Apache Kafka and IBM MQ represent two distinct approaches to enterprise messaging. While both enable asynchronous communication between applications, they differ significantly in architecture, performance characteristics, and ideal use cases. This comprehensive comparison explores these differences to help organizations make informed decisions about which technology best suits their specific requirements.
Architecture and Core Concepts
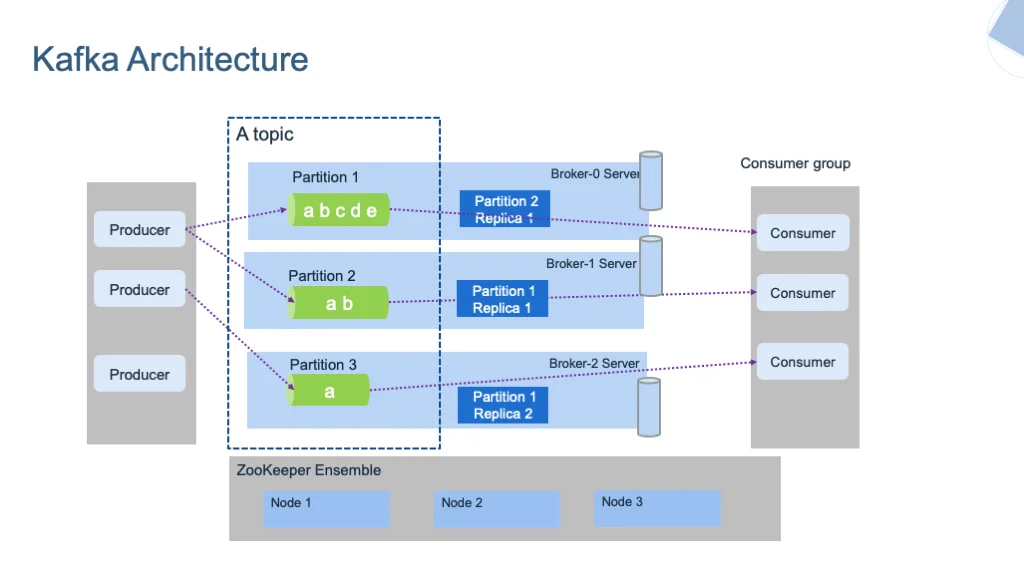
Apache Kafka Architecture
Kafka employs a distributed commit log architecture organized around topics and partitions. It stores messages in an immutable append-only log, allowing consumers to read at their own pace. Kafka's architecture consists of storage and compute layers with four core components: producer API, consumer API, streams, and connector APIs.
Topics are partitioned for data distribution and parallelism, with each partition stored on a single broker but replicated across multiple brokers for fault tolerance. Kafka uses a pull-based communication model where consumers request messages from brokers.
IBM MQ Architecture
IBM MQ is a traditional message queuing middleware using a store-and-forward approach. It relies on queue managers that act as containers for messaging resources. Messages are stored in queues until they are consumed, providing assured delivery mechanisms.
IBM MQ employs a push-based communication model where messages are sent directly to consumers once available. This architecture supports both point-to-point and publish/subscribe patterns, but with a focus on reliable message delivery rather than streaming.

Messaging Models and Capabilities
Message Handling Comparison
| Feature | Apache Kafka | IBM MQ |
|---|---|---|
| Messaging Model | Publish-subscribe with consumer groups | Point-to-point and publish-subscribe |
| Message Retention | Configurable time/size-based policies | Until consumed (queue-based) |
| Communication | Pull-based consumer model | Push-based delivery |
| Message Ordering | Guaranteed within partitions only | FIFO within queues |
| Transaction Support | Since 0.11 with some limitations | Full ACID compliance |
| Message Size Limit | Default 1MB, configurable | Up to 100MB standard |
Kafka stores messages on disk with configurable retention periods, allowing multiple consumers to read the same messages repeatedly. Messages remain available even after consumption until the retention period expires. In contrast, IBM MQ typically removes messages after they are consumed, though messages can be retained if specifically configured.
For message ordering, Kafka guarantees ordering only within a single partition, while IBM MQ maintains FIFO ordering within each queue. IBM MQ provides stronger transaction support with full ACID compliance, while Kafka introduced transaction capabilities in version 0.11 with some limitations.
Performance and Scalability
Performance Metrics
| Metric | Apache Kafka | IBM MQ |
|---|---|---|
| Maximum Throughput | 1-2 million msgs/sec per broker | 5,000-50,000 msgs/sec per queue manager |
| Latency at Low Volume | 5-10 ms | < 1 ms |
| Latency at High Volume | 10-50 ms | 5-20 ms |
| Scalability Approach | Horizontal via partitioning | Vertical with clustering options |
| Performance Degradation | Minimal with proper partitioning | More significant without clustering |
Kafka excels in high-throughput scenarios, capable of processing millions of messages per second through horizontal scaling. Its performance degrades minimally as scale increases, provided proper partitioning is implemented.
IBM MQ provides lower latency for small volumes but doesn't scale as efficiently for extremely high throughput workloads. It typically uses vertical scaling (larger machines) rather than Kafka's horizontal approach, though clustering options are available.
Scaling Strategies
Kafka scales horizontally by adding partitions and brokers. Each partition is the unit of parallelism, allowing throughput to scale linearly with additional brokers. Kafka's architecture is designed for distributed systems where storage needs grow over time.
IBM MQ traditionally scales vertically by adding resources to existing servers, though clustering can provide some horizontal scaling capability. Its performance is optimized for reliability rather than maximum throughput.
Security and Reliability
Security Features
Kafka provides security through SSL/TLS, SASL authentication, and ACL-based authorization. However, IBM MQ offers more granular security features including TLS, channel authentication, and Advanced Message Security for encryption.
Reliability Mechanisms
Both technologies offer high availability but through different approaches. Kafka relies on distributed replication across multiple brokers, while IBM MQ uses high availability pairs and clustering.
IBM MQ shines in reliable message delivery with guaranteed once-only delivery semantics, making it preferred for financial transactions and other mission-critical systems. Kafka provides good reliability with replication but focuses more on throughput than guaranteed delivery.
Implementation Considerations
Deployment and Operations
| Factor | Apache Kafka | IBM MQ |
|---|---|---|
| Deployment Complexity | Moderate to complex | Complex for full features |
| Learning Curve | Steep for advanced features | Moderate with enterprise background |
| Operational Cost | Low to moderate (open source core) | Typically higher (commercial license) |
| Enterprise Support | Available through Confluent, others | Enterprise-grade IBM support |
| Licensing Model | Apache 2.0 (open source) | Commercial with various options |
| Maintenance Requirements | Regular rebalancing, monitoring | Lower, requires specialized knowledge |
Kafka deployment involves setting up and configuring multiple components including brokers, ZooKeeper (for traditional deployments), and managing topics and partitions. IBM MQ requires setting up queue managers, configuring channels, and establishing connectivity between systems.
Operational considerations differ significantly, with Kafka requiring regular monitoring and rebalancing of partitions, while IBM MQ requires less frequent maintenance but specialized knowledge.
Configuration Best Practices
For Kafka, key performance tuning parameters include:
-
num.network.threadsandnum.io.threadsfor controlling broker request handling -
socket.send.buffer.bytesandsocket.receive.buffer.bytesfor network optimization -
Partition count planning for throughput and parallelism
-
Segment size configuration for tiered storage (512MB recommended for performance)
For IBM MQ, important configuration aspects include:
-
Queue depth monitoring to prevent bottlenecks
-
Resource utilization tracking (CPU, memory, disk I/O)
-
Message persistence configuration balancing reliability vs. performance
-
Channel and listener settings for network connectivity
Use Cases and Best Fit
Optimal Use Case Comparison
| Use Case | Apache Kafka | IBM MQ | Best Choice |
|---|---|---|---|
| High-throughput Event Streaming | Excellent | Good | Kafka |
| Mission-critical Transactions | Good with configuration | Excellent | IBM MQ |
| Real-time Analytics | Excellent | Limited | Kafka |
| Log Aggregation | Excellent | Limited | Kafka |
| IoT Data Processing | Very good | Good | Kafka |
| Financial Transactions | Good | Excellent | IBM MQ |
| Enterprise Application Integration | Good | Excellent | IBM MQ |
| Microservices Communication | Very good | Very good | Depends on requirements |
When to Choose Kafka
Kafka is the preferred choice for:
-
Real-time data streaming and event sourcing applications
-
Big data architectures and analytics platforms
-
High-volume log aggregation systems
-
Applications where throughput is prioritized over guaranteed delivery
-
Scenarios where event replay capability is important
When to Choose IBM MQ
IBM MQ is better suited for:
-
Mission-critical transactional systems requiring guaranteed delivery
-
Financial services and other regulated industries
-
Complex enterprise application integration scenarios
-
Applications that cannot tolerate message loss
-
Systems requiring strong security and compliance features
Commercial and Alternative Offerings
Confluent Kafka
Confluent, founded by Kafka's creators, offers a managed Kafka service with additional proprietary features including Schema Registry and ksqlDB. Confluent Kafka provides:
-
Cloud-native design for easier deployment and scaling
-
Simplified operations and monitoring
-
Extensive documentation and expert support
Redpanda
Redpanda is a Kafka-compatible alternative designed to eliminate the complexity of Kafka's distributed architecture. It offers:
-
Single-binary deployment with minimal resources
-
Kafka API compatibility
-
Optimized for low-latency workloads
IBM MQ Offerings
IBM provides multiple MQ deployment options:
-
On-premise installations
-
Containerized deployments
-
Cloud-based offerings (IBM MQ on Cloud)
-
IBM MQ Appliance for dedicated hardware implementations
Apache Kafka and IBM MQ serve different primary use cases despite some overlapping functionality. Kafka excels in high-throughput scenarios for real-time data streaming, analytics, and event sourcing where horizontal scalability is paramount. IBM MQ shines in enterprise integration scenarios requiring guaranteed delivery, strong transaction support, and robust security features.
The choice between these technologies should be driven by specific requirements around throughput, reliability, message handling needs, and existing infrastructure. Many organizations implement both technologies to address different use cases within their enterprise architecture.
Understanding the fundamental architectural differences—Kafka's distributed commit log versus IBM MQ's message queuing approach—provides the foundation for making appropriate technology choices that align with business objectives and technical requirements.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


