Architectural Differences
According to the design outlined in KIP-405, Apache Kafka’s tiered storage version adopts a two-tier storage approach, relying on both local disk and object storage. Message data is initially written to the local disk and then asynchronously uploaded to object storage based on a cooling-off strategy. Since local disks are susceptible to failure, each message needs to be replicated across multiple disks on different nodes via the ISR mechanism to ensure durability. Currently, when deploying the tiered storage version in a Public Cloud environment, Apache Kafka’s architecture remains unchanged, still using EBS as a replacement for local disks, requiring messages to be replicated across multiple EBS instances. In summary, Apache Kafka still treats EBS as a standard block storage device, with no fundamental difference from a physical hard drive in a local data center. AutoMQ employs object storage as its primary storage method, without the concept of storage tiers. However, to optimize storage efficiency, such as reducing latency for writing to object storage and improving write efficiency for large partitions, AutoMQ introduces a WAL storage mechanism. The architectural comparison is as follows: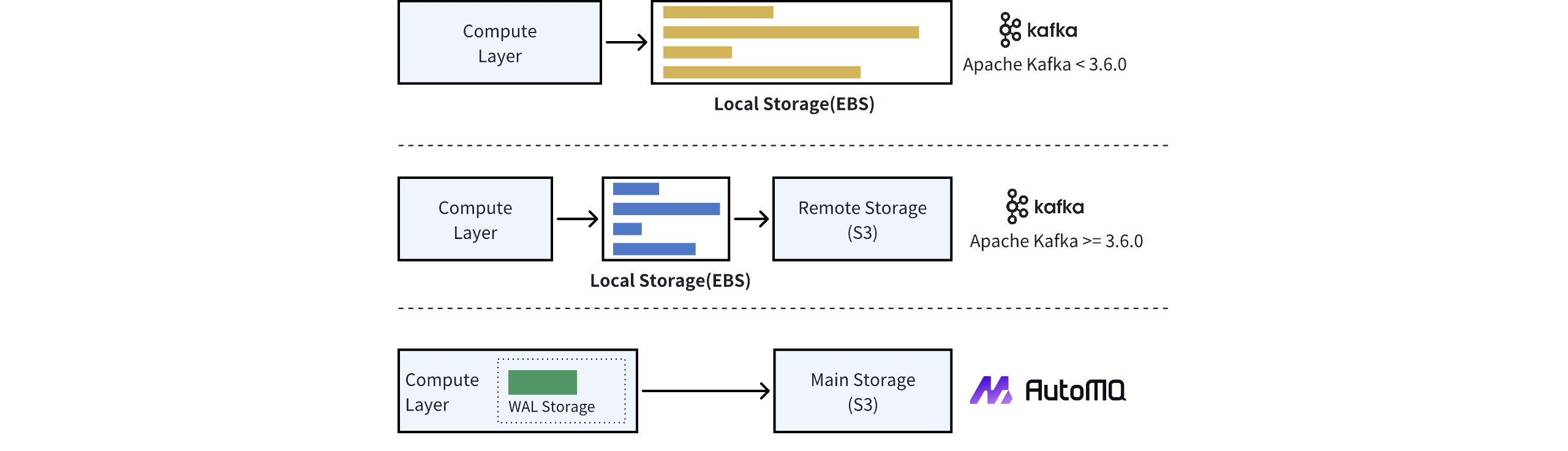
| - | WAL Storage | Kafka Tier 1 Storage |
|---|---|---|
| Responsibilities | Similar to a database Binlog, used for quick data persistence writes and data recovery during failures. | Core data storage, providing read, write, and replay functionalities. |
| Storage Efficiency | Centralized storage, mixing all partitions’ data into one WAL file or object, offering high write efficiency and low IOPS consumption. | Decentralized storage, where the system uses independent file lists to store data of each partition, resulting in low write efficiency and high IOPS consumption. |
| Storage Space | Occupies less space, around 10GiB, with deterministic storage needs. | Occupies large and uncertain space, requiring capacity assessment, with single nodes typically needing several hundred GiB. |
| Storage Medium | Can choose block storage, object storage, or file storage provided by cloud providers based on latency level and durability requirements. | Usually recommended to use local hard drives or block storage services provided by cloud vendors. |
| Durability Guarantee | Utilizing multiple replicas or EC (Erasure Coding) technologies in cloud storage services, data durability can generally reach reliability levels between 99.999% and 99.999999999%. | Apache Kafka’s ISR replica mechanism provides reliability but does not guarantee durability metrics. |
| Multi-AZ Disaster Recovery | Cloud providers offer regional EBS, object storage, and file storage (such as AWS EFS and FSx) with multi-AZ data durability, and they waive Inter-Zone replication traffic fees. | Using ISR to implement Inter-Zone data replication will incur Inter-Zone traffic replication fees. |
Cost Advantage
In Apache Kafka’s tiered storage architecture, the first tier of EBS storage is still used as the primary storage for read and write operations. Each Kafka partition must retain at least the latest active segment on the first tier storage. This leads to the following phenomenon:- EBS space is uncertain and directly related to the number of partitions in the cluster.
- Reserving a large EBS space in the production environment is necessary to reduce risks.
- EBS reservation costs are high, and the cost reduction potential through tiered storage is limited.
Example:Taking the default configuration of Apache Kafka® as an example, with each segment size set to 1GB, if the number of active partitions is 1000, it still requires reserving 1TB of EBS.
Operations Advantage
Due to the non-fixed primary storage space in Apache Kafka’s multi-tiered storage architecture, the data left on EBS for each partition is also non-fixed. Therefore, during operations like elastic scaling and fault reassignment, the time required is also uncertain, making quick scaling unachievable. While AutoMQ’s buffer only contains up to 500MB of data that needs to be uploaded to object storage, the upload can be completed within seconds, thereby supporting second-level partition reassignment.In the case of Confluent, an expansion operation on a high-traffic cluster takes 43 hours in a non-tiered storage architecture and still requires 1.4 hours in a tiered storage architecture.