
It’s really tough

Intro
Since its open-source release, Kafka has become the de facto standard for distributed messaging. It has gone from operating only on LinkedIn to meeting growing log processing demands, now serving many companies worldwide for various use cases, including messaging, log aggregation, and stream processing.
However, it was designed at a time when local data centers were more widely adopted than cloud resources. Thus, there are challenges when operating Kafka on the cloud. Compute and storage can’t scale independently, or cross-availability-zone transfer fees due to data replication.
When searching for “Kafka alternative,” you can easily find four to five solutions that all promise to make your Kafka deployment cheaper and reduce the operational overhead. They can do this or implement that to make their offer more attractive. However, one thing you might observe over and over again is that they all try to store Kafka data completely in object storage.
This article won’t explore Kafka’s internal workings or why it is so popular. Instead, we will try to understand the challenges of building Kafka on top of S3.
Background
But before we go further, let’s ask a simple question: “Why do they want to offload data to S3?“
The answer is cost efficiency.
In Kafka, compute and storage are tightly coupled, which means that scaling storage requires adding more machines, often leading to inefficient resource usage.
Kafka’s design also relies on replication for data durability. After storing messages, a leader must replicate data to followers. Because of the tightly coupled architecture, any change in cluster membership forces data to shift from one machine to another.
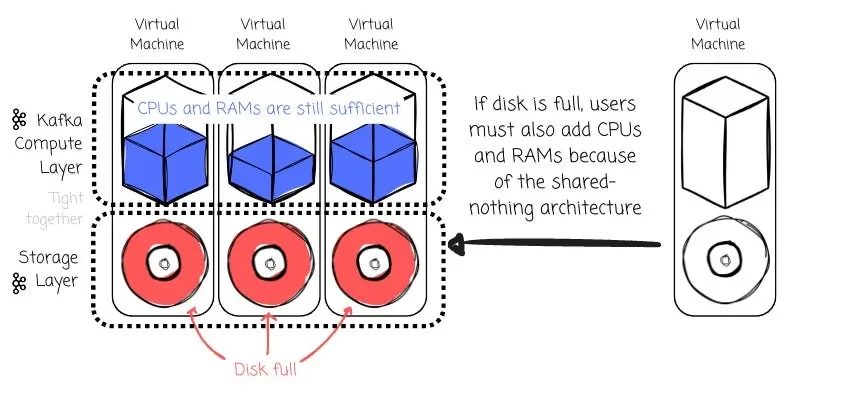
Another problem is cross-Availability Zone (AZ) transfer fees. Cloud vendors like AWS or GCP charge fees when we issue requests to different zones. Because producers can only produce messages to the partition leader, when deploying Kafka on the cloud, the producers must write to a leader in a different zone approximately two-thirds of the time (given a setup with three brokers). Kafka setup on the cloud can also incur significant cross-Availability Zone (AZ) transfer fees because the leader must replicate messages to followers in other zones.
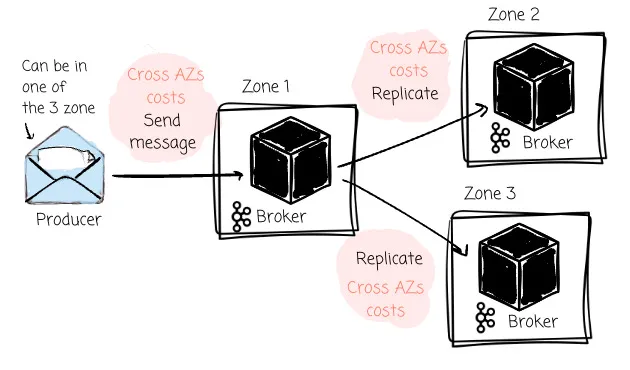
Imagine you offload all the data to object storage like S3, you can:
-
Save on storage costs because object storage is less expensive than traditional disk media.
-
Scale computing and storage independently.
-
Avoid data replication because the object storage will ensure data durability and availability.
-
Allow any broker to serve read and write
-
…
The trend of building a Kafka-compatible solution on object storage is emerging. At least five vendors have introduced a solution like that since 2023. We had WarpStream and AutoMQ in 2023, Confluent Freight Clusters, Bufstream, or Redpanda Cloud Topics in 2024.
Besides all the hype, I am curious about the challenges of building such a solution that uses S3 for the storage layer. To support this research, I chose AutoMQ because it’s the only open-source version. This allows me to dive deeper into understanding the challenges and solutions.
Brief introduction of AutoMQ
AutoMQ is a 100% Kafka-compatible alternative solution. It is designed to run Kafka efficiently on the cloud by leveraging Kafka’s codebase for the protocol and rewriting the storage layer so it can effectively offload data to object storage with the introduction of the Write Ahead Log.
Next, we will discuss the potential challenges of building Kafka on object storage and then see how AutoMQ overcomes them.
Latency
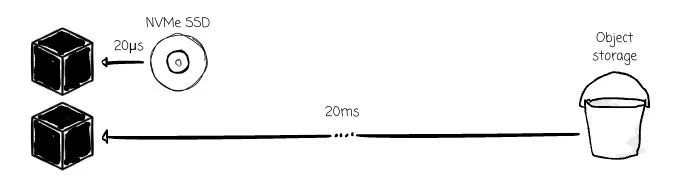
The first and most obvious challenge is the latency. Here are some numbers to help you imagine: with GetObject requests to object storage, the median latency is ~15ms, and P90 is ~60ms. The latency of an NVMe SSD is 20–100 μs, which is 1000x faster.
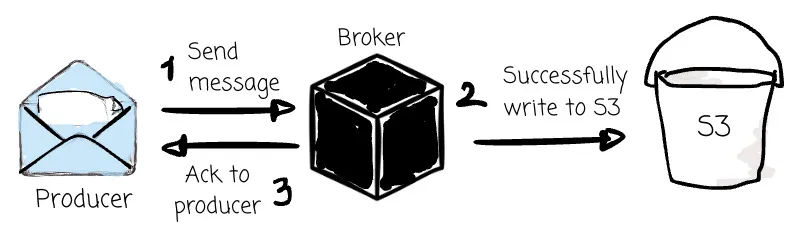
Some vendors choose to sacrifice low-latency performance. WarpStream or Bufstream believes this is a good trade-off for huge cost savings and ease of operation. These systems wait until the message persists in the object storage before sending the acknowledgment message to the producer.
AutoMQ doesn’t do that. It achieves low latency through a WAL+S3 architecture. AutoMQ supports multiple WAL backends with different latency and cost profiles. For sub-10ms write latency, the WAL uses a block storage device such as AWS EBS (EBS WAL). AutoMQ Open Source defaults to S3 WAL, which writes directly to object storage and trades some latency for a simpler, fully diskless architecture. The brokers must ensure the message is already in the WAL before writing to S3; when the broker receives the message, it returns an “I got your message” response only when it persists in the WAL. The data is then later written to object storage asynchronously.
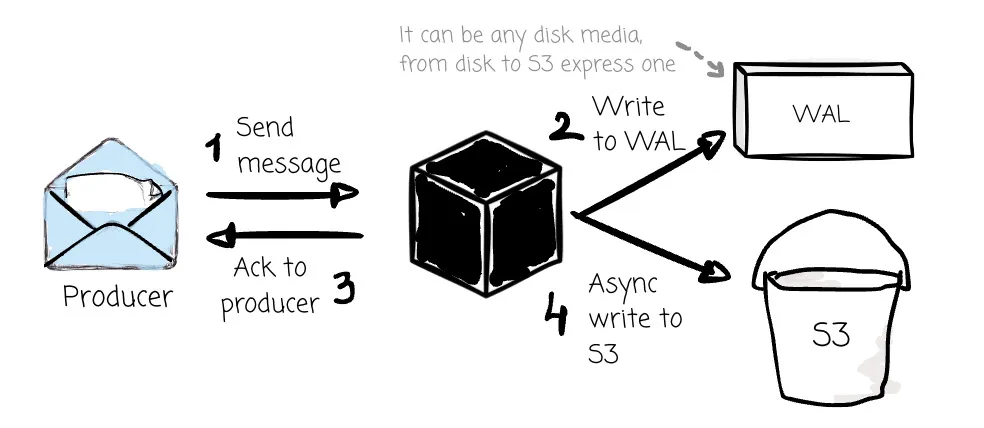
The idea is to use WAL to take advantage of the characteristics of different cloud storage media, which can be freely combined with S3 to adapt to various scenarios. For example:
-
With EBS, WAL is optimal for low latency. However, customers are still charged for cross-AZ data transfer when producers send messages to leader partitions.
-
With S3 WAL (AutoMQ treats S3 like WAL besides the primary storage), users can completely remove the cross-AZ cost, but the latency is increased in return.
IOPS
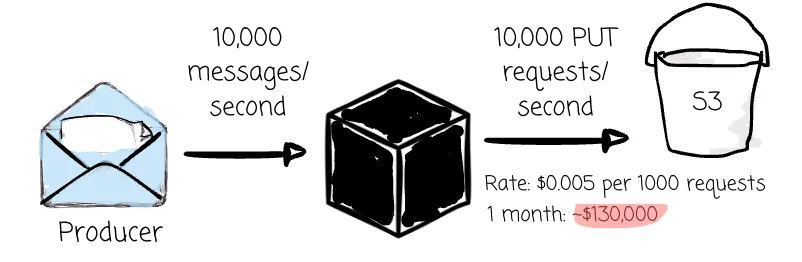
Related to the latency is the frequency of data writing to object storage. S3 Standard PUT requests are $0.005 per 1000 requests. A service with 10,000 writes per second would cost $130,000 per month.
If the brokers write the message to object storage right after they receive it from the producer, the number of PUT requests should be enormous.
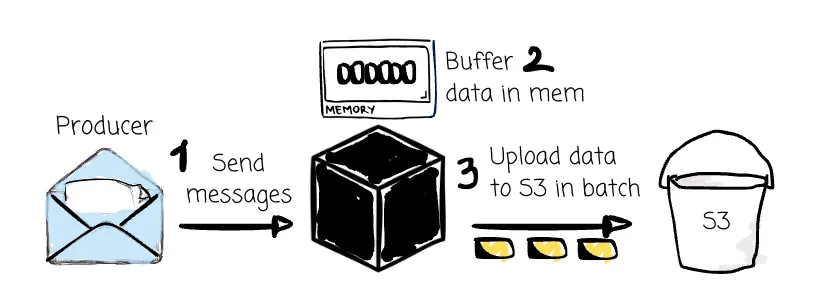
To reduce the number of requests to object storage, all vendors tell the brokers to batch the data before uploading it. They buffer the data for a while or until the accumulated data reaches a specific size. Users can choose to reduce the buffer time for lower latency, but in return, they have to pay more for PUT requests.
Those brokers can batch data from different topics/partitions to help reduce the cost of writing for a single partition. In the process of batching data in AutoMQ, it may generate two types of objects:
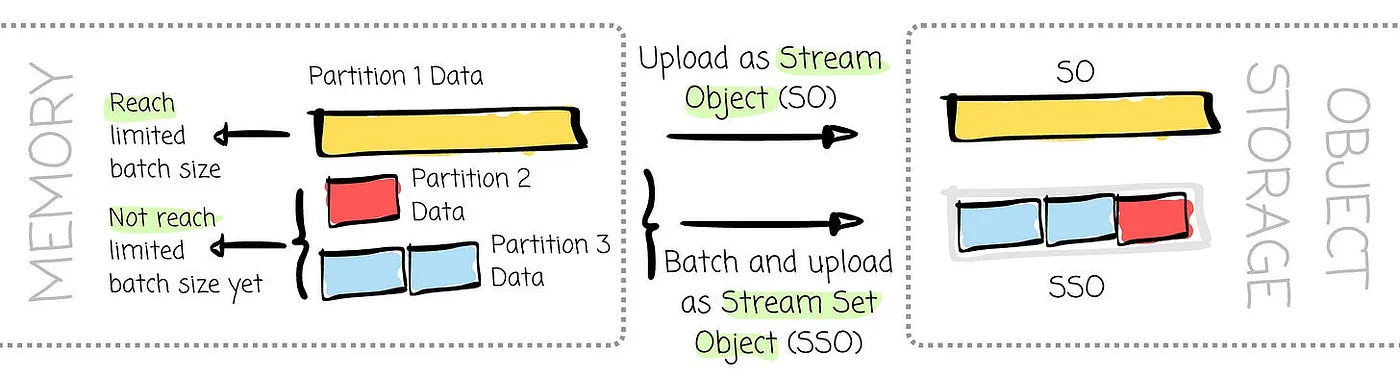
Stream Set Object (SSO): An object that contains consecutive data segments from different partitions
- Stream Object (SO): An object containing consecutive data segments from a single partition.
When writing the data in object storage, there are two scenarios:
-
Data from the same stream can fill up the batch size and will be uploaded as SO
-
Data from other partitions’ streams will be combined to meet the batch size, and the broker will upload it as the SSO.
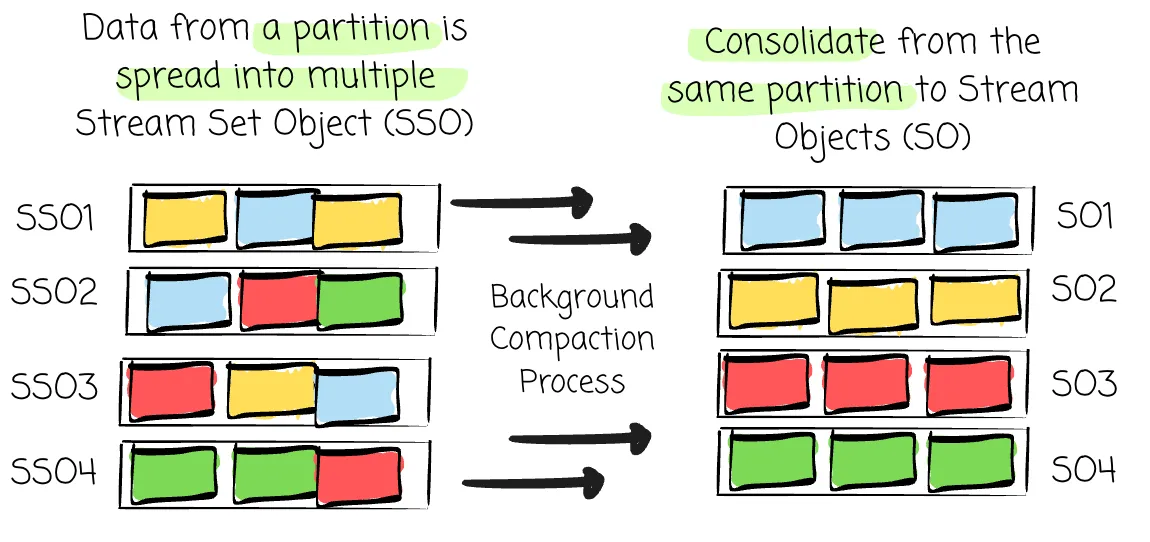
This does not reflect the actual implementation of the AutoMQ compaction process.
Thus, data from a partition can be spread into multiple objects, harming the read performance when the broker issues more requests. AutoMQ has a background compaction process that asynchronously consolidates data from the same partition onto the least possible number of objects to deal with this. This ensures that data within the same partition can be stored close together physically, enabling sequential reads from object storage.
Cache Management
Following up on the latency and the IOPS challenges above, the simplest way to improve the performance of reading data in object storage is to make fewer GET requests to object storage.
Data caching can help with that; it serves two purposes: improving the data read performance and limiting the requests to object storage. But this raises another question: How can a solution manage cache efficiently to improve the cache hit rate? (There are only two hard things in Computer Science: cache invalidation and naming things.)
WarpStream distributes loads across agents by using a consistent hashing ring. Each agent is responsible for a subset of data within a topic. When an agent receives a request from a client, the agent identifies who is in charge of the required file and routes the request accordingly.
AutoMQ tries to keep the “data locality” characteristic like Kafka, where brokers are still aware of the partition they are in charge of. Thus, cache management in AutoMQ can be implemented by letting brokers cache data from their managed partitions. (We will discuss the data locality later)
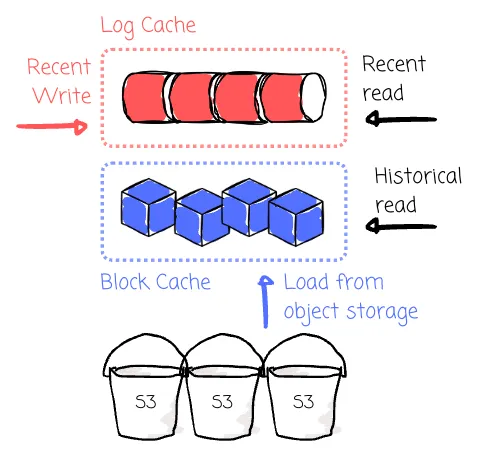
AutoMQ manages two distinct caches for different needs: the log cache handles writes and hot reads (recent data), and the block cache handles cold reads (historical data). When brokers receive messages from producers, besides writing data to WAL, brokers also write data to the log cache to serve recent reads.
If data isn’t available in the log cache, it will be read from the block cache instead. The block cache is filled by loading data from object storage. It improves the chances of hitting memory even for historical reads using techniques like prefetching and batch reading, which helps maintain performance during cold read operations.
Metadata Management
The systems built on object storage need more metadata than Kafka. For example, Kafka can scan the file system directory tree to list Segments under a Partition. The equivalent way to do this in S3 is to issue LIST requests, but unfortunately, these requests perform poorly. In addition, because of batching data, message ordering is not straightforward like in Kafka.
These new systems need more metadata to answer questions like “which objects hold this topic’s data?” or “how can I ensure the message ordering?”
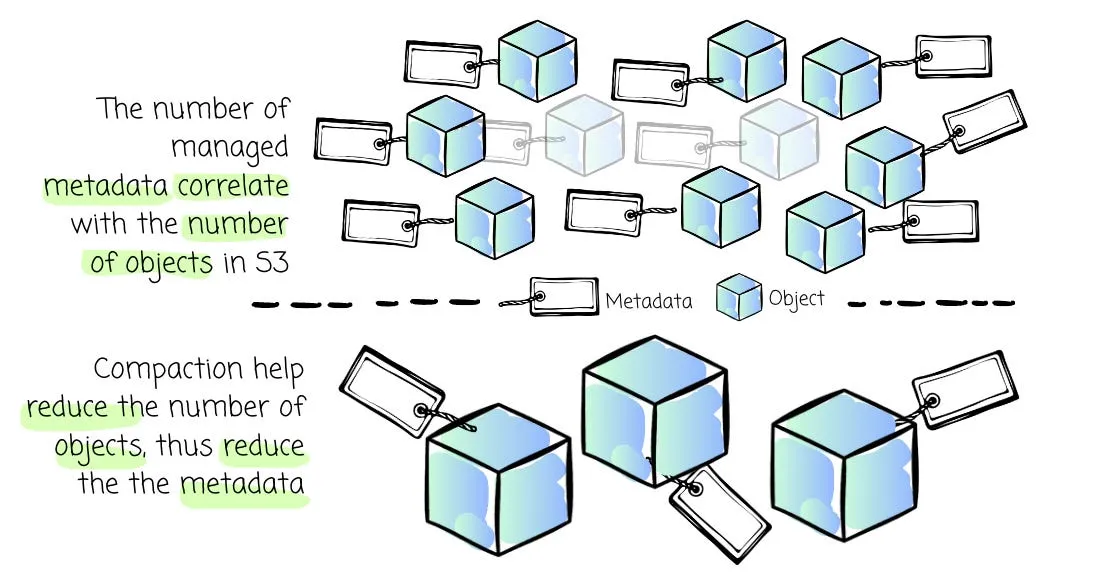
These metadata numbers correlate with the total number of objects stored in S3. To keep the number of metadata optimal, AutoMQ leverages the compaction technique from the IOPS section to combine multiple small objects into larger ones, thus limiting the amount of metadata.
In addition, Kafka uses ZooKeeper or Kraft to store cluster metadata such as broker registrations or topic configurations. WarpStream or Bufstream relies on a transactional database for this purpose.
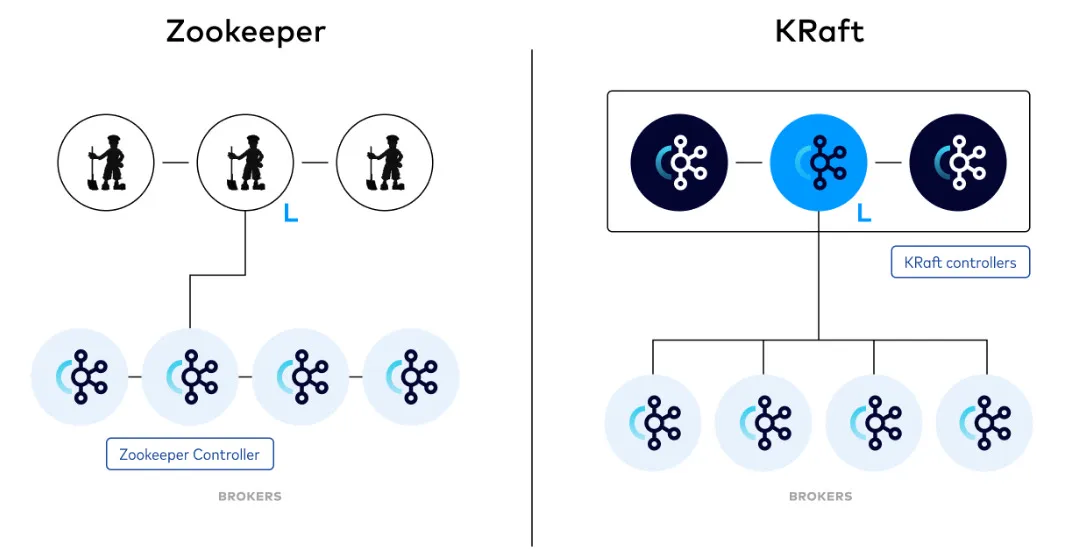
Zookeeper Mode vs Kraft Mode. Source
In contrast, AutoMQ leverages the Kraft. It also has a controller quorum that determines the controller leader. The cluster metadata, which includes mapping between topic/partition and data, mapping between partitions and brokers, etc., is stored in the leader. Only the leader can modify this metadata; if a broker wants to change it, it must communicate with the leader. The metadata is replicated to every broker; any change in the metadata is propagated to every broker by the controller.
Kafka Compatibility
Besides solving all the problems above, the Kafka alternative solution must provide a critical feature: the ability to let users switch from Kafka to their solution effortlessly. In other words, the new solution must be Kafka-compatible.
The Kafka protocol is centered around an essential technical design: it relies on local disks to store data. This includes appending messages to the physical logs, dividing the topic into partitions, replicating them among brokers, load balancing, asking for leader information to produce messages, serving consumers by locating the offset in the segment files, and more.
Thus, developing a Kafka-compatible solution using object storage is extremely challenging. Setting the performance aside, writing to object storage completely differs from how they write data to disk. We can’t open an immutable object and append data to the end as we do with the filesystem.
So, how could they provide a solution using object storage to replace a solution designed to work with local disks seamlessly?
Some (e.g., WarpStream, Bufstream) decided to rewrite the Kafka protocol from scratch to adapt to object storage. They believe this approach is more straightforward than leveraging the open-source Kafka protocol.
For AutoMQ, they think the opposite. They focus solely on answering how they could rewrite only Kafka’s storage layer to reuse the open-source protocol. Although the process might encounter many challenges, I think it is rewarding. They can confidently offer 100% Kafka compatibility to the user; if Kafka releases new features, they merge them into the AutoMQ source code. But how did they develop the new storage layer to work with the object store? Let’s first revisit the Kafka internal.
In Kafka, there are essential components:
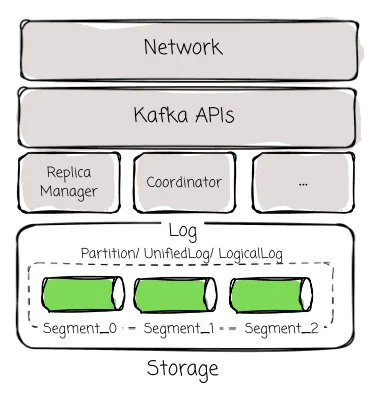
The network is responsible for managing connections to and from the Kafka Client
KafkaApis dispatches the request to specific modules based on the API key of the request
ReplicaManager is responsible for message sending and receiving and partition management; Coordinator is responsible for consumer management and transactional messages; Kraft is responsible for cluster metadata.
Storage : This module provides reliable data storage, providing the Partition abstraction to ReplicaManager, Coordinator, and Kraft. It is divided into multiple levels:
-
UnifiedLog ensures high-reliability data through ISR multi-replica replication.
-
LocalLog handles local data storage, offering an “infinite” stream storage abstraction.
-
LogSegment , the smallest storage unit in Kafka, splits LocalLog into data segments and maps them to corresponding physical files.
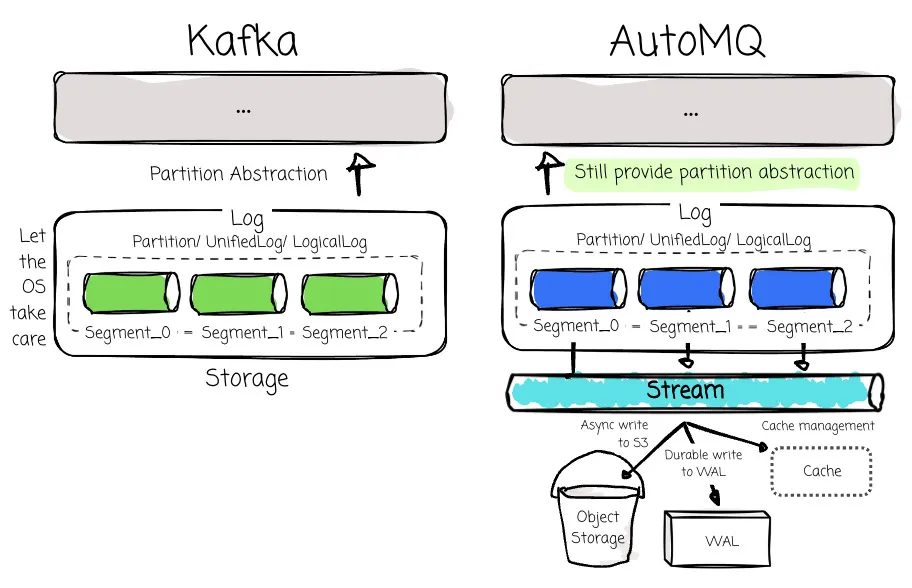
To ensure Kafka’s 100% Compatibility, AutoMQ reuses all the logic except for the storage layer. For the new implementation, AutoMQ has to ensure that it still provides the partition abstraction so other Kafka modules like ReplicaManager, Coordinator, or Kraft can smoothly integrate.
Although Kafka exposes a continuous stream abstraction through partitions, many operations must be performed using the segment concept, such as the internal compacting process, Kafka’s log recovery, transaction + timestamp indexing, or reading operations.
AutoMQ still uses segments like Kafka, but it introduces the Stream abstraction over the segments to facilitate data offloading to object storage. The stream’s core methods at the API level are appending and fetching a stream.
Compared to Kafka’s Log, it lacks indexing, transaction index, timestamp index, and compaction. To align with how Kafka organizes metadata and index, AutoMQ’s stream contains:
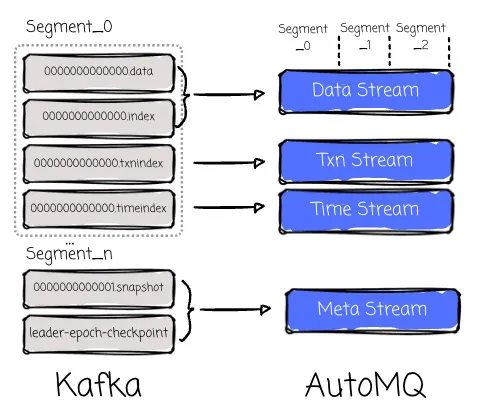
-
Meta stream provides a KV-like semantics to store metadata at the Partition level. Apache Kafka can scan the file system directory tree to list segments under a partition. In AutoMQ Kafka, Meta S3Stream uses ElasticLogMeta to record the Segment list and the mapping between Segments and Streams. This also helps avoid sending a LIST request to object storage.
-
Data stream mapping between stream and segment data. It already provides the capability to query data based on logical offsets. Thus, it can replace xxx. data and xxx.index in Kafka.
-
Txn/Time streams are equivalent to xxx. tnxindex and xxx. timeindex in Kafka
Unlike Kafka’s segment abstraction, which is limited to filesystem operations, a stream has more work to do, from caching messages, writing them to a write‑ahead log, to asynchronously offloading them to S3.
Convergence of Shared Nothing and Shared Disk
Both shared nothing and shared disk have advantages. The first has data locality that can serve writes and cache data more efficiently. The latter storage provides the efficiency of sharing data across different nodes. Theoretically, any broker can read and write any partitions when storing data in object storage.
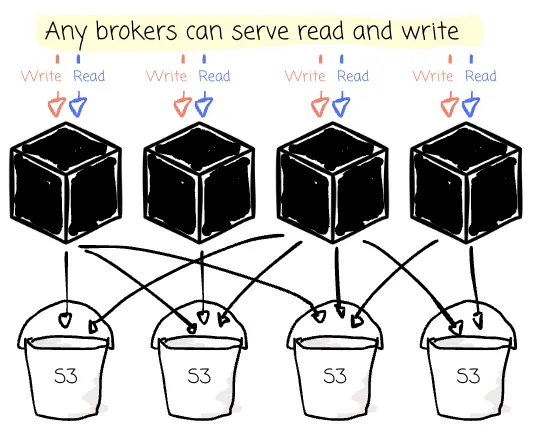
With Kafka’s initial shared-nothing design, partitions are bound to nodes. Read and write requests can only access the node with the assigned partitions. This is used to identify nodes to handle requests and to achieve load balancing. Thus, vendors must also consider data locality when building an alternative solution with shared disk architecture.
Warpstream, for example, bypasses the data locality for the write process; any agent in the same Availability Zone (AZ) as the client can serve the operations. When it comes to read requests, they must be served by the responsible agents. (mentioned from the Cache Management section)
Although AutoMQ is designed to store data completely in object storage, it still wants the brokers to know which partition they are responsible for. AutoMQ intends to keep the “data locality” characteristic, just like Kafka, where AutoMQ still assigns partition-specific brokers.
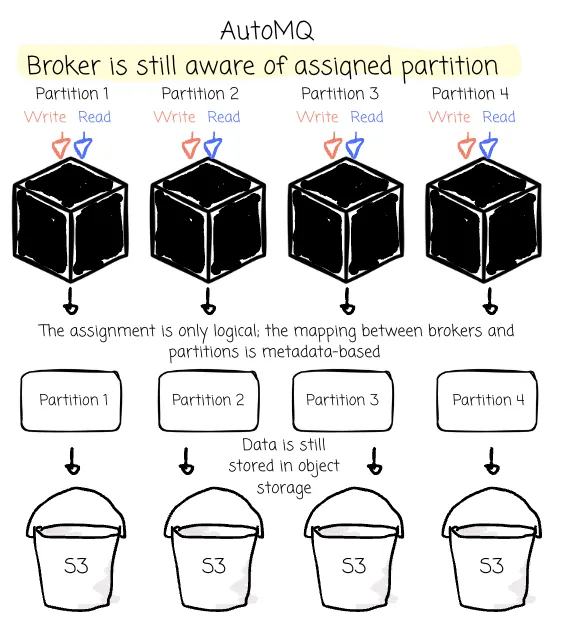
Throughput
A stateless broker has more things to do than a Kafka broker. In Kafka, the brokers let the OS systems handle all the storage aspects. But with a Kafka-compatible solution that runs on object storage, the broker must be responsible for buffering data in memory, uploading, compacting, or parsing data in object storage.
If not carefully designed, this can cause a lot of overhead for the broker. Compaction processes may affect regular write requests if these flows are not managed effectively.
In AutoMQ, there are the following types of network traffic:
-
Message Sending Traffic: Producer -> AutoMQ -> S3
-
Tail read Consumption Traffic: AutoMQ -> Consumer
-
Historical consumption traffic: S3 -> AutoMQ -> Consumer
-
Compaction read traffic: S3 -> AutoMQ
-
Compaction upload traffic: AutoMQ -> S3
To avoid different types of traffic competing with each other under limited bandwidth, AutoMQ has classified the above traffic types as follows:
-
Tier-0: Message-sending traffic
-
Tier-1: Catch-up read consumption traffic
-
Tier-2: Compaction read/write traffic
-
Tier-3: Chasing Read Consumption Traffic
AutoMQ implements an asynchronous multi-tier rate limiter based on the priority queue and the token bucket.
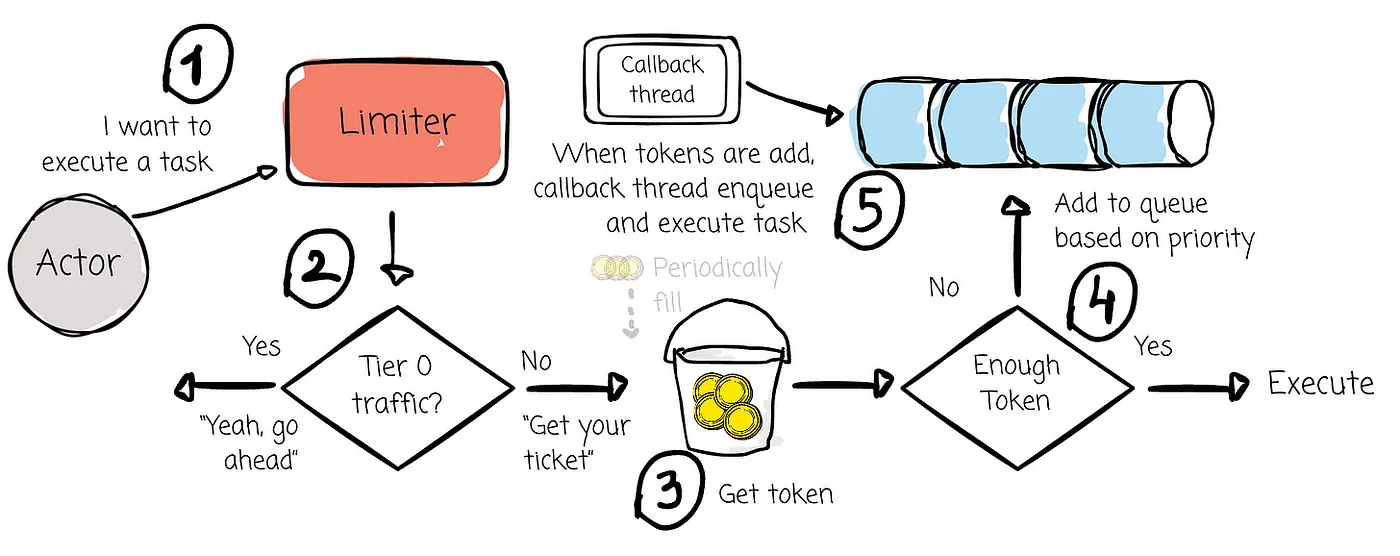
***Token Bucket:***A token bucket is a rate-limiting algorithm that periodically refills a “bucket” with tokens, each representing permission for a request to proceed. When the bucket is empty, requests are delayed or dropped to prevent system overload.
-
For Tier-0 requests, the rate limiter does not apply traffic control.
-
For Tier-1 to Tier-3 requests, if the available tokens are insufficient, they are placed into a priority queue based on their priority. When tokens are added to the token bucket periodically, the callback thread is awakened to attempt to fulfill the queued requests.
Cross-AZ traffic cost
As mentioned in the Background section, the original Kafka’s design can skyrocket your cross-AZ transfer fee billing due to two main reasons:
-
The producer could produce messages to the leader in different zones (1)
-
The leader must replicate the data to two followers in different zones (2)
With solutions built on S3, the point (2) could be resolved easily by letting the object storage take care of the data replication. For point (1), things got interesting.
Solutions like WarpStream and Bufstream tried to hack the Kafka service discovery protocol. Before the producer can send messages in Kafka, it must acquire the partition’s leader information by issuing a metadata request to a set of bootstrap servers. WarpStream or Bufstream will try to respond to metadata requests with the broker having the same availability zone as the producer, because to them, any brokers can serve message writing; there is no concept of “leader” here.
With AutoMQ, things got different because it still wants to maintain the data locality, like Kafka.
It introduced a solution where the WAL is implemented using S3 to eliminate cross-AZ data transfer costs. Imagine a scenario where the producer is in the AZ1, and the leader (B2) of Partition 2 (P2) is in the AZ2. In the AZ1, there is also a broker 1 (B1).
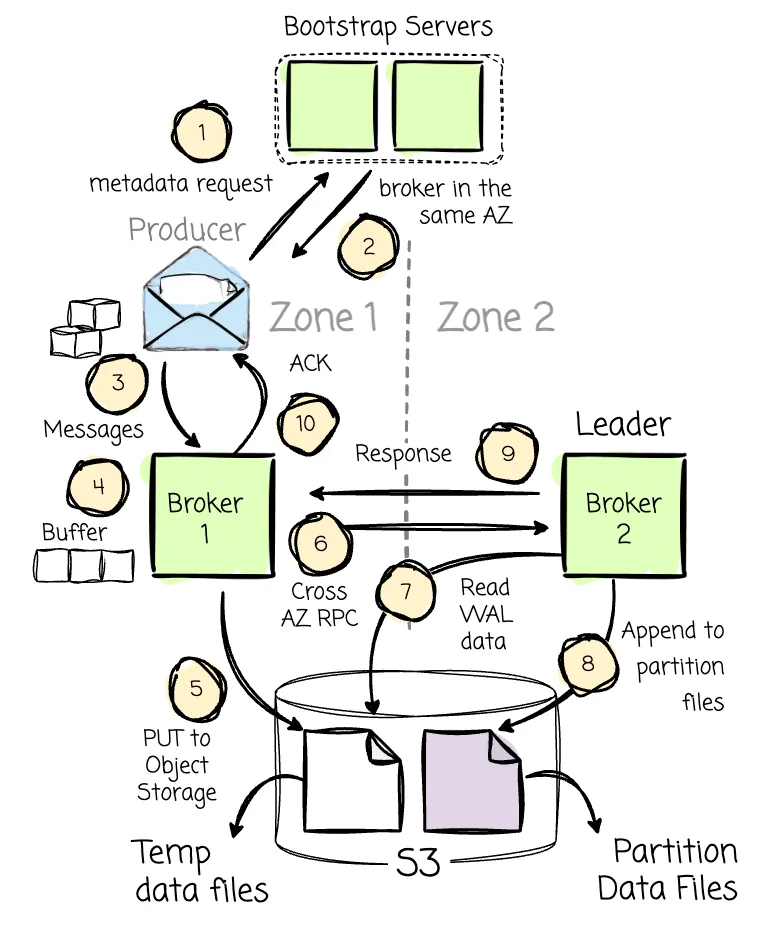
The producer still makes the metadata request, including producer zone information, to the set of bootstrap brokers. On the AutoMQ side, brokers are mapped across different AZs using a consistent hash algorithm. Let’s assume AutoMQ places B2 in AZ2 and B1 in AZ1. Since AutoMQ knows that the producer is in AZ1 (based on the metadata request), it will return the information of B1. If the producer is in the same AZ as B2, it will return the information of B2. The core idea is to ensure the producer always communicates with a broker in the same AZ.
After receiving the information about B1 (keep in mind that this broker isn’t responsible for the desired partition), the producer will begin sending messages to B1. This broker then buffers the messages in memory and asynchronously writes them into object storage as WAL data.
After successfully writing the messages to S3, B1 makes an RPC request to B2 (the actual leader of the partition) to inform it about the temporary data, including its location (this will result in a small amount of cross-AZ traffic between brokers in different AZs). B2 will then read this temporary data back and append it to the destination partition (P2). Once B2 has completed writing the data to the partition, it responds to B1, which finally sends an acknowledgment to the producer.
Outro
Thank you for reading this far.
We start this article with the trend of building Kafka-compatible solutions on top of object storage, and my curiosity about the challenges of building a system like that. We then discuss some dimensions worth mentioning, such as latency, IOPS, and Kafka compatibility. After identifying potential challenges in each dimension, we examine how AutoMQ tries to solve them.
A quick note is that I’m not a Kafka expert at all; I’m just really interested in the system and want to share my learning with the community. So, feel free to correct me.
See you next time!
References
[1] Tony Solomonik,The New Age of Data-Intensive Applications(2024)
[2] AutoMQDoc,Blog,Github Repo
[4] BufstreamDoc


