Kafka adoption continues to accelerate as organizations modernize their data infrastructure for real-time analytics, event-driven architectures, and streaming applications. Across industries, Kafka has become the backbone for moving high-volume data reliably and in real time.
On Microsoft Azure, however, teams face a structural gap. Azure does not offer a native, fully managed Apache Kafka service. Instead, organizations are left with two imperfect choices. They either self-host Kafka on Azure infrastructure or they use Azure Event Hubs, which exposes a Kafka-compatible endpoint but is not a Kafka broker and does not fully replicate Kafka's native behavior or architecture.
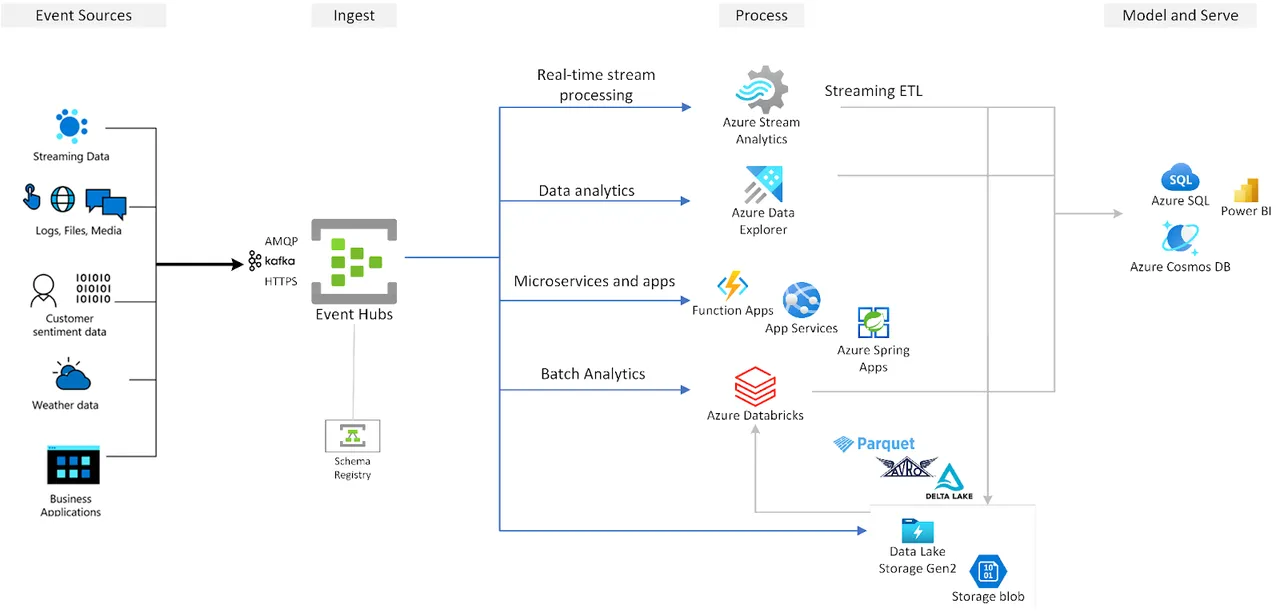
This gap matters. Running Kafka is not just about deploying brokers. It involves storage semantics, replication behavior, scaling operations, and day-to-day operational management. When these responsibilities fall entirely on internal teams, complexity and cost grow quickly, especially at scale.
As Kafka usage on Azure continues to expand, these challenges create a clear need for better Kafka deployment options. Solutions that preserve Kafka compatibility, reduce operational overhead, and align with cloud-native economics are becoming increasingly important for organizations building real-time systems on Azure.
Challenges of Self-Hosting Kafka on Azure
Running Kafka on Azure often means choosing between operational control and operational pain. Azure Event Hubs offers a Kafka-compatible endpoint, but it does not function as a Kafka broker. Teams cannot rely on Kafka-native storage semantics, broker behavior, or the full set of Kafka operational tools they expect when running Apache Kafka itself. For organizations with existing Kafka workloads, this difference can limit flexibility and create hidden migration risks.
Self-hosting Kafka avoids those limitations, but it introduces a different set of challenges. Operating Kafka clusters requires continuous effort. Teams must manage broker provisioning, monitor cluster health, handle partition reassignment, and rebalance workloads as traffic patterns change. These tasks are not occasional. They are ongoing and often disruptive, especially as data volumes grow.
Cost is another critical issue. Kafka relies on replication and frequent broker-to-broker communication to ensure durability and availability. In cloud environments, this communication generates significant cross–Availability Zone traffic. As clusters scale, inter-zone data transfer becomes a major contributor to infrastructure cost, adding financial pressure on top of operational complexity.
Together, these challenges make self-hosting Kafka on Azure difficult to sustain at scale. Engineering teams spend more time managing infrastructure and less time delivering value, while costs continue to rise alongside usage.
Requirements for an Effective Kafka Deployment on Azure
The challenges of self-hosting Kafka make one thing clear. Running Kafka on Azure requires more than basic compatibility or infrastructure automation. It requires a deployment model that fits the realities of cloud environments.
First, full Kafka API compatibility is non-negotiable. Teams need existing applications, connectors, and tooling to work without code changes. Partial compatibility or protocol emulation introduces risk and limits long-term flexibility.
Second, elasticity must be built in. An effective Kafka deployment should scale up or down without triggering complex and time-consuming rebalancing operations. Scaling should not require manual intervention or scheduled maintenance windows, especially in environments with unpredictable traffic patterns.
Cost efficiency is equally critical. Kafka deployments on Azure must minimize storage duplication and reduce inter–Availability Zone network traffic. Without addressing these two factors, infrastructure costs can quickly outpace the value delivered by streaming workloads.
Finally, the operational model needs to be simpler. Engineering teams should not spend their time managing partitions, brokers, and capacity planning. A Kafka deployment on Azure should reduce maintenance overhead and allow teams to focus on building and operating data-driven applications, not on running Kafka itself.
AutoMQ: A Fully Managed, Self-Hosted Kafka Service for Azure
AutoMQ is designed to address the operational and cost challenges of running Kafka in cloud environments, including Azure, while preserving full Kafka compatibility. It provides a managed Kafka experience without requiring organizations to give up control of their infrastructure or data.
At its core, AutoMQ offers full Kafka API compatibility. Existing Kafka applications can run without modification, allowing teams to continue using familiar Kafka clients, connectors, and ecosystem tools. This removes migration risk and protects prior Kafka investments, which is critical for production workloads.
AutoMQ deploys directly inside the customer's Azure environment, such as on Azure Kubernetes Service (AKS) or through a BYOC (Bring Your Own Cloud) model. Both the control plane and data plane remain within the customer's Azure account, supporting data residency, security, and compliance requirements defined by enterprise and regulated environments.
From an architectural perspective, AutoMQ uses a decoupled compute–storage model. Kafka brokers are stateless, while Kafka logs are stored in cloud object storage. This design eliminates the tight coupling between compute and local disks found in traditional Kafka deployments. As a result, brokers can be added or removed quickly without triggering complex data rebalancing operations.
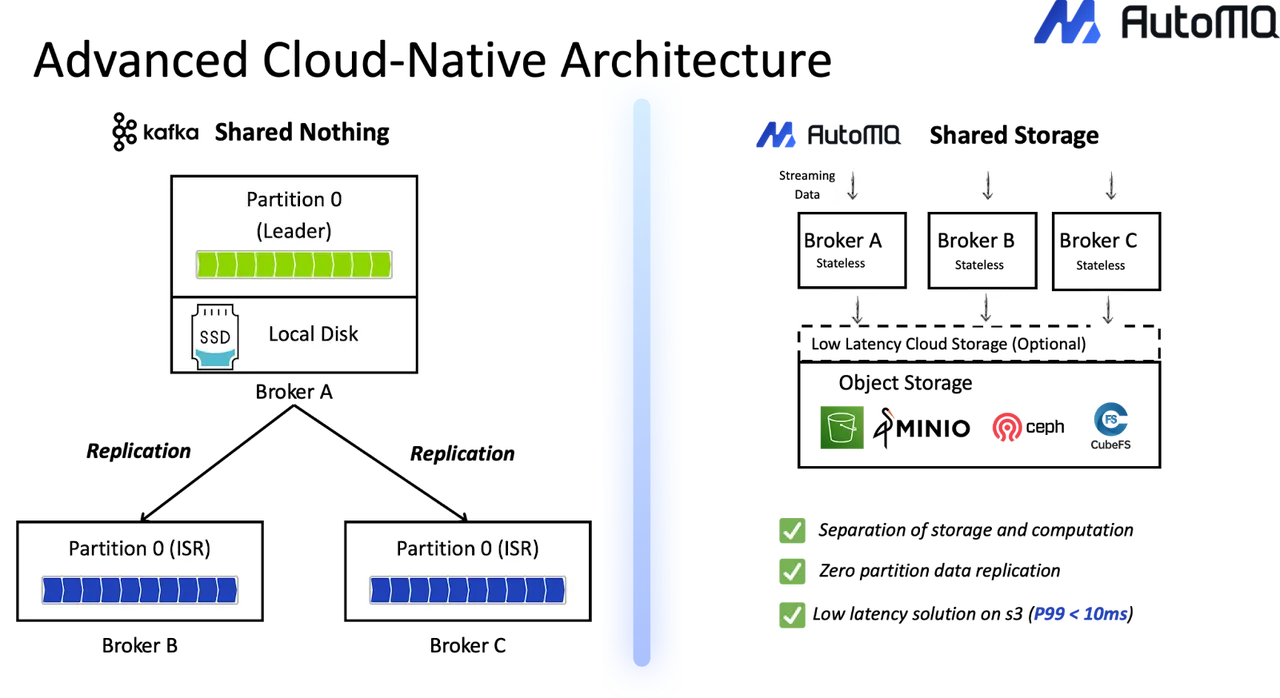
This cloud-native approach also improves cost efficiency. By relying on shared cloud storage rather than Kafka's multi-replica storage model, AutoMQ reduces storage duplication. At the same time, it minimizes cross–Availability Zone data transfer, lowering one of the largest cost drivers of Kafka deployments in the cloud.
Operationally, AutoMQ automates many of the tasks that typically consume engineering time. Scaling, partition movement, and day-to-day cluster management are simplified, allowing teams to operate Kafka on Azure with far less manual effort. The result is a Kafka deployment that aligns with cloud economics while maintaining the behavior and compatibility Kafka users expect.
Conclusion
Azure does not offer a native, fully managed Apache Kafka service. As a result, organizations are forced to choose between self-hosting Kafka—with its operational complexity and rising costs, or relying on Kafka-compatible alternatives that do not fully behave like Kafka.
AutoMQ addresses this gap by delivering a managed Kafka experience directly within the customer's Azure environment. It preserves full Kafka compatibility while reducing operational burden and improving cost efficiency through a cloud-native architecture.
For teams running Kafka on Azure, this approach provides a practical path forward—one that aligns with cloud economics, simplifies operations, and keeps control where it belongs. Kafka Azure deployments no longer have to be a trade-off between flexibility and manageability.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


