On March 18, 2025, Apache Kafka 4.0 was officially released. In this version update, compared to upgrades at the architectural level, developers should also pay attention to a key detail change: the official default value of the producer parameter linger.ms has been formally modified from the long-standing 0ms to 5ms.
This adjustment directly addresses a cognitive blind spot in traditional performance tuning; in conventional concepts, linger.ms=0 implies "zero wait" and real-time sending, typically viewed as the primary strategy for reducing latency. However, the default value change in Kafka 4.0 reveals a deeper performance logic: in complex network I/O models, purely pursuing immediacy at the sender end does not equate to global low latency. Introducing a minute "artificial delay" in exchange for higher batching efficiency can often significantly reduce system latency.
Taking the default value change of Kafka 4.0 as an opportunity, this article will provide an in-depth analysis of the synergistic mechanism behind the two core parameters, linger.ms and batch.size . This aims to help you master the principle-based best practices for linger.ms and batch.size when facing complex production environments.
Concept Breakdown: linger.ms and batch.size
To thoroughly comprehend the underlying logic behind this change, we must first return to fundamentals and accurately understand the concepts of these two core parameters.
linger.ms:
The producer groups together any records that arrive in between request transmissions into a single batched request. This batching behavior typically occurs naturally under high-load scenarios where the record arrival rate exceeds the send rate; however, under moderate load, the client can also actively reduce the number of requests by introducing a small amount of "artificial delay" via the linger.ms configuration. Its behavioral logic is analogous to the Nagle algorithm in the TCP protocol: the producer does not immediately send every arriving record but waits for a specified duration to aggregate more subsequent records. This setting defines the upper time limit for batching. Sending behavior follows the "whichever happens first" principle—once the accumulated data volume for a partition reaches batch.size , the batch is sent immediately, regardless of whether linger.ms has expired; conversely, if the data volume is insufficient, the producer will "linger" for the specified duration to await more records. In Apache Kafka 4.0, the default value of this parameter has been adjusted from 0ms to 5ms. The rationale is that the efficiency gains from larger batches are usually sufficient to offset the introduced wait time, thereby achieving comparable or even lower overall producer latency.
batch.size:
When multiple records need to be sent to the same partition, the producer aggregates these records into batches to reduce the frequency of network requests, thereby optimizing I/O performance between the client and the server. The batch.size parameter defines the default capacity limit (in bytes) for such batches; individual records exceeding this threshold will not be included in the batching logic. A single request sent to a Broker typically contains multiple batches, corresponding to different partitions. Configuring a batch.size that is too small will limit the frequency of batching and may reduce throughput (setting it to 0 will completely disable batching); whereas an excessively large configuration may lead to minor waste of memory resources because the producer always pre-allocates buffers based on this threshold. This setting establishes the spatial upper limit for sending behavior: if the accumulated data volume in the current partition has not reached this threshold, the producer will wait according to the linger.ms setting (default is 5ms); the send trigger logic follows the "Whichever happens first" principle, meaning the batch is sent as soon as the data fills the buffer or the wait time expires. It is important to note that backpressure on the Broker side may cause the actual effective wait time to exceed the configured value.
Through the decomposition of these two dimensions, we can clearly observe the synergistic working mode of linger.ms and batch.size :
-
They jointly determine the size of the
RecordBatch(batch) and the timing of theProduceRequest(request) transmission. -
Larger
linger.msandbatch.sizeparameter values -> Better batching effect forRecordBatchandProduceRequest-> Fewer RPCs for the Kafka server to process -> Lower CPU consumption on the Kafka server. -
Side effect: The time spent by the client on batching increases, leading to higher client-side sending latency.
This introduces a critical performance trade-off question:
"Given sufficient server-side CPU resources, should one minimize
linger.msandbatch.sizeas much as possible to pursue ultra-low latency?"
Based on intuitive inference, the answer seems to be affirmative. However, the official Apache Kafka 4.0 documentation points to the contrary conclusion:
"Apache Kafka 4.0 adjusts the default value from 0 to 5. Although this adds artificial wait time, the efficiency gains from larger batches usually result in similar or even lower producer latency."
linger.ms=0 represents immediate sending; why does it perform worse in terms of latency compared to "waiting for 5ms first"?
Core Principle: The Underlying Rules of Interaction Between Kafka Server and Client
To thoroughly understand this counter-intuitive performance behavior, we must not merely remain at the surface of client-side configuration but must delve into the underlying layers of the Apache Kafka network protocol. The generation of latency fundamentally stems from the interaction mechanism between the client-side sending strategy and the server-side processing model. To investigate the root cause, we need to dissect the operational logic of these underlying rules from two dimensions: the server side and the client side.
1. Server-Side Perspective: Strictly Ordered & Serial
By design, Kafka's network protocol bears a strong resemblance to HTTP 1.x; it adopts a strictly sequential and serial operational mode. This is the cornerstone for understanding all latency issues:
-
Sequential: For requests originating from the same TCP connection, the server must process them strictly in the order of receipt and return responses in the same order.
-
Serial: The server will only begin processing the next request after it has completely finished processing the current request and sent the response. This implies that even if the client concurrently dispatches multiple
ProduceRequests, the server will strictly execute a 'One-by-One' strategy: it must wait until the data of the preceding request completes all ISR replica synchronization and returns a response before initiating processing for the next request.
This implies: Even if the client concurrently sends multiple ProduceRequests in a burst, the server will not process them in parallel. If the preceding request stalls due to ISR synchronization, all subsequent requests are forced to queue and wait on the server side.
2. Client-Side Perspective: The "Batch" Mechanism
On the client side, the Producer's batching mechanism primarily consists of two core modules: RecordAccumulator and Sender , corresponding to RecordBatch and ProduceRequest , respectively.
-
RecordAccumulator: Responsible for batching
RecordBatch.KafkaProducer#senddeposits records into theRecordAccumulatorfor batch processing. When theProduceBatchdata within a partition exceedsbatch.size, it switches to the next partition and creates a newProduceBatchfor batching. -
Sender: Responsible for maintaining connections with server nodes and sending data in batches. It drains data from ready partitions in the
RecordAccumulatorbased on the node, packages them into aProduceRequest, and sends them. Draining requires the simultaneous satisfaction of the following conditions:-
The number of in-flight requests on the connection is less than
max.in.flight.requests.per.connection=5. -
Any
ProduceBatchfor the corresponding node exceedslinger.msor exceedsbatch.size.
-
Scenario Deduction: Performance Comparison of 0ms vs 5ms
Based on the aforementioned principles, we need to further evaluate the performance of this mechanism in actual scenarios. When the client configures linger.ms=0 to execute an immediate send strategy, while the server is constrained by a serial processing model, the processing rhythms of the supply and demand sides will become mismatched. To accurately determine whether this mismatch reduces latency or triggers queue backlogs, qualitative analysis alone is insufficient. Next, we will construct a model to calculate specific latency data under different configurations through scenario-based quantitative deduction.
Scenario Assumptions:
-
Deploy a single-node cluster, create a Topic containing 10 partitions.
-
Client: Single client, send rate 1000 records/s, record size 1KB.
-
Server: Processing one
ProduceRequesttakes 5ms . -
Comparison:
-
Configuration A:
linger.ms=0,batch.size=16KB(Default configuration prior to Apache Kafka 4.0) -
Configuration B:
linger.ms=5, others unchanged (New default in 4.0)
-
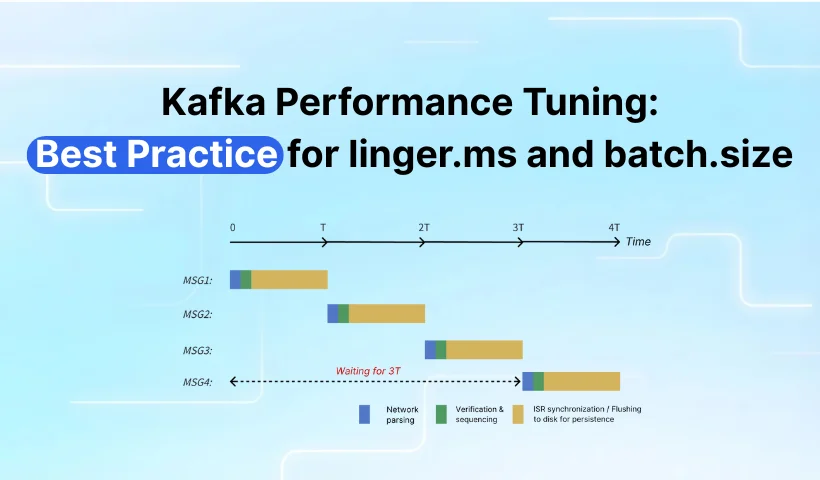
Scenario A: linger.ms = 0
-
1,000 records/s implies invoking
KafkaProducer#sendonce every 1ms; -
Since
linger.ms=0, the first 5 records are immediately converted into 5ProduceRequests, sent at timestamps T=0ms, T=0.1ms, ..., T=0.4ms respectively. -
Apache Kafka processes these 5
ProduceRequestssequentially and serially:
a. T=5ms: Apache Kafka completes the 1st ProduceRequest , returns a response, and begins processing the next ProduceRequest ;
b. T=10ms: The 2nd ProduceRequest is completed, and processing of the next one begins;
c. By analogy, the 5th ProduceRequest is completed at T=25ms .
- T=5ms: The client receives the response for the 1st
ProduceRequest, satisfying the conditioninflight.request < 5, and drains data from theRecordAccumulator. At this point, (5 - 0.4) / 1 ~= 4K of data has accumulated in memory. This data is placed into aProduceRequest, and the Sender packages it as the 6th request to be sent.
a. T=30ms: After Apache Kafka finishes processing the 5th request at T=25ms, it proceeds to process the 6th request and returns the response at T=30ms.
-
T=10ms: Similarly, after receiving the response for the 2nd
ProduceRequest, the client accumulates (10 - 5) / 1 = 5K of data and sends it to the Broker. Apache Kafka returns the response at T=35ms. -
By analogy, subsequent
ProduceRequestswill all accumulate 5K of data at time T1 and be sent to the Broker. The Broker will respond to the request at T1 + 25ms. The average production latency is 5ms / 2 + 25ms = 27.5ms. (5ms / 2 represents the average batching time)
Scenario B: linger.ms = 5
-
T=5ms: Since
linger.ms=5, the client first accumulates data until 5ms, then sends the firstProduceRequest. The server responds to this request at T=10ms. -
T=10ms: Since
linger.ms=5, the client continues to accumulate new data for 5ms, then sends the secondProduceRequest. The server responds at T=15ms. -
By analogy: Subsequent requests will all be sent to the Broker after accumulating 5K of data at time T1, and the Broker will respond at T1 + 5ms. The average production latency is calculated as follows: 5ms / 2 + 5ms = 7.5ms (Note: 5ms / 2 represents the average batching time)
In this hypothetical scenario, although we increased linger.ms from 0ms to 5ms, the average production latency actually dropped from 27.5ms to 7.5ms. Thus, it is evident that the statement "the smaller the linger.ms , the lower the latency" does not hold absolute truth.
Best Practice for linger.ms and batch.size Configuration
By comparing the scenarios where linger.ms is 0ms and 5ms, we can conclude that client-side proactive batching, which limits in-flight requests to 1 or fewer, is more effective in reducing production latency than rapidly dispatching requests only for them to queue at the network layer.
So, how can we precisely define the thresholds for these two parameters within diverse production environments?
We require a scientific calculation formula to derive the optimal client-side configuration based on the server's actual processing capacity. Below are targeted configuration recommendations aimed at minimizing production latency:
- linger.ms >= Server Processing Time.
If linger.ms is less than the network latency plus server processing time, given the serial processing model of the Kafka network protocol, the dispatched ProduceRequests will create a backlog at the network layer. This violates the aforementioned principle of "keeping the number of network in-flight requests to 1 or fewer."
- batch.size >= (Max Write Throughput per Client) * (linger.ms / 1000) / (Number of Brokers).
If batch.size is not set greater than or equal to this value, it implies that the request will be forced to send prematurely because the ProduceBatch exceeds the batch.size before linger.ms is reached. Similarly, these ProduceRequests cannot be processed in a timely manner and will queue in the network, violating the principle of "keeping the number of network in-flight requests to 1 or fewer."
- It is recommended to set batch.size as large as possible (e.g., 256K):
linger.ms is configured based on the server's average production latency. Once server-side performance jitter occurs, a larger batch.size allows us to accumulate more data within a single RecordBatch , thereby avoiding increased overall latency caused by splitting data into multiple small requests. Taking a single-node cluster as an example, assume the server requires 5ms to process a ProduceRequest . Then, we need to set linger.ms to at least 5ms. If we anticipate that a single producer's send rate can reach 10MBps, then batch.size should be set to at least 10 * 1024 * (5 / 1000) = 51.2K.
Innovative Practice: Moving from "Client-side Batching" to "Server-side Pipelining"
The adjustment of default values in Apache Kafka 4.0 validates a core technical consensus: when processing large-scale data streams, moderate batching is an effective means to balance throughput and latency. This is a mature optimization strategy based on a client-side perspective.
However, there is more than one path to performance optimization. Since the bottleneck lies in the server-side "serial processing," can we seek a breakthrough from the server side itself, rather than solely relying on adjusting client parameters? Driven by this insight, as an explorer of cloud-native Kafka, AutoMQ attempts to identify new breakthroughs from a server-side perspective: while maintaining full compatibility with Kafka protocol semantics, AutoMQ has introduced the "Pipeline mechanism." This mechanism does not alter the protocol itself; rather, it optimizes the server-side model. This allows for the full utilization of cloud-native storage concurrency while guaranteeing strict ordering, ultimately boosting the processing efficiency of ProduceRequests by 5 times.
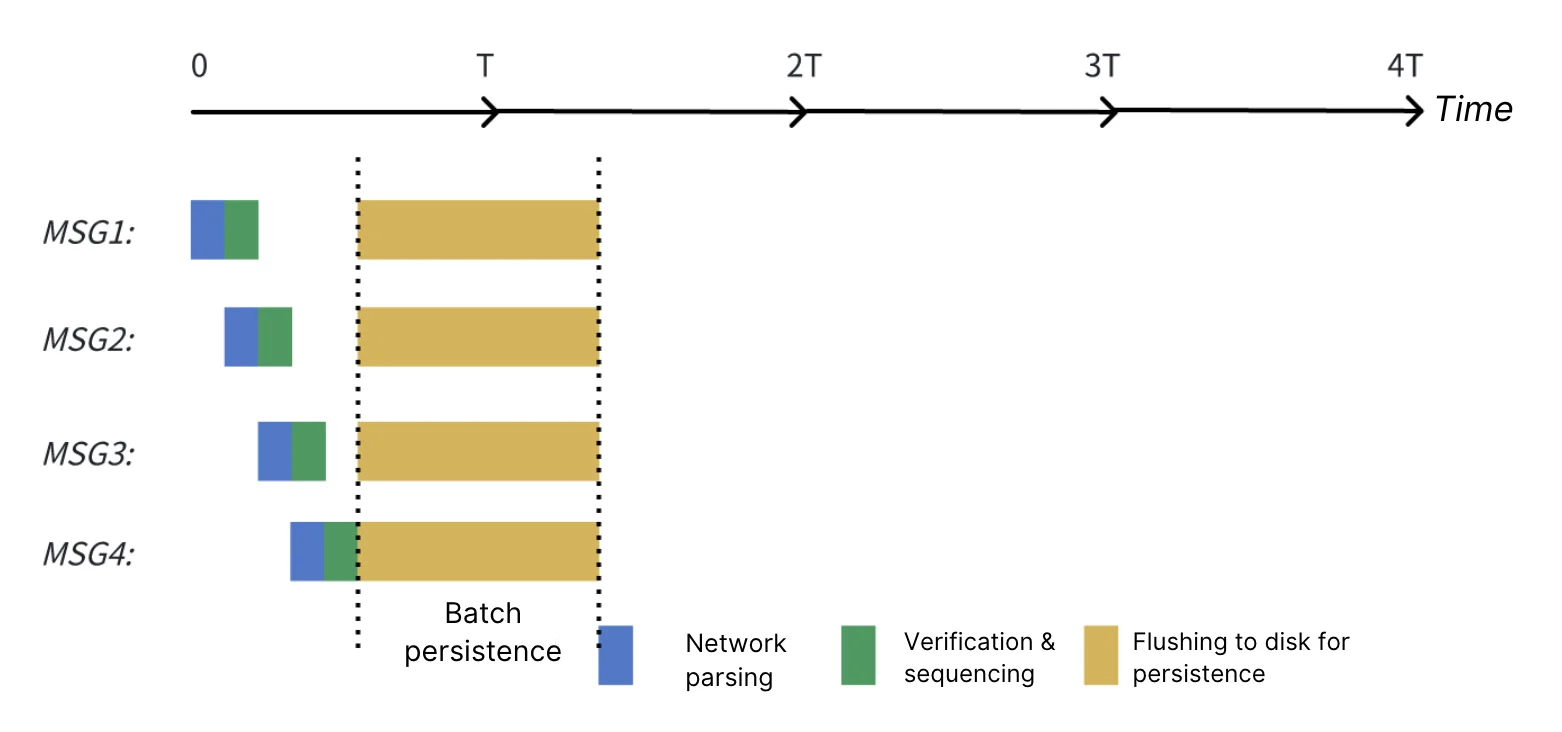
What does this imply? Let us revisit the previous deduction scenario:
Even under conditions where linger.ms=0 causes a backlog of multiple in-flight requests, AutoMQ's pipeline mechanism enables the server to process these requests concurrently, significantly reducing queuing latency:
-
Apache Kafka: Due to serial queuing, the average latency reaches 27.5ms.
-
AutoMQ: By leveraging the pipeline mechanism, the average latency decreases to 7.5ms.
Therefore, when utilizing AutoMQ as the server side, one can benefit from a 5-fold increase in server processing efficiency. The client no longer needs to accommodate the server through prolonged "lingering," thereby achieving a lower latency experience. You may configure parameters to 1/5 of the originally recommended values; the configuration strategy for linger.ms will differ slightly from that of Apache Kafka:
-
linger.ms >= (Server Processing Time / 5)
-
batch.size >= (Max Write Throughput per Client) * (linger.ms / 1000) / (Number of Brokers)
(Note: It is similarly recommended to maximize batch.size within memory limits, e.g., 256K)
This disparity in configuration reveals a shift in the perspective of performance optimization: achieving performance tuning cannot rely solely on client-side adaptation. Through innovative practices at the architectural level, AutoMQ eliminates the need for users to make difficult trade-offs between "low latency" and "high throughput," achieving both with a lower barrier to entry. Technology is in a state of constant evolution. Moving from parameter tuning to architectural evolution is not only the choice of AutoMQ but also the developmental direction of message middleware in the cloud-native era.
Conclusion
Thank you for reading.
This article reviewed the configuration of linger.ms and batch.size parameters in Apache Kafka 4.0, pointing out the "latency versus throughput" trade-off challenge faced during client-side performance tuning under the traditional serial network model. Subsequently, we provided an in-depth analysis of AutoMQ's Pipeline mechanism, which decouples the strong binding between sequential processing and serial execution through the refactoring of the server-side I/O model.
The Pipeline mechanism is one of the core features of AutoMQ's cloud-native architecture. It achieves processing efficiency 5 times that of traditional architectures without relying on tedious client-side parameter tuning, while guaranteeing strict data ordering. Combined with deep adaptation to cloud-native storage, AutoMQ is committed to empowering enterprises to build streaming data platforms with ultimate performance and simplified operations through the evolution of the underlying architecture.


