Blockchains generate massive, real-time data streams. Every transaction, block, mempool update, and smart-contract event creates a continuous flow that must be captured, processed, and distributed without delay. As blockchain networks scale, this data quickly reaches high throughput and always-on streaming levels.
To handle this, many engineering teams rely on Kafka. Kafka has become a common backbone for managing continuous data pipelines because it is designed for high-volume, real-time event streaming. In blockchain environments, Kafka is often used to ingest raw node data, power real-time analytics, and distribute events to multiple downstream systems.
This article explores the most practical Kafka blockchain use cases, focusing on how Kafka is applied across real blockchain data pipelines today. It also examines how AutoMQ, using its cloud-native Kafka architecture, can help address those challenges while remaining fully compatible with the Kafka ecosystem.
Kafka Use Cases in Blockchain Data
Blockchain systems don't generate data in batches. They produce continuous, append-only event streams that must be ingested, processed, and distributed in near real time. This is where Kafka fits naturally. Below are the most common and well-documented ways Kafka is used in blockchain data pipelines today.
Real-Time Blockchain Data Ingestion
Blockchain nodes continuously emit raw data: transactions, blocks, logs, and state changes. Kafka is commonly used as the first ingestion layer for this data.
In practice, node outputs are captured, normalized, and written into Kafka topics, creating a durable and ordered event stream that downstream systems can reliably consume. This buffering layer decouples blockchain nodes from analytics systems, reducing backpressure and improving overall pipeline stability.
Kafka is also widely used in real-time transaction streaming pipelines, where blockchain data is processed as it arrives rather than being stored first and analyzed later. This streaming-first approach is essential for applications that require low latency and continuous visibility into on-chain activity.
Real-Time Processing & Analytics
Once blockchain data is ingested, it is often processed in real time. Kafka integrates tightly with stream-processing frameworks such as Apache Flink, enabling continuous transformations, filtering, and enrichment of blockchain events.
Typical processing tasks include:
- Decoding transaction payloads
- Extracting smart-contract events
- Enriching data with metadata such as token information or address labels
Kafka is also frequently paired with analytics engines like ClickHouse for high-throughput, low-latency analytics. In this setup, Kafka acts as the streaming backbone, while analytical databases power real-time dashboards and on-chain metrics.
Fraud Detection & Risk Monitoring
Blockchain-based financial activity requires constant monitoring. Suspicious patterns, abnormal transfers, and risky behaviors must be detected as events occur.
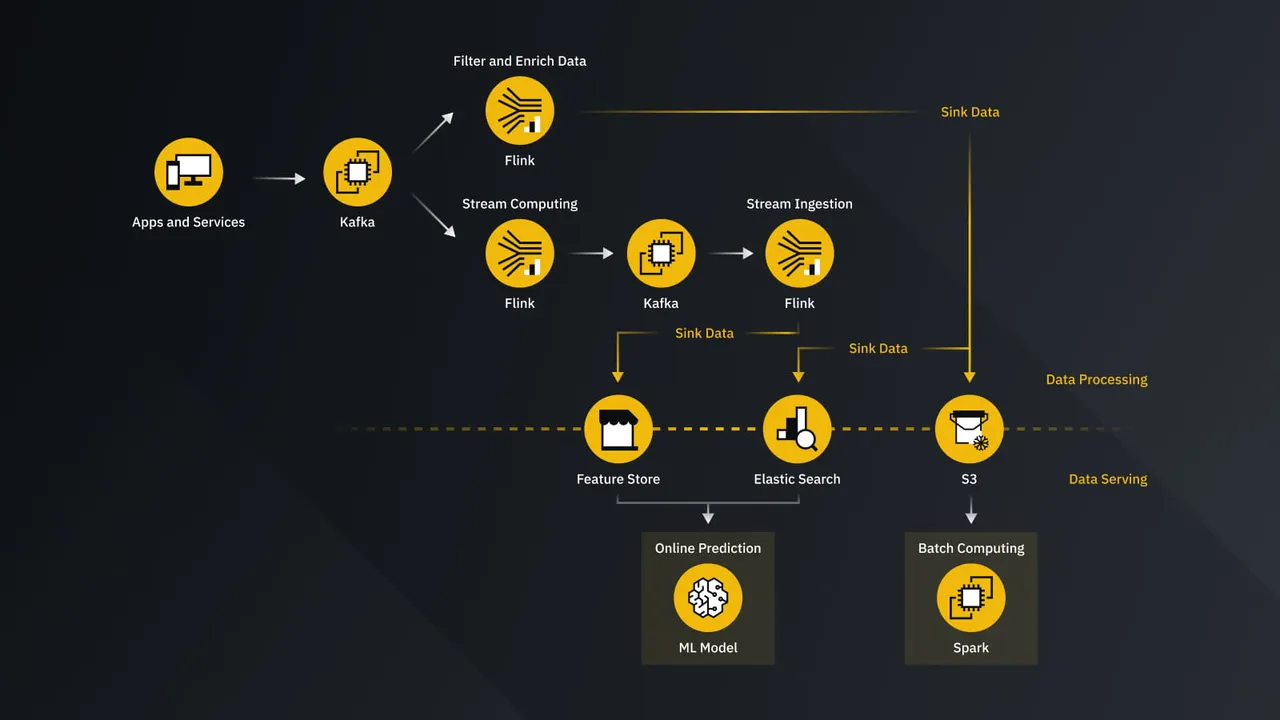
Kafka enables this by streaming blockchain events directly into risk and fraud detection systems, where rules engines or real-time analytics can evaluate transactions as they happen. This approach supports continuous monitoring rather than delayed, batch-based analysis.
Because Kafka is designed for low-latency message delivery, it is well-suited for real-time detection pipelines where speed matters. Events can be analyzed and flagged within seconds, allowing teams to react quickly to emerging risks.
Wallet, Address & Entity Monitoring
Blockchain analytics often require multiple parallel views of the same underlying data. Wallet monitoring, address clustering, and entity-level analysis all depend on consuming identical blockchain streams in different ways.
Kafka's consumer group model allows multiple independent pipelines to subscribe to the same blockchain data without interfering with each other. Each system processes events at its own pace while Kafka maintains delivery guarantees.
Blockchain analytics providers commonly use Kafka internally to distribute large blockchain datasets across teams and services. This architecture supports scalable wallet tracking, address labeling, and entity-level monitoring without duplicating ingestion logic.
Event Distribution (Fan-Out Architecture)
One of Kafka's strongest advantages in blockchain environments is fan-out distribution.
A single blockchain data stream can power multiple downstream systems simultaneously:
- Blockchain explorers
- Real-time dashboards
- Indexing services
- Monitoring and alerting platforms
Kafka consumer groups make this possible by allowing each application to consume the same data independently, while Kafka handles coordination and offset management.
Many organizations also use Kafka as a central data hub, where raw blockchain data is enriched and redistributed to internal teams and services. This hub-and-spoke model simplifies data sharing and reduces operational complexity across blockchain platforms.
Challenges With Traditional Kafka at Blockchain Scale
Blockchain workloads place unique pressure on streaming infrastructure. While Kafka is widely used in blockchain data pipelines, traditional Kafka architectures were not designed for the scale patterns that blockchains routinely produce.
One of the defining characteristics of blockchain traffic is burstiness. Network activity can spike dramatically during events such as NFT mints, token launches, liquidations, or periods of network congestion. These spikes are not gradual. They arrive suddenly, push throughput to extremes, and then subside just as quickly. Blockchain scaling research highlights how unpredictable and uneven transaction loads can become as networks grow.
High Replication Cost
Kafka relies on multi-replica partition replication to guarantee durability. At blockchain scale, this becomes expensive. Every write is replicated across brokers, multiplying storage usage and network traffic. For high-throughput blockchain streams, replication overhead grows rapidly and drives up infrastructure cost.
Cross–Availability Zone Traffic Fees
In cloud environments, Kafka replication typically spans multiple availability zones to ensure fault tolerance. This results in significant cross-AZ network traffic, which cloud providers charge for. For always-on blockchain data streams, these network fees can become one of the largest cost components of running Kafka clusters.
Slow Scaling and Operational Complexity
Kafka was originally designed for static, on-premise environments. Scaling a Kafka cluster still involves partition reassignment, data movement, and careful coordination, all of which are operationally heavy and time-consuming. For blockchain workloads that experience sudden spikes, this lack of rapid elasticity forces teams to overprovision capacity in advance.
Large Retention Requirements
Blockchain data is rarely short-lived. Many teams need to retain historical transaction and event data for analytics, audits, reprocessing, or replay. With traditional Kafka, long retention periods significantly increase storage costs because data must remain replicated across local disks.
Taken together, these challenges map directly to real blockchain workloads: bursty traffic, continuous ingestion, long-term retention, and wide fan-out consumption. While Kafka enables powerful blockchain data pipelines, its traditional architecture shows clear limitations when pushed to hyper-scale in cloud environments.
How AutoMQ Delivers Value for Blockchain-Data Use Cases
Blockchain workloads expose the structural limits of traditional Kafka deployments. AutoMQ addresses these limits by re-architecting Kafka for the cloud, while keeping full Kafka API compatibility. The value AutoMQ delivers comes directly from its documented architecture and operational characteristics.
Below, each capability is mapped to the blockchain data challenges discussed earlier.
Low Latency for Time-Sensitive Pipelines
Low latency is critical for blockchain use cases such as fraud detection, risk monitoring, and real-time alerts. AutoMQ supports single-digit millisecond P99 write latency when configured with a low-latency Write-Ahead Log (WAL) backed by cloud storage services such as EBS or FSx.
This design allows AutoMQ to meet the latency requirements of time-sensitive streaming pipelines while still benefiting from object storage for durability. For blockchain workloads that require fast detection and response, this capability enables real-time processing without abandoning Kafka semantics.
Elastic Scaling in Seconds for Bursty Traffic
Blockchain traffic is unpredictable. Transaction volumes can spike suddenly and exceed baseline capacity within minutes.
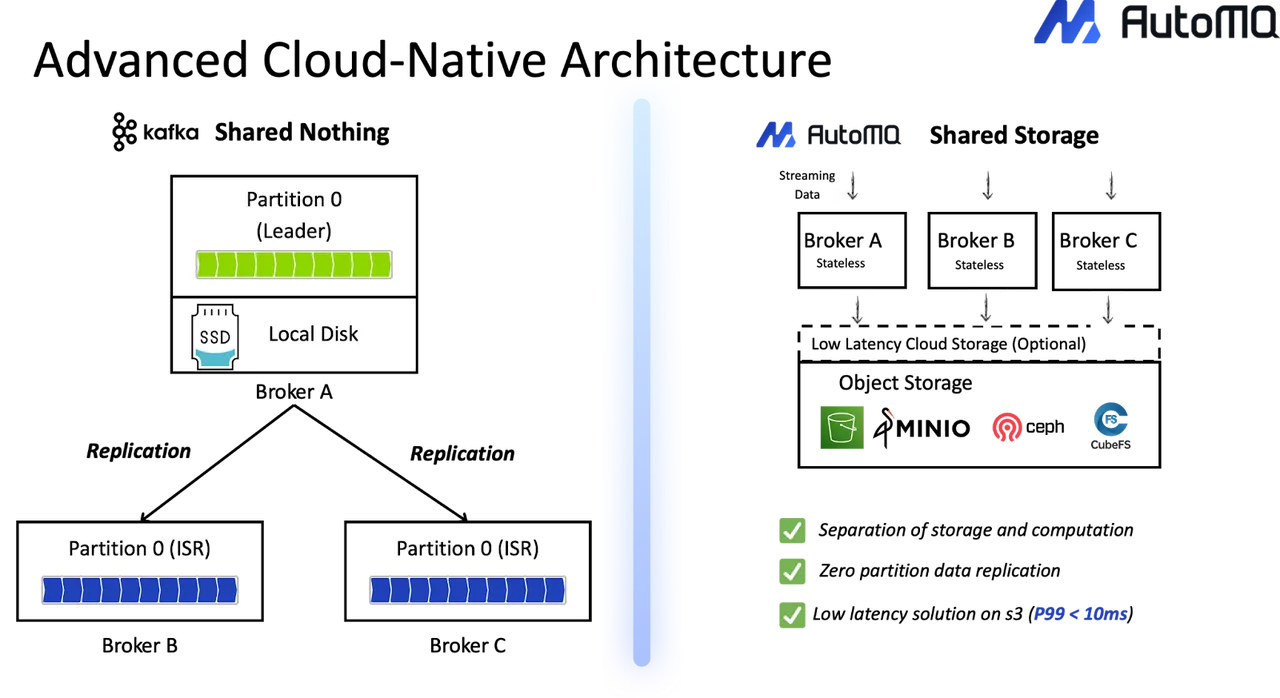
AutoMQ's diskless architecture turns Kafka brokers into stateless compute components. Because partition data is stored in shared cloud storage rather than local disks, scaling no longer requires time-consuming data movement or partition rebalancing. New brokers can be added and removed quickly, allowing capacity to scale in seconds.
This elasticity directly addresses the burst-driven nature of blockchain workloads and reduces the need for aggressive overprovisioning.
Cost-Efficient Retention with Object Storage
Blockchain data often needs to be retained for long periods. Storing this data on local disks with multiple replica drives up costs quickly.
AutoMQ offloads Kafka data to object storage, such as S3, which is designed for large-scale, cost-efficient data retention. According to AutoMQ's documented architecture, this approach can reduce Kafka-related infrastructure costs by up to 90% in applicable scenarios, primarily by lowering storage and network expenses.
This makes long-term blockchain data retention more economically sustainable without changing existing Kafka-based pipelines.
Zero Cross–Availability Zone Traffic Cost
Traditional Kafka clusters generate significant cross-AZ network traffic due to replication. For high-throughput blockchain streams, this can become a dominant cost factor.
AutoMQ eliminates this issue by relying on the durability guarantees of cloud storage rather than Kafka's multi-replica ISR mechanism. Producers write within the same availability zone, and data persistence is handled by shared storage. As a result, AutoMQ eliminates internal cross-AZ traffic costs within the Kafka cluster.
For blockchain teams running nodes, indexers, and analytics services across zones, this directly reduces operational cost.
100% Kafka Compatibility with No Pipeline Changes
Despite these architectural changes, AutoMQ remains 100% Kafka API compatible. It retains Kafka's compute layer and fully supports the Kafka ecosystem, including existing producers, consumers, connectors, and operational tools.
This means blockchain teams can adopt AutoMQ without rewriting pipelines, retraining developers, or abandoning established Kafka workflows. Migration can be incremental and low-risk, preserving long-term flexibility and avoiding vendor lock-in.
Conclusion
Kafka plays a central role in modern blockchain data pipelines. It enables real-time ingestion, processing, and event distribution at scale. However, traditional Kafka architectures struggle with bursty traffic, long retention, and rising cloud costs.
AutoMQ addresses these challenges with a cloud-native, diskless Kafka design. It delivers faster scaling, lower storage and network costs, optional low-latency operation, and simpler operations—while remaining fully Kafka compatible.
For teams running Kafka at blockchain scale, AutoMQ offers a practical path to operate more efficiently without changing existing pipelines.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


