
On January 2, 2026, Grafana published a post introducing Mimir's next-generation architecture: Mimir's next-gen architecture--Kafka in the middle, object storage underneath, and a whole lot less coupling. The title gives away the shape of the change: Kafka sits in the middle, object storage sits underneath, and Mimir components depend less tightly on one another.
Grafana starts from a classic architecture problem. In the older path, ingesters handle writes and recent-data queries at the same time. They keep freshly written samples and also serve the read path. When a heavy query saturates ingesters, the write path can be pulled into the same failure mode.
Mimir 3.0's recommended ingest storage architecture moves the write boundary to Kafka. Grafana's documentation puts it plainly: the write path ends at Kafka.
In that flow, distributors no longer push samples directly to ingesters. They write to Kafka or Kafka-compatible ingest storage. After Kafka confirms that the data is durable, Mimir can acknowledge the write to the client. Ingesters then consume samples from Kafka partitions and make them available to the read path.
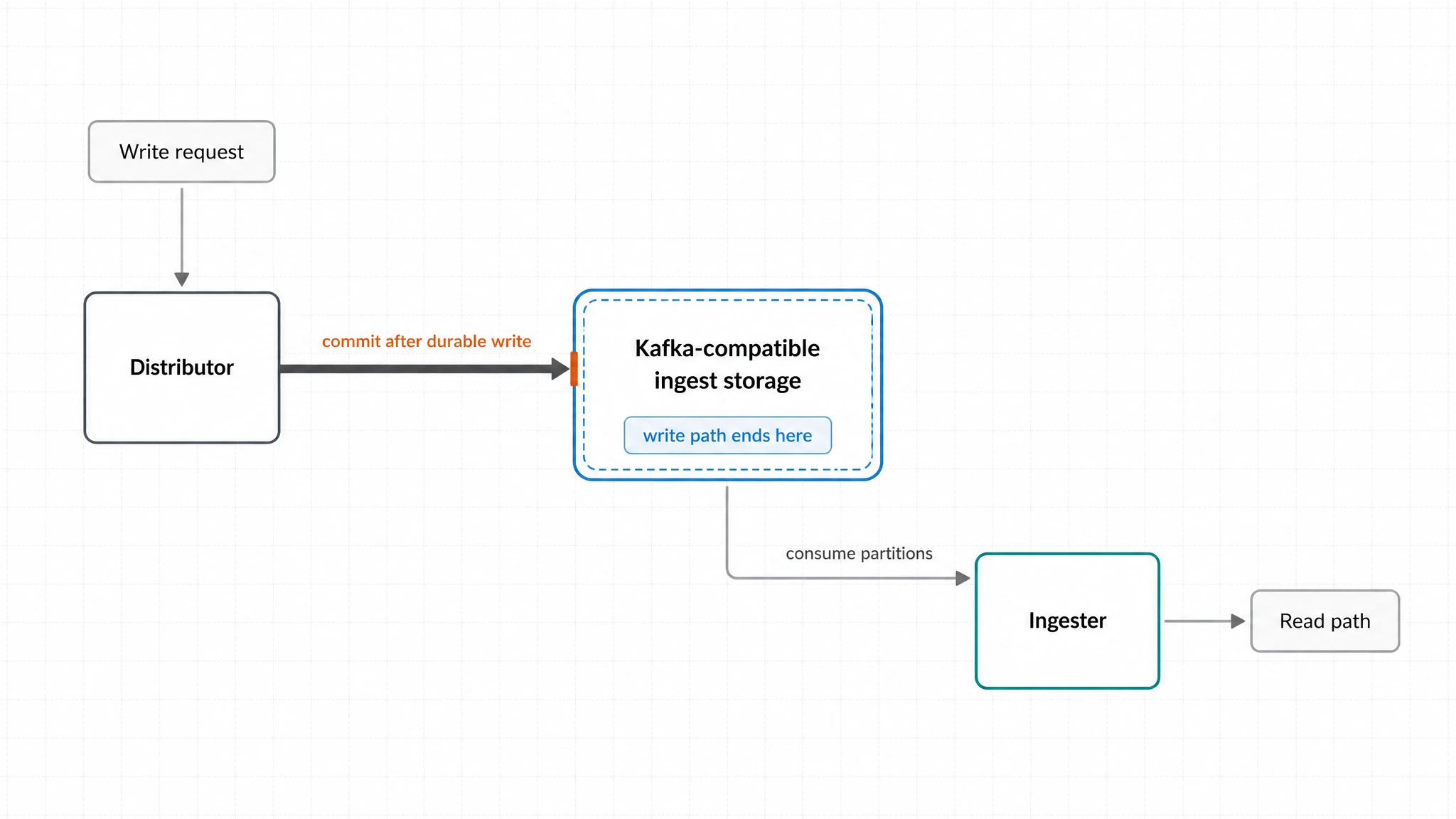
Kafka therefore becomes the commit boundary for writes, not just a dependency that happens to sit next to Mimir. For self-hosted teams evaluating Mimir ingest storage, the decision moves past Kafka API connectivity. They have to look at how that Kafka layer runs: where the data lives, whether scaling requires partition movement, how cross-AZ reads and replication are billed, and how broker replacement works on Kubernetes.
Cloud providers usually charge separately for cross-AZ data transfer. AWS records data transfer between Availability Zones in the same Region as regional data transfer; Google Cloud also lists charges for traffic between zones in the same region. Metrics ingest is data intensive. Producer writes, broker replication, and consumer reads can all turn into steady network charges when they cross AZ boundaries.
In customer conversations, we have seen more self-hosted Mimir teams place AutoMQ in front of Mimir as the Kafka-compatible ingest layer. Mimir uses Kafka to separate writes from reads. AutoMQ uses object storage to separate Kafka brokers from persistent data. Together, Mimir keeps the Kafka interface it expects without forcing the metrics pipeline back into a broker-local disk model and heavy data movement.
AutoMQ enters the Mimir evaluation for a concrete reason. A self-hosted Mimir deployment needs a Kafka-compatible backend that is stable at the Kafka semantics layer, does not bind durable state to broker-local disks, avoids large data movement during scaling, keeps multi-AZ cost under control, fits the Kubernetes operations model, and remains open source and self-hostable.
Why Mimir puts Kafka in the middle
Mimir ingest storage architecture addresses the weight carried by ingesters in the classic architecture. Metrics write pressure and query pressure do not follow the same rhythm. The write side has to accept samples continuously, while the read side has to handle queries, high-cardinality labels, bursty traffic, and uneven access patterns. When all of that pressure lands on ingesters, scaling and recovery become harder.
Kafka takes on two jobs in the new architecture. First, distributors shard write requests across Kafka topic partitions and wait for brokers to confirm that records are durable. Second, ingesters consume from those partitions, place samples into in-memory state, and serve queries. The write path no longer waits for ingesters to participate in quorum. Heavy queries on the read path should no longer directly slow down newly arriving writes.
Self-hosted teams therefore have to treat Kafka as an architecture decision. Once Mimir's write acknowledgement comes from Kafka, the storage and scaling behavior of that Kafka layer affects the whole ingest pipeline. A successful connection test only proves the basic integration. The production question is how the layer handles broker replacement, partition placement, cross-AZ traffic, and continuous writes.
What kind of Kafka layer Mimir ingest storage needs
Metrics ingest rarely changes on a neat schedule. It may stay flat for weeks, then jump after a service rollout, an incident, or a retention adjustment. Series cardinality can rise quickly, scrape pressure can change, and the team least wants to debug broker disks when the observability platform is already under pressure.
Traditional Kafka relies on broker-local disks and inter-broker replication for durability. In a multi-AZ cloud deployment, that usually means each broker owns persistent local data. When the cluster scales out, partition movement and load rebalancing become part of the operation. The larger the write volume, the more those operations compete with production traffic, and the more storage replication and cross-AZ traffic show up in the bill.
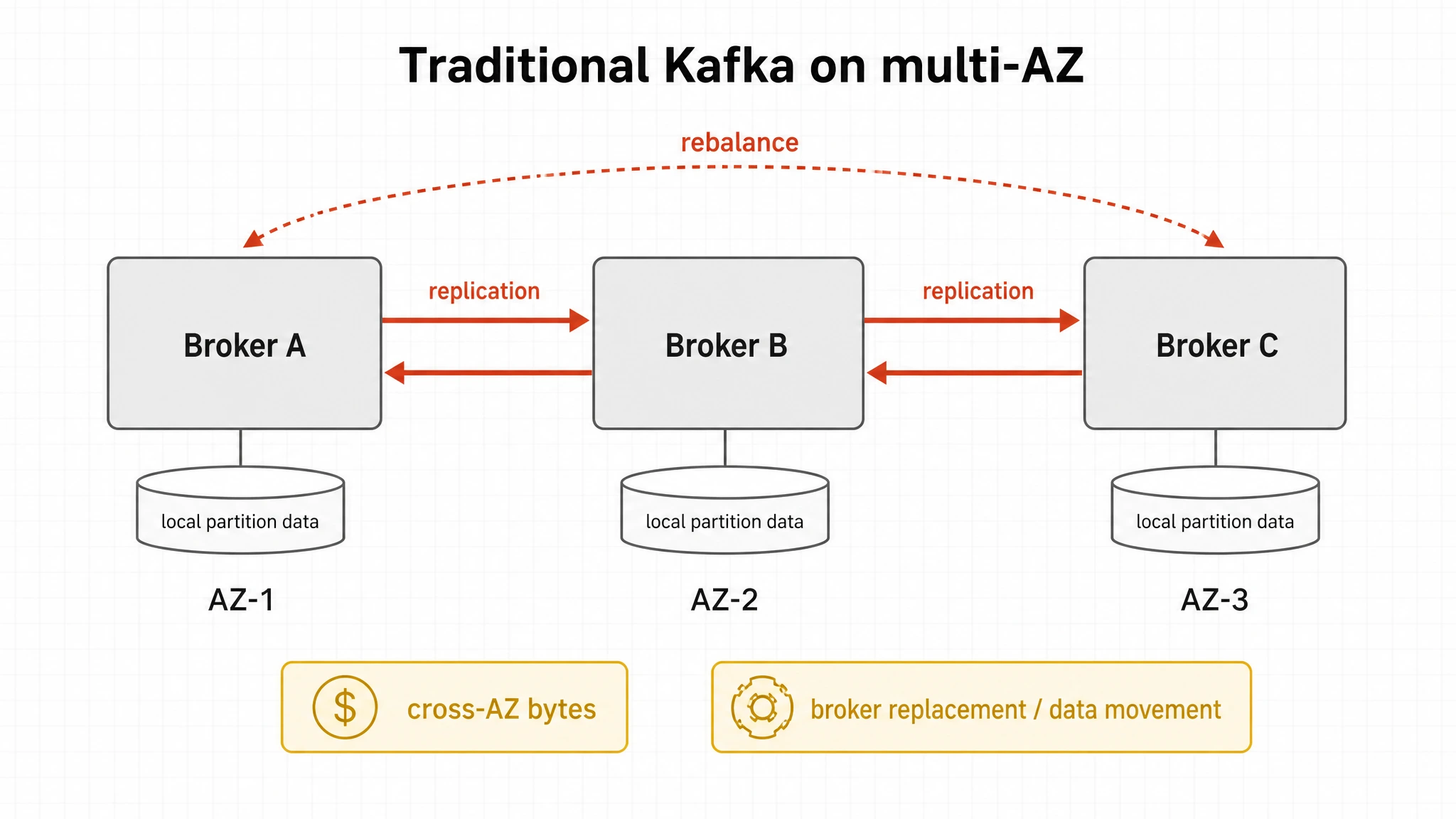
Mimir already stores long-term metric blocks in object storage. If the Kafka layer in front of it keeps a heavy broker-local storage plane, platform teams have to operate two stateful storage lifecycles at once: Mimir blocks in object storage and Kafka partitions tied to broker disks. That architecture can run, but it does not fully match the direction of Mimir's newer design, which reduces state coupling between components.
Throughput and API compatibility are only the starting point. Once Kafka sits on the Mimir ingest path, the selection has to include the storage model, scaling behavior, multi-AZ cost profile, Kubernetes operations entry point, and open-source self-hosting path.
Why AutoMQ is the best fit for Mimir ingest storage
After Mimir places Kafka inside ingest storage, that Kafka layer has to absorb continuous distributor writes, give ingesters a log they can catch up from, and keep the write path stable during service growth, failure recovery, and changing query pressure. Self-hosted teams need two guarantees: Mimir should keep working through the Kafka model, and the Kafka layer should not bring broker-local disks, data migration, and scaling friction back into the write path.
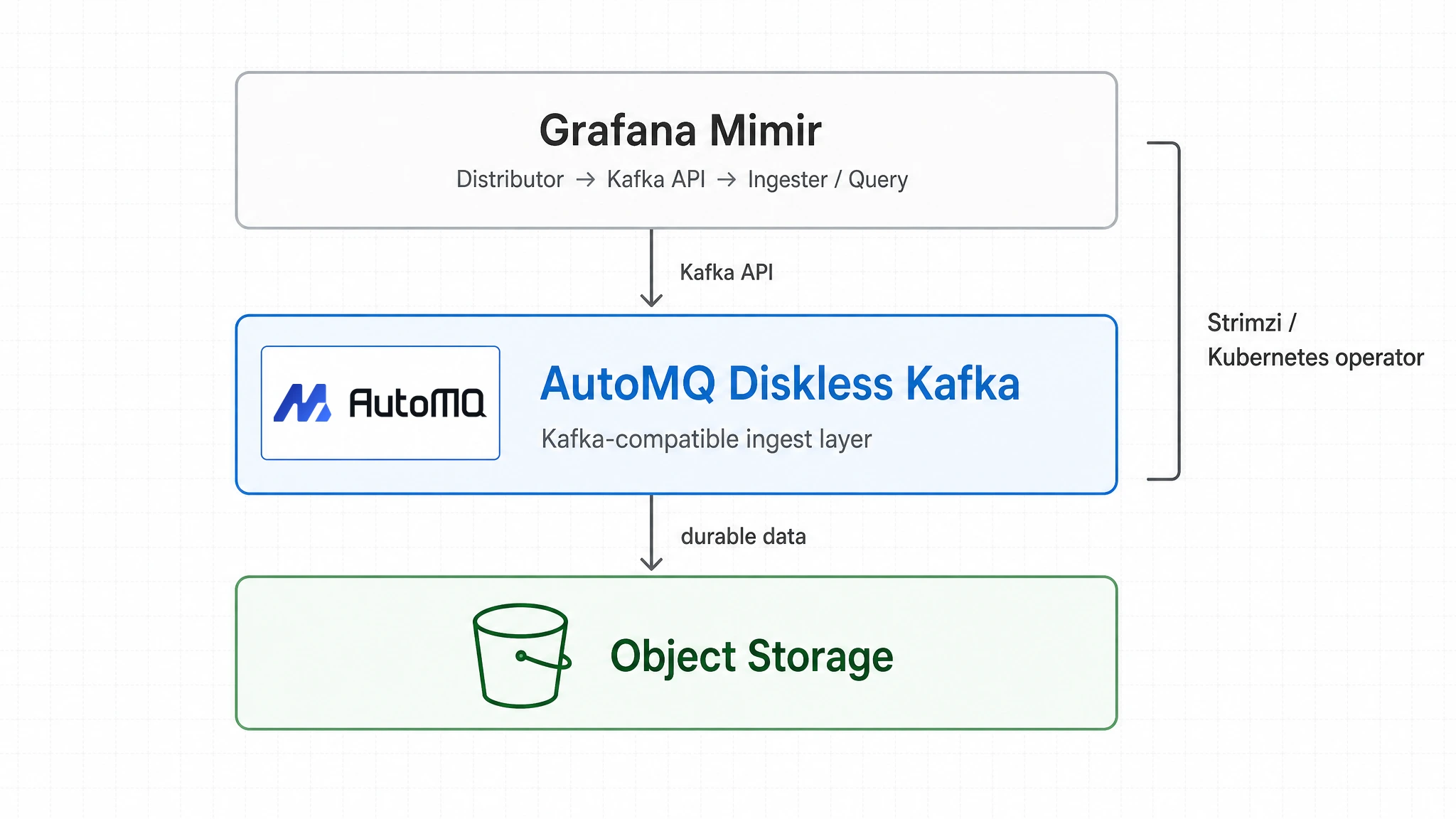
AutoMQ fits there because Mimir still sees Kafka. Distributors write to topics, and ingesters consume through consumer groups. The change happens below the Kafka interface: AutoMQ keeps the Kafka protocol and compute layer while moving Kafka's persistent data from broker-local disks into shared object storage.
The requirements from Mimir map directly to AutoMQ capabilities:
| What Mimir needs from the Kafka layer | Why it matters for Mimir | How AutoMQ maps to it |
|---|---|---|
| Stable Kafka API and protocol semantics | Distributors write to Kafka, while ingesters consume through consumer groups and persist progress. Replacing the ingest backend should not change that path. | AutoMQ positions itself around 100% Kafka API and protocol compatibility, preserving Kafka clients, tools, and ecosystem integrations. |
| Durable state not bound to broker-local disks | Kafka is now the write-path commit boundary. If durable data remains tied to broker disks, Mimir only moves state pressure one layer down. | AutoMQ is Diskless Kafka: brokers do not bind persistent data to local disks, and durable data is stored in shared object storage. |
| Elasticity under high-throughput metrics ingest | Series cardinality, scrape pressure, and service adoption change over time. Scaling should not become a partition data migration project. | Brokers are closer to compute nodes. Scaling mainly adjusts ownership and traffic rather than copying large volumes of partition data between disks. |
| A controllable multi-AZ cost structure | High-throughput metrics ingest magnifies storage replication and cross-AZ traffic. After Kafka enters the write path, that cost grows with ingest volume. | Object storage changes the cost structure created by broker-local disks and inter-broker replicas, so durable data no longer revolves around local broker copies. |
| Lighter Day-2 operations | Broker replacement, expansion, partition rebalance, and local data recovery should not repeatedly interrupt the Mimir write path. | Durable data lives in shared object storage. Broker replacement depends less on local partition data, and scaling is no longer equivalent to moving large local data sets. |
| Familiar Kubernetes operations | Many self-hosted Mimir teams already run observability systems on Kubernetes. The Kafka ingest backend should work with operator-driven operations. | AutoMQ supports deployment with Strimzi, so teams can keep a Kafka-native operations entry point. |
| Open source, self-hostable, and auditable infrastructure | Teams choosing Mimir often want an open, self-hosted, auditable observability stack. The Kafka layer should follow the same path. | AutoMQ Open Source is available under the Apache 2.0 license; Mimir and AutoMQ can form an open-source stack for self-hosted observability platforms. |
These constraints appear together on the Mimir ingest path. The write path needs Kafka semantics, the storage layer needs less broker-local state, capacity changes should not become data migration projects, cost and operational complexity should not be amplified by broker-local replication, and Kubernetes teams still need an operator workflow they recognize.
AutoMQ brings those requirements into one storage model: keep the Kafka interface, place persistent data in object storage, and make brokers closer to compute nodes. Mimir does not have to understand AutoMQ's internal storage engine or abandon the Kafka model it already uses. Platform teams can handle cost, elasticity, and Day-2 operations for the metrics ingest layer in the same architecture.
Build modern observability infrastructure with Mimir and Diskless Kafka
If you are adopting Mimir ingest storage, Kafka is already part of the observability write path. Treating it as a generic dependency understates its impact on system behavior. The Kafka layer decides how the write path absorbs pressure, how quickly the cluster can scale, how multi-AZ cost grows, and how much storage work enters the platform team's daily operations.
Mimir 3.0 points in a clear direction: use Kafka-compatible ingest storage to separate writes from reads, and use object storage for long-term metric blocks. AutoMQ carries the Kafka layer in the same direction. The application layer keeps the Kafka contract, durable data moves into object storage, and brokers no longer carry large volumes of local partition data around the cluster.
Together, Mimir handles metrics write, read, and long-term storage paths; AutoMQ provides the Kafka-compatible ingest layer with durable Diskless storage and elasticity; Strimzi keeps the Kubernetes operator workflow familiar. For self-hosted teams, the result is direct: the Kafka interface stays the same, Diskless storage reduces local-disk coupling, and cost plus operations move toward an object-storage model.
If you are evaluating Kafka-compatible ingest storage for Grafana Mimir, sign up for AutoMQ Cloud and run a Kafka-compatible, Diskless AutoMQ architecture in your own environment: Sign up for AutoMQ Cloud.


