
This article was written by Florian Beer, Engineering Team Lead, SRE at Laravel.
Laravel's Observability Challenge on AWS
Many developers first meet Laravel as the PHP framework they use to ship an application quickly. Routes, queues, databases, scheduled jobs, file storage, and the tools around them all live in one framework and ecosystem.
Laravel Cloud picks up once those applications need to run in production. Cloud is the fully managed cloud platform built by the Laravel team, enabling developers to run applications in production without provisioning a server, renewing a cert, wiring up a database, or getting paged at 3 a.m. because a queue worker died. As Laravel Cloud grew, the monitoring platform had to cover more than Laravel Cloud itself. It also had to follow supporting services, customer application workloads, and the signals behind alerting and incident response.
Those metrics come from a large number of clusters and nodes around the world, with hundreds of thousands of samples arriving every second. Laravel Cloud could not keep growing on top of a monitoring system whose operational work and cost grew at the same pace. That constraint pushed Laravel's SRE team to build a modern observability platform on Grafana Mimir.
The rollout achieved that goal in production. Laravel Cloud's observability platform handled roughly an order of magnitude more metrics volume while keeping the write pipeline easier to scale and operate. To understand why that result required a different Kafka layer, we need to start with the most important change in Mimir 3.0: ingest storage.
Why Mimir 3.0 Needed Diskless Kafka
To support this platform, we chose Grafana Mimir 3.0 as the storage and query engine for monitoring data. For our use case, the most important change in Mimir 3.0 is in the write path. Its ingest storage architecture separates metric ingestion from query processing.
In the previous write path, ingesters sat in both the write path and the query path. Writes are continuous. Queries are lower most of the time, then spike during releases, debugging, and incidents. When both types of load land on ingesters, it becomes hard to scale only one side of the workload. With Kafka-compatible ingest storage in Mimir 3.0, a write request is first written by the distributor to Kafka. After Kafka confirms the write, the request can return successfully. The ingester then consumes samples from Kafka and moves the data into the query and object storage path. The entry write path and backend consumption path can be scaled separately.
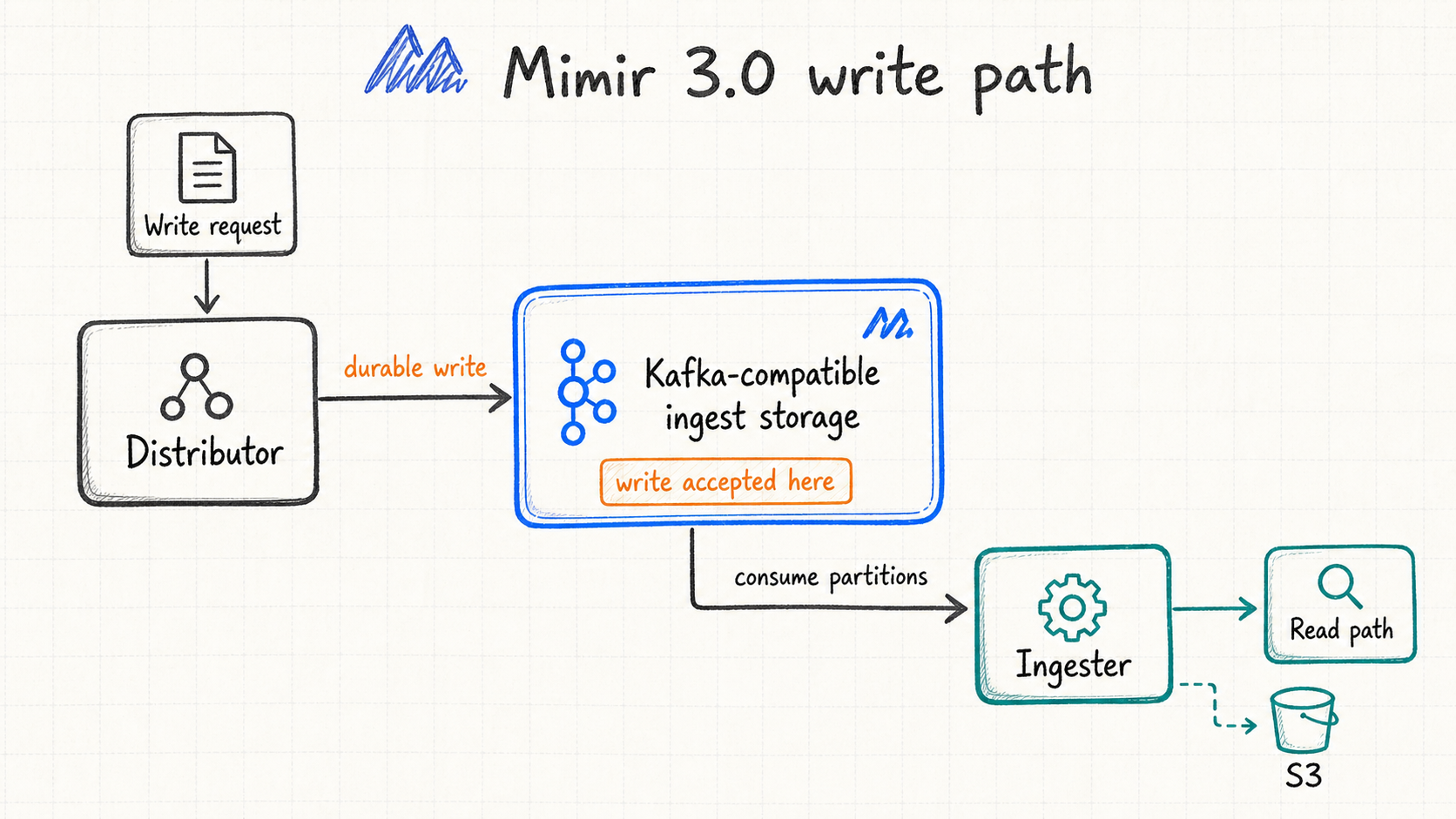
In this decoupled architecture, Kafka sits on the critical write path. During short write bursts or ingester failures, confirmed samples remain in Kafka, and ingesters continue consuming from Kafka after they recover. The Kafka architecture directly impacts cost, scaling behavior, and recovery model of the observability platform.
If we used a traditional Apache Kafka deployment backed by broker local disks, some old problems would move into the new Mimir architecture. In an observability workload, two issues matter most:
- Storage and replication costs grow with metrics volume. Metrics are written continuously, and data volume grows with services, nodes, and customer application workloads. Traditional Kafka keeps logs on broker disks, usually with multiple replicas. On AWS, that means paying for replicated EBS capacity, where block storage is already more expensive per GB than S3, and paying again for broker-to-broker replication traffic across Availability Zones.
- Capacity planning, scaling, and cluster operations become harder. Once brokers depend on local disks, scaling, node recycling, and failure recovery usually involve partition movement, replica catch-up, and local log loading. As metrics volume grows, the team still has to manage the Kafka local-disk layer in addition to watching write throughput and consumer progress.
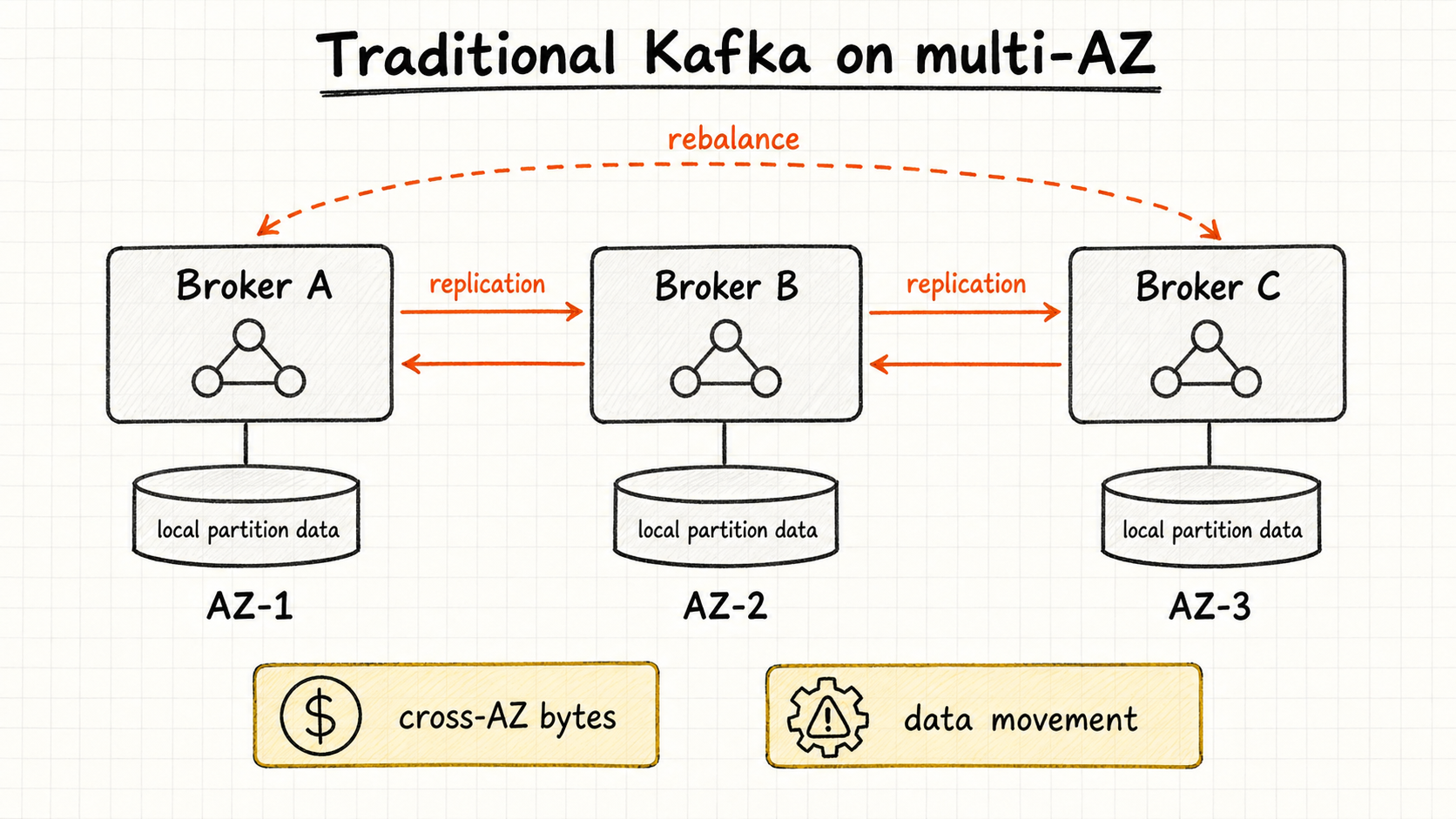
We needed a Kafka layer that fit the Mimir 3.0 architecture more naturally. It still had to provide durable buffering and replay, but it also needed to reduce the capacity, scaling, and recovery work caused by local disks. That is where we began evaluating AutoMQ, a Diskless Kafka implementation.
Why Laravel Chose AutoMQ for Mimir 3.0
AutoMQ is Diskless Kafka: it is 100% compatible with Kafka and built on a Shared Storage architecture backed by object storage. All Topic data is stored in S3, and brokers do not keep persistent data on local disks. That matched what we wanted from the Mimir 3.0 rollout. Long-lived state moves to object storage, while compute scales with load and relies on mature cloud storage such as AWS S3 for capacity and recovery.
We evaluated AutoMQ around five production questions.
| Question | What It Means for Laravel |
|---|---|
| Storage cost | AutoMQ stores Topic data in S3, so this Kafka layer does not need separately provisioned broker disks or multi-replica EBS capacity. For continuous metrics ingestion, cost no longer grows according to the traditional Kafka local-disk model. |
| Elastic scaling | Brokers do not keep local persistent data. Pod restarts, node recycling, and scale-out do not need to wait for local log recovery or data movement. As metrics volume grows, scaling decisions are driven more by write throughput, Topic partitions, and Consumer lag than by broker disk capacity. |
| Simpler operations | The SRE team no longer has to operate this Kafka layer around broker local disks, local log recovery, partition movement, and replica catch-up. Mimir's long-term blocks and AutoMQ Topic data both live in S3, so long-lived state is handled by the same type of cloud storage. |
| Migration cost | AutoMQ is 100% compatible with Kafka, and Mimir 3.0 already uses Kafka-compatible ingest storage. Evaluation work can focus on data consistency, consumer progress, and recovery behavior instead of changing Mimir components first. |
| Cross-AZ traffic | A traditional multi-AZ Kafka deployment depends on broker-to-broker replica replication. The larger the metrics volume, the more visible that cross-AZ replication cost becomes. AutoMQ removes the cross-AZ traffic cost caused by traditional Kafka replica replication. |
AutoMQ fit the Mimir 3.0 path because it covered both sides of the requirement. Kafka compatibility made the migration path more direct, while the S3-based Diskless Kafka architecture addressed the storage cost, scaling, recovery, and cross-AZ replication issues of traditional Kafka. In production, it gave us the cost, elasticity, and operational profile we were looking for.
Laravel's Modern Observability Architecture on AWS and Production Results
Laravel's observability platform runs on AWS with AutoMQ and Mimir 3.0. The production deployment looks like this:
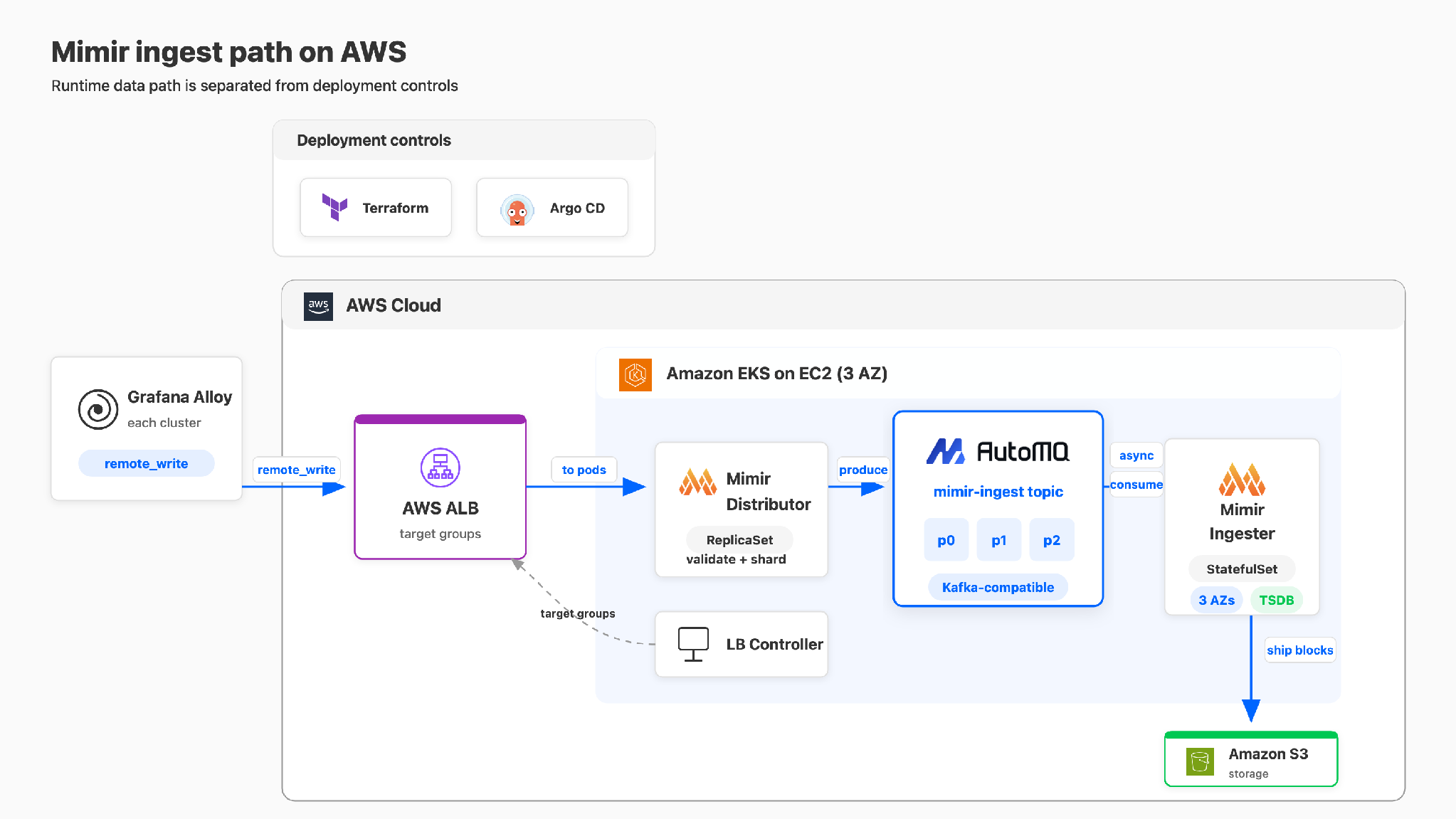
Metrics are generated in the clusters that run Laravel Cloud applications and platform services. Grafana Alloy collects metrics in these clusters and sends samples through remote write to the AWS entry point. AWS Application Load Balancer forwards requests to the Mimir distributor.
The distributor validates and shards samples, then writes records to the mimir-ingest Topic on AutoMQ. AutoMQ is the Kafka layer used by Mimir ingest storage and holds records that ingesters have not consumed yet. Mimir ingesters run as a StatefulSet, consume the partitions assigned to them, maintain recently queryable data with zone-aware replication across three Availability Zones, and upload long-term blocks to Amazon S3.
Compared with the previous architecture, the new setup changed three parts of day-to-day operations:
- More predictable storage cost. Mimir stores long-term TSDB blocks in S3, and AutoMQ stores Topic data in S3 as well. As metrics volume grows, capacity is mainly handled by object storage. The team no longer needs to keep estimating broker local disks and multi-replica EBS capacity for Kafka.
- Better scalability. Distributors handle the remote write entry point, ingesters consume Kafka data and maintain recently queryable data, and AutoMQ provides the Kafka buffer and replay layer in between. When writes increase, the team can scale the entry path, AutoMQ, and the ingester consumption side separately, instead of letting a local-disk layer dictate the scaling rhythm of the whole system.
- Simpler operations. With AutoMQ, the Kafka layer in Mimir ingest storage is no longer operated around broker local disks. During broker restarts, node recycling, or scale-out, the team does not need to handle local log recovery, partition data movement, or replica catch-up. Day-to-day troubleshooting also returns to signals such as write throughput, Consumer lag, and ingester consumption progress.
After rollout, Laravel Cloud's metrics volume increased by roughly an order of magnitude compared with the previous setup. Even with that growth, the architecture can still scale the entry write path, AutoMQ, and the ingester consumption side independently. The Kafka layer did not turn back into a local-disk scaling, log recovery, or partition movement problem.
For us, this rollout made one point clear: once Mimir 3.0 separates writes from queries, the Kafka layer in the middle should not pull the system back toward broker local disks. AutoMQ keeps the Kafka interface while placing Topic data in S3, so capacity growth is absorbed mainly by object storage. That gives Laravel Cloud a path to keep scaling this observability platform, and it is a pattern we expect to use in more places over time.


