
At Confluent Current 2025 in June, OpenAI's real-time infrastructure team delivered back-to-back talks detailing how they scaled Apache Kafka throughput 20x in a single year while pushing availability from under three 9s to five 9s (source: OpenAI at Confluent Current 2025). What's more worth unpacking is what they gave up to get there: ordering, transactions, and partition processing — some of Kafka's most fundamental semantics.
37 Clusters, 50K Connections, and Three 9s Slipping Away
By the first half of 2024, OpenAI's streaming platform had been adopted by nearly every product team — data ingestion, async processing, inter-service communication — Kafka was everywhere in ChatGPT's backend. But the platform itself was, to put it bluntly, a mess.
OpenAI had over 30 independent Kafka clusters at the time, most spun up ad hoc by different product teams at different points. Configurations were inconsistent across clusters, and some were even running on different Kafka-compatible engines. The first question a new engineer faced wasn't "how do I use Kafka" but "which cluster is my topic on." Onboarding a product team onto Kafka took days or even weeks — something that should have taken hours.
Scalability was an even bigger headache. OpenAI's external services ran large numbers of replicas to handle ChatGPT traffic, each independently connecting to Kafka clusters. Making things worse, OpenAI primarily uses Python, and the GIL limitation meant a single pod needed up to 50 independent processes to squeeze out parallelism — each establishing its own Kafka connection. The result: a single broker on one cluster was hit with 50,000 concurrent connections, JVM memory maxed out, and connections kept dropping. This wasn't a connection storm — it was steady-state overload.
On the availability front, Kafka clusters were single points of failure for many internal services. A single zone failure or cluster crash meant hard downtime or data loss for customer-facing products. The entire platform couldn't even maintain three 9s — unacceptable for infrastructure powering ChatGPT.
All of these problems were painful but survivable. What truly blocked them was that the infrastructure team couldn't make any changes: product services were tightly coupled to specific Kafka clusters, so cluster migrations, version upgrades, or even configuration tweaks required coordinating with numerous product teams.
Building a Layer on Top of Kafka
To break this coupling, OpenAI reached for a classic architectural pattern: insert a proxy layer between clients and Kafka clusters so all services interact through the proxy instead of connecting directly.
The first problem to tackle was the connection explosion. They built Prism, a minimal gRPC service exposing a single ProduceBatch endpoint. Producers send messages and target topics to Prism, which routes them to the correct underlying Kafka cluster. Users no longer need to know which cluster hosts which topic, nor configure cluster credentials or firewall rules. They even built a client library called Photon that reduced onboarding to "import the library, call one function." A single Prism pod serves multiple client pods, dramatically reducing direct connections to Kafka brokers.
Connection counts converged, but cluster coupling remained. Prism's real power lies in multi-cluster routing: a single topic can be served by multiple Kafka clusters, with Prism load-balancing across them. If a publish request to one cluster fails, Prism transparently retries against another; if a cluster degrades for an extended period, a circuit breaker marks it unavailable and routes around it. Combined with the Cluster Group concept (a set of Kafka clusters containing the same topics), high-availability Cluster Groups deploy multiple clusters across different zones, and Prism writes to whichever cluster is healthy. All of this is invisible to producers.
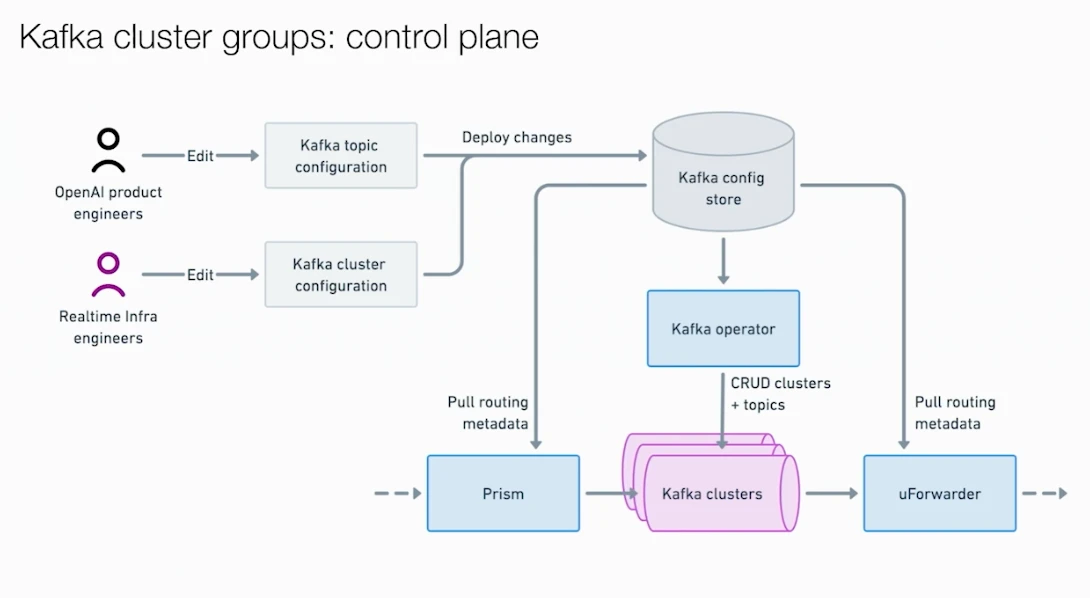
With the producer side decoupled, the consumer side needed the same treatment. OpenAI adopted Uber's open-source UForwarder and customized it into an internal Kafka Forwarder. It's a push-model consumption platform: UForwarder pulls messages from Kafka and pushes them to consumer services via gRPC. Consumers only need to expose a gRPC endpoint for message handling — no Kafka client, no offset management, no credential configuration. UForwarder also includes production-grade capabilities like retries and dead-letter queues, and supports parallelism beyond the partition count.
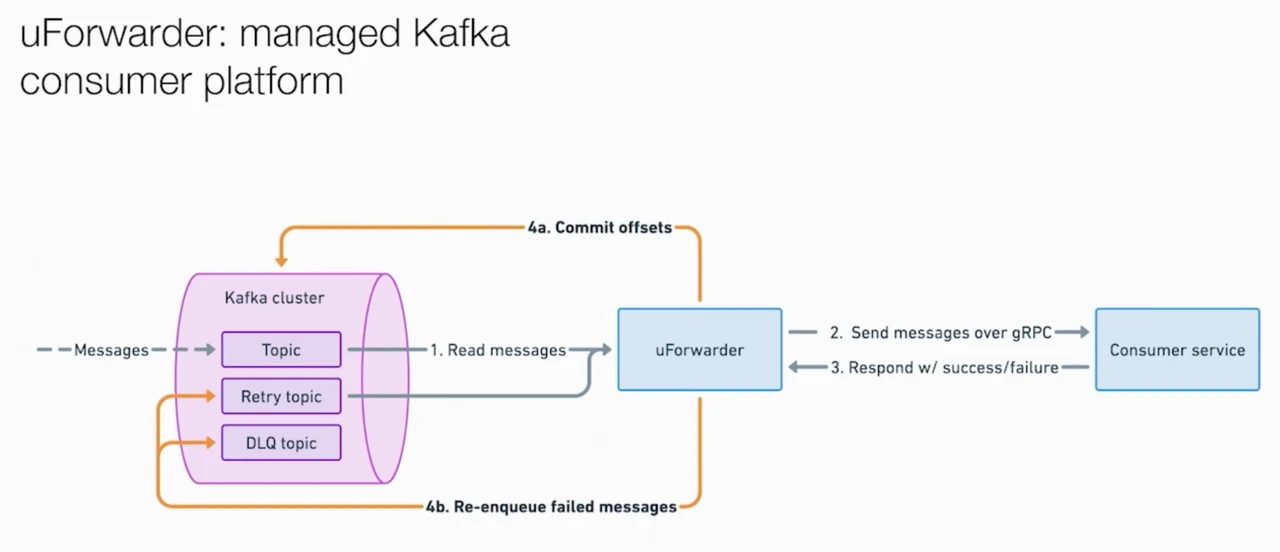 The migration process itself was cleverly designed: create the topic on the new cluster, have UForwarder consume from both old and new clusters simultaneously, gradually shift Prism's writes to the new cluster, and decommission the old cluster once its data expires. Each migration completed traffic cutover in about 30 minutes, fully transparent to users. The results:
The migration process itself was cleverly designed: create the topic on the new cluster, have UForwarder consume from both old and new clusters simultaneously, gradually shift Prism's writes to the new cluster, and decommission the old cluster once its data expires. Each migration completed traffic cutover in about 30 minutes, fully transparent to users. The results:
| Metric | Before Migration (2024 H1) | After Migration |
|---|---|---|
| Kafka clusters | 30+ independent clusters | ~6 HA Groups |
| Migration duration | — | ~2.5 months |
| User impact | — | Zero downtime, fully transparent |
| Throughput | Baseline | 20x growth |
| Availability | Under 3 nines | 5 nines |
The Price: What OpenAI Gave Up for Availability
OpenAI's engineers were remarkably candid in their talks: this architecture required them to abandon several of Kafka's core semantics.
| Capability Sacrificed | Reason | OpenAI's Workaround |
|---|---|---|
| Message ordering | Multi-cluster routing means messages with the same key can land on different clusters | Attach logical clock tags to each message, infer order downstream |
| Exactly-once semantics | The proxy layer cannot support idempotent writes and transactions | Require consumer business logic to be idempotent + downstream deduplication |
| Partition processing | UForwarder distributes messages randomly to consumer instances, no sharding | Use Apache Flink for stateful stream processing |
| Keyed publish | Same as above — multi-cluster routing breaks key-to-partition mapping | Re-partition within downstream applications |
These aren't edge-case features. Ordering, transactions, and partition processing are what distinguish Kafka from a generic message queue — they're foundational assumptions for many stream processing use cases. OpenAI's philosophy is "Simple things should be simple, complex things should be possible." They kept a direct-to-Kafka escape hatch for the minority of use cases that need these capabilities, but steered the vast majority through the proxy layer.
OpenAI's engineers noted that in practice, users didn't really mind these limitations, and adoption actually grew faster thanks to the simplification. That may hold true in OpenAI's context, where Kafka use cases are dominated by async processing and data ingestion with low demand for ordering and transactions. But for the broader Kafka user base, this trade-off exposes a fundamental issue: if achieving cloud-grade elasticity and availability requires sacrificing core semantics, the problem isn't in the application-layer trade-off decisions — it's in the Kafka engine itself.
The Root Cause Behind the Workarounds
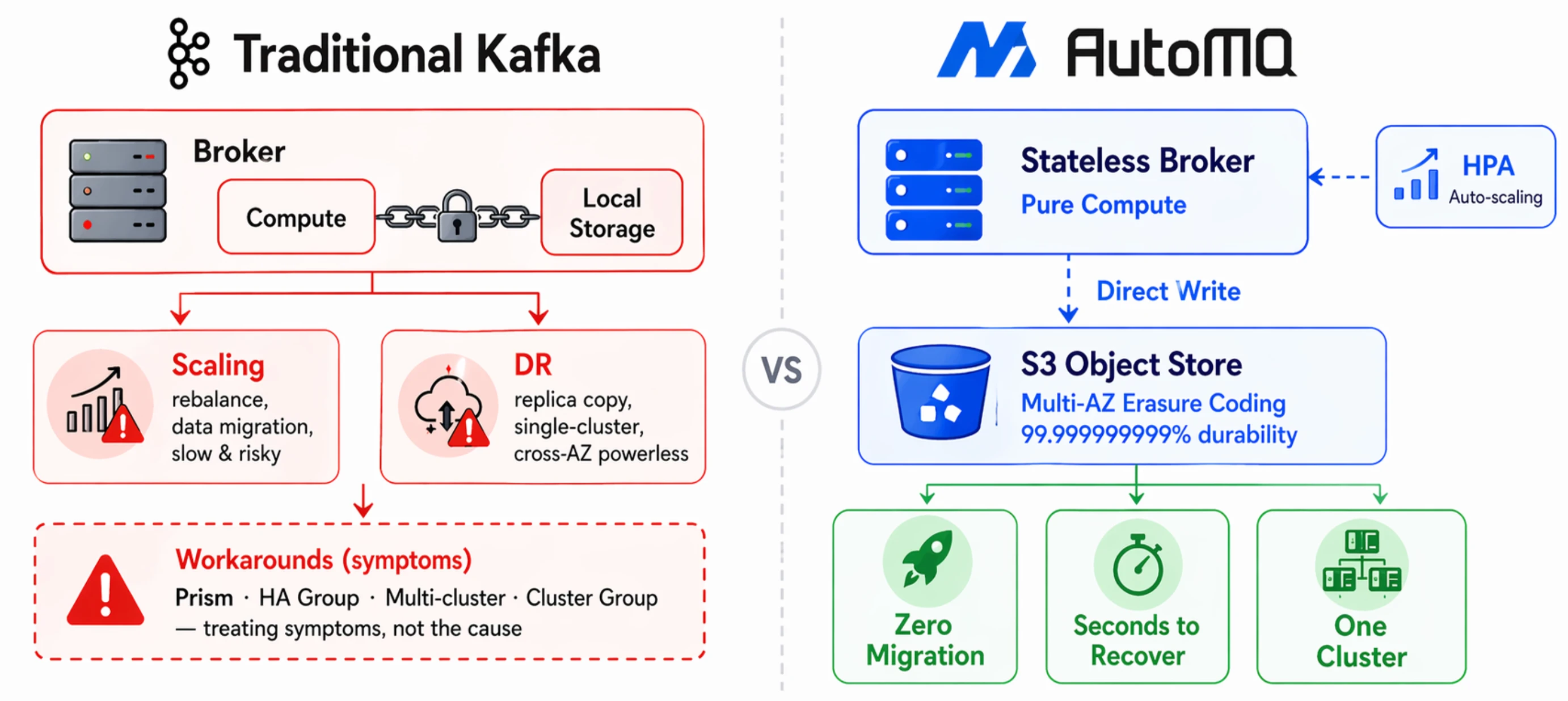
Every problem OpenAI's proxy layer works around traces back to the same root cause: brokers manage both compute and storage, binding state to individual nodes. If this root cause were addressed at the engine layer — brokers become stateless, data persists to shared object storage — these workarounds lose their reason to exist.
Take OpenAI's 50,000-connection JVM meltdown. They used Prism to converge connection counts, but the underlying issue was that you can't freely add brokers — each new broker triggers data rebalancing, moving large volumes of partition replicas in a slow process that impacts live traffic. If brokers were stateless, scaling out is just adding a compute node. Connection capacity scales linearly with broker count, and you could even use Kubernetes HPA for autoscaling.
The scaling story is similar. OpenAI chose to "add new clusters" rather than "add brokers to existing clusters" for horizontal scaling precisely because rebalancing the latter was too risky. When partition data lives in shared storage rather than on local broker disks, partition migration becomes a pure metadata operation: update the mapping of "which broker serves this partition" and you're done — not a single byte of data moves. The elasticity problem vanishes at its root.
Then look at where OpenAI invested the most engineering effort: multi-cluster HA Groups, Prism circuit breakers, cross-cluster retries — the entire failover apparatus. Traditional Kafka's multi-replica replication provides broker-level fault tolerance, but it's powerless against zone failures or entire cluster outages because all replicas live within the same cluster.
If data is written directly to object storage like S3, durability is inherently multi-AZ (S3 delivers 11-nines durability via erasure coding). When a broker fails, any surviving node can take over the partition and resume serving within seconds. S3's multi-AZ erasure coding already handles this — OpenAI rebuilt the same guarantee at the application layer.
When a single cluster can handle traffic fluctuations through elastic scaling and guarantee cross-AZ durability through object storage, the premise behind OpenAI maintaining 37 clusters disappears. Cluster count naturally converges, ZooKeeper bottlenecks vanish with it, and the storage-compute separation architecture is a natural fit for KRaft with no external coordination components needed. Most critically, OpenAI gave up ordering, exactly-once semantics, and partition processing because multi-cluster routing broke key-to-partition mapping. Under a disaggregated storage architecture, a single cluster provides sufficient elasticity and availability — no multi-cluster routing needed, and therefore no need to sacrifice these semantics. 100% Kafka protocol compatibility means all existing Kafka clients, Kafka Connect, and Kafka Streams work seamlessly without changing a single line of code.
AutoMQ is a storage-compute separated Kafka implementation built along exactly this direction. Putting OpenAI's pain points, their proxy-layer solutions, and the engine-layer alternatives side by side:
| OpenAI's Pain Point | Proxy-Layer Solution | Engine-Layer Resolution via Storage-Compute Separation |
|---|---|---|
| Single broker OOM at 50K connections | Prism converges connection count | Stateless brokers, elastic scaling, connections scale linearly with broker count |
| No single-cluster disaster recovery | Multi-cluster HA Group + circuit breakers | S3-native multi-AZ durability, broker failure recovery in seconds |
| Scaling requires rebalancing | Multi-cluster horizontal scaling to bypass rebalance | Partition migration is a pure metadata operation |
| 30+ clusters with zero standardization | Cluster Group unified management | Single cluster covers all needs, no multi-cluster required |
| ZooKeeper removal | Planned | Complete (KRaft built-in) |
| Sacrificed ordering/transactions/partition processing | Accepted the trade-off | No sacrifice needed — 100% Kafka protocol compatible |
Of course, writing data to S3 isn't without trade-offs. Object storage API call latency is higher than local disk, and tail latencies (p99/p999) require additional optimization. In high-frequency, small-batch write scenarios, the cost of S3 API calls themselves can't be ignored either. This is a different engineering trade-off — not a silver bullet.
On storage costs, traditional Kafka's three-way replication combined with EBS (Elastic Block Store) redundancy results in effective storage overhead far exceeding object storage's erasure coding approach. The storage-compute separation architecture eliminates inter-broker replication entirely — data writes go directly to S3, with erasure coding ensuring durability — significantly reducing storage costs. Detailed cost comparison data is available at the AutoMQ official benchmark.
The Roadmap and the Destination
During the Q&A at Confluent Current in June 2025, someone asked OpenAI's engineers about their view on Diskless Kafka. The answer: "We're very actively thinking about and exploring it." When you've already paid this much engineering cost to work around traditional Kafka's limitations, a fundamental evolution at the engine layer is naturally the most compelling next step. OpenAI proved that Kafka can work at massive scale even without ordering and transactions, but that cost is itself the strongest argument: engine-layer evolution is no longer optional. For teams planning their next-generation streaming infrastructure, the only question is whether to solve it at the engine layer now, or build a proxy layer first and deal with it later.
Want to solve these problems directly at the engine layer? Try AutoMQ on GitHub, or check out the storage-compute separation architecture docs for technical details.


