
Introduction
The cost of an Apache Kafka cluster is mainly composed of two parts: computing cost and storage cost. The former mainly includes servers for running Kafka Broker (such as AWS EC2), and the latter mainly includes storage devices for saving data (such as AWS EBS).
For both computing and storage, AutoMQ Kafka has made substantial optimizations. Under the same traffic, the total cost of the cluster can be reduced to 1/10 of the original.
In this report, we will introduce the cost optimizations made by AutoMQ Kafka in terms of storage and computing, and calculate the theoretically saved costs. Finally, we refer to common scenarios online, run an AutoMQ Kafka cluster, and compare its cost with Apache Kafka (versions below 3.6.0, without tiered storage).
:::note Unless otherwise specified, the pricing of related cloud products mentioned below is as of October 31, 2023, for the Amazon Web Services Ningxia region (cn-northwest-1). :::
Storage: Fully Utilize High-Reliability, Low-Cost Cloud Storage
In the era of the cloud, all cloud vendors provide highly reliable cloud storage. At the same time, in different scenarios, cloud vendors provide a variety of characteristic cloud products for users to choose from, such as AWS EBS, AWS S3, AWS EFS, etc.
To fully utilize cloud storage, AutoMQ Kafka offloads the majority of data to object storage, using only a small amount of block storage (from hundreds of MBs to several GBs) as a buffer. This ensures performance and reliability while significantly reducing data storage costs.
Single Replica, High Reliability
Cloud disks, as one of the most widely used storage in cloud storage, currently provide ultra-high storage reliability. However, multi-replica storage built on cloud disks contributes little to the improvement of reliability, but instead doubles the storage costs.
In AutoMQ Kafka, a small-capacity single-replica cloud disk is used as a durable write buffer before data is uploaded to object storage, without the need for additional data replication. At the same time, AutoMQ Kafka can ensure high availability of single-replica cloud disks in various scenarios through a series of means (see Single Replica High Availability). Therefore, AutoMQ Kafka can achieve the same storage reliability and availability as Apache Kafka's three replicas with a single replica cloud disk.
Affordable Object Storage
Object storage, as one of the cheapest storage products in the cloud, has extremely low prices and nearly unlimited capacity. AutoMQ Kafka greatly reduces storage costs by offloading the majority of data to object storage (see S3 Stream).
Taking AWS as an example, the unit price of AWS S3 Standard Storage is 0.1755 CNY/(GiBmonth)*, and the unit price of AWS EBS gp3 is *0.5312 CNY/(GiBmonth). Using S3 will save 67.0% of storage costs.
Below, we will compare the storage costs of AutoMQ Kafka and Apache Kafka using AWS EBS and S3 as examples. The monthly cost of AutoMQ Kafka using S3 Standard Storage to store 10 TiB of data is:
10 TiB * 1024 GiB/TiB * 0.1755 CNY/(GiB*month) = 1797.12 CNY/month
And the monthly cost of 3-replica Apache Kafka using EBS gp3 to store 10 TiB of data is (assuming a disk watermark of 80%):
10 TiB * 1024 GiB/TiB ÷ 80% * 3 * 0.5312 CNY/(GiB*month) = 20398.08 CNY/month
The storage cost of Apache Kafka is theoretically about 20398.08 / 1797.12 ~= 11.4 times that of AutoMQ Kafka.
Calculation: Fully Utilize the Elasticity of Cloud Computing with Pay-as-you-go and Scalability
In the era of the cloud, cloud vendors provide highly elastic cloud computing services. Users can purchase or release cloud servers at any time according to their needs. At the same time, these cloud servers are billed on a pay-as-you-go basis, and users can release them when they are idle to save costs.
The architecture of AutoMQ Kafka, which separates storage from computation, can naturally utilize the elastic capabilities of cloud computing: whether it's partition migration or machine scaling, AutoMQ Kafka can complete it within minutes.
Scale on Demand, No Idle Time
AutoMQ Kafka has the ability to replicate partition data in seconds and continuously rebalance data, so whether it's scaling down or scaling up, it can be completed within minutes (see Scale-out/in in minutes).
This fast scaling ability allows AutoMQ Kafka to change the cluster capacity in real time according to the cluster traffic, avoiding waste of computing resources. In contrast, Apache Kafka needs to be deployed based on estimated maximum traffic to avoid business damage due to insufficient scaling when peak traffic arrives. This can save a lot of costs in scenarios where the traffic peaks and valleys are very pronounced.
Assuming that the peak-to-valley ratio of a cluster's traffic is 10:1, and the peak traffic lasts for 4 hours per day, the theoretical ratio of the number of instances required by AutoMQ Kafka and 3-replica Apache Kafka is:
(1 * (24 - 4) + 10 * 4) : (10 * 24 * 3) = **1 : 12**
Spot Instances, Flexible and Affordable
Currently, all major cloud vendors offer Spot Instances (also known as "Preemptible Instances") services, which have the following characteristics compared to on-demand instances:
- Lower price. For example, AWS Spot Instances can enjoy up to a 90% discount.
- Uncontrollable lifespan. When the bid is lower than the market price, Spot Instances will be forcibly released.
The characteristic that Spot Instances may be forcibly released at any time makes them more difficult to utilize than on-demand instances, but AutoMQ Kafka can completely solve this problem:
- When receiving a signal that an instance is about to be released, AutoMQ Kafka can quickly migrate the partitions on that Broker to other Brokers (see Replicate partition data in seconds), and then gracefully shut down.
- In extreme cases, when the partition is not fully migrated and the instance is released, AutoMQ Kafka can still recover and upload data from the data disk of that instance (see Single Replica High Availability) to avoid data loss.
In an AutoMQ Kafka cluster, all Brokers can be Spot Instances, thereby significantly saving costs.
Taking AWS r6i.large model as an example, the on-demand price is 0.88313 CNY/hour, and the Spot price is 0.2067 CNY/hour, using Spot Instances can save 76.6% of the cost.
Bandwidth is Used Where It Matters
All cloud vendors set a network bandwidth limit (inbound and outbound traffic are calculated separately) for instances of different models. This limit will restrict the traffic that a single broker can carry. Conversely, if the network bandwidth used by the Broker can be saved, the single-machine traffic limit can be increased, thereby saving costs.
Next, we compare the traffic usage of AutoMQ Kafka and Apache Kafka under the condition that the production-consumption ratio of the cluster is 1:1:
- For AutoMQ Kafka, when a Broker receives a message with 1 unit of traffic, its outbound traffic includes 1 unit sent to the consumer and 1 unit uploaded to object storage. A total of 2 units.
- For Apache Kafka with 3 replicas, when a Broker receives a message with 1 unit of traffic, its outbound traffic includes 1 unit sent to the consumer and 2 units for inter-replica replication. A total of 3 units.
It can be calculated that when the production-consumption ratio is 1:1, the traffic load limit of the AutoMQ Kafka Broker is 1.5 times that of Apache Kafka.
Online Scenario Test
In order to verify the cost advantages of AutoMQ Kafka, we set up an AutoMQ Kafka cluster on AWS and simulated common scenarios for sending and receiving messages. Finally, we obtained the cluster capacity change curve and cost curve through AWS CloudWatch and AWS Cost Explorer, and compared the costs of AutoMQ Kafka with Apache Kafka.
Testing Plan
- Deploy an AutoMQ Kafka cluster on AWS by AutoMQ Cloud and AutoMQ Installer (Can be downloaded when you create a cluster on AutoMQ Cloud).
- Use the OpenMessaging Benchmark Framework to send and receive messages to this cluster continuously for 24 hours.
- Use AWS CloudWatch to observe the relationship between the number of Brokers in the cluster, the traffic of each Broker, and the total traffic of the cluster.
- Use AWS Cost Explorer to obtain the hourly cost of each cloud product in the cluster.
It is worth noting that in order to simulate the cluster traffic in real scenarios, we made some modifications to the OpenMessaging Benchmark Framework to support changing the traffic of sending and receiving messages in a specified time period. The traffic curve used in the test is:
- The constant traffic is 80 MiB/s.
- From 00:00 to 01:00, the traffic rises to 800 MiB/s, drops to 400 MiB/s at 02:00, and returns to 80 MiB/s at 03:00.
- From 13:00 to 13:45, the traffic rises to 800 MiB/s, and returns to 80 MiB/s at 14:30.
- From 18:00 to 19:00, the traffic rises to 1200 MiB/s, and returns to 80 MiB/s at 20:00.
Other configurations are detailed in Appendix 1.
Test Results
After running the above load for 24 hours in the AWS Ningxia region (cn-northwest-1), the following results were obtained.
Dynamic Scaling
Through AWS CloudWatch, we can get the relationship between the number of brokers and the total cluster traffic over time. As shown in the following figure:
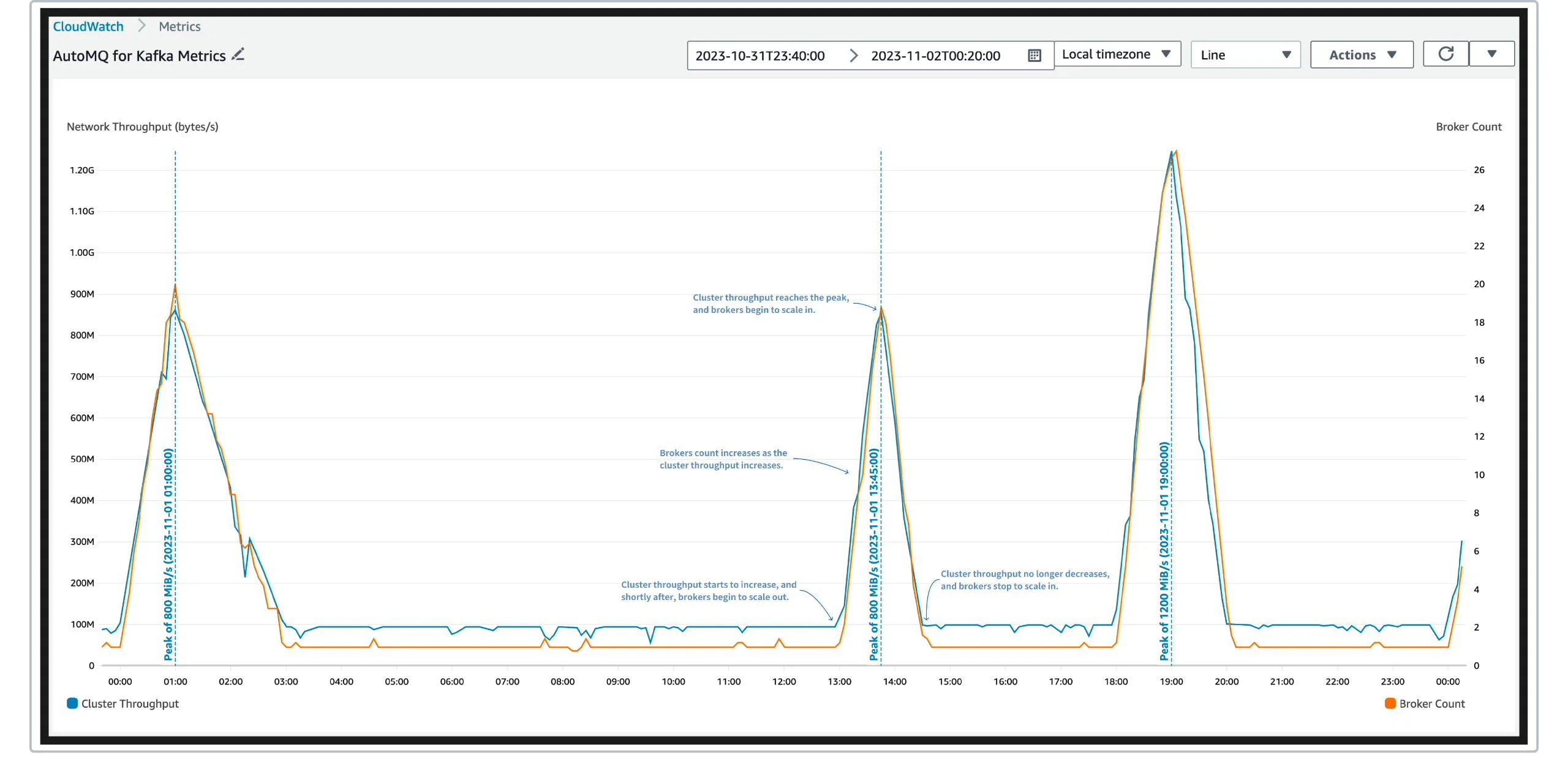
Note:
- The blue curve in the figure represents the total traffic of messages produced in the cluster (i.e., the total size of messages produced per second). Since the production-consumption ratio is 1:1, this is also the total traffic of consumed messages. Its unit is bytes/s, and the units marked in the left Y-axis are in exponentials with a base of 10, for example, 1M = 1,000,000, 1G = 1,000,000,000.
- Due to the activation of AWS Auto Scaling group rebalancing and the release of Spot Instances, there may still be short-term increases and decreases in the number of brokers even when the cluster traffic is stable.
From the figure, it can be seen that:
- AutoMQ Kafka can scale up and down in real-time with the increase and decrease of traffic, with only a delay of minutes, which will save a lot of computing costs.
- During the scaling process, AutoMQ Kafka will only cause short-term, minor traffic fluctuations, which will not affect the availability of the cluster.
Cost Composition
| Type | Cost (CNY) | Proportion |
|---|---|---|
| EC2 - On-Demand Instances | 64.450 | 34.3% |
| EC2 - Spot Instances | 19.446 | 10.4% |
| S3 - Standard Storage Fee | 93.715 | 49.9% |
| S3 - API call fee | 7.692 | 4.1% |
| EBS - gp3 | 2.431 | 1.3% |
| Total | 187.734 | 100.0% |
Note:
- The cost statistics period listed in the table is from 00:00 on 2023-11-01 to 23:59 on 2023-11-01, a total of 24 hours.
- To ensure the stability of the cluster, AutoMQ Kafka will use 3 on-demand instances as Controllers (at the same time, they will also act as Brokers to bear a small part of the traffic), and their cost is 0.88313 CNY/hour * 3 * 24 hours = 63.59 CNY, which is basically consistent with the "EC2 - On-Demand Instance" item in the table.
- Since AWS Cost Explorer has a delay in the statistics of "S3 - Standard Storage Fee", the cost listed in the table is an estimated value of 0.1755 CNY/(GiB*month) * 16242 GiB / 730 hours/month * 24 hours = 93.715 CNY. The 16242 GiB here is the data volume generated by the aforementioned traffic in 24 hours.
- "S3 - API Call Fee" includes the costs of calling the following APIs: GetObject, PutObject, InitiateMultipartUpload, UploadPart, CopyPart, and CompleteMultipartUpload.
- The table does not list costs that did not exceed 0.001 CNY, such as the API call fees for CreateBucket, ListBucket, DeleteBucket, etc.
From the table, it can be seen that:
- Since all Brokers in AutoMQ Kafka use Spot Instances, and the instances scale according to demand, this significantly reduces computing costs.
- AutoMQ Kafka saves most data in object storage (S3), with only a small portion of data saved in block storage (EBS) used as a buffer, significantly reducing storage costs.
In summary, AutoMQ Kafka's ability, like Scale-out/in in minutes and use of object storage (see S3 Stream) can fully leverage the advantages of the cloud, significantly reducing costs, and truly achieving cloud-native.
Comparison with Apache Kafka
We also estimated the cost required by Apache Kafka (version below 3.6.0, no tiered storage) in the same scenario.
The following assumptions are made for this Apache Kafka cluster:
- Purchase on-demand instances according to the peak traffic of the cluster (1200 MiB/s), using the same r6i.large model (its on-demand price is 0.88313 CNY/hour, Spot price is 0.2067 CNY/hour, base bandwidth is 100MiB/s), and the network water level is 80%; in addition, purchase 3 additional on-demand instances as Controllers.
- Purchase block storage according to the total storage volume of the cluster (16242 GiB), using gp3 (its price is 0.5312 CNY per GiB per month), using 3 replicas for storage, and the storage water level is 80%.
The estimation is as follows:
Single broker traffic limit: 100 MiB/s * 80% / (1 + 2) = 26.67 MiB/s
Number of brokers in the cluster: 1200 MiB/s ÷ 26.67 MiB/s = 45
Number of required instances: 45 + 3 = 48
Daily computing cost: 48 * 24 hours * 0.88313 CNY/hour = 1017.366 CNY
Required storage size: 16242 GiB * 3 / 80% = 60907.5 GiB
Daily storage cost: 60907.5 GiB * 0.5312 CNY/(GiB*month) / 730 hours/month * 24 hours = 1063.695 CNY
Total cost: 1017.366 CNY + 1063.695 CNY = 2081.061 CNY
Contrast this with AutoMQ Kafka :
| Cost Category | Apache Kafka® (CNY) | AutoMQ Kafka (CNY) | Multiply |
|---|---|---|---|
| Calculation | 1017.336 | 83.896 | 12.13 |
| Storage | 1063.695 | 103.838 | 10.24 |
| Total | 2081.061 | 187.734 | 11.09 |
It can be seen that AutoMQ Kafka gives full play to the elasticity capabilities of the cloud and makes full use of Object storage. Compared with Apache Kafka® , it significantly reduces the cost of computing and storage, ultimately saving more than 10 times the cost.
Appendix 1: Test Configuration
Configuration file kos-config.yaml of the AutoMQ for Kafka installer:
kos:
installID: xxxx
vpcID: vpc-xxxxxx
cidr: 10.0.1.0/24
zoneNameList: cn-northwest-1b
kafka:
controllerCount: 3
heapOpts: "-Xms6g -Xmx6g -XX:MetaspaceSize=96m -XX:MaxDirectMemorySize=6g"
controllerSettings:
- autobalancer.reporter.network.in.capacity=60000
- autobalancer.reporter.network.out.capacity=60000
brokerSettings:
- autobalancer.reporter.network.in.capacity=100000
- autobalancer.reporter.network.out.capacity=100000
commonSettings:
- metric.reporters=kafka.autobalancer.metricsreporter.AutoBalancerMetricsReporter,org.apache.kafka.server.metrics.s3stream.KafkaS3MetricsLoggerReporter
- s3.metrics.logger.interval.ms=60000
- autobalancer.topic.num.partitions=1
- autobalancer.controller.enable=true
- autobalancer.controller.anomaly.detect.interval.ms=60000
- autobalancer.controller.metrics.delay.ms=20000
- autobalancer.controller.network.in.distribution.detect.threshold=0.2
- autobalancer.controller.network.in.distribution.detect.avg.deviation=0.05
- autobalancer.controller.network.out.distribution.detect.threshold=0.2
- autobalancer.controller.network.out.distribution.detect.avg.deviation=0.05
- autobalancer.controller.network.in.utilization.threshold=0.8
- autobalancer.controller.network.out.utilization.threshold=0.8
- autobalancer.controller.execution.interval.ms=100
- autobalancer.controller.execution.steps=1024
- autobalancer.controller.load.aggregation=true
- autobalancer.controller.exclude.topics=__consumer_offsets
- autobalancer.reporter.metrics.reporting.interval.ms=5000
- s3.network.baseline.bandwidth=104824045
- s3.wal.capacity=4294967296
- s3.wal.cache.size=2147483648
- s3.wal.object.size=536870912
- s3.stream.object.split.size=8388608
- s3.object.block.size=16777216
- s3.object.part.size=33554432
- s3.block.cache.size=1073741824
- s3.object.compaction.cache.size=536870912
scaling:
cooldown: 10
alarmPeriod: 60
scalingAlarmEvaluationTimes: 1
fallbackAlarmEvaluationTimes: 2
scalingNetworkUpBoundRatio: 0.8
scalingNetworkLowerBoundRatio: 0.8
ec2:
instanceType: r6i.large
controllerSpotEnabled: false
keyPairName: kafka_on_s3_benchmark_key-xxxx
enablePublic: true
enableDetailedMonitor: true
accessKey: xxxxxx
secretKey: xxxxxxSome notes:
- All models use r6i.large, and its network baseline bandwidth is 0.781Gbps,so set s3.network.baseline.bandwidth to 104824045(Byte)
- In order to simulate the production scenario, the number of controllers is configured to 3, and the controller uses on-demand instances.
- In order to quickly sense traffic changes and expand and shrink capacity in a timely manner, AWS EC2 detailed monitoring is enabled, kos.scaling.cooldown is set to 10(s) and kos.scaling.alarmPeriod is set to 60(s)
- In order to take full advantage of the elasticity of AutoMQ Kafka , set both kos.scaling.scalingNetworkUpBoundRatio and kos.scaling.scalingNetworkLowerBoundRatio to 0.8
OpenMessaging Benchmark Framework is configured as follows:
driver.yaml:
name: AutoMQ for Kafka
driverClass: io.openmessaging.benchmark.driver.kafka.KafkaBenchmarkDriver
# Kafka client-specific configuration
replicationFactor: 3
reset: false
topicConfig: |
min.insync.replicas=2
commonConfig: |
bootstrap.servers=10.0.1.134:9092,10.0.1.132:9092,10.0.1.133:9092
producerConfig: |
acks=all
linger.ms=0
batch.size=131072
send.buffer.bytes=1048576
receive.buffer.bytes=1048576
consumerConfig: |
auto.offset.reset=earliest
enable.auto.commit=false
auto.commit.interval.ms=0
max.partition.fetch.bytes=131072
send.buffer.bytes=1048576
receive.buffer.bytes=1048576workload.yaml:
name: 1-topic-128-partitions-4kb-4p4c-dynamic
topics: 1
partitionsPerTopic: 128
messageSize: 4096
payloadFile: "payload/payload-4Kb.data"
subscriptionsPerTopic: 1
consumerPerSubscription: 4
producersPerTopic: 4
producerRate: 19200
producerRateList:
- [16, 0, 20480]
- [17, 0, 204800]
- [18, 0, 102400]
- [19, 0, 20480]
- [5, 0, 20480]
- [5, 45, 204800]
- [6, 30, 20480]
- [10, 0, 20480]
- [11, 0, 307200]
- [12, 0, 20480]
consumerBacklogSizeGB: 0
warmupDurationMinutes: 0
testDurationMinutes: 2100In addition, using two c6in.2xlarge instances as workers, the network baseline bandwidth is 12.5Gbps(i.e.1600MiB/s), which can meet the needs of sending and receiving messages during peak traffic.


