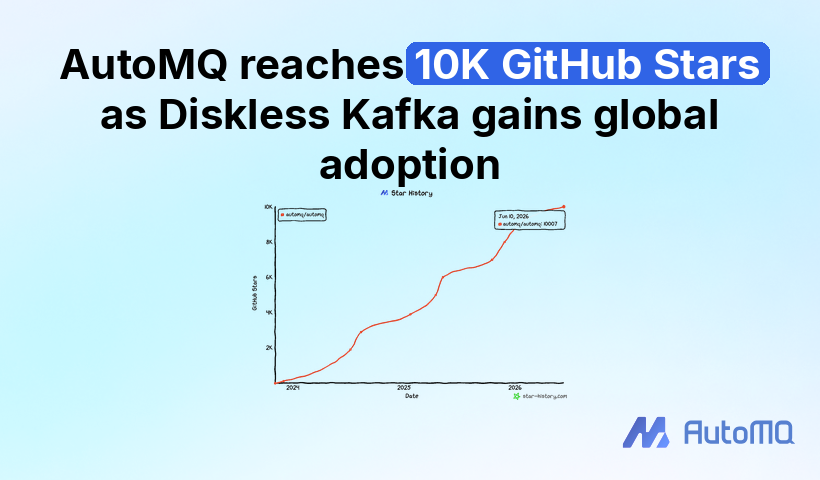
In June 2026, the AutoMQ open-source repository passed 10K GitHub Stars. This is a milestone we are happy to share, and we are grateful to every developer and user who watched the project, tried a deployment, opened an issue, joined a discussion, or gave us direct feedback.
For infrastructure software, GitHub Stars usually arrive after some homework. Developers read the design, run a demo, check issues, or compare the project with systems they already operate. Platform teams are even more cautious: before a Kafka implementation enters evaluation, it has to answer compatibility, reliability, migration, and operations. Many of these stars came after that kind of engineering attention.
AutoMQ's first public GitHub release, v0.6.6, was published in November 2023. From that release, developers could read and run a working Diskless Kafka implementation. The direction was clear: keep Kafka's protocol, semantics, and ecosystem, while moving durable stream storage away from broker-local disks and into object storage and shared storage. AutoMQ has been one of the earliest public open-source implementations of this direction, and we have kept validating it through production work since then.
The star chart is only the visible part. Around it, Hacker News readers asked hard engineering questions, the Apache Kafka community discussed shared storage through KIP-1183, customers tested AutoMQ in production, and more Kafka teams started asking whether durable data still belongs on broker-local disks.
A Diskless Kafka Pioneer, Tested in the Open
Many developers first encountered AutoMQ on Hacker News. In April 2024, AutoMQ was posted as Show HN: AutoMQ - A Cost-Effective Kafka Distro That Can Autoscale in Seconds, and the post reached the Hacker News front page. For an infrastructure project that had been open for only a few months, that was a memorable moment.
On Hacker News, the thread moved quickly from the headline to the design. Developers asked about standard Kafka client compatibility, write acknowledgement, WAL recovery, benchmark data, and whether AutoMQ would still behave like Kafka from an application point of view. Those questions went straight to the design premise behind AutoMQ: durable data can move from broker-local disks into shared storage while preserving the Kafka behavior applications depend on.
The next step was to bring those engineering details into the Kafka community. AutoMQ's work on shared storage, cloud-native elasticity, and Kafka compatibility gave us implementation experience to share alongside the proposal.
In 2025, AutoMQ contributed KIP-1183: Unified Shared Storage. The proposal discusses how Kafka could support a unified shared storage layer across object storage, file storage, and block storage. The motivation matches the architecture AutoMQ has been implementing and validating in production: keep Kafka's mature protocol and ecosystem, while letting the storage layer use the durability, elastic capacity, and pay-as-you-go model of cloud infrastructure.
At Confluent Current London in 2025, those discussions continued in person. We brought AutoMQ's open-source implementation, KIP-1183, production experience, and the engineering choices behind low-latency Diskless Kafka to the conference.
During the event, we discussed AutoMQ's architecture with Kafka engineering teams from IBM, Apple, OpenAI, and others. The conversations were specific: durable data on shared storage, Kafka client and tooling compatibility, broker recovery, scaling without heavy partition data movement, and latency. We received strong technical feedback on AutoMQ's low-latency Diskless Kafka design. We also heard something broader: teams that have operated Kafka for years are actively looking at how Kafka should evolve for cloud infrastructure and AI-era real-time data workloads.

AutoMQ's Diskless Kafka Direction
AutoMQ's technical direction is getting attention because it touches a real Kafka operations problem: broker-local storage is becoming expensive and slow to manage under cloud and AI-era workloads.
Kafka's protocol, semantics, and ecosystem are still the reason teams choose Kafka. The pressure is in the storage model, especially where durable data lives. The Hacker News questions, KIP-1183 discussion, and London conversations all came back to that placement decision. If Kafka is going to keep serving cloud and AI-era real-time workloads, should durable data stay bound to individual brokers?
Traditional Kafka's shared-nothing architecture made sense in the data center era. Each broker managed its own local disk. Partition data was replicated through ISR across multiple brokers. Reliability came from application-level replicas. In that environment, copying data between machines usually did not show up as a separate cloud-networking line item, and binding compute and storage to the same physical server was a straightforward engineering choice.
In the cloud, those assumptions change. Cloud infrastructure already provides durability, cross-zone redundancy, elastic capacity, and pay-as-you-go storage services. When Kafka continues to run as if broker-local disks are the durable home of partition data, teams often pay for duplicated work:
- At the storage layer, cloud disks already provide durability, while traditional Kafka still replicates the same partition data across multiple brokers.
- At the network layer, cross-zone broker replication can create continuous cross-AZ traffic cost.
- At the operations layer, scaling compute also means moving large amounts of partition data, and rebalancing can last for hours.
- At the resource layer, compute, storage, and network remain tied to broker identity, making it difficult to scale one resource independently.
AutoMQ's Diskless architecture places durable data in shared storage and makes brokers stateless compute nodes, while keeping Kafka's protocol, semantics, and ecosystem. When a broker fails or the cluster scales, the system mainly changes metadata and traffic ownership. It no longer needs to move large amounts of partition data for every capacity change.
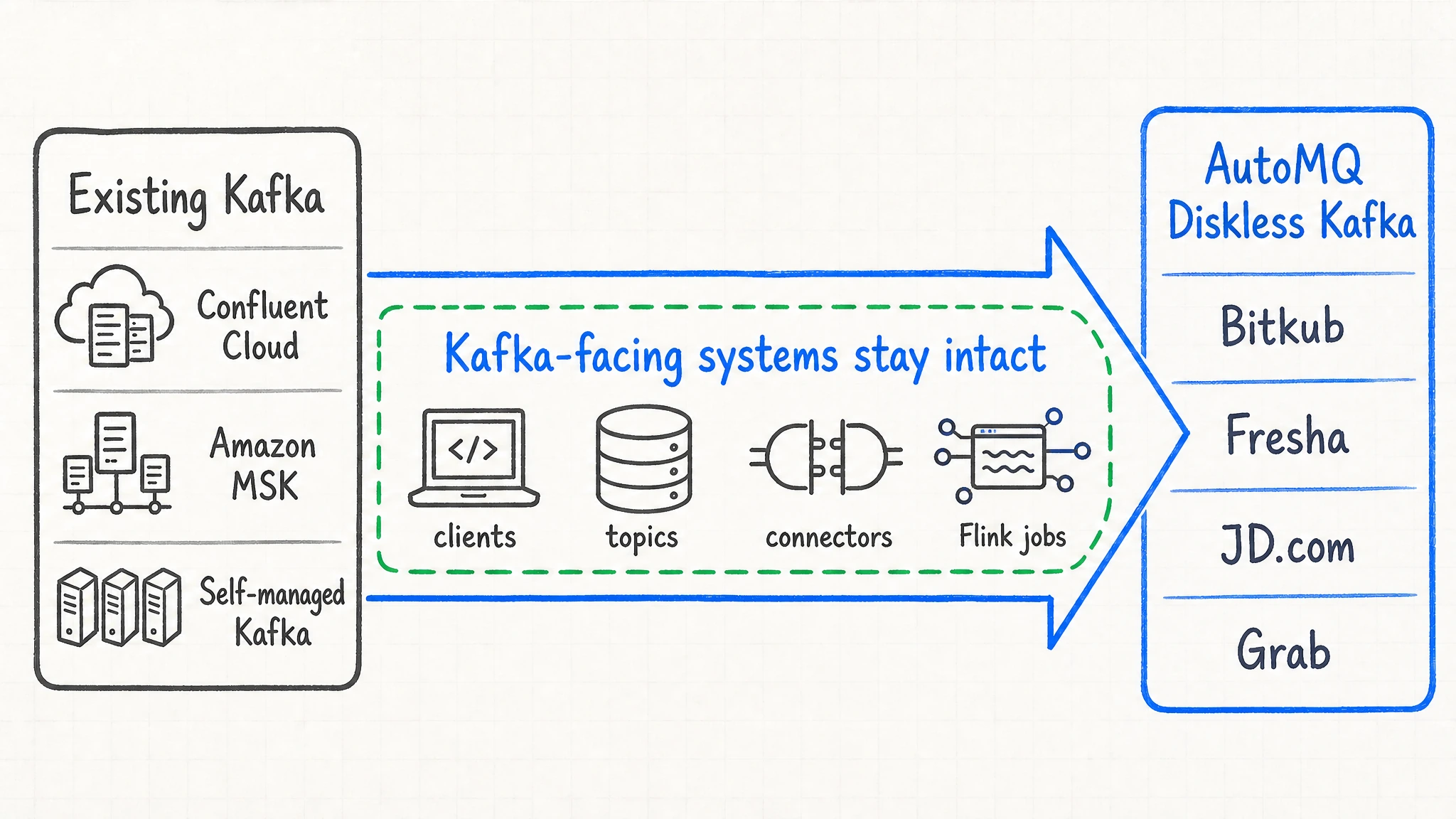
For teams already running Kafka, an architecture upgrade cannot require application code and surrounding systems to start over. AutoMQ is built from the Apache Kafka codebase. It keeps Kafka protocol semantics and client ecosystem at the access layer, while replacing traditional local LogSegment storage with S3Stream and shared object storage at the storage layer. Clients, connectors, Flink jobs, Schema Registry, and existing operational habits can continue to work.
Continuous Technical Innovation and Production Adoption
Some of AutoMQ's earliest public customer stories came from specialized, demanding Kafka workloads where the old operating model was already getting in the way. POIZON put AutoMQ into an observability platform dealing with petabytes of trace data and large traffic peaks. JD.com's JDQ platform had a different shape: a Kafka-based real-time data bus for more than 1,400 business lines, already running with Kubernetes and CubeFS, where broker-local storage created duplicate durability work and made scaling expensive to operate. These public cases tested the implementation under real traffic: Kafka compatibility, WAL behavior, S3Stream storage, partition reassignment, failure recovery, and observability.
Once those systems were running, the value showed up in normal operations. Broker changes caused less data movement. Object storage changed the storage cost model. Stateless brokers made compute capacity easier to adjust. Kafka compatibility kept producers, consumers, Flink jobs, connectors, and operational habits in place. For operations teams, the difference is easy to understand: fewer changes require careful partition data movement.
Later public cases showed a broader migration pattern. Teams were not trying to replace Kafka at the application boundary. They wanted Kafka clients, topics, consumer groups, connectors, Flink jobs, and operational habits to keep working. The change was lower in the stack: move durable data off broker-local disks, use shared object storage, and make brokers stateless enough that capacity changes no longer depend on heavy partition movement.
Bitkub and Fresha are two clear public examples of that shift. Bitkub Blockchain Technology moved from Confluent Cloud to AutoMQ for its AWS-based blockchain payment infrastructure. Fresha moved a CDC warehouse workload from Amazon MSK to AutoMQ. Different starting points, same direction: teams kept Kafka-facing systems intact while moving the storage model toward Diskless Kafka. Other public stories, including Grab, Tencent Cloud EMR, and FunPlus, show the same architecture entering high-volume streaming, cloud service integration, and gaming observability.
This is also why open source and public engineering writing matter. AutoMQ has been pushing Diskless Kafka through working code and production engineering practice: publishing code, explaining seconds-level partition reassignment, documenting S3Stream and WAL design, and showing how Kafka compatibility is preserved. Fresha's Anton Borisov described that kind of transparency in developer terms:
With AutoMQ, we can trace how the system works, why certain choices were made, and where it can improve. That transparency: messy, evolving, but real is what keeps progress visible.
That’s why I have a soft spot for AutoMQ as they don’t just build the future, they open it up for everyone to build together, yet continuing pushing the frontier with new ideas and features.
— Anton Borisov, Fresha
Fresha's later production write-up, AutoMQ in Production: Auto-Magically Quitting MSK, then shows the same evaluation path reaching production: Diskless Kafka running since the end of February 2026, approximately 150 Kafka Connectors migrated in a matter of days with AutoMQ Linking, and about 50% lower total monthly cost for that CDC warehouse cluster, from roughly $3,200 to $1,600 including the subscription cost.
What Comes Next
Thank you to everyone who has starred AutoMQ, tried it, opened issues, contributed code, shared feedback, or put AutoMQ into a real production evaluation.
10K GitHub Stars is a milestone. We will celebrate it, and then go back to the everyday work: writing code, fixing issues, improving documentation, supporting customers, and discussing Kafka's next step in the cloud with the community.
AutoMQ will keep working on the direction that brought us here: Kafka compatibility, open-source transparency, and low-latency Diskless Kafka. We will continue reducing the burden created by broker-local disks and large data movement when companies run critical Kafka workloads in the cloud. As real-time analytics, lakehouse systems, and AI applications put new pressure on streaming data, we will also keep building around Table Topic so Kafka data can move more directly into Apache Iceberg and modern data infrastructure.
A star chart is easy to draw. The work behind it is slower: people read code, try clusters, open issues, test migration paths, validate production behavior, and send feedback back to the community. We are grateful for every one of those decisions.
If you are evaluating Kafka cloud migration, cost optimization, or elastic scaling, start with the AutoMQ open-source repository. Read the code, run a test environment, and validate whether Diskless Kafka fits your production workload: View AutoMQ on GitHub.


