
In May 2026, an AWS US-EAST-1 Availability Zone (AZ) failure briefly disrupted Coinbase’s trading service. One detail in The Stack’s post-incident write-up is especially relevant for Kafka platform teams: Coinbase’s Amazon MSK cluster followed Kafka best practices with a multi-AZ, multi-replica deployment, yet AWS MSK did not fail over as expected.
Coinbase’s 2021 MSK architecture write-up also shows that the cluster’s baseline configuration was not weak: 30 brokers across multiple AZs, a 3-AZ deployment, Replication Factor=3, and min.insync.replicas=2. These are all important parts of Kafka high availability design. The case is a useful reminder that even a complete-looking replica configuration does not guarantee recovery under a real failure. Kafka availability is not finished once a few replication parameters are set correctly. It is a system-level design that also has to cover failover, client reconnects, capacity headroom, replica catch-up, consumption progress, and downstream recovery. If any one part breaks, high availability and disaster recovery may not execute as expected.
With that in mind, this article looks at the availability challenges Kafka faces during real failure recovery, and then shows how AutoMQ’s high availability and disaster recovery design makes those recovery processes more predictable.
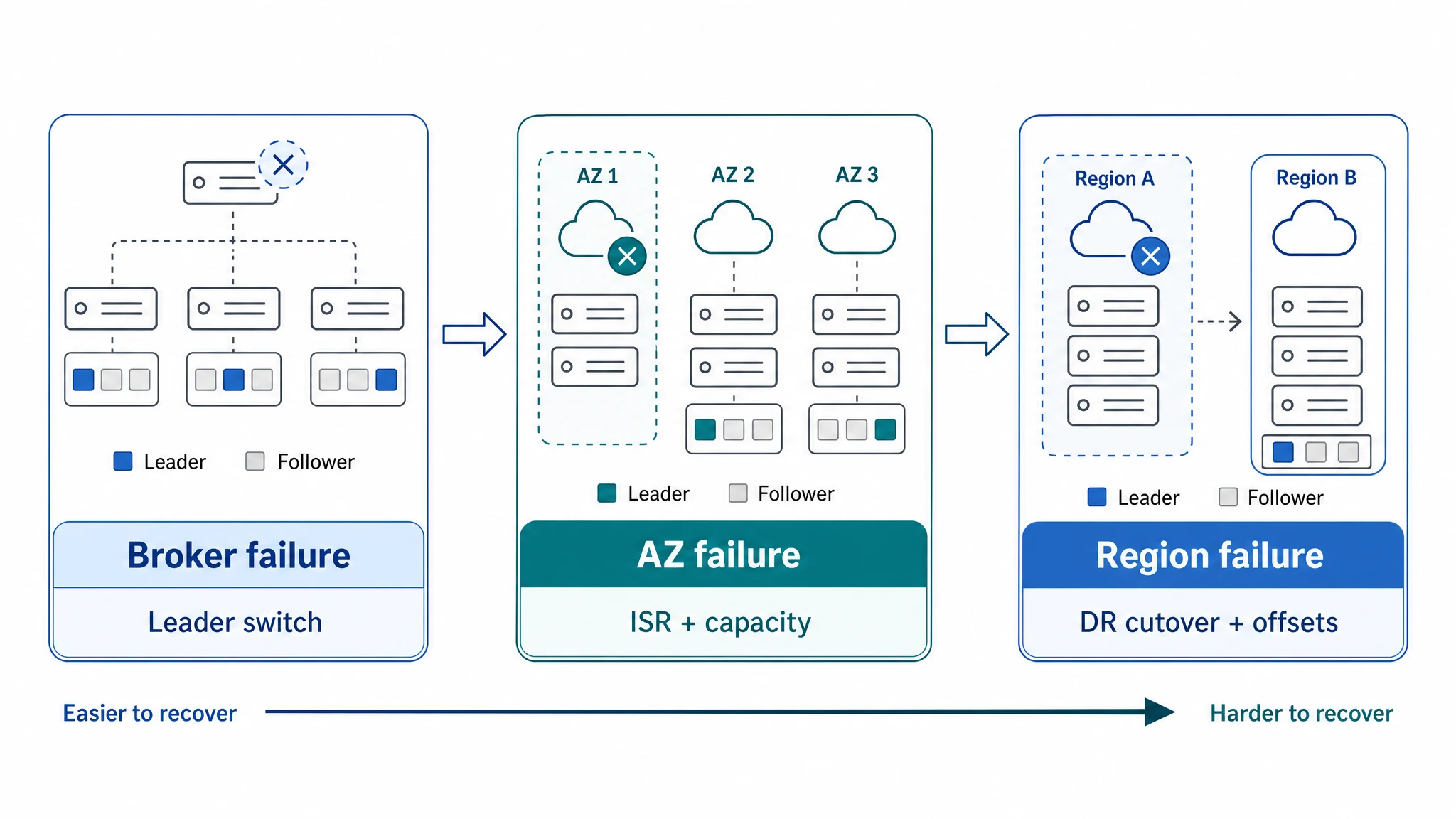
Single-Cluster Failure Domain: Takeover and Capacity
Inside one cluster, when a broker, node, or AZ fails, Kafka needs to keep serving traffic in that same cluster: confirm ISR, move partition leadership, refresh client metadata, and keep producers and consumers moving. Replication Factor defines how many replicas exist, while min.insync.replicas defines the minimum synchronized replicas required for a successful write. Those settings cover the “do we have enough replicas?” part of the problem. Recovery still depends on whether leadership moves cleanly, clients reconnect in time, remaining brokers have enough capacity, and lagging replicas can catch up.
Traditional Kafka recovery becomes heavy here because brokers handle both compute and local persistence. Each partition is copied to multiple brokers, which means the same log is maintained across several local disks. This model made sense in the data center era and has supported Kafka production deployments for years. In the cloud, however, it overlaps with cross-failure-domain durability capabilities such as object storage, and it means post-failure replica recovery, scaling, and partition reassignment can all involve data movement.
That directly affects availability after a failure. After a broker goes down, leadership can move to other replicas, but the remaining brokers still have to serve more traffic. If the cluster was already close to saturation, applications may still see higher latency, throttling, or client errors. When an AZ has problems, the remaining AZs need not only available replicas, but also enough ISR, healthy leaders, and compute capacity. Availability recovery does not end when a failover action completes; it ends when the service can stably handle post-failure traffic.
AutoMQ’s entry point for single-cluster high availability is to reduce the binding between brokers and locally persisted data. AutoMQ keeps Kafka protocol and semantic compatibility, but moves the storage layer that traditional Kafka binds to broker-local disks into shared object storage. Brokers become closer to stateless compute nodes, while durable data is handled by shared storage. A broker failure is first a compute-node loss, not the loss of a set of local partition replicas.
With AutoMQ’s Shared Storage architecture, single-cluster recovery can avoid one of the heaviest steps: copying a full partition replica to a new node before it can help. In traditional Kafka, leader movement depends on ISR state; later, restoring replica count or rebalancing capacity through partition reassignment often moves data. In AutoMQ, a partition’s durable data is not tied to the failed broker’s local disk. After a failure, a healthy broker can restore serving state from shared durable data and then take over reads and writes for that partition. Because recovery does not have to wait for a full replica copy, healthy brokers or newly added brokers can join scheduling and traffic redistribution faster, so cluster capacity recovers faster as well.
Cross-Region Disaster Recovery: Consistency and RTO
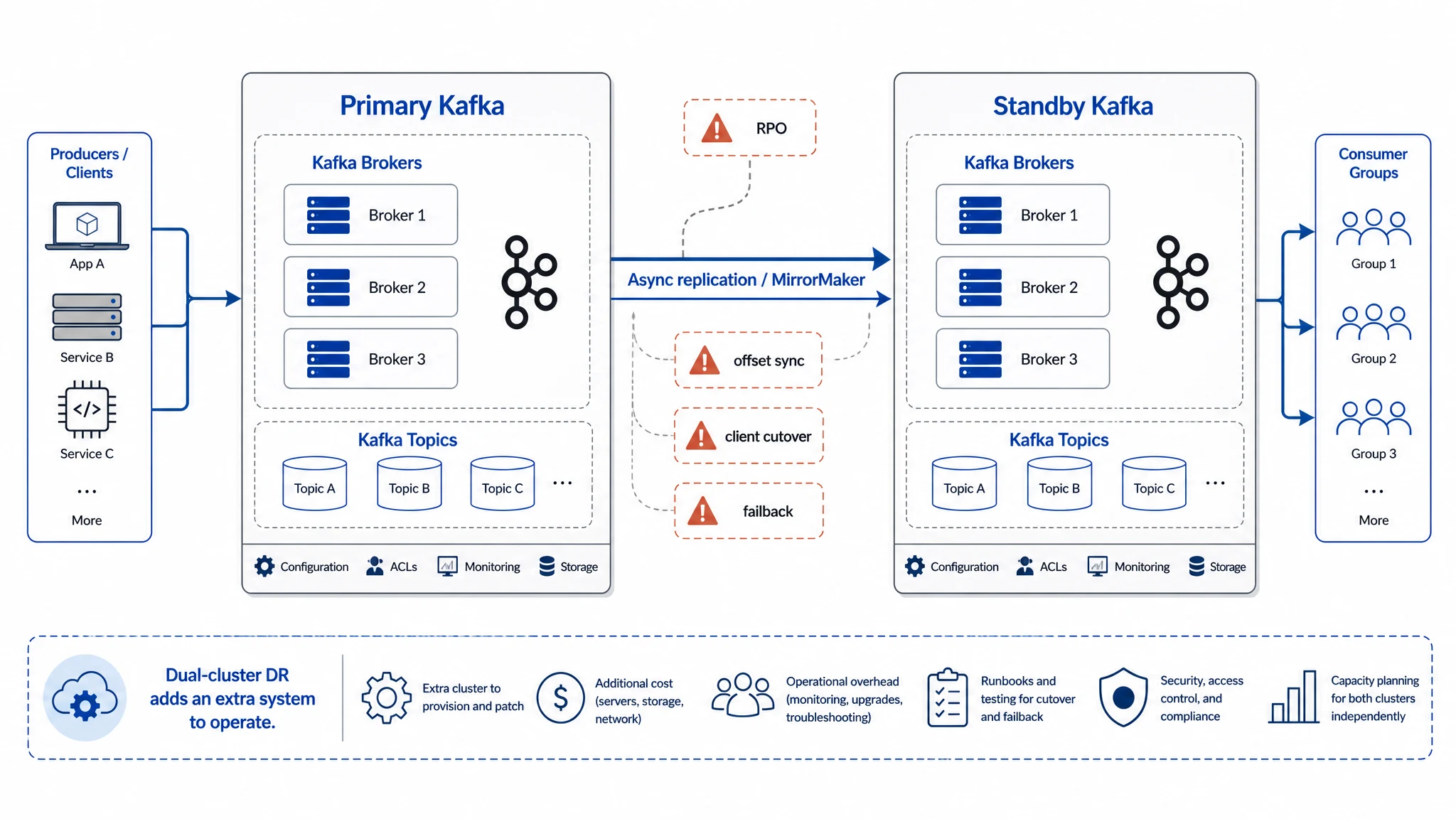
Even a well-designed single-cluster HA plan usually stays within one Region and at most covers broker, node, or AZ failures. When a cross-Region failure happens, or when the full cluster cannot keep serving traffic because of a bad rollout, metadata corruption, or network isolation, platform teams usually prepare an independent DR cluster: the primary cluster serves live traffic, while the DR cluster continuously receives replicated data and can be promoted when needed.
Traditional dual-cluster Kafka disaster recovery has two main challenges: consistent recovery and keeping RTO short enough.
Consistent recovery comes first. MirrorMaker 2, Kafka Connect, or a custom replication pipeline can continuously copy data into the DR cluster, but at cutover time, consumer group offsets, Flink checkpoints, replication lag, failback, and reconciliation still have to line up. Traditional asynchronous replication based on MirrorMaker 2 can solve data copy, but the quality of recovery still depends on how far the DR cluster lags, where applications should resume, and whether downstream state can align with Kafka offsets. Replication answers whether data arrived. Consistent recovery answers whether the business can continue from the correct position.
The other challenge is RTO: when a failure happens, can the platform restore the business entry point quickly enough to deliver an almost seamless, seconds-level recovery experience? In traditional replication-based DR, cutover and promotion are often manual operations involving DNS changes, client reconnects, and application restarts, so RTO is often measured in minutes or longer.
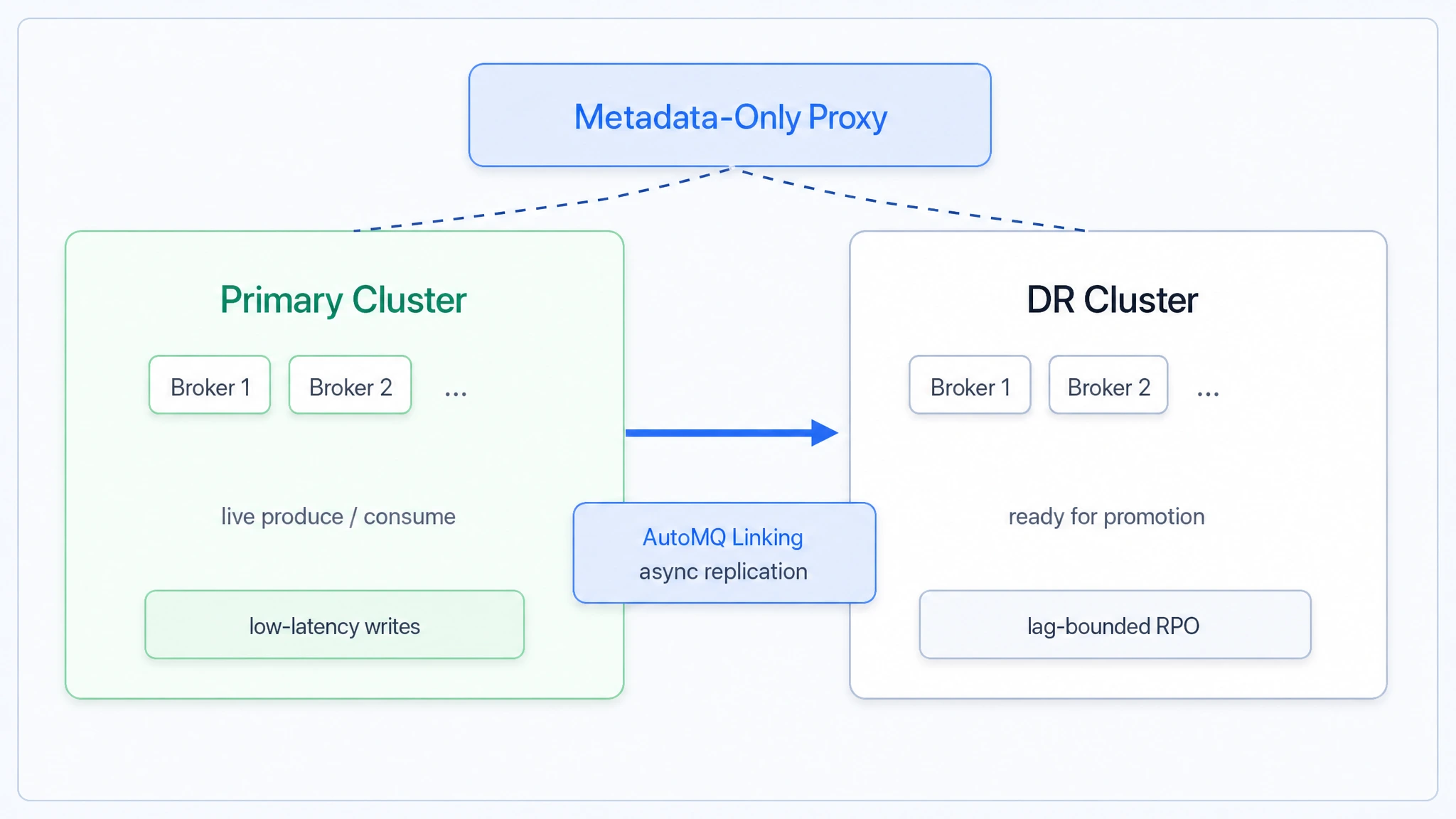
To address these Kafka disaster recovery challenges, AutoMQ provides Async Kafka Linking DR. The capability is designed around two goals at the same time: seconds-level RTO and consistent recovery.
The primary cluster continues to serve low-latency writes, while AutoMQ Linking uses byte-level replication to asynchronously copy data into an independent DR cluster and preserve offset consistency between the source and target clusters. When disaster recovery is needed, Metadata-only Proxy provides automatic traffic switching so applications can move to the DR cluster without application-side cutover logic, while consumer groups and Flink jobs recover from aligned checkpoint positions.
AutoMQ uses Metadata-only Proxy to provide a consistent entry point for the primary and DR clusters. When a failure happens, it can automatically promote the DR cluster to primary, keep the business available, and provide a seconds-level RTO experience. The proxy handles metadata requests, placement decisions, and failover routing, while produce and consume traffic still goes directly to AutoMQ Brokers. It is a lightweight component designed specifically for disaster recovery.
Summary: Think About Availability in Three Layers
The Coinbase incident is a useful reminder that correct parameters are only the starting point. Platform teams still have to answer three recovery questions: within one cluster, can service take over quickly; after takeover, can capacity absorb traffic; across Regions, can the business recover from the correct position in the DR cluster.
| Layer | Question | AutoMQ approach |
|---|---|---|
| HA | During single-cluster failures, can service move and does data remain safe? | Shared Storage architecture, healthy brokers taking over partition reads and writes, controller-driven failover |
| Capacity recovery | After failover, can the remaining compute pool serve shifted traffic? | Stateless brokers, fast scale-out, Self-Balancing |
| DR | During Region failure, cluster abnormality, or cutover to a DR cluster, can the business switch quickly and recover from the correct position? | Multi-cluster isolation, Metadata-only Proxy, AutoMQ Linking, offset alignment, Async Kafka Linking DR |
This is AutoMQ’s basic approach to Kafka availability: absorb part of the recovery complexity in the architecture. Shared Storage shortens the single-cluster HA path, fast scale-out restores capacity, and Async Kafka Linking DR provides seconds-level RTO and consistent recovery for cross-Region disaster recovery. If you are interested in AutoMQ’s cluster high availability and cross-Region disaster recovery capabilities, contact us to discuss which layered availability architecture fits your Kafka workload.


