
Overview
This article provides an in-depth look at iQIYI's technical journey in evolving from a traditional Kafka architecture to AutoMQ to handle large-scale real-time streaming data. To address challenges in private cloud environments—such as difficult cluster scaling, low resource utilization, and high operational overhead—iQIYI developed the Stream Platform and Stream-SDK, effectively decoupling business logic from underlying storage. Subsequently, the company integrated public cloud services and ultimately transitioned to AutoMQ, leveraging its cloud-native, separation-of-storage-and-compute architecture. By utilizing AutoMQ's single-replica storage and second-level elasticity, iQIYI significantly enhanced system flexibility. This series of architectural upgrades not only optimized their data governance framework but also successfully slashed operational costs by over 70%. Currently, iQIYI is continuously scaling its AutoMQ deployment to further drive long-term efficiency and cost reduction.
Background
Since its inception, Kafka has rapidly become the standard component for streaming data storage due to its high throughput, low latency, and scalability, seeing widespread adoption across real-time Big Data scenarios. iQIYI's streaming data services were also primarily built on Kafka. However, as real-time applications proliferated, the increasing number and scale of Kafka clusters brought about significant challenges, including cumbersome scaling processes, high costs, and difficult governance. To tackle these issues, we embarked on a series of explorations, including "Kafka-as-a-Service," cloud migration, and the transition to AutoMQ.
This article details iQIYI's journey and practical experience in moving Kafka from private to public clouds and evolving from legacy Kafka to AutoMQ.
Applications of Streaming Data at iQIYI
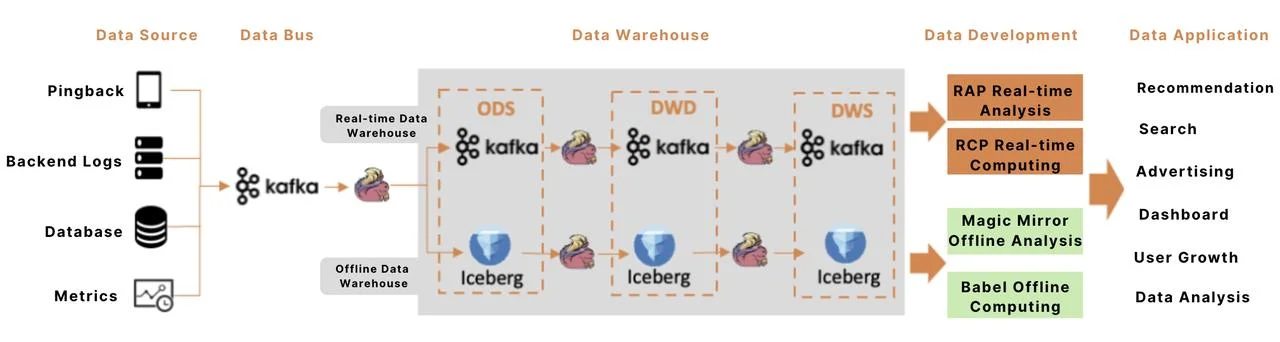
At iQIYI, Kafka is utilized as the storage component for streaming data, while Flink serves as the primary compute engine. A typical streaming data pipeline is illustrated above, encompassing the following key stages:
- Data Integration: Continuous streams of data—including Pingback (client-side delivery logs), backend logs, database binlogs, and metrics—are written to Kafka, the central data bus, in real-time.
- Data Warehousing: Flink applications ingest data into both real-time (streaming) and offline (batch) data warehouses. In the real-time warehouse, data remains in Kafka as streams, with Flink building out the various architectural layers. In the offline warehouse, streaming data is aggregated into batches and stored in Iceberg; Flink then incrementally consumes Iceberg data to construct the offline layers. Real-time warehouses achieve second-level latency, while offline warehouses operate with latencies of minutes or more.
- Data Development: Data from these warehouses is applied to various business scenarios via a data development platform. In real-time computing, Kafka also functions as intermediate stream storage to decouple tasks.
- Data Applications: Data is extensively used across iQIYI's recommendation, search, advertising, and reporting systems. Since data value decays rapidly as latency increases, most core application scenarios have transitioned to streaming data in recent years to maximize its utility.
In summary, Kafka acts as the backbone of the Big Data ecosystem, serving as the data bus for integration, the storage layer for the real-time data warehouse, and the decoupling mechanism between real-time tasks.
Streaming Data Storage Service: From Managing Clusters to Managing Data
iQIYI's streaming data service was initially built around Kafka clusters, providing fundamental capabilities such as cluster lifecycle management, topic management, and consumption monitoring. However, as business scale expanded and both cluster counts and data volumes surged, several pain points emerged:
- Tight Coupling Between Business and Clusters: Business logic relied directly on Kafka bootstrap servers for access. Any cluster migration or adjustment necessitated code changes and redeployments, leading to significant inflexibility. Furthermore, the platform could not centrally identify or monitor the read/write patterns of specific business lines.
- Lack of Unified Data and Schema Management: The platform lacked metadata management for data descriptions, schemas, and data ownership. Without data discovery capabilities, cross-team data comprehension, reuse, and governance became increasingly difficult.
- Absence of Primary-Backup Data Management: For mission-critical data, business units typically configured primary and backup pipelines manually. However, the platform lacked unified management of these relationships, making it challenging to ensure data consistency or implement automated failover governance.
To address these challenges, we upgraded our streaming data storage service to the architecture shown below, consisting of three core components: the Stream Platform, Stream-SDK, and storage components.
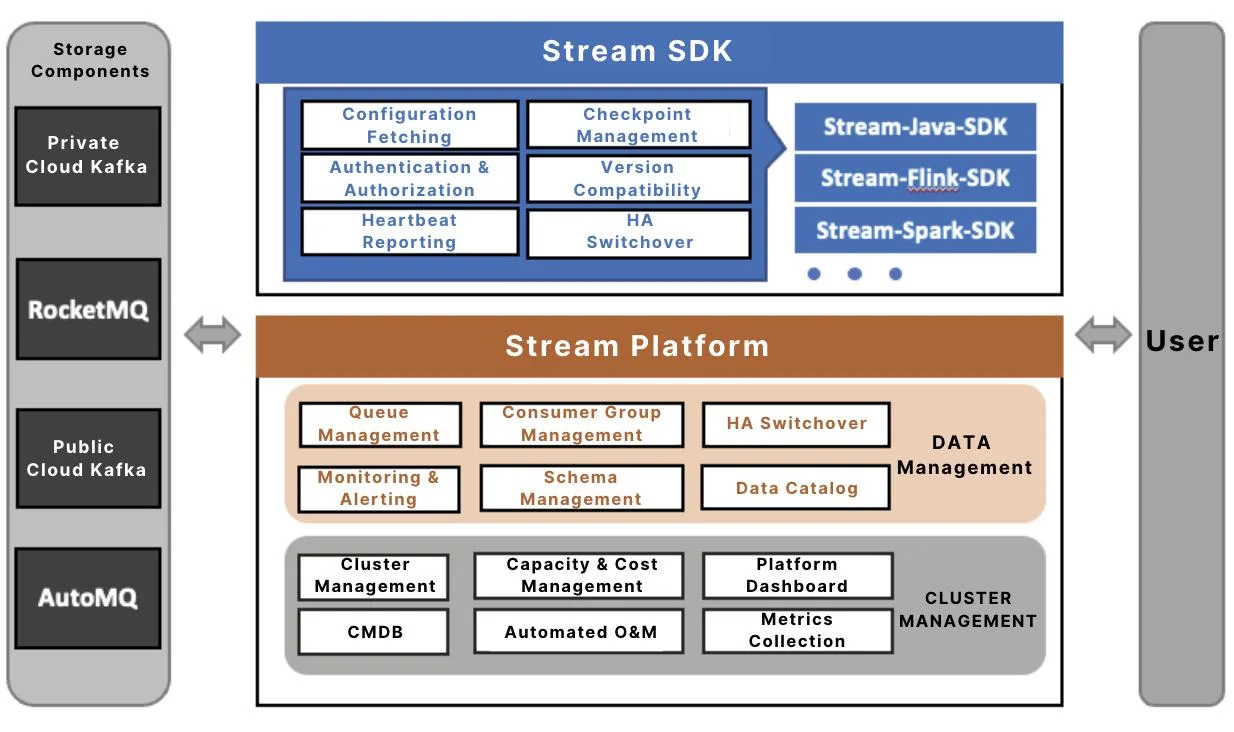
The Stream platform consists of two primary modules: Cluster Management and Data Management. While Cluster Management handles the unified management of cluster lifecycles and underlying resources—focusing on operational efficiency—Data Management serves as the platform's "data-centric" core. It provides data developers with a unified data view and governance capabilities through the following features:
- Logical Queues: We have evolved from the traditional "Cluster + Topic" addressing model to a logical naming convention based on "Project + Queue (Topic)." In this model, the physical cluster is merely an attribute of the queue, effectively decoupling business logic from specific infrastructure. Logical queues also support simultaneous binding to primary and backup clusters, enabling one-click failover via the Stream-SDK.
- Schema Management: The platform supports schema configuration for queues and automatically synchronizes this metadata to the Big Data Metadata Center. This allows queues to be automatically mapped as logical tables within data development platforms, enabling developers to process streaming data directly using SQL.
- Data Map: This provides multi-dimensional discovery and search capabilities for queues. It supports online application and authorization workflows, significantly simplifying cross-team data discovery and reuse.
- Data Lineage: By leveraging read/write metadata automatically reported by the Stream-SDK, the platform constructs application-level lineage maps. This helps developers quickly identify upstream/downstream dependencies and perform impact analysis for changes.
Stream-SDK: A Unified Client for Streaming Data I/O
The Stream-SDK is the platform's unified data access client. It abstracts underlying native clients and maintains full compatibility with both Kafka and RocketMQ protocols. By simply configuring the "Project + Queue" parameters, developers can perform data read and write operations without concerning themselves with specific cluster addresses or authentication methods. This architecture ensures complete decoupling between business logic and the underlying storage infrastructure.
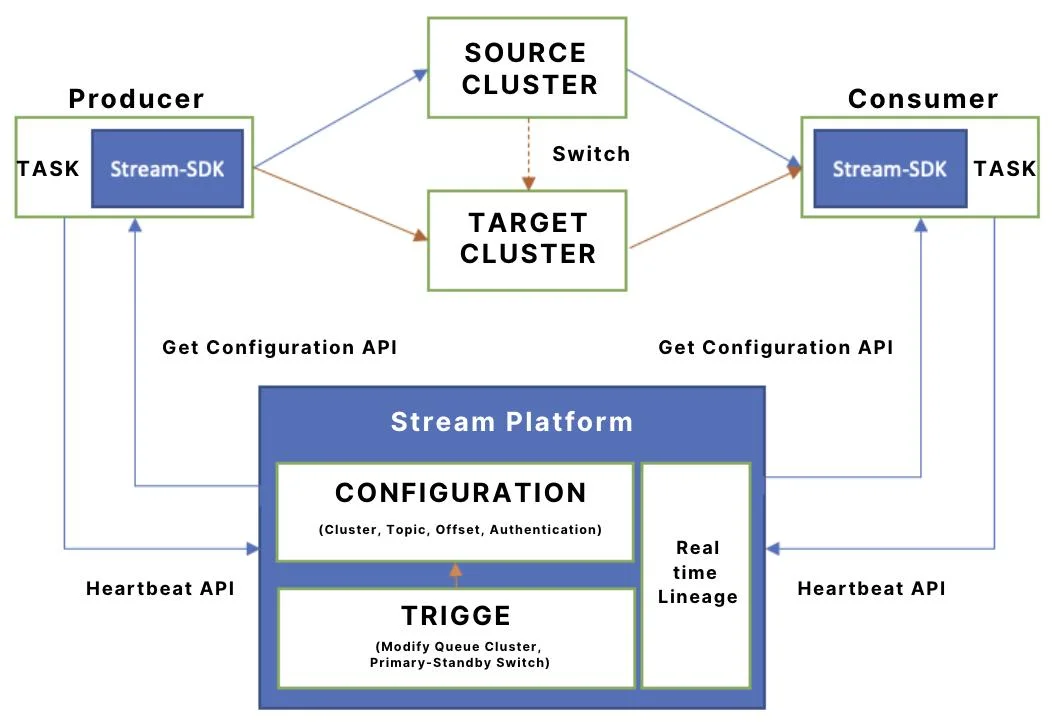
The data read/write workflow of the Stream-SDK consists of two primary stages:
-
Configuration Acquisition and Metadata Reporting: Using the Project, Queue, and Token (for authentication) provided by the application, the SDK calls the Stream Platform's configuration API to retrieve cluster details, topic names, and authentication parameters. It then initializes the native client to execute I/O operations. Simultaneously, the SDK reports metadata—such as client IP, consumer groups, and application names—via this API, which the platform uses to construct real-time read/write lineage.
-
Dynamic Cluster Perception and Automated Failover: During runtime, the SDK maintains a one-minute heartbeat interval with the Stream Platform to monitor for changes in queue-to-cluster mappings. If a change is detected, the SDK automatically reroutes traffic to the new cluster, achieving a seamless migration without manual intervention or service restarts.
By leveraging the Stream-SDK, the cost of cluster migration is drastically reduced. This architecture also paves the way for future infrastructure evolution, such as migrating from private to public clouds or transitioning from Kafka to AutoMQ.
Building a Hybrid Multi-Cloud Kafka Infrastructure
In the early stages, iQIYI's Kafka clusters were deployed in private cloud IDCs. Constrained by IDC resource provisioning models and the inherent architectural characteristics of Kafka, it was challenging to maintain resource utilization within an optimal range. Since 2023, the platform has gradually integrated several public cloud Kafka providers to form a hybrid cloud architecture, achieving significant results in resource elasticity, O&M (Operations and Maintenance) efficiency, and cost optimization. The following sections detail our cloud migration journey.
Private Cloud Kafka
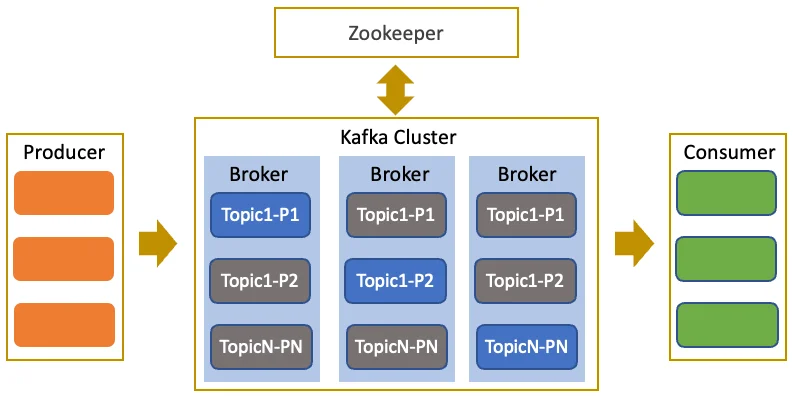
The Kafka architecture, as illustrated above, is a classic multi-replica, fault-tolerant distributed system comprising two primary roles: Brokers and ZooKeeper. Brokers are responsible for data storage and handling client I/O, while ZooKeeper manages cluster metadata and coordination states. Within iQIYI's private cloud, Kafka is deployed across various IDCs; typically, ZooKeeper is hosted on virtual machines (VMs), while Brokers are deployed on either VMs or bare-metal servers depending on the specific workload.
While the private cloud model has supported the rapid growth of our streaming data, the continued scaling of business volume has highlighted the following limitations:
- Limited Cluster Elasticity: Although Kafka's Shared Nothing architecture is simple and reliable, each Broker persists a large volume of data. Consequently, any scaling (in or out) necessitates significant data migration between Brokers. This process is time-consuming and can degrade the I/O performance of active business tasks, preventing the cluster from achieving seamless, elastic scaling.
- Insufficient Resource Elasticity: In a private cloud environment, the lifecycle of physical resources—from procurement to decommissioning—is lengthy. This makes it difficult to adjust capacity rapidly in response to dynamic traffic fluctuations, leading to clusters being either over-provisioned or under-provisioned for long periods. Additionally, it is challenging to scale resources on-demand for short-term peaks, such as during holiday breaks or major live-streaming events, which negatively impacts overall resource efficiency and cost optimization.
From Private Cloud Kafka to Public Cloud Kafka
To achieve cost optimization and enhance the flexibility of our streaming data storage, we introduced and integrated public cloud Kafka services.
These public cloud Kafka products adhere strictly to the Kafka protocol. By implementing unified adaptation within the Stream Platform and Stream-SDK, we offer a consistent and transparent experience for business units. This enables unified access and seamless switching between private and public cloud infrastructures.
By leveraging the public cloud's vast resource pools and on-demand cluster provisioning, we have effectively addressed the elasticity constraints of our private cloud environment, resulting in a cost reduction of over 20%.
From Kafka to AutoMQ
While public cloud Kafka addressed the problem of insufficient resource elasticity, the challenge of poor cluster elasticity persisted. The emergence of AutoMQ, which boasts second-level elasticity, has significantly caught our attention.
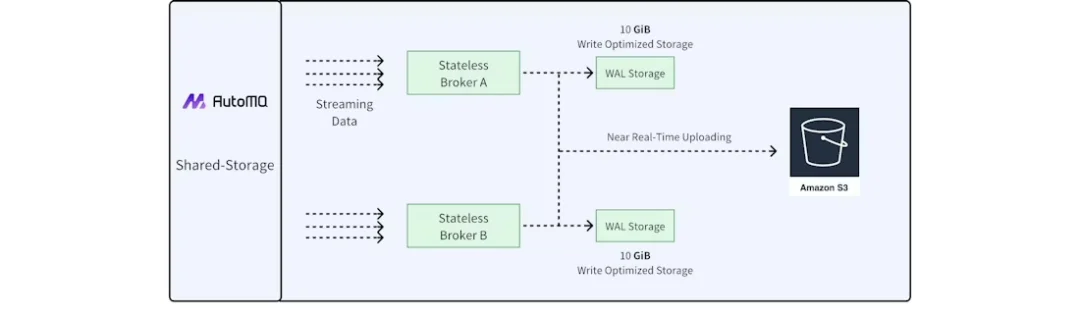
AutoMQ adopts a storage-compute separation architecture, as shown in the figure, and features the following characteristics:
- Shared Storage: Data is stored centrally in object storage, and Brokers no longer maintain local data. To mitigate the high latency and low IOPS typically associated with object storage, AutoMQ introduces cloud block storage as a Write-Ahead Log (WAL). Data is first written to the WAL and then asynchronously persisted to object storage in batches.
- Single-Replica Storage: Since cloud block storage and object storage are inherently multi-replica and provide high availability at the infrastructure layer, AutoMQ utilizes a single-replica strategy for all topics. This eliminates the replica synchronization overhead between Brokers found in traditional Kafka, significantly reducing costs and data replication pressure.
- Kafka Protocol Compatibility: Built upon open-source Kafka, AutoMQ retains the original compute layer logic while replacing the underlying storage implementation, ensuring 100% compatibility with the Kafka protocol and its ecosystem.
- Rapid Elasticity: Because Brokers are stateless and do not store data, nodes can be provisioned or decommissioned in minutes. Furthermore, the pay-as-you-go model of object storage allows the resource scale to match business traffic fluctuations precisely, eliminating resource waste.
After completing rigorous performance and stability validations, we deployed AutoMQ in our public cloud environment and integrated it into our streaming data service ecosystem. By systematically migrating our private and public cloud Kafka clusters to AutoMQ via the Stream platform, we have achieved a further cost reduction of over 70%.
Summary and Future Roadmap
Due to its low-latency characteristics, streaming data has become a mission-critical data highway for iQIYI. As the scale of operations expanded, traditional private cloud Kafka encountered significant bottlenecks in elasticity, cost, and governance. Consequently, our streaming data storage architecture shifted from "cluster-centric management" to "data-centric management," leveraging the Stream Platform and Stream-SDK to achieve decoupling and unified governance. The subsequent integration of public cloud Kafka and AutoMQ has led to substantial improvements in system elasticity, O&M efficiency, and cost-effectiveness.
Currently, approximately 40% of iQIYI's traffic has been migrated to public cloud Kafka or AutoMQ, with AutoMQ already carrying half of that volume. Our next steps involve further scaling the adoption of AutoMQ and exploring its adaptive auto-scaling mechanisms to drive continuous cost reduction and optimization.


