
If you run an Apache Kafka cluster on AWS or GCP, do one thing right now: open your cloud bill and find the "Data Transfer" line item.
You'll likely find a number that shouldn't be there. Not a few dozen dollars of rounding error—thousands, sometimes tens of thousands of dollars in monthly spend, sitting quietly, month after month.
According to Confluent's observational data, cross-Availability Zone (AZ) traffic costs can account for over 50% of a Kafka bill. A typical three-node production cluster (100 MiB/s write throughput, three consumer groups) generates $14,000 to $24,000 per month in cross-AZ traffic costs, depending on whether optimizations like Fetch from Follower are in place. This cost doesn't appear on your Kafka monitoring dashboard. It's buried under the "EC2-Other" category in your AWS bill, mixed in with traffic charges from RDS, ElastiCache, and ELB.
Where does this cost come from? Why have you never noticed it? And is there a way to eliminate it at the root?
Cross-AZ Traffic: A Tax Written into Kafka's DNA
Here's the baseline: major cloud providers charge for data transfer between AZs. AWS states on its EC2 pricing page that data transfer between AZs within the same region costs $0.01/GB, billed in both directions—meaning every 1 GB of cross-AZ transfer costs the sender $0.01 and the receiver $0.01, for an effective rate of $0.02/GB. GCP lists a cross-AZ egress rate of $0.01/GB on its VPC network pricing page. This isn't a hidden clause—it's in the official pricing documentation. Most teams never factor it in when estimating Kafka costs.
Kafka requires multi-AZ deployment for high availability, and production clusters are typically deployed across at least three AZs. Multi-AZ deployment itself is standard practice for production systems in the cloud. The problem arises when Kafka's data replication mechanism combines with this deployment model, generating massive cross-AZ data transfer at three points. One cent per GB sounds negligible, but when a cluster processes hundreds of megabytes per second, the number grows fast.
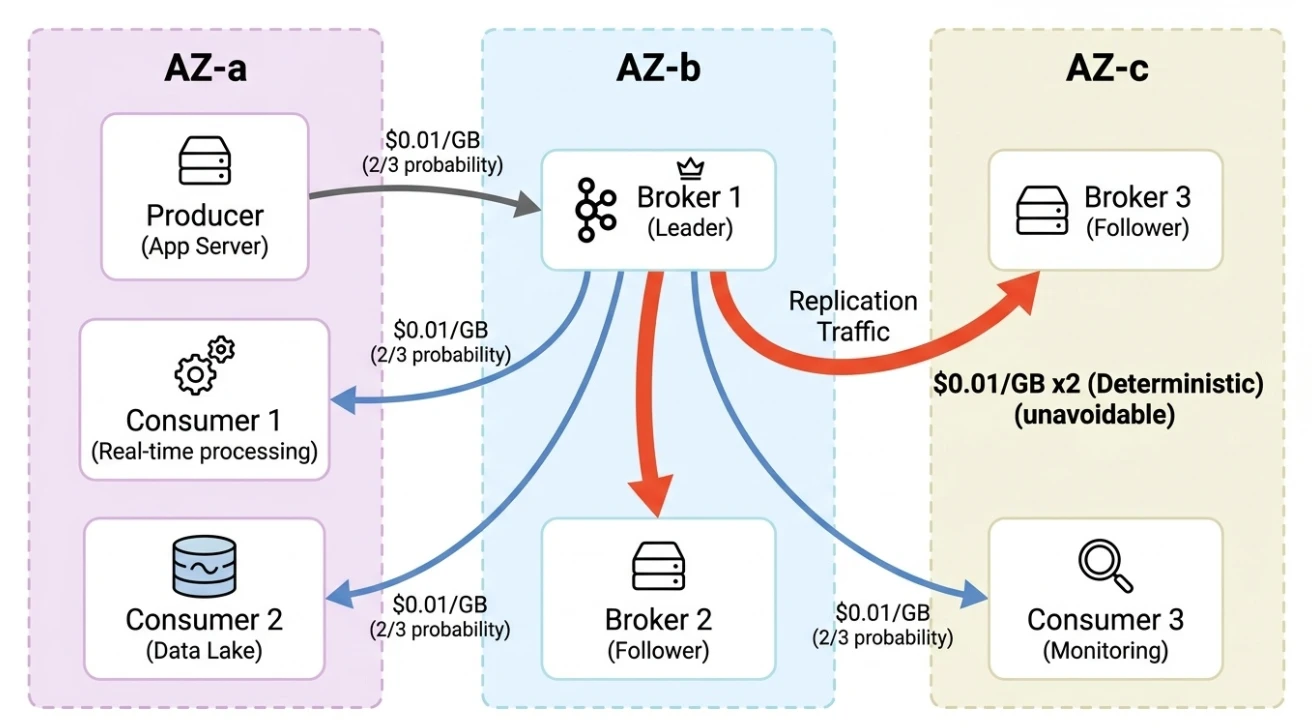
Cross-AZ traffic comes from three sources:
- Producer → Leader Broker: Each partition has a single leader, distributed across different AZs. In a three-AZ deployment, a producer has roughly a 2/3 probability of writing cross-AZ. Two out of every three messages incur a "toll."
- Leader → Follower replication: The largest traffic source. With Kafka's default replication factor of three, the leader must replicate data to followers in two other AZs. Every 1 GB written deterministically produces 2 GB of cross-AZ traffic. It can't be turned off or bypassed.
- Broker → Consumer reads: Consumers read from the leader by default, facing the same 2/3 cross-AZ probability. With three consumer groups (real-time processing, data lake, monitoring), the traffic multiplies by three.
These three hops compound, and the traffic costs snowball. Replication is deterministic and unavoidable. As long as Kafka uses the model where "each broker stores its own data replicas," this cost is locked in.
The Math
Numbers speak louder than words. Consider a mid-scale production scenario—common across core business clusters:
| Parameter | Value |
|---|---|
| Write throughput | 100 MiB/s (sustained) |
| Replication factor | 3 (Kafka default) |
| Consumer groups | 3 (real-time processing + data lake + monitoring) |
| Data retention | 72 hours |
| Deployment model | 3 AZs (standard production configuration) |
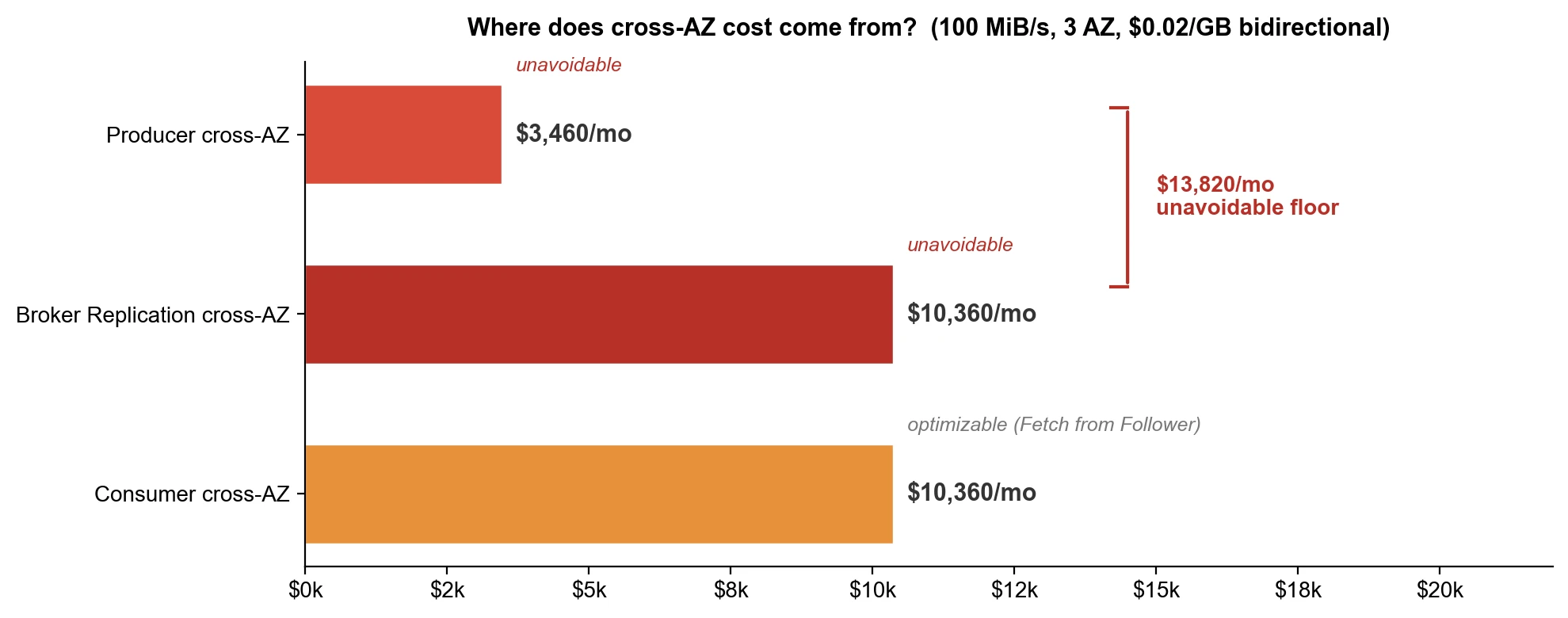
Producer side: 100 MiB/s sustained write throughput produces roughly 259 TB of total traffic per month (100 × 86,400 × 30 ÷ 1,000,000). Two-thirds crosses AZ boundaries—approximately 173 TB. With AWS's bidirectional billing at an effective rate of $0.02/GB, that's about $3,460/month. Sounds manageable? Keep reading.
Replication is the big one. Every 1 GB written triggers the leader to replicate to two followers, producing 2 GB of cross-AZ traffic. That's approximately 518 TB per month, at the bidirectional rate of $0.02/GB, roughly $10,360/month. This cost is deterministic—unless you are willing to drop the replication factor to one, which no one does in production.
That's the write side alone. On the consumer side, three consumer groups each read the full data volume, with two-thirds crossing AZ boundaries—another roughly 518 TB, another $10,360/month.
All three combined, the theoretical ceiling is approximately $24,000/month. Fetch from Follower (KIP-392) lets consumers read from a same-AZ follower, significantly reducing the third component. Rack-aware configuration helps as well. But producer writes and replication remain unavoidable—those two alone total approximately $13,800/month. Even with consumer-side optimizations pushed to the limit, the floor for cross-AZ traffic costs stays around $14,000:
| Cost Component | Monthly Cost | Optimizable? |
|---|---|---|
| Producer cross-AZ | ~$3,460 | Limited (rack-aware partially mitigates) |
| Replication cross-AZ | ~$10,360 | Unavoidable (architecture-determined) |
| Consumer cross-AZ (3 groups) | ~$10,360 | Significantly reducible (Fetch from Follower) |
| Unoptimized total | ~$24,000 | — |
| Optimized floor | ~$14,000 | Producer + replication unavoidable |
| EC2 instance cost (comparison) | ~$3,000 | — |
| EBS (Elastic Block Store) storage cost (comparison) | ~$2,000 | — |
You spend more on invisible traffic than on visible servers. So why do most teams never notice?
A Cost That's Structurally Hidden
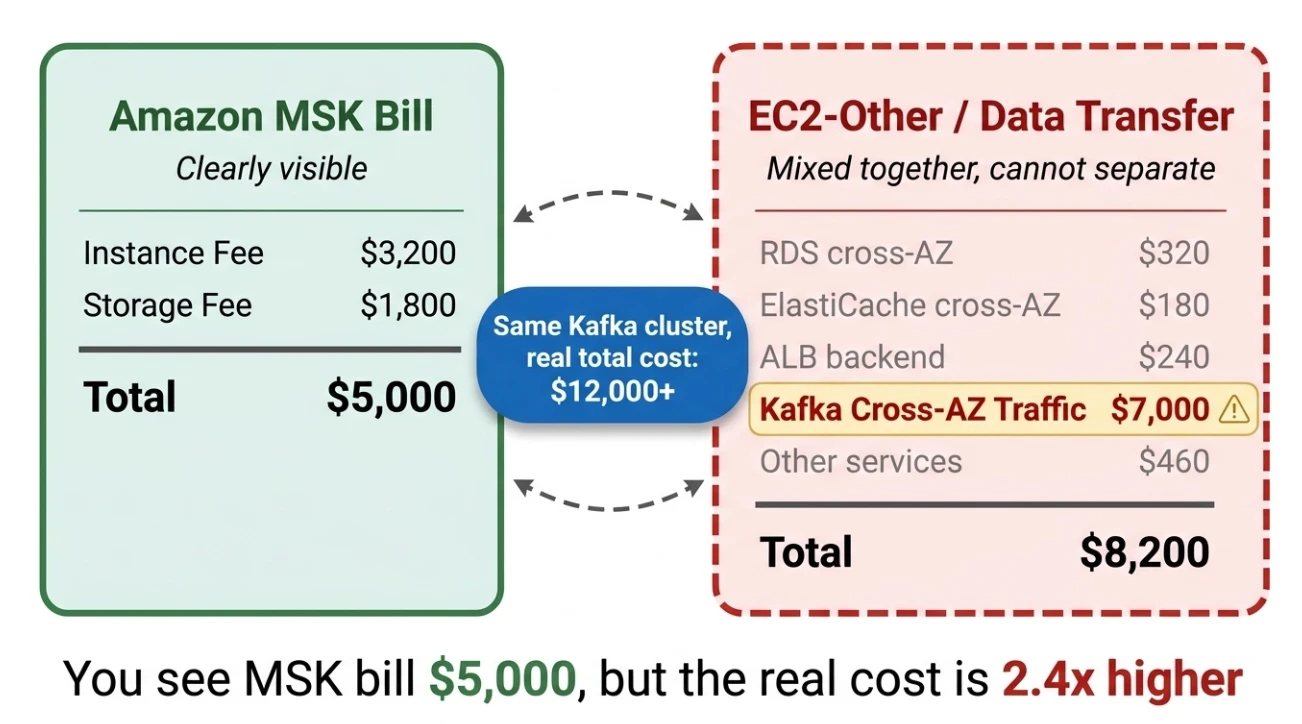
Because the billing structure buries it.
AWS classifies cross-AZ traffic costs under "EC2-Other" or "Data Transfer," lumped together with network traffic from every service in the account. Cross-AZ reads from RDS, cluster sync from ElastiCache, backend communication from ALB—all aggregated on the same line. Isolating Kafka's contribution? Nearly impossible.
Self-managed Kafka clusters face an especially opaque situation. Your EC2 instance costs and EBS storage costs might add up to $5,000, and you think "that's reasonable." Meanwhile, another $14,000 to $24,000 in cross-AZ traffic costs sits quietly in a corner of the EC2 bill, mixed with network charges from dozens of other services, with no way to attribute it.
Three factors make this cost invisible:
- Ambiguous billing classification: Cross-AZ traffic costs are filed under "EC2-Other," mixed with network charges from dozens of services
- Separated from Kafka costs: EC2 instance costs and EBS storage costs look clean and clear, but cross-AZ traffic costs are filed under generic EC2 network charges with no association to your Kafka cluster
- Account-level aggregation: No per-service or per-cluster breakdown; cost allocation across teams sharing an account is nearly impossible
AWS isn't deliberately hiding it—the billing structure inherently makes this cost invisible.
Configuration Tuning Can't Save You
Can configuration tuning solve this? Only to a limited extent.
Fetch from Follower reduces consumer-side cross-AZ traffic and genuinely helps. But producer writes and replication together account for the bulk of cross-AZ traffic costs, and they're determined by Kafka's architecture—no configuration can address them. You can set replica.selector.class to enable consumers to read from a nearby replica, but you can't stop the leader from replicating to followers, and you can't force producers to write only to same-AZ partitions. This isn't a configuration problem. It's an architecture problem.
The root cause lies in Kafka's storage model: each broker maintains its own data replicas on local disk, synchronizing across brokers over the network. This model made sense in the data center era, when inter-machine network traffic was free. In the cloud, cross-AZ traffic costs real money. Kafka's architecture assumes a world where network traffic is free. It now runs in a world where network traffic is metered.
To eliminate this cost at the root, one question needs an answer: in the cloud, does Kafka still need app-level multi-replica replication?
Rethinking Storage: Why We Redesigned Kafka
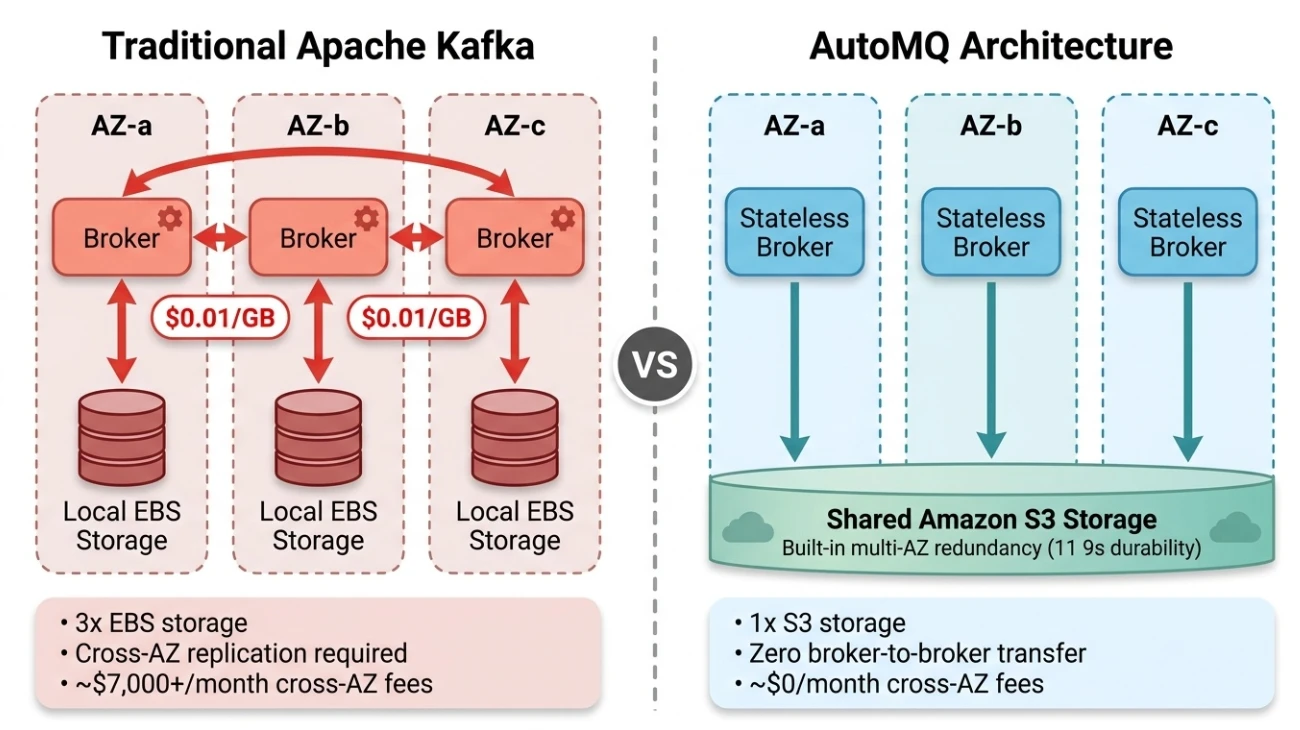
AWS S3 provides 99.999999999% (eleven 9s) data durability with built-in multi-AZ redundancy. Once data is written to S3, AWS handles redundant storage across multiple AZs—fully transparent to the user, with no cross-AZ traffic charges. S3 already does what Kafka's replication is trying to do—guarantee data durability across AZs—and it does it better and at lower cost. Since the cloud provider has already solved data durability at the infrastructure layer, repeating multi-replica replication at the app layer isn't only redundant work but also incurs steep cross-AZ traffic charges.
We built AutoMQ because of these problems. Kafka originated in LinkedIn's data centers. Its architecture assumptions—local disk is inexpensive, network traffic is free, machines are long-lived pets—all break down in the cloud. Cross-AZ traffic costs are one symptom; the underlying issue is a mismatch between the storage architecture and the cloud environment. Instead of continuously patching a data-center-era architecture, we chose to redesign from the storage layer up. Reducing the cost of running Kafka in the cloud through technical innovation is one of our core priorities.
AutoMQ maintains 100% Apache Kafka protocol compatibility—all your existing Kafka clients, Connect, and Streams work without modification—but redesigns the storage architecture from the ground up. There's one core change: move data persistence from broker-local disk (EBS) to object storage (S3), letting S3 handle data durability and multi-AZ redundancy.
This is easy to confuse with Kafka's Tiered Storage (KIP-405), but the difference is fundamental:
| Tiered Storage (KIP-405) | Diskless Architecture | |
|---|---|---|
| Approach | "Less disk" | "Zero disk" |
| Hot data | Still on local EBS | No local persistent data |
| S3 role | Cold data only | Sole persistence layer |
| Inter-broker replication | Still required | Completely eliminated |
| Cross-AZ traffic cost | No reduction | Near $0 |
| Scaling | Still requires hot data reassignment | Seconds-level—metadata only |
Tiered Storage moves cold data to S3 while hot data remains on local disk. Inter-broker replication persists, and cross-AZ traffic costs remain unchanged. AutoMQ takes a more thorough approach: S3 is the sole persistence layer, and brokers retain no local persistent data. With no local data, there is nothing to "sync" between brokers—the architecture eliminates replication entirely.
Does writing directly to S3 introduce high latency? Yes. S3 write latency is in the hundreds of milliseconds—unacceptable for Kafka. AutoMQ's solution uses a small cloud storage volume (such as EBS, 20 GB by default) on each broker as a WAL (Write-Ahead Log). Data writes to the WAL first, and the broker returns an acknowledgment immediately—keeping write latency under 10ms. Data then asynchronously flushes to S3 in batches. The WAL itself is durable (EBS provides built-in durability), but its role is a write buffer, not long-term storage. The final destination for all data is S3.
The key point: the WAL exists only on a single broker's local storage and does not need to sync with other brokers, so it introduces no cross-AZ replication. An additional benefit: it aggregates small writes into large batches before flushing to S3, reducing S3 API call volume and cost. This low-latency EBS WAL is a capability of AutoMQ commercial editions; AutoMQ Open Source uses S3 WAL, which has higher latency but equally eliminates cross-AZ replication.
With storage delegated to S3, brokers become truly stateless compute nodes. If a broker fails, a new broker reads data from S3 and recovers in seconds—no need to "catch up" from other brokers for hours. Scaling out means adding a broker that can immediately serve any partition, because the data in S3 is accessible to all brokers. Scaling in means decommissioning a broker with no data to migrate first. AutoMQ can even run on Spot Instances—something traditional Kafka can't do.
Under this architecture, the three traffic sources are eliminated one by one:
- Producer → Broker: AZ-aware scheduling routes producers to write to a same-AZ broker
- Replication: No longer exists—S3 provides built-in multi-AZ redundancy
- Consumer ← Broker: AZ-aware scheduling routes consumers to read from a same-AZ broker
Cross-AZ traffic costs drop from $14,000–$24,000 per month to near zero. Your existing producers, consumers, Kafka Connect, Kafka Streams, and Flink jobs can all switch seamlessly—no code changes required.
With the architecture analysis complete, the remaining question is: how does this perform in real production environments?
From MSK to AutoMQ: How FunPlus Cut Kafka Costs by Over 60%
FunPlus is a global gaming company headquartered in Switzerland with over 2,000 employees. Their title State of Survival has topped 150 million downloads. Their data infrastructure runs on AWS, with Kafka clusters powering a real-time data pipeline processing billions of messages daily: player behavior analytics, real-time anti-cheat, in-game recommendations, and operational dashboards all depend on this pipeline.

The gaming industry hits every amplifying factor for cross-AZ traffic costs: high throughput, multi-AZ high-availability deployment, and global multi-region presence. A popular game's backend requires Kafka clusters deployed across three AZs for high availability, and traditional Kafka's multi-replica replication means every message is replicated across AZs twice. Add producer and consumer cross-AZ communication, and traffic costs accumulate rapidly.
When FunPlus's infrastructure team conducted a cost audit, they discovered that cross-AZ traffic had become the single largest line item in their Kafka infrastructure costs. Not instance costs. Not storage costs. The network traffic charges buried in the EC2 bill that no one could attribute. Multi-AZ deployment is non-negotiable for high availability. Multi-replica replication is Kafka's core mechanism for data durability and cannot be turned off. The problem was clear: high availability and low cost are contradictory under traditional Kafka's architecture.
They evaluated a few options. Fetch from Follower enables consumers to read locally, reducing traffic from consumer reads, but inter-broker replication is the dominant cost—architecture-determined and beyond configuration. Reducing the replication factor? In a production environment processing billions of messages daily, no one takes that risk. Ultimately, they chose to solve it at the architecture level by switching to AutoMQ.
After migration, overall Kafka infrastructure costs dropped by over 60%, with the dramatic reduction in cross-AZ traffic costs—from the largest expense to a negligible one—as the key contributing factor. Storage costs also fell significantly, moving from three EBS replicas to a single copy in S3. FunPlus's AutoMQ cluster runs in AWS us-west-2, processing approximately seven billion messages daily with peak queries per second (QPS) exceeding 15,000. The pipeline runs smoothly end to end—downstream Flink jobs, data lake writes, and real-time analytics services required zero modifications.
"After switching to AutoMQ, overall costs dropped by over 60%, and cross-AZ traffic is no longer the most painful item on our bill." — FunPlus Infrastructure Team
This case is worth highlighting not just for the 60%+ cost reduction, but because gaming hits every amplifying factor for cross-AZ traffic: high throughput, multiple consumers, and global deployment. The problem isn't limited to gaming, though. Any team running a mid-to-large-scale Kafka cluster in the cloud—e-commerce order streams, financial transaction pipelines, IoT device data, SaaS event buses—faces the same billing structure. The difference is only in degree.
What You Should Do
If you suspect your Kafka bill hides a similar surprise, here are three steps you can take right now:
1. Check your bill. Log into AWS Cost Explorer, filter for "Data Transfer" costs under the "EC2-Other" category, and see if that number is larger than expected. GCP users can find similar information under the Network category in Billing. If the number is unexpectedly large, Kafka is a common major contributor.
2. Estimate your cross-AZ traffic costs. Use this simplified formula:
Monthly cross-AZ traffic cost ≈ write throughput (MiB/s) × 2,628,000 × (2/3 + 2 + fanout × 2/3) × $0.02/GB ÷ 1,024
At 50 MiB/s write throughput with two consumer groups, the unoptimized monthly cross-AZ traffic cost is approximately $10,000. Even with Fetch from Follower optimization on the consumer side, producer writes plus replication still cost approximately $6,700.
3. Evaluate architecture-level solutions. When cross-AZ traffic costs exceed 30% of total Kafka costs, configuration-level optimizations are no longer sufficient. It's time to address this at the storage architecture level—delegate data durability to S3 and let brokers return to the role they should play: efficient message routing nodes, not expensive data storage nodes.
AutoMQ offers a free managed trial environment with no credit card required. Spin up a real Kafka cluster in minutes and verify zero cross-AZ traffic costs firsthand. Sign up for a free trial.
Go back to your AWS bill, the Data Transfer line. Now you know where that number comes from.
Cost data in this article is based on AWS public pricing (us-east-1 region, April 2026). Actual costs vary by region, traffic patterns, and configuration.


