
TL;DR
We're excited to announce Open Source AutoMQ v1.6.0. Key improvements for developers include:
-
Up to 17x Cost-Effectiveness: Through significant write path optimizations, AutoMQ now achieves up to a 17x TCO reduction compared to self-hosted Apache Kafka under high-throughput workloads.
-
Enhanced Table Topic: Simplifies data lake ingestion with native support for CDC streams and more flexible schema management, reducing the need for separate ETL jobs or a mandatory Schema Registry.
-
Full Strimzi Operator Compatibility: Enables seamless integration with the Strimzi Operator, allowing you to manage AutoMQ on Kubernetes with familiar tooling for rapid, data-rebalance-free scaling.

If you are interested in the full list of v1.6.0 updates, see the full release note.
AutoMQ: The Reinvented Diskless Kafka on S3
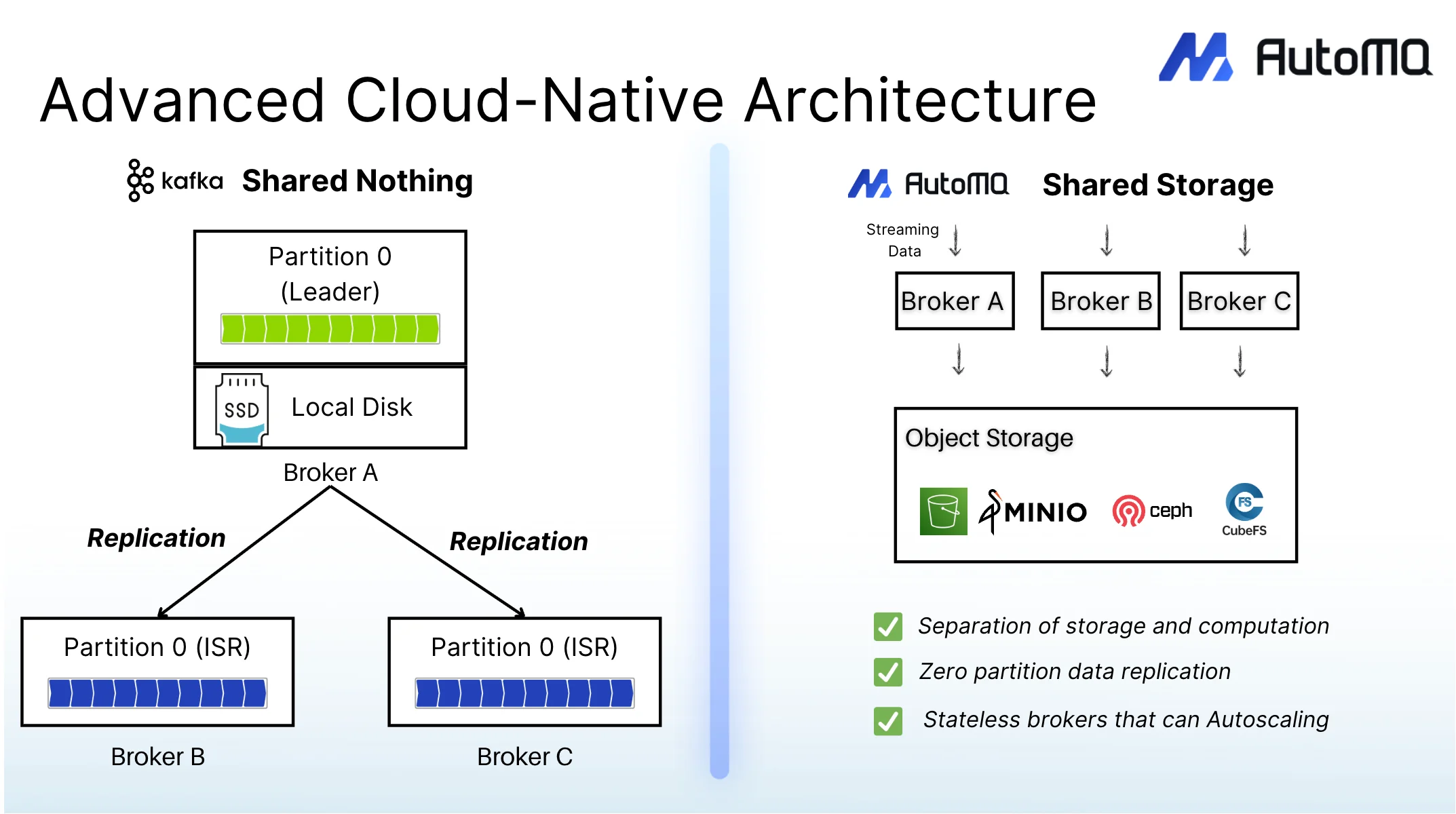
Before we dive into the specifics of 1.6.0, for those new to the project, it’s worth recapping the core architecture of AutoMQ and the problems we set out to solve. Every engineer who has managed Kafka at scale knows the operational friction. A traffic spike demands more capacity, but scaling out means facing hours of partition rebalancing—a high-risk, resource-intensive process that locks compute and storage into a rigid dance. This is the architectural scar tissue from Kafka's on-premise, shared-nothing origins.
AutoMQ was built to erase that scar tissue by fundamentally re-architecting Kafka for the cloud. We started with a simple question: What if brokers didn’t have disks? By decoupling compute from storage and building a new storage layer that streams data directly to S3 or compatible object storage, we address Kafka's primary cloud challenges head-on:
-
True Elasticity: Brokers become lightweight and stateless. That late-night scaling event is no longer a dreaded data migration project; it's simply about launching new pods, a process that completes in seconds, not hours.
-
Drastically Lower Costs: We eliminate the need for expensive, over-provisioned block storage (like EBS) and slash cross-AZ data replication costs by leveraging S3's pay-as-you-go model and regional endpoints.
-
Cloud-Native Durability: An AZ failure loses its sting. By offloading data persistence to cloud storage, the source of truth is always safe without the operational overhead of managing multi-replica ISR mechanisms.
This diskless foundation is what makes AutoMQ inherently more elastic, cost-effective, and resilient in the cloud. It’s the platform upon which the powerful cost and feature enhancements in this v1.6.0 release are built.
Beyond Kafka: A 17x Cost Reduction with AutoMQ
Running Kafka at scale in the cloud can be painfully expensive. We've all seen the bills. What if you could keep the Kafka API you love but slash the Total Cost of Ownership (TCO)? Our latest benchmark of v1.6.0 shows how AutoMQ can make that happen.
TL;DR: For a 1 GB/s workload, 3-AZ workload, AutoMQ 1.6 costs ~$12,900 per month . A comparable self-hosted Apache Kafka cluster costs ~$226,196 per month . That's a 17.5x cost reduction , primarily from slashing cross-AZ data transfer costs.
Let's break down how we got there.
The Benchmark Setup
Transparency is key. We ran these tests using our open-source benchmark tool to simulate a common, high-throughput streaming workload. Our goal was to compare the cost of running a fully durable, multi-AZ AutoMQ versus a traditional self-hosted Apache Kafka deployment on AWS.
| Parameter | Configuration |
|---|---|
| Workload | 1 GB/s throughput, 1:1 Fanout |
| Durability | Replication across 3 AWS Availability Zones (AZs) |
| Data Retention | 3 days TTL |
| AutoMQ Cluster | 6 x m7g.4xlarge EC2 instances |
| Baseline | Self-hosted Apache Kafka |
A 17x Cost Reduction, Explained
The cost savings aren't magic; they're the result of fundamentally changing how Kafka's storage layer interacts with cloud infrastructure. By replacing local disks with a direct-to-S3 storage engine, we decouple compute from storage and unlock massive efficiencies.
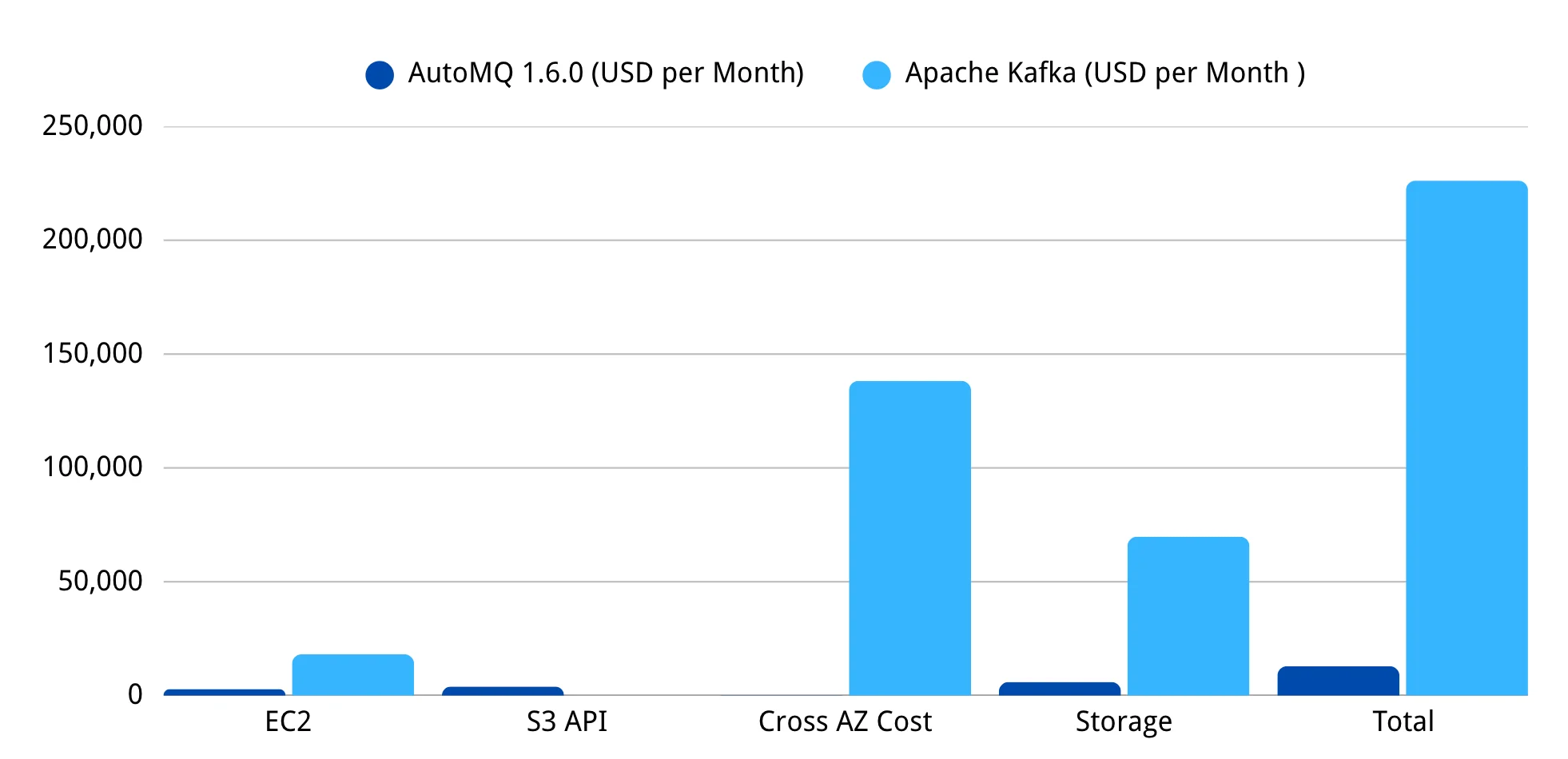
| Billing item | AutoMQ 1.6.0 (USD per Month) | Apache Kafka (USD per Month ) |
|---|---|---|
| EC2 | 2,859 | 18,134 |
| S3 API | 3,952 | - |
| Cross AZ Cost | 128 | 138,240 |
| Storage | 5,961 | 69,822 |
| Total | 12,900 | 226,196 |
Here’s where the savings come from:
-
Cross-AZ Networking (1080x Cheaper): This is the game-changer. A standard Kafka cluster replicates data by sending every message from the leader broker to follower brokers in other AZs. For a 1 GB/s workload with 3x replication, this generates enormous, costly cross-AZ traffic (~$138k/month). AutoMQ writes data directly to S3 and only needs to transfer a small amount of metadata and hot data across AZs. This single architectural change reduced our monthly cross-AZ networking bill from $138,240 to just $128.
-
Compute (6.3x Cheaper): Apache Kafka relies on local storage, and there is coupling between computation and storage. Cloud providers impose limits on the size of local disks; for example, AWS restricts disk usage to a maximum of 16TB. Given the need to store large amounts of data and redundant data partition replicas, Apache Kafka has to use more compute instances, resulting in wasted computing resources. AutoMQ separates computation from storage, allowing independent scaling and completely resolving this issue.
-
Storage (7x Cheaper): Apache Kafka requires expensive, provisioned block storage (like EBS) that must be scaled for peak capacity. AutoMQ leverages the elasticity and cost-effectiveness of S3's pay-as-you-go model. You only pay for the data you store, eliminating waste from over-provisioning.
What About Performance?
Performance is a careful balance of throughput, latency, and cost. In this 1 GB/s benchmark, AutoMQ 1.6 delivered a P99 produce latency of approximately 823ms.
Of course, we recognize that not all workloads are the same. For applications with strict low-latency requirements, AutoMQ Enterprise Edition provides the flexibility to use low-latency storage like regional EBS or FSx as the WAL storage backend. This configuration delivers the best of both worlds: P99 produce latencies of less than 10ms while still leveraging S3 for cost-effective, long-term storage.
You can learn more about our approach to balancing cost and latency in our deep-dive blog post: Deep Dive into the Challenges of Building Kafka on Top of S3.
Kafka Topic to the Iceberg Tables with Zero-ETL
The demand for real-time analytics is pushing data architectures to evolve. Traditional batch ETL pipelines, which ferry data from Kafka to data lakes, are increasingly being replaced by more direct, streaming ingestion patterns. This shift minimizes latency and operational overhead, but building and maintaining these custom pipelines remains a significant challenge.
As a developer, your goal is often straightforward: get the event stream from Kafka into your data lake, like Apache Iceberg, so you can run real-time analytics. The journey, however, is anything but. You start by deploying a separate ETL system—Flink, Spark, or Kafka Connect. Suddenly, you're managing a second distributed system just to move data out of your first one. It comes with its own operational overhead, failure modes, and, of course, costs.
Then comes the real challenge: keeping the pipeline alive. A microservice team adds a new field to their Protobuf schema. Your Flink job breaks. You now have to coordinate a multi-step deployment across the service, the ETL job, and the Iceberg table schema, all while praying data isn't lost. Or consider streaming database changes with Debezium. Your Kafka topic is flooded with complex CDC event envelopes, and now you have to write and maintain stateful logic to correctly parse the before and after images and translate op codes into the right INSERT , UPDATE , or DELETE operations on Iceberg. For every data source and format, you repeat this cycle, building brittle, duplicative pipelines.
This is the "ETL tax," and it's why we built AutoMQ Table Topic . It’s not another tool; it’s a fundamental rethinking of the streaming-to-data-lake workflow. Table Topic is a specialized topic type that acts as a native, Zero-ETL bridge directly within the Kafka broker, streaming data seamlessly into Apache Iceberg. It aims to eliminate the ETL tax by simplifying operations, automating schema evolution, and providing end-to-end reliability without external systems.
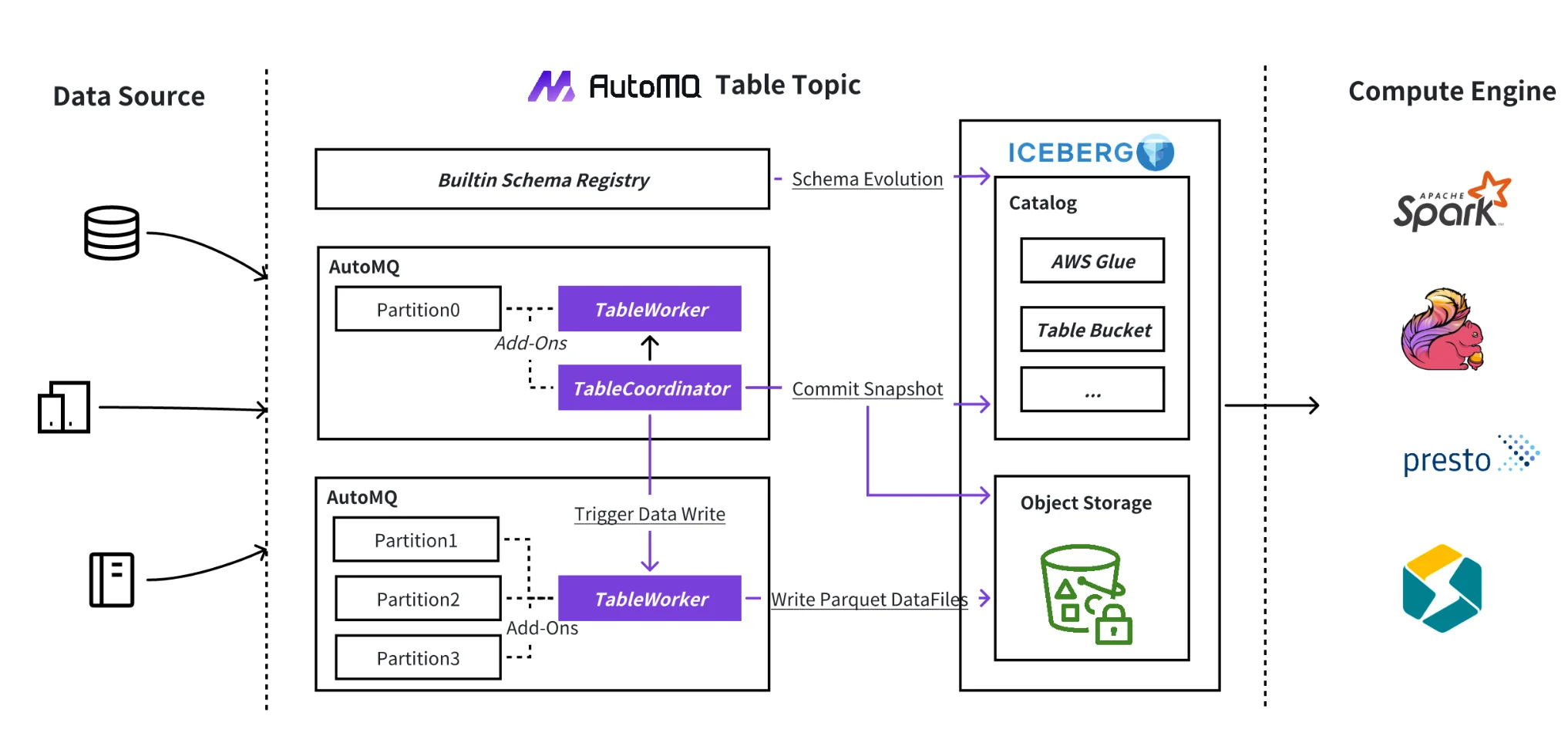
With AutoMQ 1.6.0, we’ve re-architected the engine behind Table Topic specifically to tackle these real-world complexities head-on. Our previous design worked, but as we onboarded more users, we hit the same walls you do. One team managed their Protobuf schemas directly in their application's git repo—they didn't want the operational burden of a Schema Registry. Our old implementation couldn't support them. Another team using Debezium found that while Table Topic could dump the raw changelog events into Iceberg, it couldn't semantically understand them; an UPDATE was just another row, not an actual update.
The 1.6.0 redesign solves these problems with a robust two-stage internal pipeline that separates concerns:
-
First, we've introduced a versatile data ingestion layer that liberates you from traditional constraints. This layer intelligently transforms raw Kafka message bytes into a structured, normalized internal format. By adopting a format deeply aligned with the data lake ecosystem and designed for seamless schema evolution, we effectively decouple you from a rigid dependency on a Schema Registry. This means greater flexibility for managing your schemas – whether you're directly importing Protobuf .proto files or dealing with schemaless JSON, we've got you covered.
-
Second, building on this normalized foundation, we apply intelligent content-aware processing. This is where we unlock advanced data lake capabilities. Take the Debezium challenge, for instance: our system now natively understands and processes Debezium CDC streams. With minimal configuration, it intelligently unwraps the Debezium envelope, precisely extracts your actual business data (from before or after fields), and accurately identifies the operation type (create, update, delete). This empowers your Table Topics to perform true upserts and deletes directly on your Iceberg tables, finally making CDC streams first-class citizens in your data lake. As a bonus, we've significantly boosted overall ingestion performance by optimizing the final data binding step from Avro to Iceberg.
This new architecture transforms Table Topic from a simple data mover into an intelligent, content-aware ingestion engine. It means you can now build a true end-to-end CDC pipeline or stream your application-managed Protobuf events without writing a single line of ETL code. For developers building real-time data lakes, this finally delivers on the promise of focusing on data, not the plumbing.
These enhancements make Table Topic an even more compelling solution for building real-time data lakes, powering use cases from live detailed transaction tables to near-real-time analytical dashboards.
100% Kafka-compatible: Seamless Strimzi integration

Imagine it's 3 AM. A traffic spike forces you to scale out your Kafka brokers on Kubernetes. This should be a routine, automated task. Instead, you're faced with a painful trade-off. Scaling out triggers hours of data rebalancing, creating a storm of network traffic and I/O load that jeopardizes cluster stability. This isn't a failure of Kubernetes; it's a sign that traditional Kafka is not truly Kubernetes-native. Kubernetes thrives on managing ephemeral, stateless workloads, enabling rapid scaling and self-healing. Kafka’s architecture, which tightly couples compute and storage, fundamentally resists these principles. This friction means you never realize the full promise of elasticity that brought you to Kubernetes in the first place.
The community’s best answer to this operational challenge is Strimzi, the definitive operator for automating Kafka management. It brilliantly simplifies deployment, but it cannot fix the underlying architectural constraints. It can't eliminate the data gravity that makes scaling a high-stakes event, so it can't deliver a truly Kubernetes-native Kafka experience. AutoMQ solves this core problem with an innovative compute-storage separated architecture. But this naturally leads to a critical question we hear from developers: "If you've re-architected Kafka's core, do we lose compatibility with the tools we rely on, especially Strimzi?"
The answer is an emphatic no . Thanks to our foundational design principle of maintaining 100% Kafka protocol compatibility, you don't lose the tools you trust. By simply adjusting the container image reference in the Strimzi custom resource, you can manage an AutoMQ cluster seamlessly. We are thrilled to announce that starting with version 1.6.0, AutoMQ is fully compatible with the Strimzi Operator, and we have validated its core capabilities through a comprehensive testing process.
| Category | Test Case | Status |
|---|---|---|
| K8s Integration | Resource & Scheduling Settings | Passed |
| - | Multi-AZ Deployment & Affinity | Passed |
| Core Operations | Broker Configuration Pass-through | Passed |
| - | JVM Parameter Settings | Passed |
| Elasticity & Scaling | Horizontal Broker Scaling (In/Out) | Passed |
| - | Version Upgrades | Passed |
| Security | SASL/PLAIN Authentication | Passed |
This seamless integration isn't a happy accident; it's a direct result of our philosophy. We believe the Kafka community is great and its ecosystem is powerful. By embracing the Kafka protocol completely, we ensure that as the ecosystem evolves, AutoMQ will evolve with it. Our Strimzi compatibility is a testament to this commitment. Now, when that 3 AM traffic spike hits, you can finally use the operator you trust to manage a Kafka that scales in minutes, not hours, truly unlocking the power of Kubernetes for your data streams. You can learn more about the technical design that makes this possible in our blog on achieving 100% Kafka protocol compatibility.
Tips: With full compatibility with Kafka, AutoMQ 1.6.0 has also released an image based on the Apache Kafka Open Source Image. Compatible with the startup logic of the Apache Kafka Docker image, out of the box. See more from here.
Try Open Source AutoMQ Now
AutoMQ 1.6.0 brings three things developers care about most in the cloud: dramatically lower cost, simpler data lake ingestion, and zero-friction operations on Kubernetes. With a 17x TCO reduction in our benchmark, a re-architected Table Topic for true Zero-ETL to Iceberg, and 100% Kafka-compatible Strimzi integration, you can keep your existing tools and APIs while finally gaining the elasticity the cloud promised.

Let's try AutoMQ now: https://docs.automq.com/automq/what-is-automq/overview


