
Preface: High Availability Is Not an Option—It's the Baseline
What Is RTO?
Before diving into the technical specifics, we must align on a critical metric: RTO (Recovery Time Objective).
In the context of distributed systems, RTO isn't just an abstract SLA figure; it's a ticking stopwatch. It represents the maximum allowable duration from the onset of a failure to the moment the system restores full service capacity. For SRE and DevOps teams, RTO is the "golden hour"—the race against time between a system alert and successful business mitigation.
Why Does Kafka's RTO Matter So Much?
In modern architecture, Apache Kafka has evolved into the "central nervous system" of infrastructure. It is no longer merely a log pipeline; it is the lifeblood of mission-critical business workflows.
Consider a typical anti-fraud scenario: user activity logs flow through Kafka to a risk engine in real-time. Upon detecting an anomalous login, the system must issue a blocking command within milliseconds. If the Kafka cluster goes down due to node failure, every second of RTO represents a massive "blind spot." During those seconds—or even tens of seconds—user accounts remain vulnerable to theft while the system is effectively blind.
Consequently, Kafka's high availability transcends mere system stability; it is directly tied to business security and customer trust. Can we shrink this "blind spot"? How can we ensure Kafka recovers near-instantaneously after a node failure?
The answer is surprisingly simple: sometimes, a single line of configuration is all it takes to cut your RTO in half.
The One-Liner: request.timeout.ms = 15000
A common pitfall in Kafka RTO optimization is an over-fixation on server-side replica scheduling policies. In reality, the client-perceived recovery speed is often dictated by a frequently overlooked client-side parameter: request.timeout.ms.
The Baseline for Partition Fault Tolerance: Three Core Configurations
Before tweaking request.timeout.ms, we must clarify a fundamental prerequisite: the cluster must possess the underlying capability to execute a Leader failover upon failure. If a failure renders a partition permanently unavailable, any discussion regarding RTO optimization becomes moot. Whether a Kafka partition can successfully fail over after a broker crash depends on the synergy of these three settings:
replication.factor: Total number of replicas (e.g., 3).min.insync.replicas(minISR): The minimum number of in-sync replicas required for a successful write (e.g., 2).unclean.leader.election.enable: Determines whether to allow non-ISR replicas to be elected as Leader (default isfalse).
The cluster can only sustain write availability during a single-point failure if the number of replicas in the ISR (In-Sync Replicas) list remains above the min.insync.replicas threshold. Even when this "recoverability" prerequisite is met, why does recovery speed often fall short of expectations? To answer this, we need to dive deep into the latency gap between the server-side state change and client-side perception.
RTO Bottleneck Analysis: The Latency Gap Between Server and Client
Assuming the previously mentioned availability prerequisites are met, the actual RTO during a broker outage is dictated by the time discrepancy between server-side recovery and client-side perception.
Server-Side Perspective: Rapid Recovery Within 10 Seconds
The server-side recovery process, driven by the Controller's failure detection mechanism, is remarkably efficient:
- Detection Phase: A failed broker stops sending heartbeats. If no heartbeat is received within the
broker.session.timeout.mswindow (default: 10s), the Controller marks the broker as Fenced. - Recovery Phase: The Controller immediately triggers a Leader election, promoting another healthy replica from the ISR to become the new Partition Leader.
Conclusion: From the infrastructure's standpoint, partition availability is typically restored within 10 seconds.
Client-Side Perspective: Metadata Refresh Lag
However, the client does not instantly "perceive" this leader change. It continues to dispatch requests to the stale Leader address until the request eventually times out.
At this stage, request.timeout.ms (default: 30,000ms) becomes the primary bottleneck:
- The client stays in a blocking state, waiting for a response to the current request until the 30-second timeout is reached.
- Only after the timeout occurs does the client proactively refresh its Metadata (to fetch the updated Leader information) and initiate a retry.
Conclusion: This means that even though the server completes its recovery at the 10-second mark, the client remains "stalled" for an additional 20 seconds before it can successfully resume write operations.
Optimization Strategy: Aligning Fault Detection Windows
The analysis above pinpoints the root cause of elevated RTO: a misalignment between client-side timeout thresholds and the server-side failure detection window.
Recommendation: Adjust the client-side request.timeout.ms from the default 30s to 15s.
- The Mechanism: By setting this to 15 seconds, the client will trigger a timeout and initiate a metadata refresh much sooner. This aligns more tightly with the Controller's ~10-second failure detection window, while still providing a 5-second safety buffer to account for transient network jitter.
- The Benefit: This subtle configuration tweak reduces the RTO in single-node failure scenarios from 30 seconds down to approximately 15 seconds—effectively cutting recovery time by 50%.
Apache Kafka RTO Deduction: From Theory to Reality
In the previous section, we successfully reduced the RTO for single-node failures by 50% by tuning request.timeout.ms. While this optimization is highly valuable for day-to-day operations, its effectiveness hinges on a strict boundary condition: the cluster must remain in a recoverable state—meaning the failure is confined to a single node.
However, in distributed system design, we must account for more severe scenarios. As business growth drives cluster expansion, the laws of probability will inevitably push the limits of system availability. To quantify this risk, we have built a probability model based on real-world SLA data, focusing on how RTO fluctuates when driven by broker failures.
SLA-Based Failure Probability Modeling
Taking a standard AWS EC2 instance as an example, the SLA guarantees 99.5% monthly availability. Based on this, the expected annual downtime for a single compute instance is approximately:
(1 - 0.995) × 365 × 24 ≈ 43.8 hours/year
Using this data, we define a standard production-grade Kafka cluster configuration: replication.factor=3, min.insync.replicas=2, and unclean.leader.election.enable=false. Below, we deduce the probability variance between "single-node failures" and "concurrent dual-node failures" across different cluster scales.
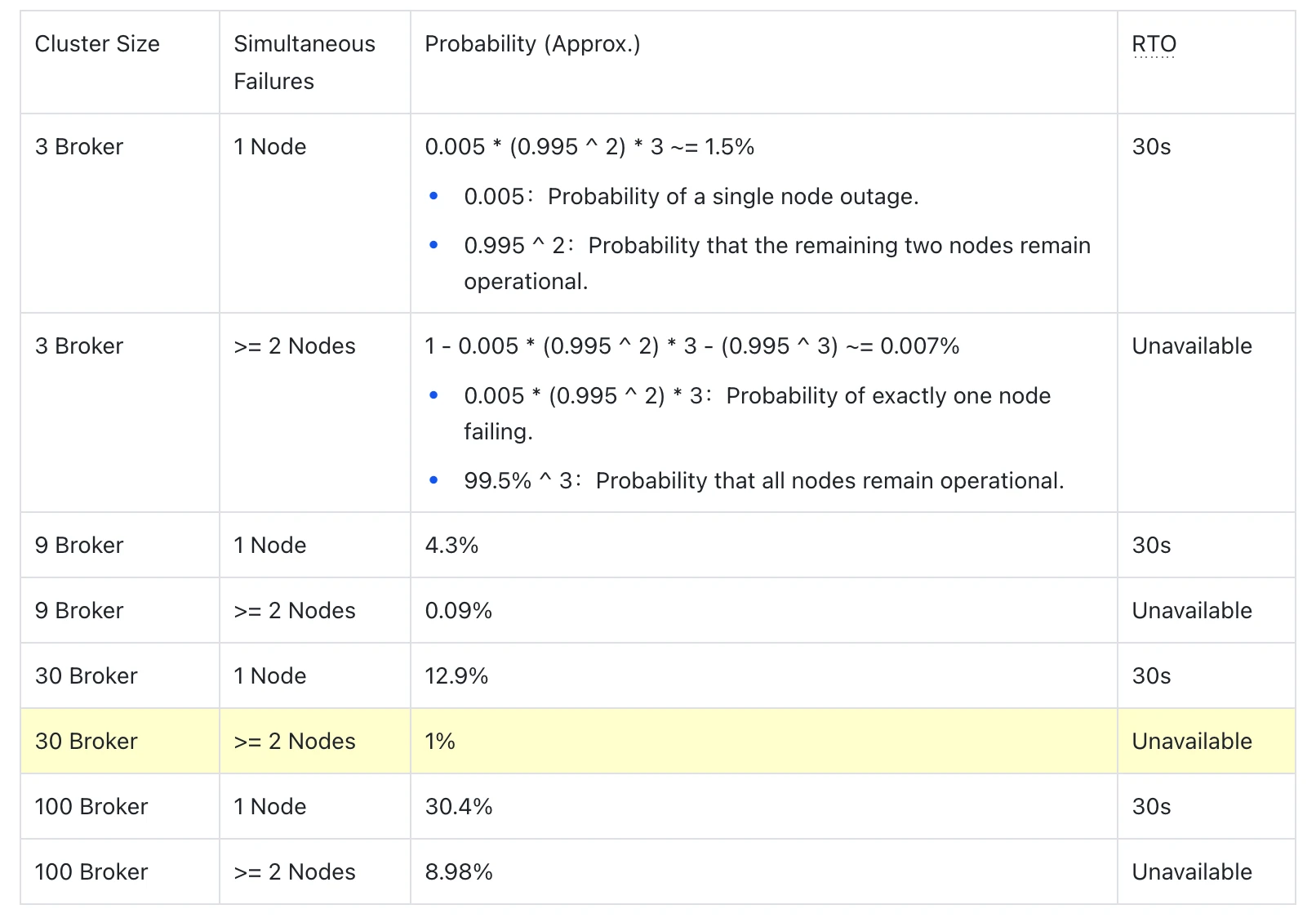
Table 1: Failure Probability Deduction Across Different Cluster Scales
Fault Mode Divergence: Automated Recovery vs. Service Disruption
From the probability model, we can observe that as the number of nodes increases, the system faces two distinct fault modes with fundamentally different RTO characteristics:
Mode 1: Single-Node Failure (Self-Recoverable)
Under a typical configuration of replication.factor=3 and min.insync.replicas=2, the ISR (In-Sync Replicas) usually maintains at least two synchronized copies. When a single Broker crashes, the Controller can rapidly switch the Partition Leader to another surviving replica within the ISR, restoring service within 10 seconds. Clients can successfully resend requests through the built-in retry mechanism within the request.timeout.ms=30s window; the upper-level business will not receive exceptions, perceiving only a transient spike in tail latency.
Trend: As the cluster scales, the frequency of such failures increases, but they are considered "controlled noise" within the system's design parameters and do not compromise service continuity.
Mode 2: Concurrent Multi-Node Failure (Service Outage)
Even if the ISR originally contains 3 synchronized replicas, if ≥ 2 nodes fail simultaneously, the number of surviving ISR replicas will drop below the min.insync.replicas=2 threshold. At this point, even if a new Leader is successfully elected, producer writes will still be rejected due to insufficient replicas, returning a NOT_ENOUGH_REPLICAS error. The system enters a state of sustained unavailability until enough Brokers are restored and the ISR once again satisfies the minISR requirement. In this scenario, RTO is no longer governed by software configuration; it equals the actual physical recovery time of the nodes (which could span several hours).
Trend: Clients will throw timeout or write failure exceptions, directly impacting business continuity.
The Qualitative Shift in Risk at Scale
Data indicates that when a cluster reaches 30 nodes, quantitative change triggers a qualitative shift. The annual probability of "multi-node concurrent failures" approaches 1%.
From an engineering perspective, a 1% probability translates to approximately 87 hours of potential total service unavailability per year. For business scenarios with extremely high SLA requirements—such as financial transactions or core risk control—this represents a systemic risk that cannot be mitigated through operational workarounds alone. Under the architectural constraints of coupled compute and storage, there is a clear ceiling to optimizing RTO through configuration. As cluster size expands, the probability of multi-point failures will breach the defensive lines of configuration optimization, leaving business continuity facing severe challenges.
The Ultimate Solution: Deterministic RTO Based on Disaggregated Storage-Compute Architecture
The RTO bottlenecks inherent in traditional Kafka are, at their core, a direct consequence of its coupled storage-compute architecture. In conventional designs, a Broker acts as both the compute node and the physical custodian of data. This coupling creates a "Node-is-Data" constraint: once a node fails, it doesn't just interrupt service—it often triggers a write block due to insufficient ISR replicas.
To break through this physical limitation requires a fundamental paradigm shift at the architectural level. Modern architectures like AutoMQ adopt a disaggregated storage-compute model, offloading all data to highly available object storage (such as AWS S3). This transforms Brokers into entirely stateless compute units. This design completely decouples RTO from the scale of the failure, reconstructing the disaster recovery workflow to provide two fundamental advantages:
- Universal Partition Takeover: Any surviving node can take over any partition, regardless of where the data was previously "owned."
- Constant RTO: RTO is decoupled from the number of failed nodes, tending toward a near-constant, predictable recovery time.
Deconstructing AutoMQ's Disaster Recovery Mechanism
To understand how this architecture achieves second-level recovery, we need to examine the micro-level mechanics of a failure. In a storage-compute disaggregated architecture, disaster recovery no longer relies on sluggish data migration or replica synchronization; instead, it shifts to rapid metadata handover. AutoMQ's recovery workflow consists of the following four critical phases:
1. Prerequisite: Global Data Visibility
Because all log data is persisted in shared object storage, any Broker can access the complete data of any Partition at any time. This means that regardless of how many nodes fail simultaneously, as long as at least one Broker remains healthy in the cluster, the Partition is eligible for immediate recovery—with no need to wait for replica synchronization or worry about ISR shrinkage.
2. Trigger: Lightweight Leader Failover
Failure Detection: AutoMQ follows the standard Apache Kafka mechanism. If the Controller does not receive a heartbeat within the broker.session.timeout.ms=10s window, it marks the failed Broker as Fenced.
Leader Election Logic: The key difference lies in ISR management. AutoMQ's ISR contains only the current Leader (since data persistence does not rely on local replica synchronization). Therefore, the Controller does not need to coordinate states across multiple replicas. Once the original Leader is fenced, the Controller can immediately designate any surviving Broker as the new Partition Leader and update the ISR to that node.
3. Guarantee: ConfirmWAL Handover and Consistency
AutoMQ's write process returns success as soon as data is persisted to the ConfirmWAL ( a Write-Ahead Log abstraction built on object storage). To maintain data compactness and readability, the system periodically triggers a Commit (every 20 seconds or every 500 MiB), which organizes and uploads data to object storage and records the resulting metadata in the KRaft log.
When the original node is fenced, the Controller assigns a surviving Broker to take over its outstanding ConfirmWAL Commit tasks. Once the ConfirmWAL Commit is complete, the object metadata becomes visible to all nodes via KRaft, allowing the Partition to be successfully opened by the new Leader. Leveraging the high throughput and parallelism of object storage, this process typically completes in < 5 seconds, ensuring data consistency remains intact.
4. Recovery: Second-level Reconstruction based on Checkpoints
Once the newly elected Broker learns via KRaft that it is responsible for a Partition, it immediately loads the Segment metadata from object storage and initiates the recovery process from an UNCLEAN_SHUTDOWN state.
Thanks to AutoMQ's optimized Checkpointing of Partition states, the recovery only needs to replay a small portion of data following the last LogSegment to reconstruct indices (whereas standard Apache Kafka UNCLEAN_SHUTDOWN requires replaying the entire LogSegment). This usually finishes in < 5 seconds, restoring read/write services to the outside world.
Conclusion: RTO Decoupled from Cluster Scale
By integrating these processes, AutoMQ maintains a consistent end-to-end RTO of under 30 seconds in both single-node and multi-node failure scenarios.
More importantly, this RTO performance does not degrade as the cluster scales. Even in clusters with 30 or 100+ nodes, a "concurrent failure of ≥ 2 nodes" no longer signifies a catastrophic business outage; instead, it is handled as a routine event that the system recovers from automatically and rapidly.
Summary: From "Parameter Tuning" to "Architectural Evolution"
The adjustment of request.timeout.ms=15000—though seemingly minor and low-cost—effectively eliminates client-side lag during single-node failures, cutting RTO by approximately 50%. For any legacy Kafka cluster operating on a coupled storage-compute architecture, this is an optimization worth implementing immediately.
However, as architects, we must also recognize the physical limits of configuration tuning.
As cluster size scales, the probability of concurrent multi-node failures increases exponentially. In traditional coupled architectures, the ISR mechanism—which relies on local replica synchronization—has an inherent availability ceiling. Once this defensive line is breached, RTO is no longer governed by software parameters; instead, it is dictated by hardware recovery times or the speed of manual intervention.
A true breakthrough requires a shift in architectural paradigms.
Through its disaggregated storage-compute architecture, AutoMQ offloads data persistence to highly available object storage (such as S3), transforming Brokers into entirely stateless compute units. This design not only removes the dependence of partition recovery on replica synchronization but also achieves the decoupling of RTO from failure scale. Whether one or multiple Brokers fail, services achieve deterministic recovery within 30 seconds.
Moving from "tuning a single line of configuration" to "transitioning to a new architecture" is not an either-or choice, but a natural path of technical evolution: use configuration optimization to safeguard today's SLA, and embrace architectural evolution to secure the certainty of tomorrow.


