Introduction
AutoMQ is a next-generation Diskless Kafka built on S3, offering full compatibility with the Kafka protocol. Its cloud-native architecture significantly enhances operational efficiency through decoupled storage and compute and on-demand elasticity. The most critical breakthrough is its utilization of shared storage to eliminate expensive cross-AZ data transfer fees, which can save multi-AZ clusters thousands to tens of thousands of dollars in monthly networking costs.
While maintaining exceptional cost-effectiveness, the December 2025 release of AutoMQ officially introduced support for AWS FSx as a WAL storage option to further overcome the latency limitations of Diskless architectures. This evolution allows AutoMQ to deliver millisecond-level latency—comparable to local disks—while retaining zero cross-AZ traffic costs and multi-AZ disaster recovery capabilities, achieving a perfect balance between low cost, high reliability, and extreme performance.
To validate these architectural advantages in real-world conditions, we conducted a series of performance benchmarks focused on end-to-end client-observed latency.
For the official announcement of AutoMQ’s FSxN capabilities, please refer to the article: AutoMQ x FSx: 10ms Latency Diskless Kafka on AWS
For a detailed technical deep dive into the implementation principles of AutoMQ FSxN, please refer to the article: How does AutoMQ implement a sub-10ms latency Diskless Kafka?
Test Scenarios and Results
To interpret the benchmark results, we must first break down the components of latency:
Components of Latency
From a business perspective, latency primarily stems from two sources: Kafka client queuing latency and server-side processing latency. In the following sections, we isolate these two components so that the impact of AutoMQ’s FSxN design on each can be clearly understood.
Server-side Processing Latency
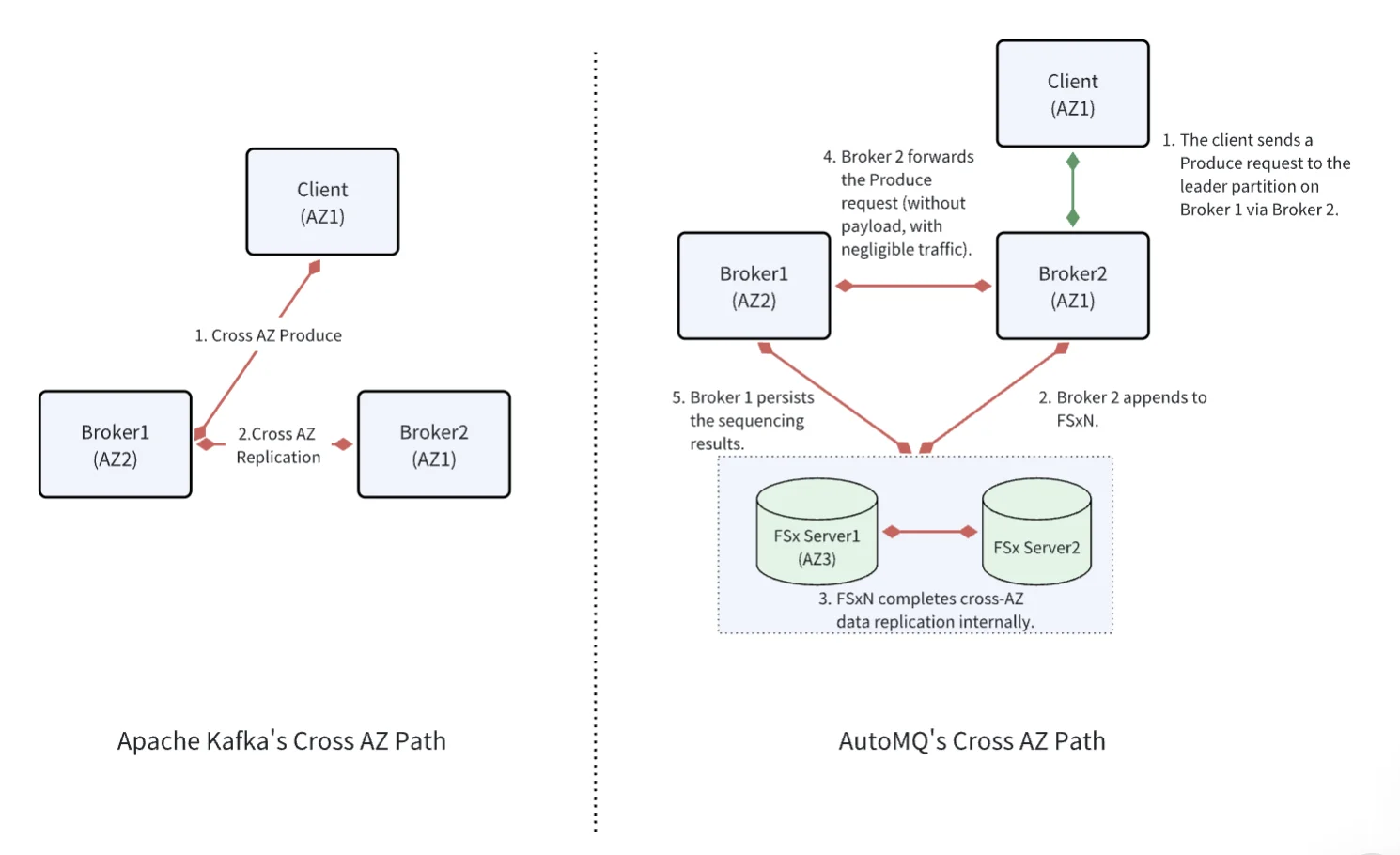
In traditional Kafka architectures, server-side latency overhead is primarily consumed by: cross-AZ communication between clients and services, and the cross-AZ replication process (ACK=ALL). Both types of cross-AZ communication involve direct RPC requests, which incur substantial data transfer costs on AWS.
AutoMQ introduces a fundamental architectural shift: it uses AWS FSx as a shared WAL layer to eliminate replica replication traffic entirely, and leverages FSx as a relay for cross-AZ client–server requests. This design trades a small, tightly bounded increase in processing latency for an order-of-magnitude reduction in cross-AZ networking costs.
Client-side Queuing Latency
Kafka producers utilize a two-stage "batch-then-send" design: first, messages are accumulated in memory by partition. Once they reach the batch.size threshold or the linger.ms timeout, the batch is placed into a ready queue for transmission. The network layer then retrieves these batches from the queue and dispatches them to the server within defined concurrency limits.
In scenarios demanding extreme throughput, developers often increase linger.ms to proactively encourage larger batches. However, this causes requests to queue at the client-side, resulting in higher end-to-end latency from a business perspective. Typically, l inger.ms and batch.size are the primary levers to balance the trade-off between throughput and latency, and they are exactly the knobs we will tune in the following test scenarios. For a detailed deep dive, refer to our previous article: Kafka Performance Tuning: Best Practice for linger.ms and batch.size
Test Scenario Selection
To comprehensively and objectively evaluate AutoMQ's performance with the introduction of AWS FSxN and provide high-value data for real-world applications, we have defined our test scenarios across two dimensions: the Extreme Performance Baseline and the Production Steady-state Model (Robustness).
Extreme Performance Baseline: Server-side Latency Physical Limit Test
In distributed systems, client-side queuing mechanisms often mask the true I/O response of the storage medium. Therefore, we first conducted tests under low concurrency with linger.ms=0 to create an ideal "zero-queuing" environment.
- Test Objective: By isolating client-side interference, we aim to directly measure the core server-side processing latency and network relay overhead of AutoMQ combined with FSxN WAL, establishing the physical performance boundaries of this architecture.
Production Steady-state Model: Deterministic Latency Test Under High Throughput
In real-world production environments, traffic bursts, producer scaling, and uneven partition loads are the norm. To balance throughput and cost, developers typically optimize batching via linger.ms and batch.size .
- Test Objective: We selected typical production configurations (e.g.,
linger.ms=3) and simulated a cluster running at full capacity. This scenario is designed to verify whether AutoMQ can provide highly deterministic latency under real business pressure and to observe tail latency performance (P99/P999) during high-frequency small-packet writes (High TPS).
Together, these two scenarios bracket the realistic performance envelope of AutoMQ with FSxN—from the physical lower bound of server-side latency to the steady-state behavior under production-grade load.
By comparing these two dimensions, we can demonstrate not only the "explosive" performance of this solution in ideal states but also its stability as core infrastructure in complex production environments.
Detailed Testing
The test environment is configured as follows:
-
Framework: OpenMessaging Benchmark, with a total write throughput of 300 MiB/s and a fanout ratio of 1:4.
-
Server: m7g.4xlarge *3;
-
WAL Storage: FSx 736MBps、1T SSD、3072IOPS;
-
Client: m7g.4xlarge *3;
-
Cluster Load: Operating at full capacity saturation.
Minimum Latency Scenario
To probe the system's physical performance limits, we established an ideal "zero-queuing" environment. We specifically tuned key parameters that directly impact latency:
-
batch.size=64K、linger.ms=0 (default). -
Compression disabled**:** Enabling compression typically reduces write throughput and can lead to lower write latency, which would make the test scenario less challenging.
The specific configurations are as follows:
name: Kafka
driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver
# Kafka client-specific configuration
replicationFactor: 1
topicConfig: |
min.insync.replicas=2
commonConfig: |
bootstrap.servers=10.0.0.112:9092
producerConfig: |
acks=1
batch.size=65536
client.id=automq_type=producer&automq_az=us-east-1b
consumerConfig: |
auto.offset.reset=earliest
enable.auto.commit=true
client.id=automq_type=consumer&automq_az=us-east-1b-
Record Size: 64 KB
-
Write TPS: 4,800
-
Total Partitions: 96
-
Number of Producers: 48
The workload configuration is as follows:
name: Lowest latency case
topics: 1
partitionsPerTopic: 32
messageSize: 65536
payloadFile: "payload/payload-64Kb.data"
subscriptionsPerTopic: 4
consumerPerSubscription: 16
producersPerTopic: 16
producerRate: 1600
consumerBacklogSizeGB: 0Test Results
-
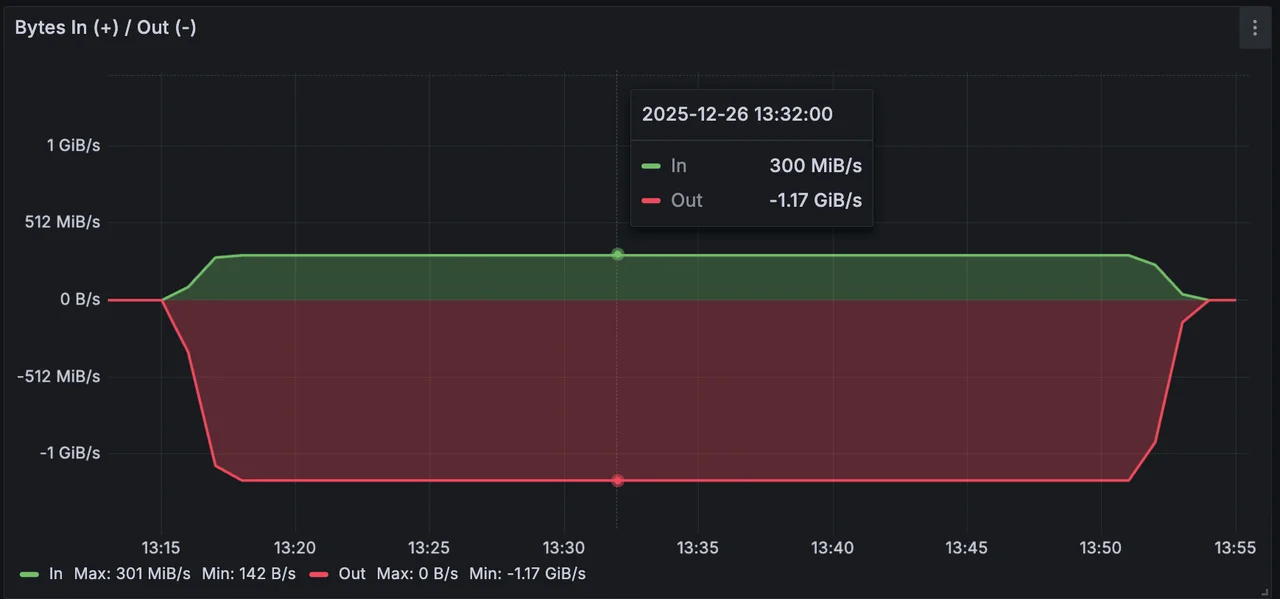
Total Write Throughput: 300 MiB/s
-
Total Read Throughput: Approximately 1.2 GiB/s
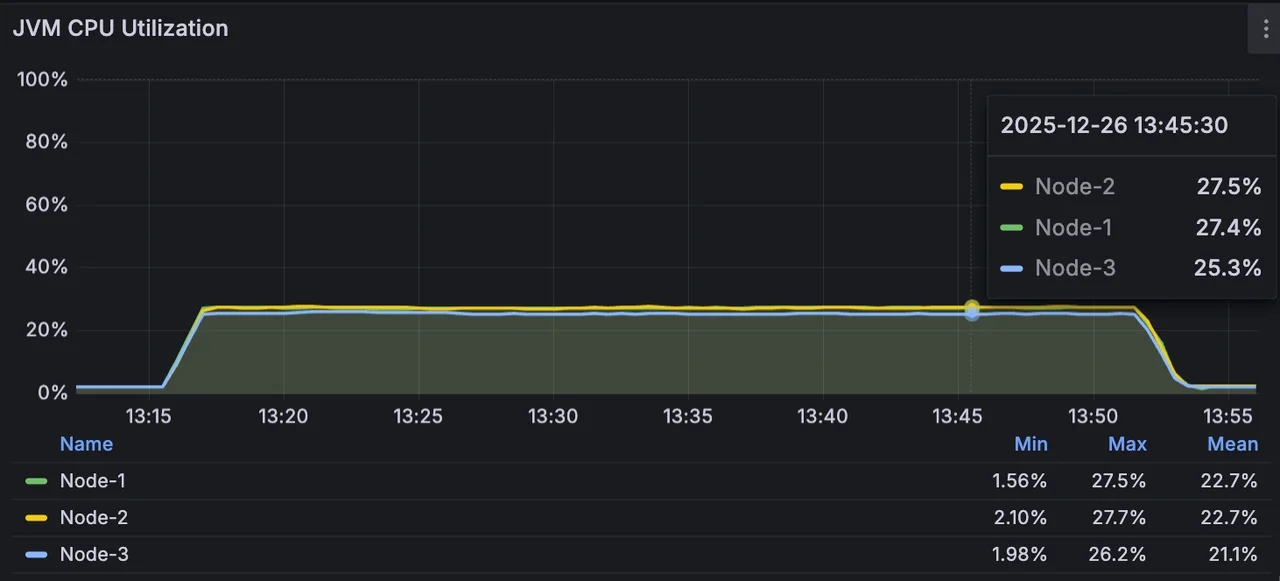
CPU utilization sits at approximately 27.5%, while the memory footprint remains around 10 GiB.
Average Write Latency: 6.0 ms; P99: 13.11 ms; P999: 17.68 ms.
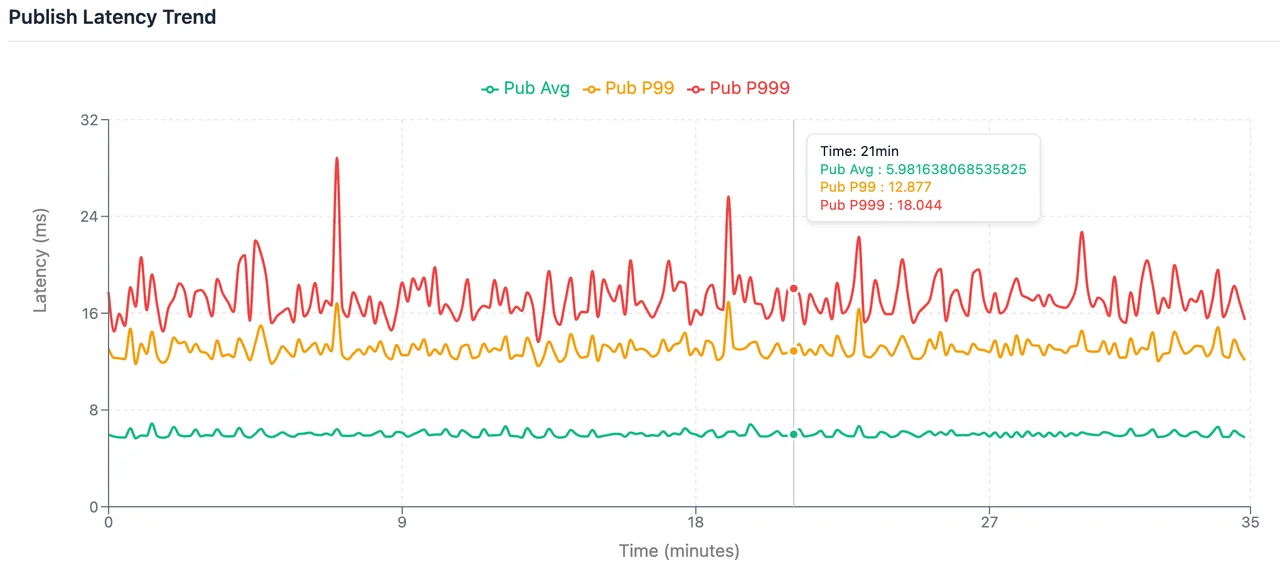
End-to-End Average Latency: 7.79 ms; P99: 19.0 ms; P999: 29.0 ms.
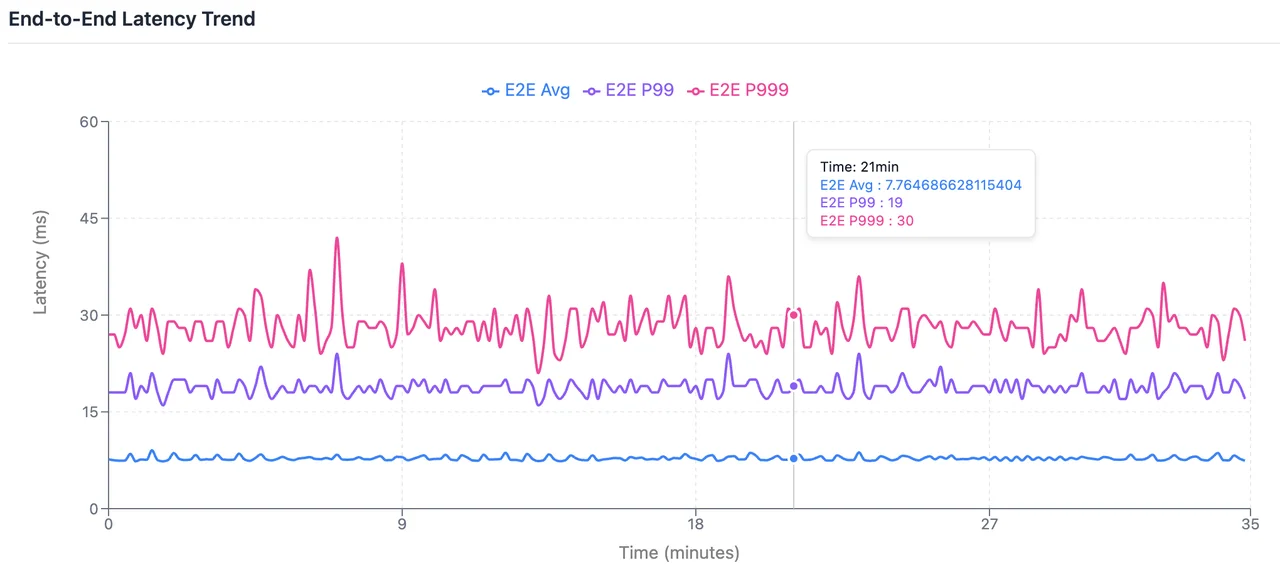
Setting linger.ms=0 disables batching delay. If the current number of in-flight requests remains within the maximum concurrency limit, messages are dispatched to the server immediately, minimizing client-side overhead. However, as business traffic fluctuates—with surges in throughput or TPS—concurrency constraints may trigger additional client-side queuing, ultimately impacting end-to-end latency.
Consequently, this scenario reflects latency under ideal conditions. While it yields the lowest possible figures, it is highly sensitive to traffic volatility and client scale, lacking the consistency required for stable production environments.
More Consistent Latency Scenario
Given the fluctuation risks inherent in the extreme performance scenario, how does AutoMQ perform in production environments that demand a balance between throughput and stability? Let's examine the steady-state test results with client-side batching enabled.
-
batch.size: 64K -
linger.ms: 3 (calibrated based on estimated server-side processing time to optimize batching efficiency)
The specific configurations are as follows:
name: Kafka
driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver
# Kafka client-specific configuration
replicationFactor: 1
topicConfig: |
min.insync.replicas=2
commonConfig: |
bootstrap.servers=10.0.0.112:9092
producerConfig: |
acks=1
linger.ms=3
batch.size=65536
client.id=automq_type=producer&automq_az=us-east-1b
consumerConfig: |
auto.offset.reset=earliest
enable.auto.commit=true
client.id=automq_type=consumer&automq_az=us-east-1bSmaller record sizes impose higher write overhead. To ensure the results are more broadly applicable to diverse real-world scenarios, we have reduced the record size for this test.
-
Record Size: 1 KB
-
Write TPS: 307,200
-
Total Partitions: 96
-
Producers: 15
The detailed workload configuration is as follows:
name: 1 Robust latency case
topics: 1
partitionsPerTopic: 32
messageSize: 1024
payloadFile: "payload/payload-1Kb.data"
subscriptionsPerTopic: 4
consumerPerSubscription: 5
producersPerTopic: 5
producerRate: 102400
consumerBacklogSizeGB: 0Test Results
-
Total Write Throughput: 300 MiB/s
-
Total Read Throughput: Approximately 1.2 GiB/s
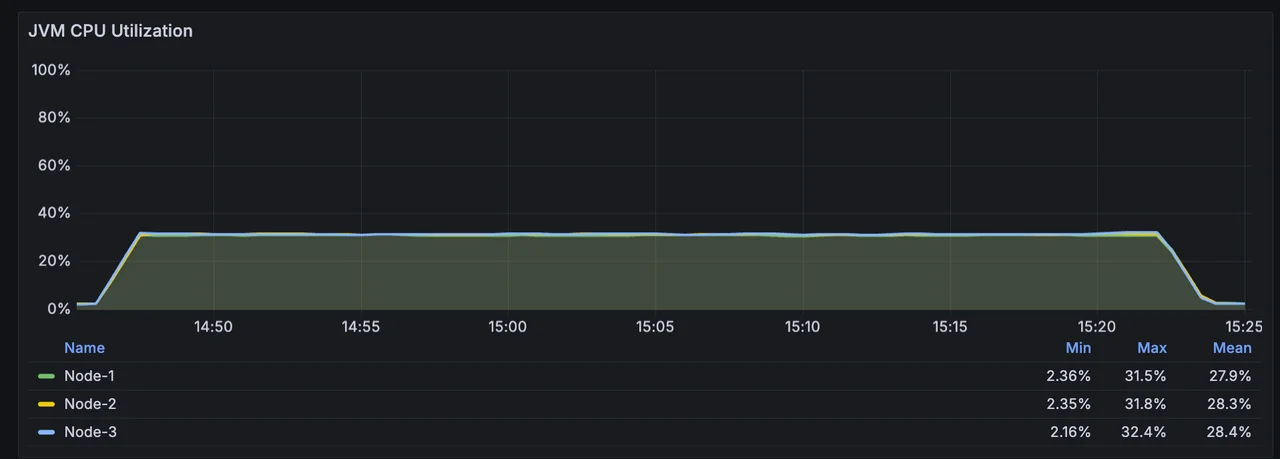
CPU utilization is approximately 31.5%, with memory occupancy at around 14 GiB.
Average Write Latency: 7.89 ms; P99: 16.30 ms; P999: 30.26 ms.
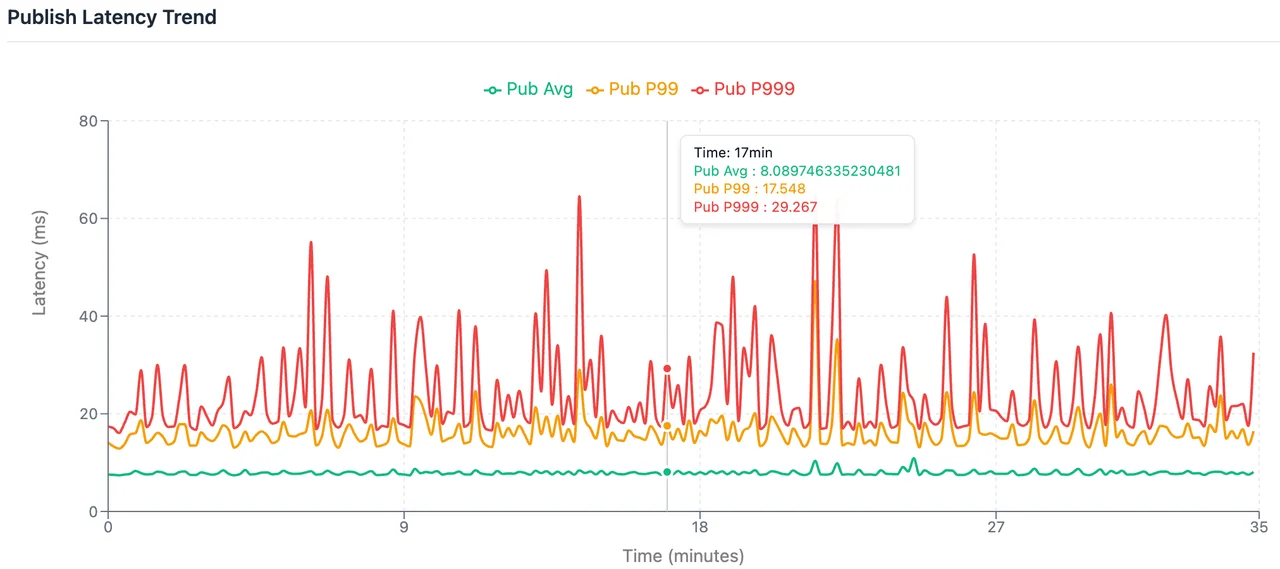
End-to-End Average Latency: 9.88 ms; P99: 22.0 ms; P999: 38.0 ms.
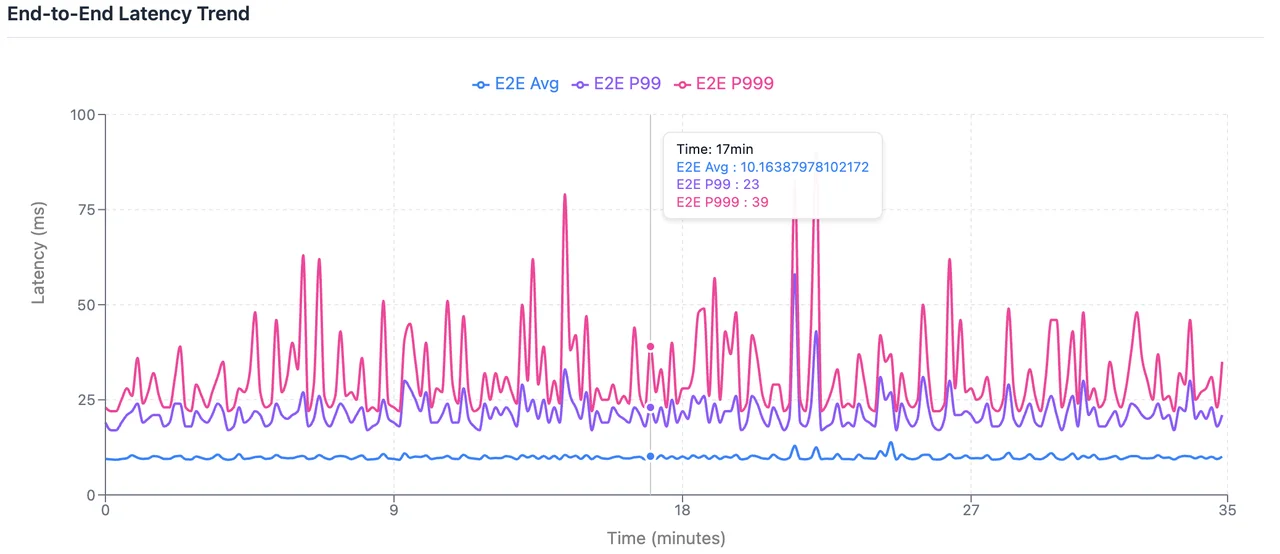
Increasing linger.ms=3 introduces marginal client-side latency but yields more consistent batching. This configuration better absorbs the impact of traffic spikes, troughs, and fluctuations in producer counts during cluster scaling, providing a more predictable latency profile that serves as a high-fidelity reference for production environments.
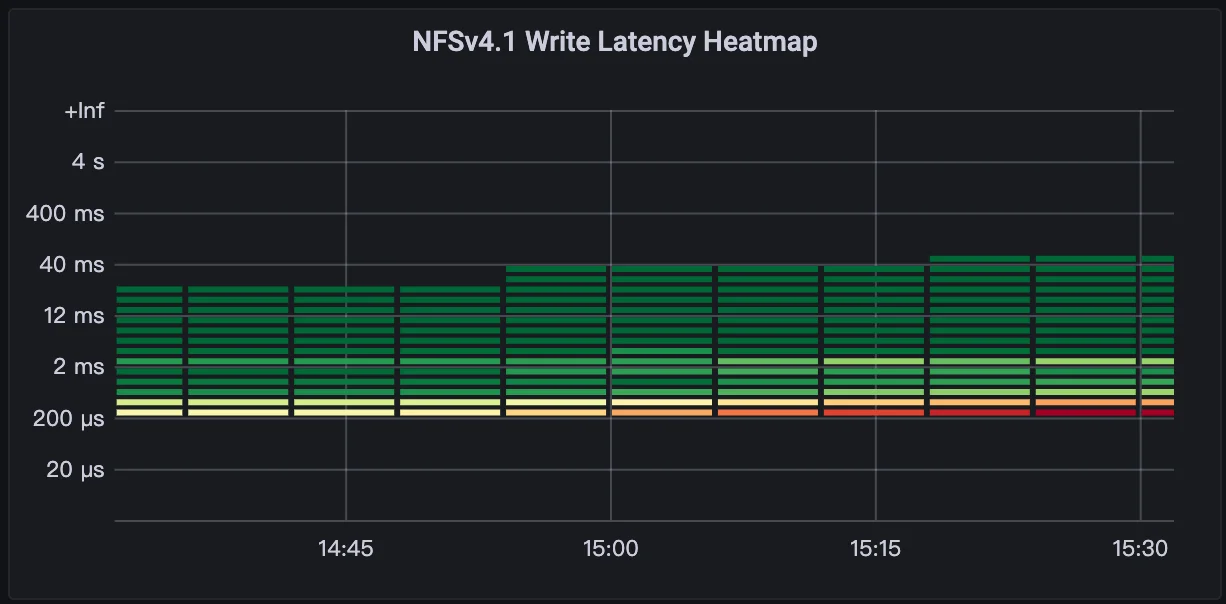
Furthermore, these tests were conducted under full cluster saturation, which presents a significant challenge for tail latency metrics like P99 and P999. AutoMQ has undergone extensive internal optimization to ensure highly stable file system performance.
According to the file system latency heatmaps, 90% of write responses are sub-millisecond, while 91% of reads also consistently clock in under 1ms.
Cost Analysis
After such a dramatic performance leap, it is natural to ask whether the price also skyrockets—but in fact, the opposite is true.
In AutoMQ's integrated architecture, FSxN is not designed for the long-term storage of massive datasets. Instead, it functions as a "high-speed staging area." It is responsible only for hosting a minimal amount of the most recent Write-Ahead Logs (WAL), while the bulk of business data remains stored in the ultra-low-cost S3.
Why the cost remains exceptionally low:
-
Fixed Scale and On-Demand Occupancy: Since data is rapidly offloaded (tiering) to S3 buckets, FSxN requires only a minimal and fixed capacity. Its cost does not scale linearly with the growth of total business data.
-
Elimination of Massive Traffic Fees: While integrating FSxN introduces a minor resource overhead, it completely eliminates the most expensive component of traditional Kafka: cross-AZ replication traffic fees.
-
99% of Data Resides in S3: The vast majority of data is stored in S3, which offers industry-leading cost efficiency.
This means that even with the performance boost provided by FSxN, AutoMQ’s Total Cost of Ownership remains nearly 90% lower than that of traditional Kafka.
For a detailed breakdown, please refer to: 👉 AutoMQ x FSx: 10ms Latency Diskless Kafka on AWS
Summary
By integrating FSxN as a WAL layer, AutoMQ preserves the core benefits of multi-AZ disaster recovery and S3-based storage-compute decoupling while dramatically slashing average write latency from hundreds of milliseconds to sub-10ms—a performance level comparable to local disks. This breakthrough effectively resolves the historical latency bottleneck of Diskless architectures, enabling them to support mission-critical, latency-sensitive workloads—such as microservices, risk management, and trade matching—with high stability and industry-leading cost-efficiency.


