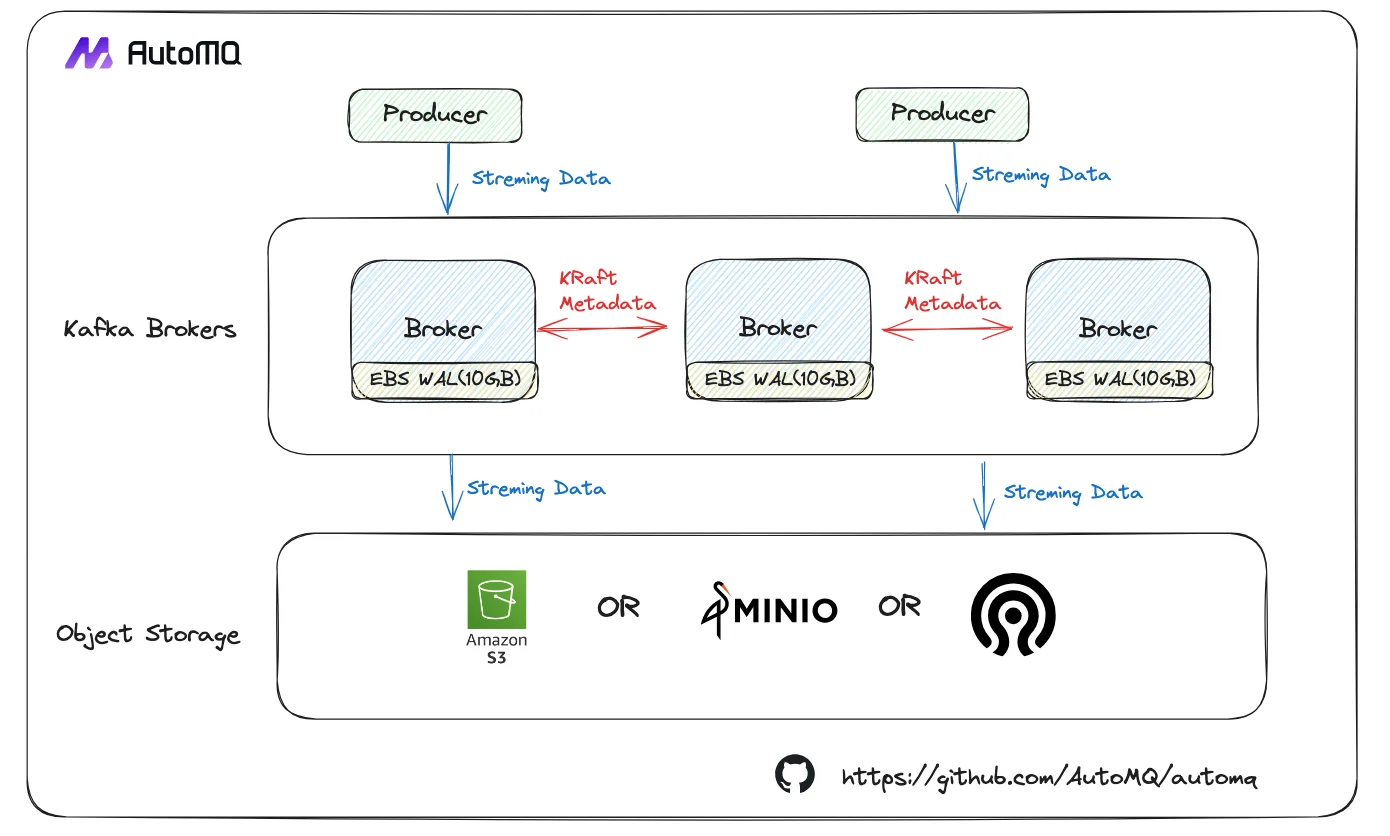
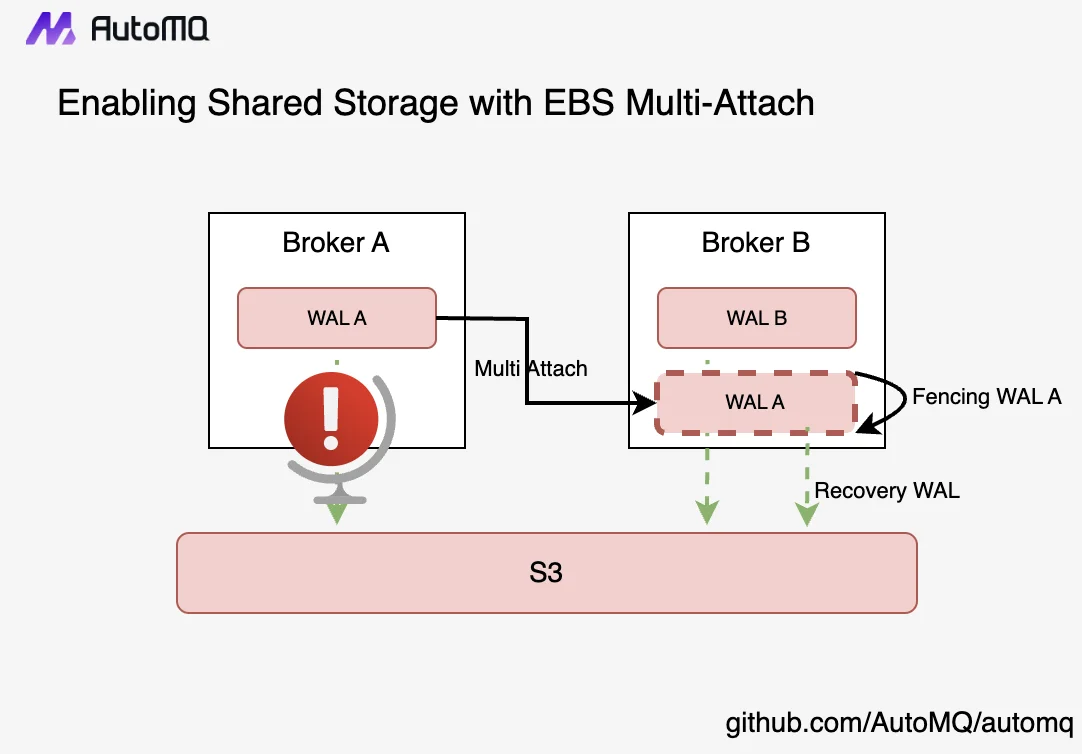
Open vs. Closed: Multi-Mode Shared Storage Architecture
Another significant difference in the storage design philosophy between AutoMQ and WarpStream is that AutoMQ is an open stream storage architecture. This openness manifests in several ways:
-
AutoMQ’s Core Stream Storage Engine Source Code is Public : WarpStream is a fully closed-source commercial product. Compared to open-source/open-code products, closed-source products naturally have a disadvantage in product validation. The lack of sufficient users means their maturity is slower than that of open-source/open-code products. Moreover, it creates a higher barrier for initial users interested in trying and experiencing the product, hindering deep understanding and learning. In contrast, AutoMQ has publicly released all source code [12] of its core stream storage engine, S3Stream, on GitHub. The open-source version of AutoMQ available on GitHub is referred to as the Community Edition. Users are free to study, learn, and experience AutoMQ through the Community Edition, and they can apply it to production environments for free.
-
AutoMQ Features a More Flexible and Open Stream Storage Engine Implementation : Recently, we’ve seen Databricks acquire Tabular, the creator of Apache Iceberg [13]. Iceberg’s rise to become the de facto standard for data lake storage formats is closely related to its flexible and open design philosophy. A similar example is Kubernetes triumphing over Docker Swarm to become the de facto standard in container orchestration. History shows that a more open and general design is more likely to succeed. Compared to WarpStream, AutoMQ’s stream storage engine design is more flexible and versatile. AutoMQ’s top layer provides a more general and flexible abstraction for WAL, known as Shared WAL [14]. Shared WAL can have different implementations for different storage media and even combine various implementations. Different storage media have different performance characteristics and usage scenarios. The WarpStream-like approach of writing directly to S3 is already implemented in AutoMQ, and you can run it now with our open-source code.
KRaft vs. Proprietary Metadata Storage
AutoMQ, as a native Kafka, directly leverages Apache Kafka's KRaft to manage metadata, bringing the following advantages over WarpStream:
-
More mature and stable : KRaft has undergone more than three years of market testing since its initial release and has been widely adopted in production environments by many Kafka service providers such as Confluent, AWS MSK, Aiven, and Instaclustr. As one of the core components of a stream system, ensuring the stability and reliability of metadata storage services is particularly important.
-
No external dependencies for metadata services: AutoMQ uses KRaft for metadata management without any external dependencies. According to the principle of Occam's Razor, one should not multiply entities beyond necessity. By using KRaft, AutoMQ embodies this principle well, simplifying the architecture, shortening the metadata transmission path, and reducing complexity and the likelihood of errors. WarpStream, on the other hand, relies on two additional independent services, Cloud Service and Virtual Cluster, resulting in a longer metadata transmission path. To ensure the reliability of metadata transmission, high availability of both Cloud Service and Virtual Cluster must be guaranteed, which adds complexity in deployment and engineering implementation.
-
Friendly to self-deployment : AutoMQ is very friendly to self-deployment. AutoMQ has optimized Kafka's startup process, allowing the creation of a distributed AutoMQ cluster with a single command on multiple machines, even when using the free open-source Community Edition, with no external dependencies and simple deployment. In contrast, WarpStream requires the deployment of high-availability versions of Cloud Service and Virtual Cluster to ensure the availability of the entire WarpStream service.

Stream system latency cannot be ignored: Low latency vs. high latency
WarpStream was designed with the plan to completely abandon stream system latency performance. While we acknowledge that some scenarios indeed do not require low latency, this approach seems more like a "forced compromise." The desire to build a stream system on top of S3 without a good solution to elegantly handle latency issues has led to an acceptance of latency performance loss. From AutoMQ's perspective, low latency is an essential aspect of a stream system. Latency is a strong indicator of product consistency and compatibility.
-
Real-time capability is the future technology trend : Technological advancement is always moving forward. The streaming field inherently values data real-time capabilities, leading to the emergence of low-latency stream processing engines like Apache Flink and stream databases like RisingWave for real-time low-latency event streams. A high-latency stream system would hinder better collaboration with other products in the modern data tech stack.
-
Real-time capability drives business success : In an increasingly competitive global environment, those who can quickly derive value from data will have more business opportunities and be more likely to succeed.
-
Real-time scenarios still have significant applications in the field of streaming : They remain crucial in financial trading, real-time data analysis, real-time monitoring, fraud detection, and real-time recommendations.
-
Switching to high-latency systems incurs additional reassignment costs : If your existing business is using Apache Kafka, the reassignment cost to use AutoMQ is lower. Transitioning from low latency to high latency involves a range of implementation difficulties and costs, such as performance testing, parameter tuning, and AB version comparisons. With AutoMQ, there is no need to adjust any configurations for your clients and upper-layer applications. AutoMQ has supported many customers in reassigning their production environments from Apache Kafka to AutoMQ, fully validating this point.
Even if your current business operations do not prioritize latency, we still recommend using AutoMQ. AutoMQ provides an integrated multi-modal storage engine. AutoMQ Open Source defaults to S3 WAL, which is simple to deploy and fully diskless. When latency is not a concern, this is the ideal choice. When you need lower latency in the future, you can switch to a low-latency WAL option such as EBS WAL or Regional EBS WAL without replacing your streaming system. Looking further ahead, if new storage media with unique advantages emerge in the market, AutoMQ's Shared WAL unified abstraction can easily support these new storage types. Refer to previous content on how we achieved Kafka directly on S3 with just over 100 lines of code [15]. By using a single streaming system product, you will be better equipped to adapt to various future changes, rather than having to procure a new product when latency becomes a concern.
References
[1] AutoMQ: https://www.automq.com
[2] WarpStream: https://www.warpstream.com
[3] KIP-932: Queues for Kafka: https://cwiki.apache.org/confluence/display/KAFKA/KIP-932%3A+Queues+for+Kafka
[4] Apache Kafka Protocol: https://kafka.apache.org/protocol.html#protocol_api_keys
[5] Protocol and Feature Support: https://docs.warpstream.com/warpstream/reference/protocol-and-feature-support
[6] AutoMQ Kafka Compatibility: https://docs.automq.com/automq/what-is-automq/compatibility-with-apache-kafka
[7] Kafka API is the De Facto Standard API for Event Streaming like Amazon S3 for Object Storage: https://www.kai-waehner.de/blog/2021/05/09/kafka-api-de-facto-standard-event-streaming-like-amazon-s3-object-storage/
[8]Deploy the Agents: https://docs.warpstream.com/warpstream/byoc/deploy
[9] Bitnami Kafka: https://artifacthub.io/packages/helm/bitnami/kafka
[10] WarpStream Benchmark: https://www.warpstream.com/blog/warpstream-benchmarks-and-tco
[11] AutoMQ Benchmark: https://docs.automq.com/automq/benchmarks/benchmark-automq-vs-apache-kafka
[12] AutoMQ S3Stream: https://github.com/AutoMQ/automq/tree/main/s3stream
[13] Databricks Agrees to Acquire Tabular: https://www.databricks.com/company/newsroom/press-releases/databricks-agrees-acquire-tabular-company-founded-original-creators
[14] AutoMQ Shared WAL: https://docs.automq.com/automq/architecture/s3stream-shared-streaming-storage/wal-storage
[15] 100+ Lines of Code to Implement Kafka on S3: https://github.com/AutoMQ/automq/wiki/100--Lines-of-Code-to-Implement-Kafka-on-S3
[16] Kafka is dead, long live Kafka: https://www.warpstream.com/blog/kafka-is-dead-long-live-kafka
[17] Aacke Kafka Documentation 2.8.0: https://kafka.apache.org/28/documentation.html


