
Background and Challenges
Every morning, hundreds of thousands of beauty and wellness merchants around the world open Fresha and check yesterday's revenue, upcoming bookings, and staff performance. Behind those simple numbers is a real-time data pipeline handling 600,000 bookings per day, billions of database change events, and peak traffic of 3,000 requests per second.
As pressure on the real-time pipeline kept rising, Fresha's data engineering team realized that point optimizations were no longer enough. The whole architecture needed to be redesigned.
Fresha is a leading SaaS platform for the global beauty, wellness, and self-care industry, headquartered in the United Kingdom and serving millions of consumers and merchants worldwide. In less than a year, the team completed a systematic upgrade of its data platform: from a traditional architecture centered on Postgres, Snowflake, and Amazon MSK to a modern real-time analytics stack built on AutoMQ and StarRocks.
The old architecture had two major pressure points.
The Messaging Layer: When Data-Center Kafka Meets the Cloud
Fresha's data pipeline was built on Apache Kafka. Change events from roughly 100 Postgres databases were written into Kafka through Debezium CDC. Downstream systems such as Flink, Spark, StarRocks, and Snowflake then consumed data from Kafka. For Fresha, Kafka was not just a message queue. It was the nervous system of the data platform.
At the time, Fresha ran two Kafka clusters on Amazon MSK. One was a CDC/Warehouse cluster carrying all CDC traffic for the data platform and moving billions of events every day. The other was an Outbox cluster used for event-driven integration between microservices, with much stricter latency requirements than the CDC workload.
The two workloads were very different, but both were running on the same managed Kafka model.
Kafka was born in the data-center era, and its storage model reflects that origin. Each broker writes data to local disks and uses ISR replication across brokers, often across availability zones, to provide durability.
In a traditional data center, this design makes sense. Disk cost is relatively controllable, machine-to-machine replication usually does not create a separate network bill, and coupling compute with storage on the same physical machine is a simple architecture choice.
Once Kafka moves to the cloud, however, the compute-storage coupled model creates several problems:
Storage cost is high. EBS charges by capacity and IOPS, and a three-replica model means storage cost is effectively multiplied.
Cross-AZ traffic is expensive. Replica replication between brokers across availability zones generates additional network charges, and the cost grows with data volume.
Scaling granularity is coarse. Scaling usually means adding whole brokers, so CPU, memory, network, and storage all scale together, even when only one resource is constrained.
Elasticity is limited. Partitions are bound to specific brokers. After adding brokers, teams must physically move partition data to rebalance load, a process that can take hours and cannot react quickly to traffic changes.
Fresha's traffic pattern amplified these issues. The platform has clear daily peaks: morning and evening traffic can be several times higher than the baseline. With a compute-storage coupled architecture, the team had to reserve broker capacity for the peaks, leaving resources idle for much of the day.
The data pipeline was also growing. As more Flink jobs were added, each new pipeline often introduced more intermediate topics. MSK ties partition limits to broker instance types: to support more partitions, the team often had to upgrade to larger instances. Because MSK cost also increases with partition count, topic and partition growth translated directly into Kafka resource pressure and cost pressure.
As a managed Kafka service, MSK lowered deployment effort, but it did not change Kafka's underlying architectural constraints. It also introduced new operational pressure. MSK regularly runs mandatory maintenance windows for OS patching and restarts brokers one by one. Because each broker is stateful and owns many partitions, restarts often trigger leader movement and rebalancing, leading to alerts and temporary performance fluctuation. The team had to watch every maintenance window closely.
Fresha spent six to seven months evaluating alternatives, including Confluent and Aiven. But these options still followed the traditional compute-storage coupled Kafka architecture. They changed the managed service model, not the root problem.
In other words, the problem was not simply that MSK was hard to use. The deeper issue was that traditional Kafka's architecture did not fit the cloud environment well.
The Analytics Layer: From Postgres to Snowflake, the Bottleneck Continued
The messaging layer delivered data downstream, but Fresha also ran into repeated bottlenecks in the analytics layer.
At first, analytics queries were served directly by Postgres. Real-time analytics widgets on a merchant's home page, such as recent revenue, upcoming appointments, popular services, and employee performance comparisons, all queried the OLTP database.
The problem surfaced quickly. Fresha's traffic has sharp peaks. In the morning and evening, many merchants open the home page at the same time to check business data. Outside those peaks, the Postgres buffer cache mostly holds hot OLTP transaction data, and query latency remains stable. During peak periods, analytics queries load large amounts of historical data pages and push hot transactional data out of the cache.
The first cold query could time out while loading data pages. Later queries might benefit from cache, but the OLTP data needed by transactions had already been evicted. Even order flows could slow down.
For small merchants, the data volume was manageable. But Fresha's most important large merchants often had the largest data volume. They contributed more revenue and had higher expectations, yet they were also the most likely to hit performance limits.
In those scenarios, P99 latency once rose above four seconds, and many requests returned 500 errors. The customers who most needed a stable experience were getting the worst one.
To move analytics load out of Postgres, the team introduced Snowflake. Debezium CDC synchronized data into Snowflake, and dbt handled batch modeling. This solved traditional BI dashboard needs.
But Fresha needed more than BI. When merchants open the home page, they expect fresh revenue data, not a snapshot from 20 minutes earlier. The team tried several ways to lower end-to-end latency, but none solved the problem cleanly:
dbt batch modeling could be optimized to about a 20-minute refresh interval, still far from true real time.
A Lambda architecture could combine real-time events with batch precomputed results and reduce latency to tens of seconds, but complexity grew quickly and maintenance became hard to justify.
ClickHouse was familiar to Anton, who had years of experience with it, but Fresha's queries often involve 20 to 30 joins. For this kind of complex join workload, ClickHouse usually requires wide-table pre-modeling, creating too much upfront work.
At this point, the messaging layer still lacked an ideal replacement, and the analytics layer had reached new ceilings through multiple migrations. Fresha needed a systematic data stack upgrade.
The team had a clear design principle: do not introduce a new tool only to solve the next immediate problem. Build a composable platform that can keep evolving. When the next requirement appears, the team should not have to redesign the architecture from scratch.
The New Architecture
That principle became a unified ingestion spine with multiple downstream data paths for different business requirements.
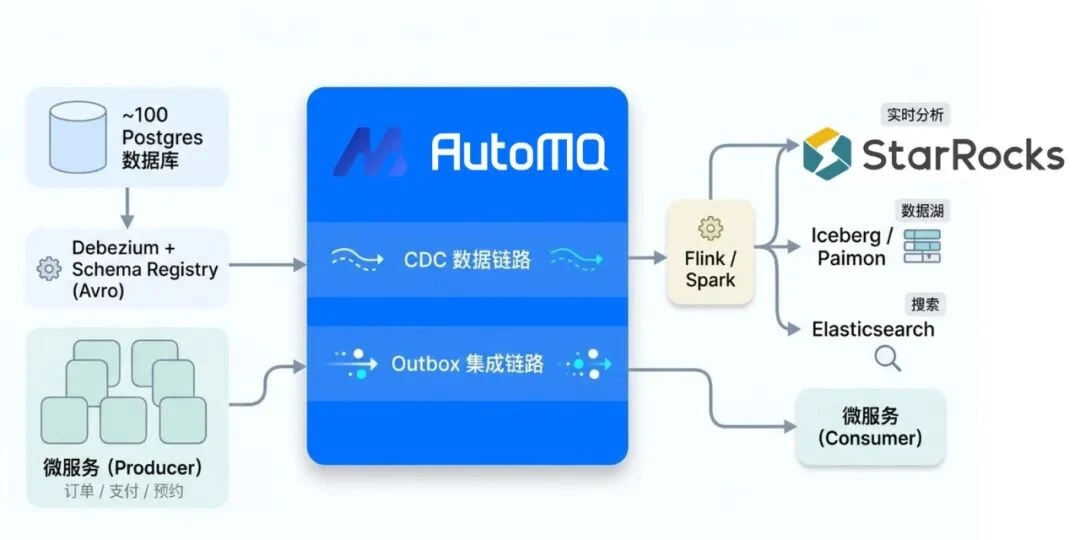
About 100 Postgres databases capture CDC events through Debezium, serialize them in Avro through Schema Registry, and write them into AutoMQ. Flink and Spark then distribute the data to downstream systems: StarRocks powers real-time dashboards, Iceberg and Paimon provide long-term lakehouse storage, and Elasticsearch supports full-text search.
In the new architecture, StarRocks acts as the unified SQL query layer and exposes the MySQL protocol. Engineers can use SQL to join real-time data, historical data, and search indexes in one analytical query.
Why Fresha Chose AutoMQ
The mismatch between traditional Kafka's compute-storage coupled model and the cloud led Fresha toward a clearer direction: Diskless Kafka.
The core idea is to move data from broker-local disks to cloud object storage such as S3. Brokers become stateless compute nodes, and storage is handled by cloud infrastructure. S3 already provides eleven nines of durability and cross-AZ redundancy, so the application layer no longer needs multi-replica broker replication for durability.
This architecture addresses several core cloud Kafka problems at once: three-replica storage cost, cross-AZ replica traffic, whole-broker scaling, and the need to physically move partition data during rebalancing.
But diskless design has tradeoffs. Some existing Diskless Kafka approaches build data fully on S3. Write latency is then bounded by object storage response time and often lands in the hundreds of milliseconds.
For Fresha's CDC cluster, that latency was acceptable. CDC is more sensitive to throughput and cost than to single-digit millisecond latency. But Fresha also had the Outbox cluster for event-driven microservice integration, where latency requirements are much stricter. If the team adopted a pure-S3 Diskless Kafka implementation, the CDC problem could be solved while the Outbox cluster would still need another system.
AutoMQ's architecture addresses that gap. As a next-generation cloud-native Diskless Kafka implementation, AutoMQ introduces a WAL between brokers and S3 and makes it a core part of the storage engine. Writes are first persisted to the WAL and acknowledged immediately, then flushed to S3 asynchronously in the background.
This design preserves the key advantages of Diskless Kafka: stateless brokers, storage on S3, and no application-level replica replication. At the same time, different WAL backends support different latency requirements. High-throughput, low-cost workloads can use S3 WAL. Latency-sensitive workloads can use a low-latency WAL. The two workload types no longer need separate systems.
For Fresha, this meant the CDC cluster could use S3 WAL to reduce cost, while the Outbox cluster could use a low-latency WAL to achieve single-digit millisecond writes. Both clusters run on the same AutoMQ architecture and share the same operational model and monitoring system.
This is why the six-to-seven-month evaluation finally reached a conclusion. The answer was not to choose between cost and latency, but to use one architecture that could cover both workloads.
Fresha's gains from AutoMQ came in three areas.

- Architecture-driven cost reduction.
AutoMQ moves persistence from three EBS replicas to a single copy in S3, significantly reducing storage cost. Because brokers no longer replicate data across availability zones, network traffic cost is also removed architecturally. AutoMQ's pricing model is not tied to partition count, so Flink intermediate topics can be created as needed without pushing up cost the way MSK partition growth did.
Production validation.
Anton deployed AutoMQ on EC2 and mirrored the full production traffic from the CDC cluster for three days. The result showed that AutoMQ's S3 storage cost was 17 to 20 times lower than MSK.
"We deployed AutoMQ on our EC2s. I mirrored all the traffic from our CDC warehouse cluster and I watched the cost in S3 and it was like 17-20 times less than our AWS cost."
-- Anton Borisov, Principal Data Engineer, Fresha
- One advanced Diskless Kafka architecture for multiple workload types.
Stateless brokers mean the cluster can scale in seconds. During morning and evening peaks, the team no longer needs to reserve whole brokers for peak capacity. Rolling upgrades no longer require partition rebalancing and leader movement, so alert storms caused by MSK maintenance windows disappear.
More importantly, different WAL backends allow the CDC cluster and the Outbox cluster to run on the same AutoMQ architecture. Fresha no longer needs to find and operate two separate systems for the two workload classes.
- 100% Kafka compatibility and seamless migration with no code changes.
AutoMQ is fully compatible with the Apache Kafka protocol. Fresha's existing producers, consumers, Flink jobs, and connectors could keep running without code changes. With AutoMQ's built-in Kafka Linking zero-downtime migration tool, the team migrated nearly 1,000 topics in one week, with downstream systems almost unaware of the switch.
Why Fresha Chose StarRocks
Fresha needed more than a faster analytics engine. It needed a query layer that could support real-time business analytics.
The query pattern had two clear characteristics. First, joins were frequent and complex. Home page analytics usually involved three to five joins, while payment log analytics could involve 20 to 30 joins across multiple databases. Second, these were not low-frequency offline BI queries. They directly served merchant home pages and required low latency plus minute-level freshness.
That made many common options unsuitable. Keeping analytics queries on Postgres would continue to hurt OLTP performance. Using ClickHouse would often require pre-joining data into wide tables for complex join workloads, creating significant modeling and maintenance work. The team needed a more direct path: run complex queries first with limited pre-modeling, then evolve the model as the business grows.
StarRocks fit this requirement. It can support complex join queries without heavy upfront pre-modeling, and it is compatible with the MySQL protocol. Engineers could reuse familiar clients and connection methods, reducing the effort required to launch the first use case.
Migration in Practice
AutoMQ: Migrating Nearly 1,000 Topics in One Week with Zero Downtime
After the architecture was selected and cost validation passed, the real challenge was migration. Fresha's CDC cluster carried nearly 1,000 topics, with downstream Flink jobs, connectors, StarRocks Routine Load jobs, and Snowflake data pipelines. Every topic had downstream consumers relying on offsets to maintain progress.
If offsets changed, Flink checkpoints could fail and consumer positions could be lost. A poorly handled migration would be almost equivalent to rebuilding the data pipeline.
Traditional migration tools such as MirrorMaker2 have a problem here: they reserialize messages, so offsets in the target cluster do not match offsets in the source cluster. Anton had already seen this issue when using MirrorMaker for traffic mirroring during POC. Data could be copied, but offsets did not align, forcing downstream systems to be reconfigured.
For production migration, Fresha used AutoMQ's built-in Kafka Linking. It is not an external add-on, but a zero-downtime migration capability built into AutoMQ to solve the two most important migration requirements: no business interruption and no consumer offset loss.
| Business concern | Kafka Linking answer | How it works |
|---|---|---|
| "Will offsets change?" | Strict 1:1 consistency | Copies the source cluster's original byte stream without reserialization, preserving offsets exactly |
| "Will Flink checkpoints fail?" | No | Offsets stay consistent, so Flink, Spark, and other offset-dependent jobs need no adjustment |
| "Can we roll back if something goes wrong?" | Lossless rollback at any stage | Intelligent write forwarding transparently proxies new-cluster writes back to the source cluster during transition |
| "Do we have to cut everything over at once?" | No | Supports topic-level and consumer-group-level control |
| "Will the business notice the migration?" | No | Producers and consumers are updated through rolling changes with zero downtime |
| "Does it depend on an external migration component?" | No | Kafka Linking is built into AutoMQ and fully managed |
With these capabilities, Fresha did not have to make a high-risk big-bang migration. The team used a staged approach:
-
Migrate non-critical workloads first. Monitoring and log topics were moved to AutoMQ to validate data integrity and latency with limited blast radius.
-
Gradually switch core pipelines. After the first batch ran stably, the team moved Flink jobs, StarRocks Routine Load, and Snowflake synchronization pipelines.
-
Roll clients forward. Upstream producers and downstream consumers were switched through standard rolling updates, without a shared downtime window.
During the transition, Kafka Linking's write forwarding kept data consistent across old and new clusters. At any stage, the team could switch back if needed.
Fresha ultimately migrated nearly 1,000 topics in one week with zero downtime. Flink jobs and connector tasks were almost unaware of the change. There was no 3 a.m. maintenance window and no need for multiple teams to coordinate a single cutover meeting.
Because offsets were preserved 1:1, the Kafka cluster looked almost unchanged from the consumer perspective. Only the underlying architecture had been upgraded.
StarRocks Migration in Practice
The first workload Fresha moved to StarRocks was the most important real-time path: home page analytics.
Previously, these queries went directly to Postgres. Small merchants could still be served, but large merchants quickly pushed data volume high enough that pages often took 15 to 20 seconds to load or timed out. Analytics queries also displaced Postgres buffer cache and affected OLTP transaction performance. The customers who most needed a reliable experience were the most likely to see the worst one.
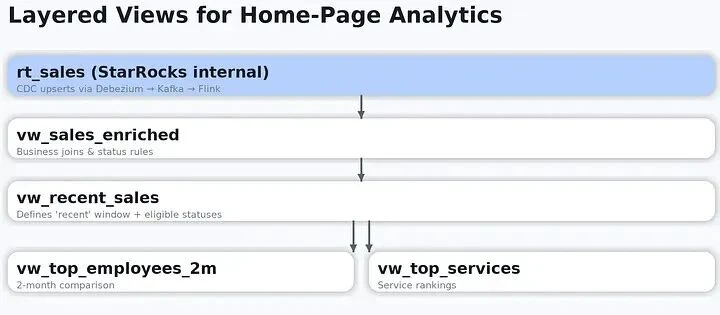
The team had a clear requirement for the new path: it had to be fast, and it had to deliver minute-level freshness. Iceberg was evaluated, but high-frequency writes created small-file and compaction pressure, making the freshness target hard to meet consistently. Fresha therefore wrote hot real-time data into StarRocks internal tables while keeping Iceberg and Paimon as the long-term historical storage layer.
Instead of relying only on materialized views, the team built layered SQL views on top of real-time tables. These views encapsulated business relationships, status definitions, and analytics semantics such as "recent" and "top." Product services could query higher-level views without repeatedly reimplementing business logic, while the StarRocks optimizer pushed filters and pruning through the query plan.
Results
After the migration, home page analytics queries under complex filters and aggregations returned in roughly 200 milliseconds, meeting the requirement for minute-level freshness. Postgres was freed from analytics load and returned to its role as a stable transactional database, while StarRocks handled concurrent real-time analytics for the home page.
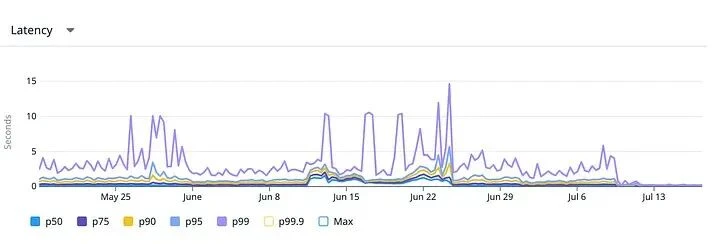
The latency comparison before and after enabling the StarRocks query path through feature flags shows the impact clearly. Before the switch, the old Postgres path often had multi-second spikes. After StarRocks was enabled, p95 dropped to around one second or below, and long-tail p99 and p99.9 spikes largely disappeared.
More migration details are available in the original Chinese article.
Production Outcomes
Fresha's new data platform is now running in production, supporting real-time analytics, historical trend queries, and search experiences for global merchants.
For the messaging layer powered by AutoMQ:
| Dimension | Result |
|---|---|
| MSK migration scale | Nearly 1,000 topics migrated in one week with zero downtime and no application code changes |
| Kafka storage cost | S3 storage was 17 to 20 times lower than MSK in production-traffic testing |
| Operational burden | Rebalance alerts caused by mandatory MSK maintenance windows were eliminated |
| Workload coverage | CDC and Outbox workloads can be supported by one unified system |
| Cost optimization | Pricing is not tied to partition count, so Flink intermediate topics can be created on demand |
| Elasticity | Stateless brokers enable second-level compute scale-out and scale-in |
For the analytics layer powered by StarRocks:
| Dimension | Result |
|---|---|
| Home page analytics latency | P99.9 dropped from 10-15 seconds to about 300 milliseconds, and 500 errors were eliminated |
| Payment log analytics | Query latency dropped from more than one minute to sub-second |
| Development efficiency | MySQL protocol compatibility enabled the first use case to be integrated in two days |
| Postgres load | Analytics queries were fully separated from Postgres, restoring OLTP performance |
AutoMQ provided reliable, low-cost messaging infrastructure capable of supporting mixed workloads. StarRocks provided a unified real-time analytics query layer. Together, they became the foundation of Fresha's next-generation data platform.
A Modern Data Stack Built as a System
Fresha's experience validates an architectural direction that more teams are beginning to adopt: the messaging layer and analytics layer need to be modernized together.
Upgrading only one layer often moves the bottleneck somewhere else. Even a fast analytics engine is constrained if the messaging layer cannot keep up with cost, elasticity, and operational complexity. Even an efficient messaging layer cannot fix user-facing latency if analytics queries still run on Postgres.
The combination of AutoMQ and StarRocks works because both systems solve a similar underlying problem in different layers: replacing data-center-era designs with architectures built for the cloud.
AutoMQ uses a Diskless Kafka architecture to move Kafka storage from broker-local disks to object storage, addressing cost, elasticity, and operational pressure caused by compute-storage coupling. StarRocks uses a compute-storage separated architecture for analytics, allowing compute nodes to scale as needed.

Both systems also preserve strong compatibility with existing ecosystems. AutoMQ is compatible with the Kafka protocol, and StarRocks is compatible with the MySQL protocol, which keeps migration effort relatively low.
For teams still running a Kafka plus OLAP stack in the cloud, Fresha's practice offers a practical path: do not replace the entire system in one move. Modernize the messaging layer and analytics layer separately, use zero-downtime migration to switch gradually, and upgrade the architecture without interrupting the business.
Back to the opening scene: every morning, merchants open Fresha to check business metrics. Those numbers can now be refreshed in seconds, powered by billions of events flowing through AutoMQ each day and sub-second analytical queries served by StarRocks.
The data pipeline is no longer a system the team has to keep rescuing. It has become infrastructure they can rely on.


