本文中提及的 AZ 全称为 Available Zone,特指公有云环境中,云厂商提供的可用区(Zone)。 每个独立的 AZ 背后可能是独立的机房设施。
问题背景
Apache Kafka 跨 AZ 流量分析
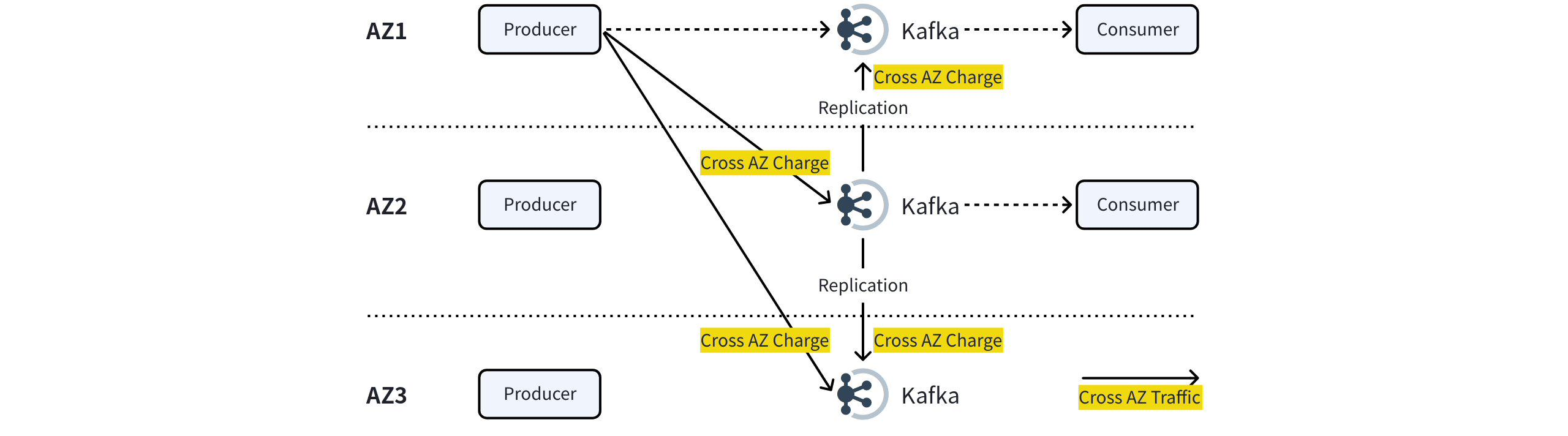
用户在 AWS、GCP 云环境中如果将 Apache Kafka 部署到多个 AZ,虽然可以实现多 AZ 服务容灾,但同时会带来跨 AZ 数据传输成本,大规模集群中流量成本可能占比达到 60-70% 。- 跨 AZ 生产流量 :假设 Producer 未设置 ShardingKey,并且分区在集群节点间均匀分布。那么至少有 2 / 3 的 Producer 流量会跨 AZ 发送,例如 AZ1 的 Producer 分别有 1 / 3 的流量发送到 AZ2 和 AZ3。
- 服务端跨 AZ 复制流量 :Kafka Broker 收到消息后为了保证数据的高可靠,会将数据复制到其他 AZ 的 Broker,产生 2 倍 Produce 的跨 AZ 流量。
- 跨 AZ 消费流量 :Consumer 可以通过设置 client.rack 来消费同 AZ 的分区/副本来避免产生跨 AZ 流量。
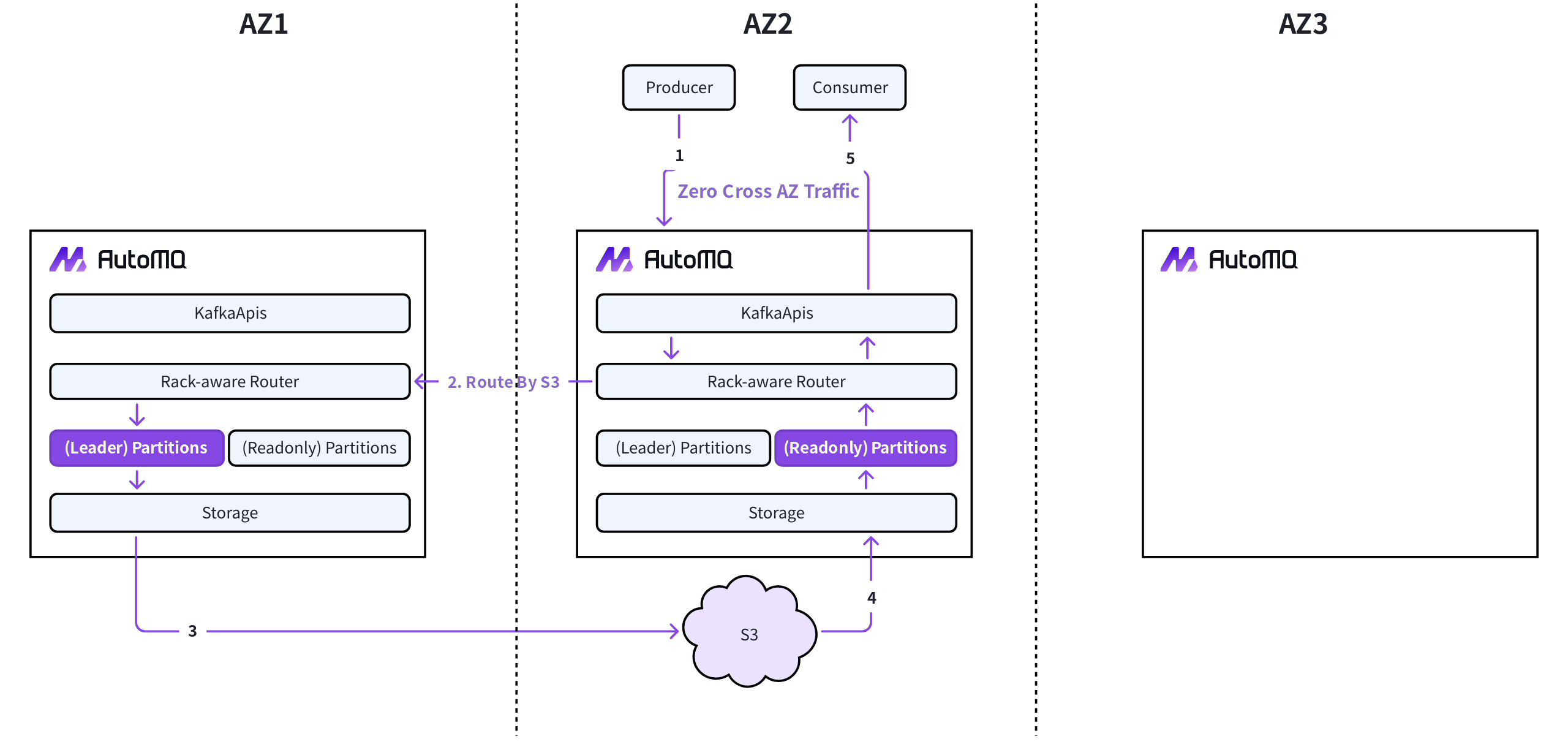
AutoMQ 消除跨可用区数据传输
AutoMQ 使用 S3 实现了存算分离架构,AutoMQ 基于 S3 实现了零跨可用区流量费用:- 生产流量:AutoMQ 内置 Proxy 层拦截和识别跨可用区的 Produce 请求,并基于 S3 构建跨可用区代理通道,将 Produce 请求代理转发到真正的分区 Leader。生产者只需要与同可用区的 Broker 节点通信,无跨可用区流量费用。
- 复制流量:AutoMQ 使用 S3 作为共享存储层,S3 会通过纠删码保在多可用区之间生成多副本,AutoMQ Broker 节点之间无 Apache Kafka 的复制流量。
- 消费流量:除了 Leader 分区外,AutoMQ 会在其他每个可用区生成一个只读分区。只读分区按需直接从 S3 读取 Leader 分区写入的数据。消费者只需要与同可用区的 Leader 分区或者只读分区通信,无跨可用区流量费用。