
We have operated hundreds of bare-metal Kafka clusters for years, and the biggest pain point has always been consumer backlog during peak traffic dragging down cluster-wide write performance. After switching to AutoMQ, producer P99 latency on our log search platform dropped from 10 seconds to 500 milliseconds, backlog fell by 40x, and hardware costs were cut in half. Our team can finally shift focus from infrastructure operations to business optimization.
Author: Wang Renyi, Zhihui Cloud Middleware Team, Qihoo 360 Cloud Platform
About Qihoo 360
Qihoo 360 is a leading internet security company in China, as well as a pioneer and advocate of free internet security. Since its founding in 2005, it has launched products such as 360 Safeguard, 360 Mobile Guard, and 360 Secure Browser, serving hundreds of millions of users. As its business footprint expanded from security into search, gaming, smart hardware, and more, 360's internal data volume has continued to grow: every day it generates logs at the hundred-billion scale, with PB-scale data that must be collected, transmitted, and analyzed in real time.
The foundation supporting all of this is the Qihoo 360 Cloud Platform. As the group's central technical platform, it provides foundational cloud services such as storage, compute, and middleware for all business lines, and Kafka is its most critical event streaming layer. The production environment runs hundreds of Kafka clusters, primarily deployed on bare metal, with a single-topic peak of 600,000 QPS and a cluster peak of 5 million QPS.
As cluster scale kept growing, operating costs and isolation issues became increasingly prominent: hardware failure handling, scale-out and reassignment, and catch-up reads dragging down writes are all long-standing pain points in large-scale bare-metal Kafka.
Under the broader trend toward cloud-native and serverless architectures, the Qihoo 360 Cloud Platform began asking: is there a more advanced Kafka architecture that better fits the cloud era?
The team started evaluating next-generation solutions, and AutoMQ's S3-based diskless Kafka architecture drew attention: separation of compute and storage, isolation of read/write paths, and second-level elastic scaling addressed exactly the most painful problems Qihoo 360 faced in large-scale Kafka operations. Meanwhile, Qihoo 360's internal team had already built a distributed storage system based on Apache Ozone that supports the standard S3 API protocol, which meant the object-storage foundation required by AutoMQ was already in place and deployment conditions were mature.
The Cold Read Problem
Catch-up reads are a very common scenario in event streaming systems: due to downstream processing bottlenecks or batch jobs, consumers need to resume consumption from earlier offsets and read "cold data" that is no longer in memory. For most event streaming systems, this should not be difficult, but Apache Kafka's architectural design turns cold reads into a global performance killer.
The root cause lies in two key technical choices in Kafka's read/write path:
-
Page Cache cannot distinguish hot and cold data. Kafka fully delegates memory management to the OS Page Cache and does not perform hot/cold separation itself. When consumers read cold data, large volumes of disk data are loaded into Page Cache, squeezing out memory space for hot data, so even real-time consumption (tail read) that could originally read directly from memory starts frequently triggering disk IO.
-
The SendFile system call blocks network threads. Kafka's zero-copy mechanism relies on the SendFile system call, and this call occurs in Kafka's network thread pool. When SendFile needs to copy cold data from disk, it blocks network threads. Because the same thread pool handles both read and write requests, cold reads not only slow themselves down but also cascade into degraded write performance across all topics in the same cluster.
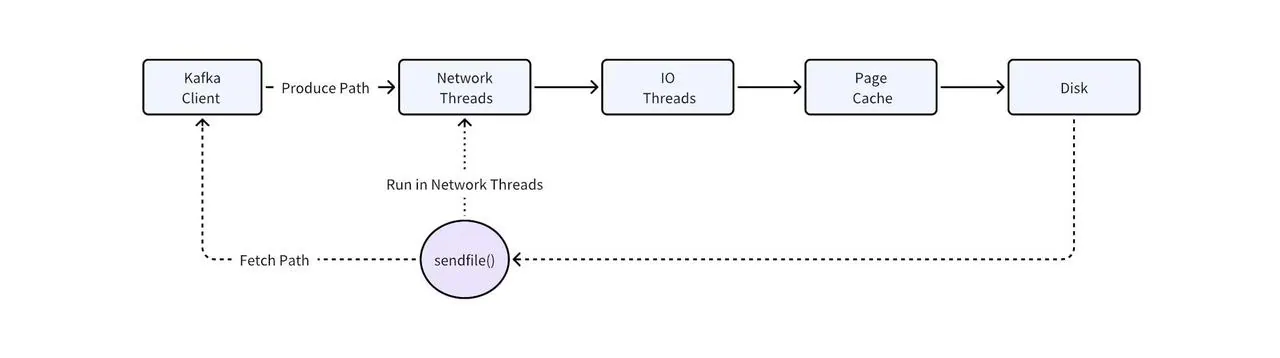
This is a known architectural issue (KAFKA-7504) that has not yet been fundamentally resolved.
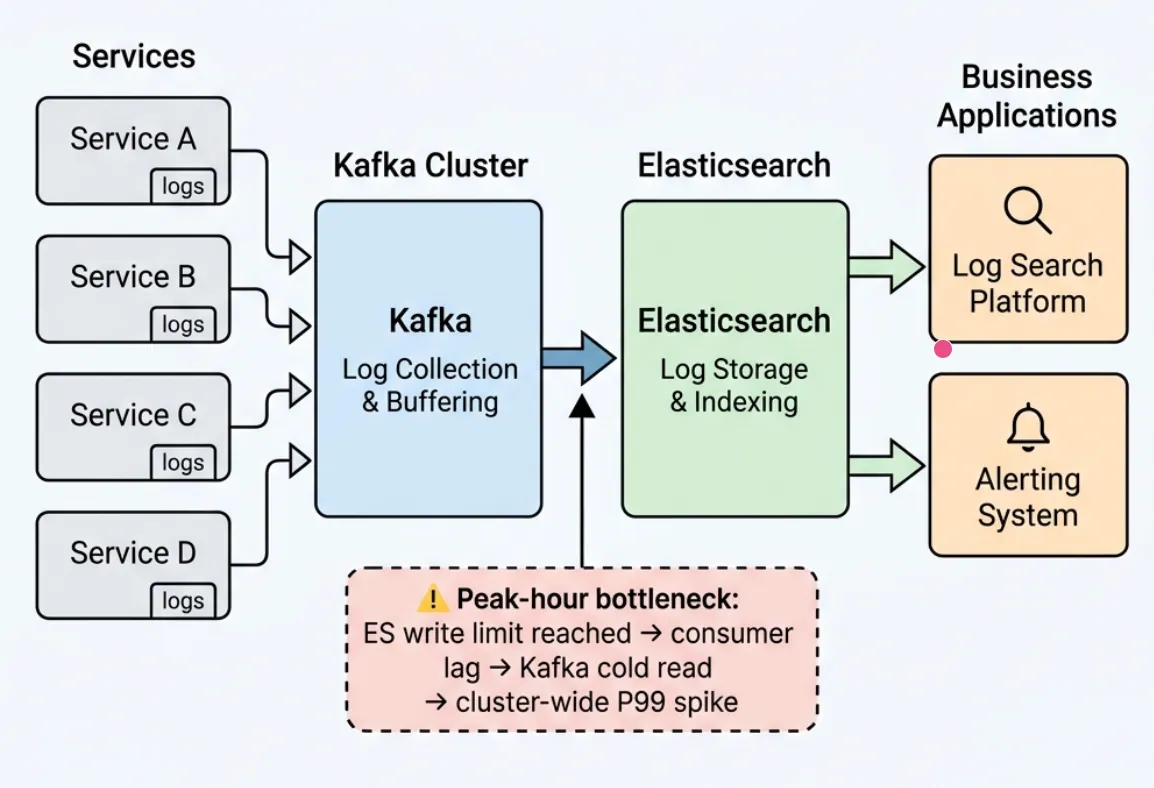
The Qihoo 360 Cloud Platform has experienced this firsthand. One core workload is a unified online log search platform. Runtime logs from all services are collected through Kafka and written centrally to Elasticsearch, where business teams run log search and alerting. This workload has clear peaks and valleys: during daily traffic peaks, downstream ES writes hit bottlenecks, consumers fall behind producers, and message backlog starts to build, which is exactly the cold-read scenario described above. In practice, during peak periods backlog reached 1 billion messages (about 200 GB), cluster write P99 surged to around 10 seconds, and topics for other businesses in the same cluster were also affected, making timely log search and alerting impossible to guarantee.
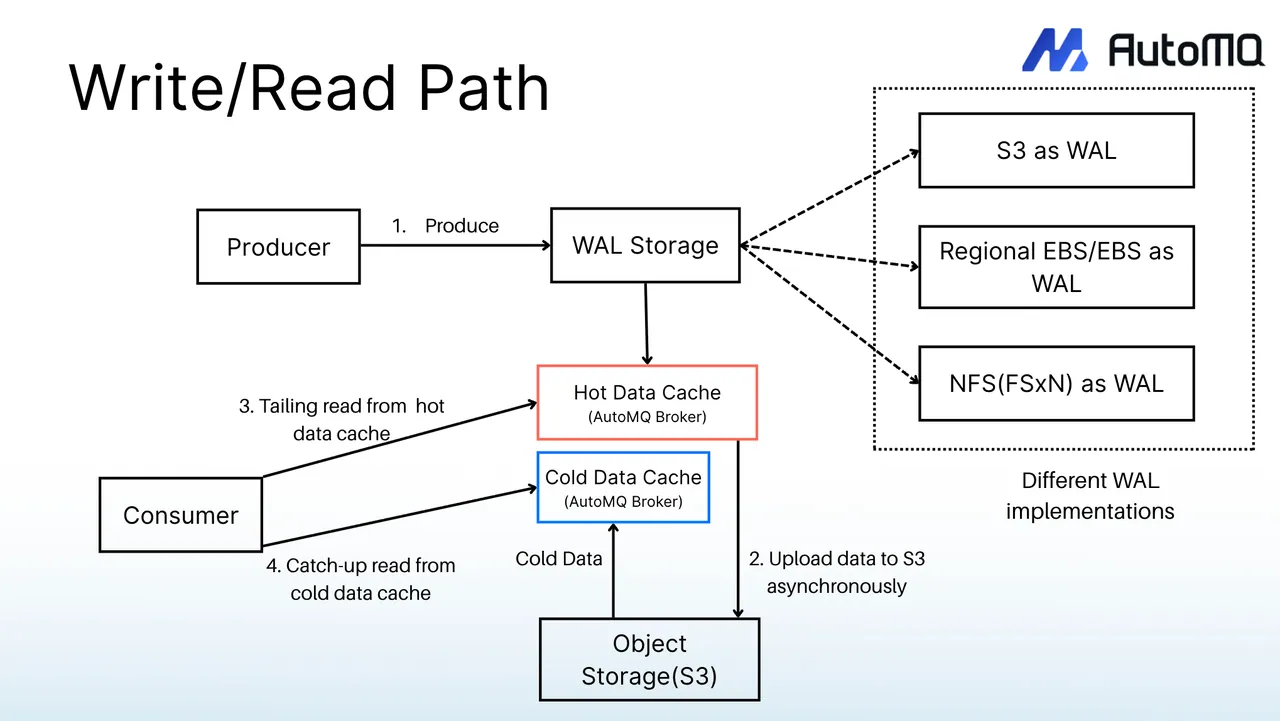
AutoMQ considered hot/cold data isolation from day one and splits the data path into three independent channels:
| Path | Responsibility | Storage Medium |
|---|---|---|
| Write Path | Writes | Direct IO -> WAL (Write-Ahead Log, local disk) |
| Tail Read Path | Real-time consumption (hot data) | Memory |
| Cold Read Path | Catch-up read (cold data) | Object storage |
Writes use Direct IO to bypass Page Cache, fundamentally preventing cold reads from interfering with the write path. Cold reads use the high-throughput channel of object storage, fully leveraging object storage bandwidth without competing with writes or real-time consumption. The three paths are fully isolated at the architectural level, which means no matter how much backlog downstream consumers accumulate, catch-up reads do not affect producer write performance.
For Qihoo 360, AutoMQ's three-path architecture directly addresses the cold-read issue on the log search platform. At the same time, AutoMQ is 100% Kafka protocol-compatible, so Qihoo 360's existing business code and self-developed client framework required no changes; its cloud-native K8s deployment model also naturally aligns with the fully containerized infrastructure already in place on the Qihoo 360 Cloud Platform.
Performance Validation
Before putting it into production, the Qihoo 360 team built an evaluation cluster on Kubernetes and systematically validated AutoMQ across three dimensions: baseline latency, cold-read isolation, and elastic scaling. The evaluation cluster used StatefulSets to separately manage AutoMQ Controllers (2C/4GB) and Brokers (4C/16GB), with data persisted to object storage.
Performance Benchmark Testing
After the evaluation environment was ready, the first step was to verify whether baseline latency met production requirements. On an 8-node Broker cluster, the Qihoo 360 team used the industry-standard OpenMessaging Benchmark framework and ran stress tests at two load levels, 100 MiB/s and 500 MiB/s (acks=all, returning success only after data persistence):
Send Latency (ms)
| Percentile | 100 MiB/s | 500 MiB/s |
|---|---|---|
| Avg | 1.28 | 1.51 |
| P50 | 0.99 | 0.84 |
| P95 | 1.55 | 2.83 |
| P99 | 11.98 | 19.13 |
End-to-End Latency (ms)
| Percentile | 100 MiB/s | 500 MiB/s |
|---|---|---|
| Avg | 2.2 | 22.55 |
| P50 | 2.0 | 19.0 |
| P95 | 3.0 | 46.0 |
| P99 | 14.0 | 65.0 |
Catch-up Read Isolation Testing
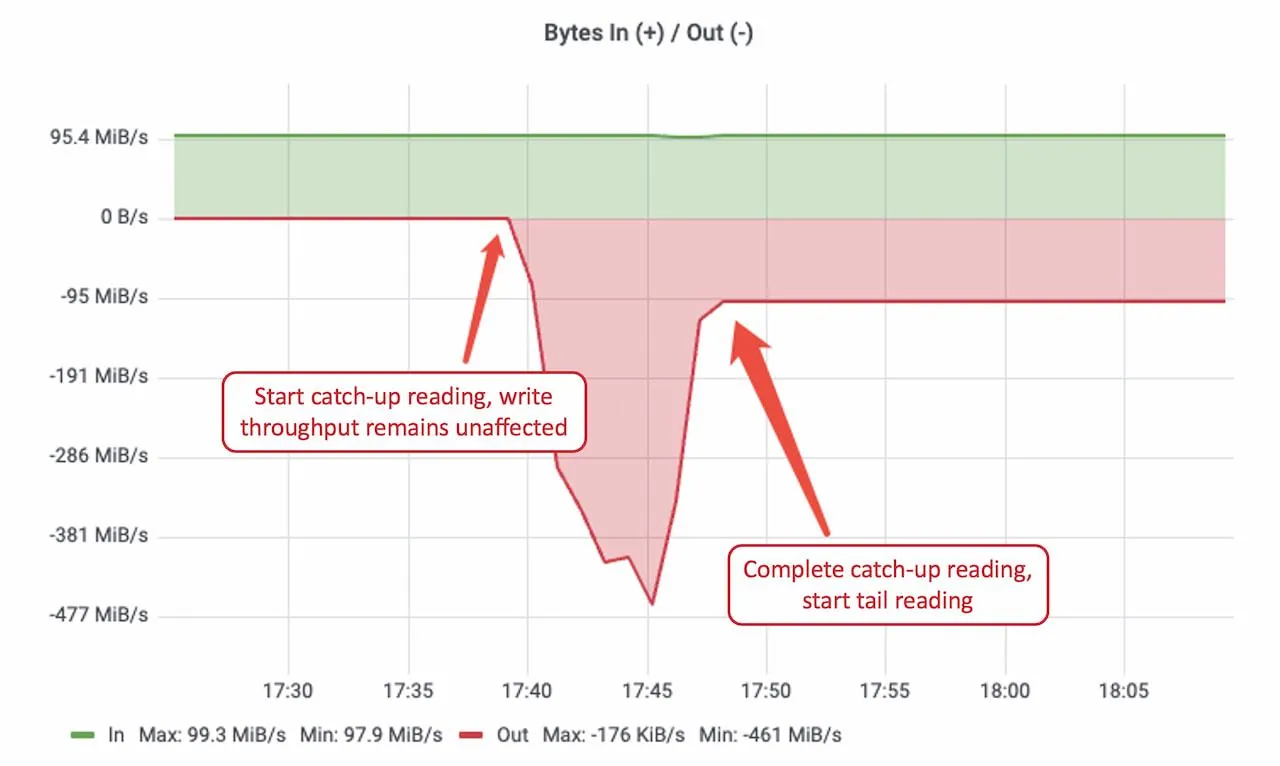
The Qihoo 360 team continuously produced at 100 MiB/s and, after accumulating 100 GiB of data, started consumers from the earliest offset to simulate peak-time cold reads. Results showed that write rate and latency remained stable during catch-up reads, while catch-up read throughput peaked at around 461 MiB/s, enabling rapid backlog drain. Isolation between read and write paths was validated.
Elastic Scaling Testing
For a team like Qihoo 360 operating hundreds of Kafka clusters, elastic scaling capability directly determines operational burden. The core reason traditional Apache Kafka scale-out is slow is that Brokers are stateful: each Broker stores large amounts of partition data on local disks, and when new nodes are added, this data must be reassigned across the network to achieve load balancing. The larger the data volume, the slower the reassignment, often taking hours or even days. AutoMQ's compute-storage separation fundamentally changes this: all data is persisted in object storage and Brokers are stateless. After a new node starts, it only needs to take over partition metadata, with no data reassignment, enabling second-level partition reassignment and minute-level elastic scale-out. After scale-out, AutoMQ's built-in Self-Balancing continuously monitors node load and dynamically schedules partition assignment, ensuring traffic is automatically balanced across old and new nodes.
The Qihoo 360 team designed an extreme scenario to validate this capability: the cluster started with only one Broker, then created a topic with 1,000 partitions and immediately sent traffic at 1 GiB/s. From monitoring alert trigger to bulk scale-out to automatic traffic balancing, the entire process finished in 4 minutes without manual intervention, as shown below.
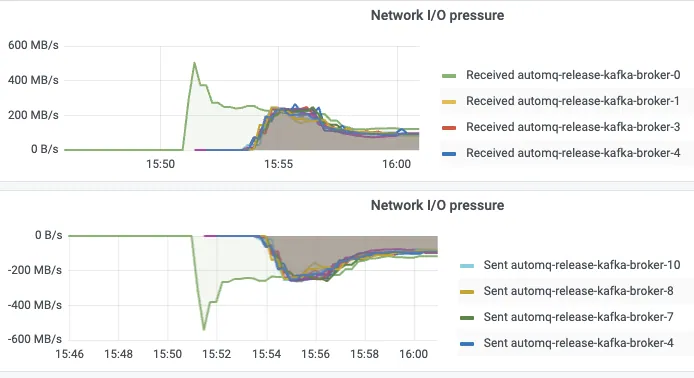
| Stage | Duration |
|---|---|
| Monitoring alert | 60s |
| Bulk scale-out | 60s |
| Self-Balancing | 120s |
| Total | 4 minutes |
Compared with traditional Kafka scale-out, which often requires hours of data reassignment, this result means that when Qihoo 360 faces burst traffic in the future, it can truly achieve automated elastic response instead of relying on manual on-call operations and large pre-provisioned redundant resources.
Evaluation Conclusion
All three rounds of testing met expectations. Baseline latency remained at the millisecond level even with acks=all; write performance was completely unaffected during catch-up reads, and the architectural promise of hot/cold isolation was validated in real tests; elastic scaling from 0 to 1 GiB/s took only 4 minutes, fundamentally changing the operations model of traditional Kafka scale-out.
Production Results
Based on the evaluation results, the Qihoo 360 team decided to migrate the log search platform, the workload with the most prominent cold-read issue, as the first production workload to AutoMQ.
Production Deployment Architecture
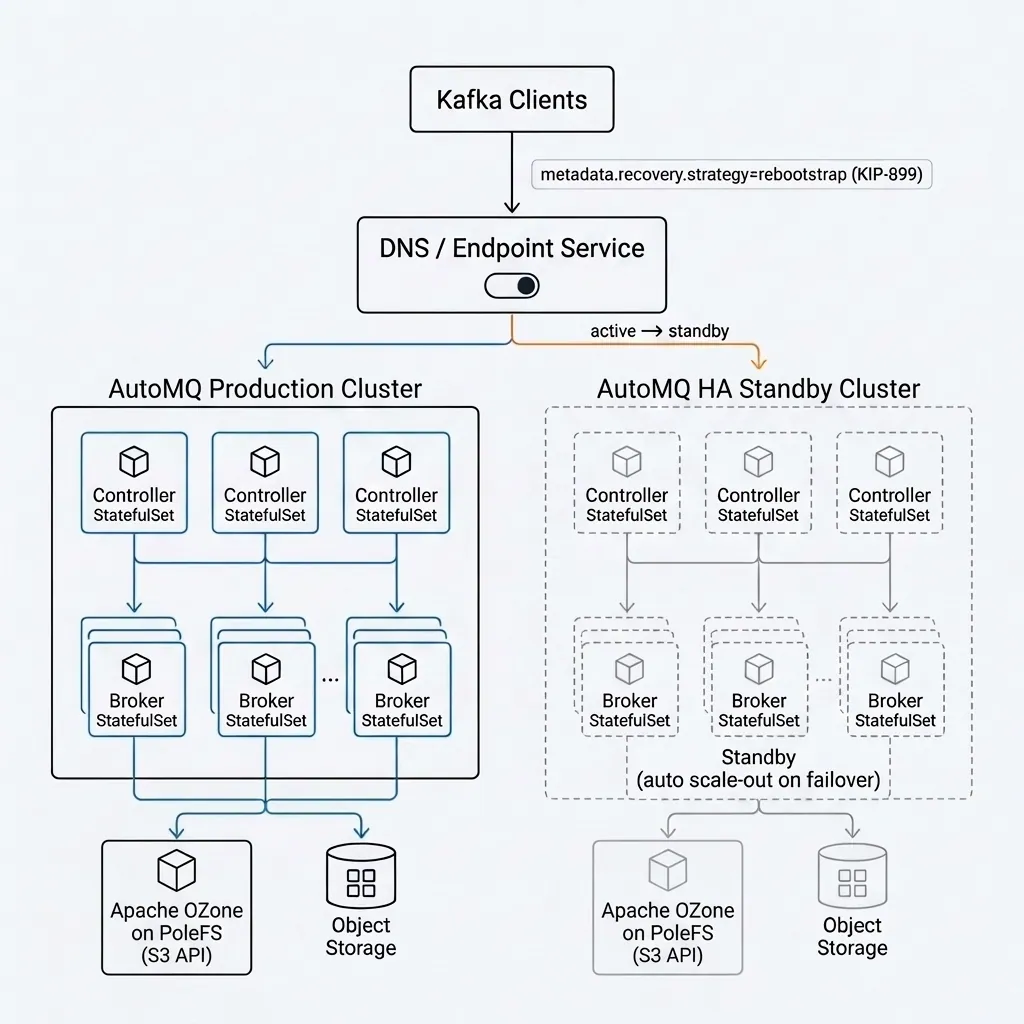
The production environment followed the deployment model from the evaluation phase. AutoMQ's architectural principle is to offload data durability and availability to cloud storage, where the high availability of object storage itself is the foundation of the entire architecture. To further improve availability on top of this, Qihoo 360 additionally designed a cluster-level failover solution.
Qihoo 360's approach is straightforward: each AutoMQ cluster is paired with one HA standby cluster, and cluster metadata is synchronized on a schedule. The production cluster continuously monitors health through real-time write checks. Once an anomaly is detected, cluster DNS resolution is automatically switched to the standby cluster, and the cluster address returned by the Endpoint service is updated at the same time. On the client side, metadata.recovery.strategy=rebootstrap (Kafka KIP-899) is configured, so after a failure, clients automatically reinitialize connection addresses to complete cluster switching, and the standby cluster elastically scales on demand to take over traffic. This approach fully leverages the stateless nature of AutoMQ Brokers: the standby cluster does not need to preload data and only needs to scale out quickly at switchover time.
For resource configuration, a single log search cluster deploys 30 Broker Pods (4C/16GB) during peak periods, with HPA-based auto scaling and automatic scale-in during off-peak periods to save resources. Compared with Qihoo 360's previous bare-metal Kafka that required long-term reservation of large numbers of physical machines for peak traffic, containerized deployment has delivered a qualitative improvement in resource utilization.
Go-Live Benefits
After the log search platform switched to AutoMQ, the long-standing peak backlog issue was completely resolved. The key metrics before and after migration are compared below:
| Before Migration (Apache Kafka) | After Migration (AutoMQ) | |
|---|---|---|
| Peak backlog | 1 billion messages, about 200 GB | Reduced by 40x, about 5 GB |
| Producer P99 | About 10 seconds | About 500 milliseconds |
| Isolation | Other topics in the same cluster were affected during backlog | Read/write fully isolated; other topics unaffected |
| Hardware cost | Bare-metal physical machine clusters with high compute/storage cost | Innovative diskless Kafka architecture significantly reduced compute and storage consumption, saving about 50%+ in cost |
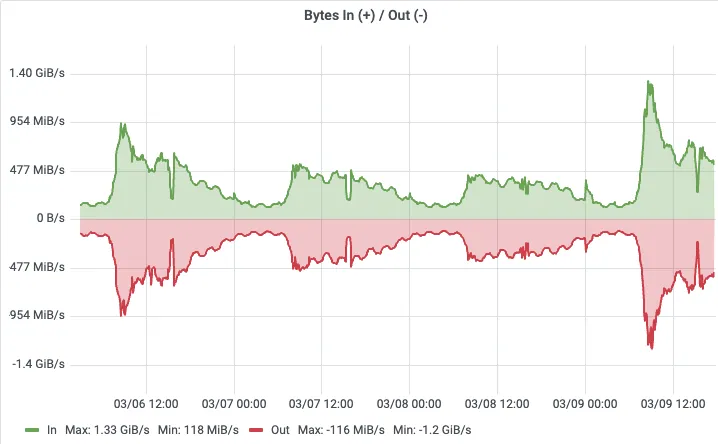
Throughput monitoring shows that after migration, peak throughput on the log search cluster reached 1.4 GB/s during business peaks, and 30 Pods of 4C/16GB could sustain it stably, with smooth write curves and no spikes.
For storage, data is automatically persisted to object storage, and storage capacity scales elastically with business volume. There is no need to pre-plan disk capacity, and there is no longer the operational burden of disk-space alerts from the bare-metal era.
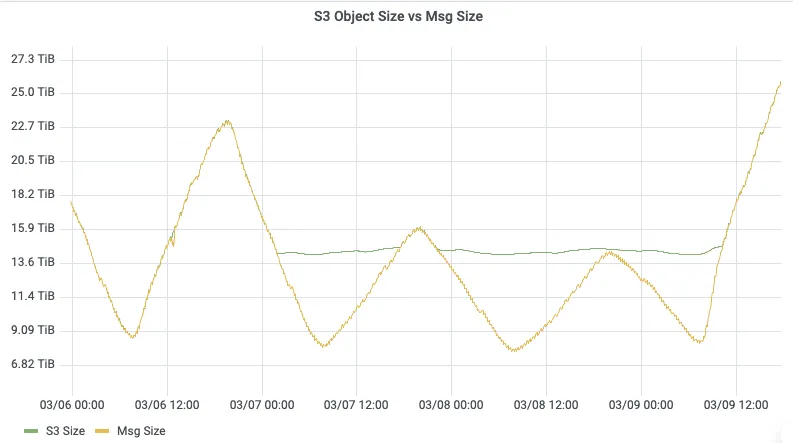
The most intuitive comparison is the Consumer Lag curve: before migration, peak backlog during business peaks exceeded 1 billion messages; after migration, under the same business traffic, backlog dropped by 40x, and consumers could quickly catch up with producers.
The most critical change is isolation: before migration, peak-period backlog would pollute Page Cache through cold reads and cascade into write degradation for all topics in the same cluster; after migration, because AutoMQ isolates read/write paths completely at the architectural level, even if downstream ES experiences write bottlenecks and consumer backlog accumulates, producer-side write latency still stays at the millisecond level, ensuring timely log search and alerting.
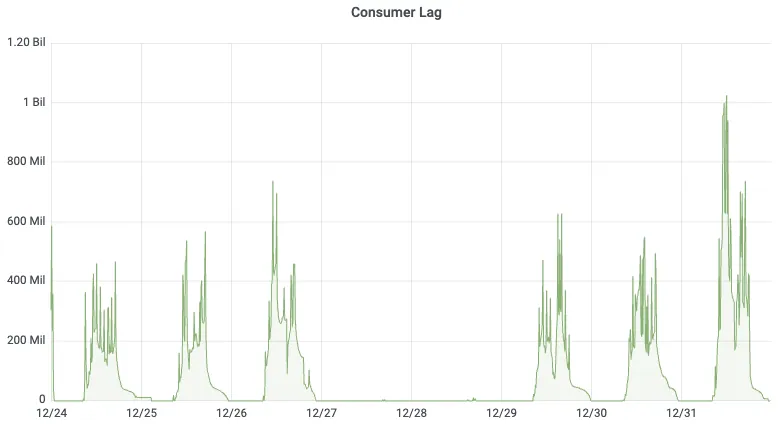 Consumer Lag before switching to AutoMQ
Consumer Lag before switching to AutoMQ
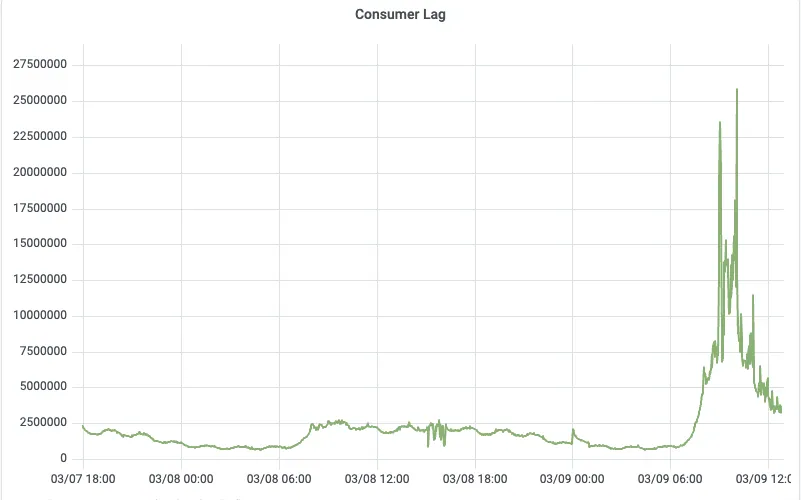 Consumer Lag after switching to AutoMQ (40x backlog reduction)
Consumer Lag after switching to AutoMQ (40x backlog reduction)
Future Outlook
The production launch of the log search platform validated AutoMQ's feasibility in Qihoo 360's production environment. As the group's central technical platform, the Qihoo 360 Cloud Platform carries hundreds of Kafka clusters across many business scenarios, including log collection, real-time computing, monitoring and alerting, and data synchronization. The log search platform is only the first step. Next, the team plans to gradually roll out AutoMQ to Kafka clusters across more business lines, fully leveraging the elasticity and cost advantages brought by compute-storage separation, and ultimately completing an overall upgrade from bare-metal deployments to a cloud-native Kafka architecture.