Hong Lvhang, Chief Engineer of Digital Infrastructure, Geely Automobile Group
About Geely Automobile
**Geely Automobile Group (stock code: HK.0175) ** is an automobile group under Geely Holding Group, which integrates the design, research and development, production, sales and service of complete vehicles, powertrains and key components. It has more than 70,000 employees and has ranked first in the sales of Chinese brand passenger cars for four consecutive years, continuously leading Chinese brands to be confident and upward.
Geely Automobile Group has established styling design and engineering research and development centers in Shanghai, Ningbo, Gothenburg, Barcelona, California, Frankfurt, and Kuala Lumpur, with more than 20,000 design and development personnel and a large number of invention and innovation patents. In China and MY, Geely has world-class modern vehicle and powertrain manufacturing factories, with more than 1,400 sales outlets and a global sales and service network.
Adhering to the values of "people-oriented, innovation, and excellence", Geely Automobile Group takes "creating a travel experience beyond expectations" as its mission and is committed to becoming the most competitive and respected Chinese automobile brand.
Application of AutoMQ in Geely vehicle-to-everything (V2X) Hybrid Cloud architecture
Geely Big Data Platform (abbreviation: GDMP) has the capabilities of Data Acquisition, low-code development, task scheduling, data mapping, quality monitoring, data services, etc. It is the foundation and data development governance platform of Geely Automobile Big Data, carrying the whole-link Line of Business of research, production, supply, sales, and service. Under the trend of automotive electrification, intelligence, networking, and sharing, the vehicle to everything data has grown by PB annually, and the coverage of business scenarios is becoming wider and wider. As the core data infrastructure of enterprise vehicle to everything data, the rapid development of automotive business has put forward higher requirements for Kafka's elasticity and cost. AutoMQ, as the new generation of Kafka, perfectly solves the Kafka volume expansion and contraction problem that Geely Automobile is currently most concerned about, ensuring the normal operation of the vehicle-to-everything (V2X) core system.
Geely's vehicle to everything system currently uses the Hybrid Cloud architecture, mainly considering the following reasons:
-
**Cost ** : Geely Automobile has a large amount of existing data infrastructure in the private cloud, and adopting the Hybrid Cloud architecture will have better cost-effectiveness overall.
-
Data security: Some key data is stored in Geely's own data center for better data privacy and security.
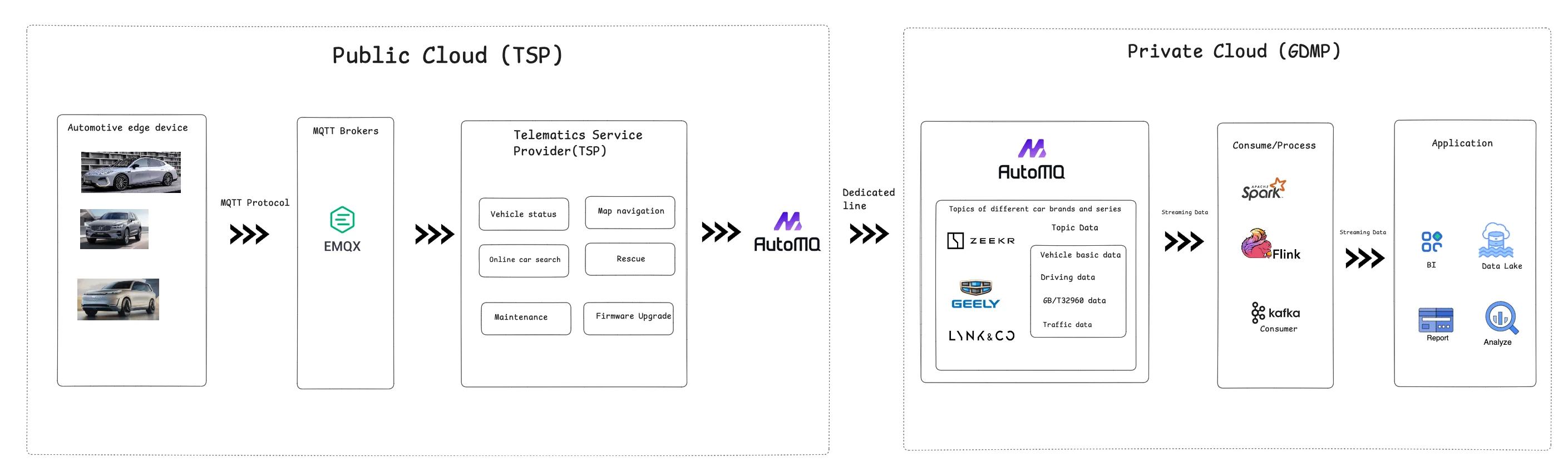
- **Data reporting ** : The end point device of the car will send the core data required for vehicle to everything to the MQTT Server in the cloud through the MQTT protocol for TSP. TSP combines the vehicle to everything service capabilities provided by the car and the car company, providing many service capabilities such as rescue, entertainment, rescue, autonomous driving, firmware upgrade, etc. On Geely Automobile Public Cloud, an AutoMQ cluster will be deployed to receive and distribute data from the vehicle networking TSP application on the Public Cloud. AutoMQ will serve as the core data bus for vehicle to everything data reporting, providing powerful throughput, reliable persistent storage, and read and write performance.
TSP (Telematics Service Provider) is an automotive remote service provider. It occupies a core position in the Telematics industry chain, connecting automotive and in-vehicle equipment manufacturers, network operators, and content providers. Telematics services integrate modern computer technologies such as location-based services, GIS services, and communication services, providing powerful services for car owners and individuals such as navigation, entertainment, information, security, SNS, and remote maintenance.
- **Data flows into the AutoMQ cluster of GDMP ** : The data of TSP on Public Cloud will further flow into the AutoMQ cluster of Geely's private cloud Big data platform GDMP through a dedicated line. The Topic data in this AutoMQ cluster includes vehicle to everything data from different car brands under Geely Group, such as Flink, Spark and Kafka consumers downstream. The data will eventually be written into the Data lake and applied in scenarios such as BI, Data Analysis, and reporting for Geely Automobile.
Why choose AutoMQ?
Geely Automobile owns numerous car brands. In recent years, with the strong development of each brand's business, the data volume of vehicle to everything has also been expanding. Against this backdrop, the problem of Kafka's difficulty in volume expansion and contraction has become increasingly severe.
-
**Unable to expand capacity at critical moments, the business suffers ** : Apache Kafka's volume expansion and contraction is a high-risk, heavy-duty, and time-consuming operation. Evaluating and managing Kafka cluster capacity is a difficult task in actual production environments. If there is a sudden peak load, the Kafka cluster does not reserve enough resources. At this time, the service capability of the existing cluster can only be downgraded to "tough it out". This directly affects our normal business, affecting the actual vehicle to everything experience and normal operation of car owners. For example, in the past, because we couldn't handle the expansion of Kafka cluster well, we could only reduce the original retention time from 5 days to 2 days. The reduction in retention time also had some impact on scenarios where we consume historical data such as data re-run.
-
**It is difficult to manage the capacity of Kafka cluster and the operation and maintenance cost is high ** : Kafka relies on local storage due to its computing strong coupling storage. When volume expansion and contraction, a comprehensive migration plan needs to be developed to replicate the existing partition data, which is highly complex and time-consuming. For example, the Kafka cluster used by Geely Automobile in the past needs to mount new data volumes when the capacity is insufficient. On the one hand, there is an upper limit to the data volumes that computing instances can mount. If the mounting limit is reached, both computing and storage have to be expanded at the same time, resulting in a lot of resource waste. The new cost growth also requires re-application for budget and approval internally, which is very complex and costly to implement. On the other hand, mounting new data volumes on the Broker to expand the storage capacity of the Kafka cluster is a very complex matter, involving operations such as adding disks, mounting, modifying configurations, migrating partitions, and drainage. It can only be implemented under key guarantees during low business peak periods, which is a complex and dangerous operation. It is precisely because Kafka cluster volume expansion and contraction are difficult that Kafka operation and maintenance personnel are forced to manage the capacity of the Kafka cluster in advance. However, capacity management often puts operation and maintenance colleagues in a dilemma in actual production practice. If too many resources are reserved for the Kafka cluster, it will lead to a lot of cost waste during low business peak periods. If the resources are insufficient, it is impossible to expand in time when the enterprise traffic grows rapidly, and only accept the loss of business.
Due to the pain points caused by Kafka's lack of elasticity, we began to seek new Kafka alternatives. AutoMQ offloaded persistence to cloud storage and built a new generation of low-cost, high-performance, and extremely fast Kafka using WAL and object storage such as S3. These excellent features quickly caught our attention. At that time, our cluster had to reduce retention time due to Kafka's lack of elasticity and difficulty in scaling. The emergence of AutoMQ made us very excited. We immediately contacted the AutoMQ team and conducted PoC. After actual application, we confirmed that AutoMQ did indeed solve several pain points we had previously been concerned about.
-
Zero operation and maintenance, rapid volume expansion and contraction: AutoMQ's rapid expansion is mainly due to its innovative streaming storage architecture. By offloading data persistence to cloud storage, AutoMQ no longer needs to configure multiple replicas internally like Kafka, because cloud storage itself already has multiple replicas and provides high persistence. In addition to cost savings, the more important point is that it no longer needs to replicate partition data like Kafka during volume expansion and contraction, thus providing second-level partition migration capability. In addition, its built-in continuous running rebalancing component can ensure that newly added nodes automatically complete safe and reliable drainage while ensuring optimal cluster utilization. Therefore, the entire rapid expansion does not require manual intervention and is completely automated. This is a world of difference from the experience of operating and maintaining Kafka in the past.
-
No need for capacity assessment, reduce operation and maintenance costs : The cost of Kafka is not only reflected in the consumption of its IaaS resources, but also a large part of the proportion lies in the manpower investment in the organization. AutoMQ itself provides unlimited capacity streaming storage capabilities based on S3, and computing and storage are completely decoupled, which means that we no longer need to worry about insufficient storage space caused by setting long retention times. If the cluster needs to carry out larger throughput and needs to be expanded, AutoMQ can also automate volume expansion and contraction in a very short time, so we do not need to prepare plans, coordinate upstream and downstream applications, formulate migration plans, and expand, migrate, and attract traffic during business peak periods as in the past. This completely frees Kafka operation and maintenance colleagues from complex, high-risk volume expansion and contraction operation and maintenance, capacity evaluation and other work, so that they can perform more valuable operation and maintenance tasks.
-
100% Kafka compatibility : AutoMQ's full compatibility with Apache Kafka is also a key reason why we can choose it with confidence. This means that we do not need to make any modifications to all the applications, tools, or even client configurations built around Kafka to complete the migration. In the future, Geely Automobile can still use Kafka's powerful ecosystem to further improve and iterate our data infrastructure.
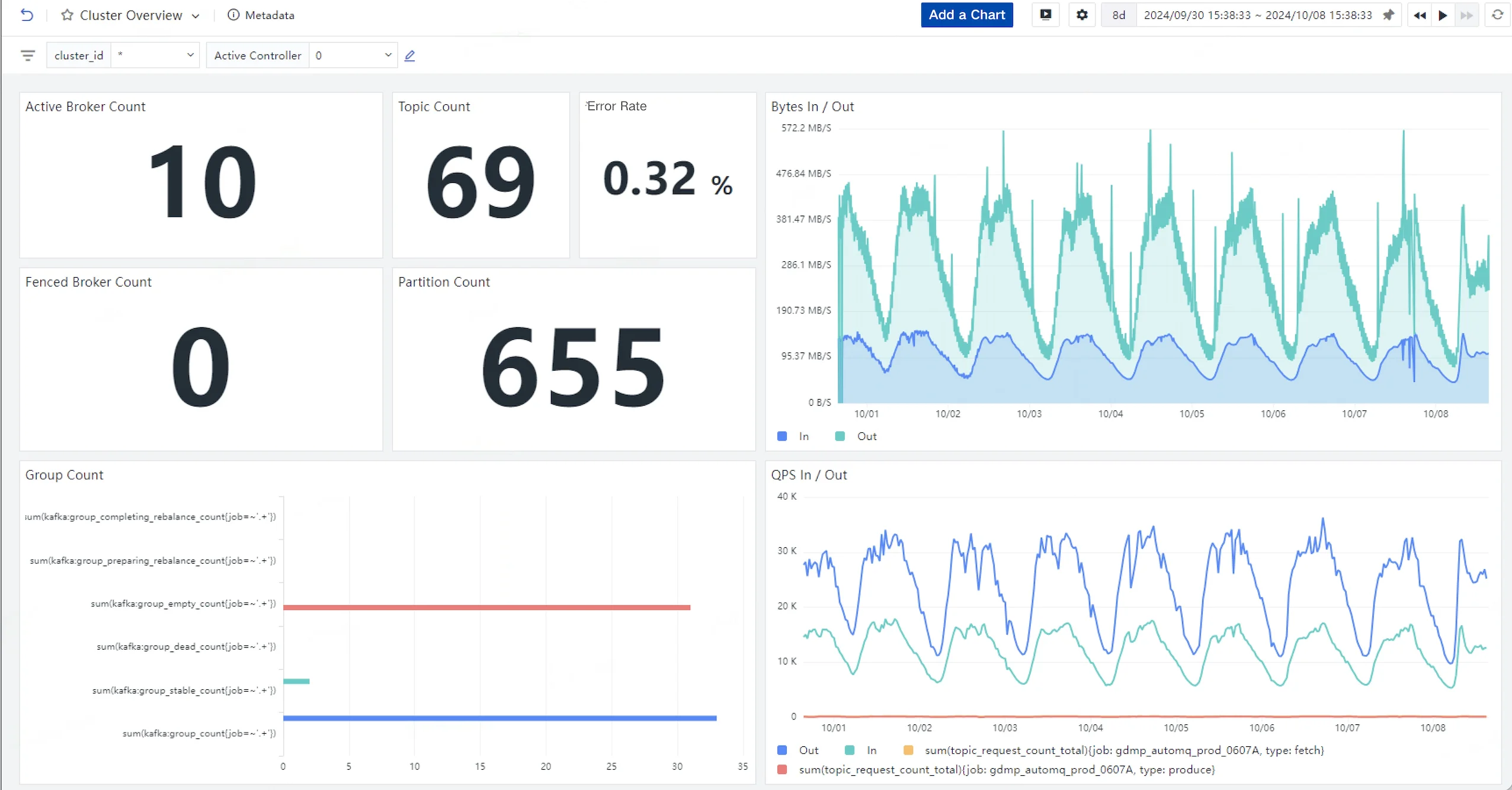
The effect of AutoMQ production application
Currently, AutoMQ has been officially applied to the production environment of Geely's vehicle to everything core system. The following figure shows the monitoring chart of one of the production clusters. After applying AutoMQ, it perfectly solved all the pain points we encountered in Kafka in the past, and also helped us save a lot of IaaS layer costs, far exceeding expectations. In the future, we will continue to cooperate with the AutoMQ team and use modern and advanced stream storage technology to provide our customers with the best vehicle to everything service.