
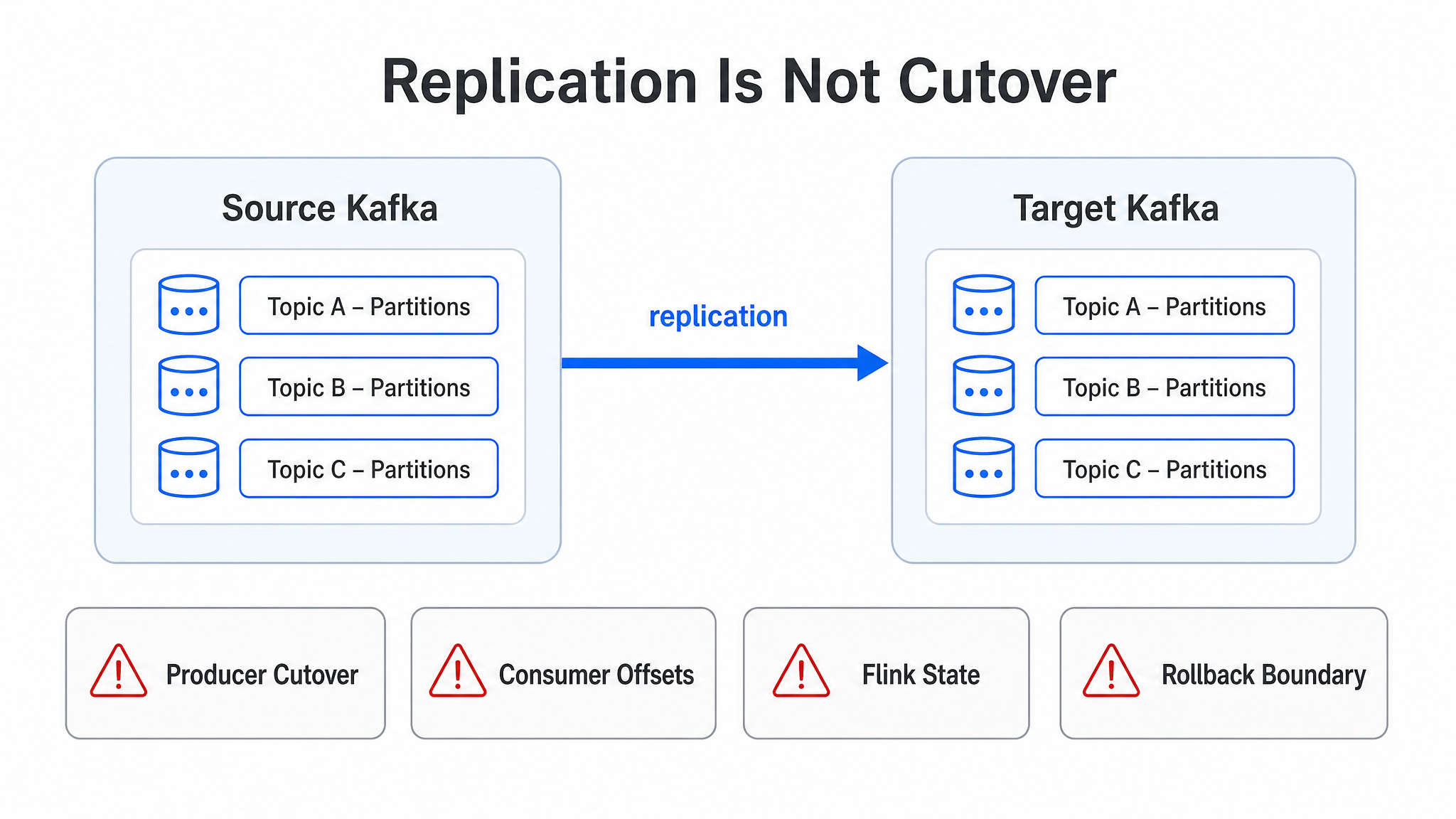
When teams migrate Apache Kafka, the most stressful part is usually not starting the replication job. It is the few hours when clients start moving. The old cluster is still receiving writes, the new cluster is starting to receive traffic, some Producers have already changed bootstrap.servers, others have not, Consumer groups need a safe offset to resume from, and Flink checkpoints may contain positions that must still make sense after the switch. Many migration plans focus on whether data can be copied. The downtime window and rollback risk usually sit in these cutover details.
The problem often starts when Kafka migration is treated as "just run MirrorMaker 2." MirrorMaker 2 is a mature cross-cluster replication tool. It is good at replication. Zero-downtime Kafka migration has to solve cutover. The two are close to each other, but the engineering risks are different.
What MirrorMaker 2 Gets Right
MirrorMaker 2 should not be dismissed outright. Built on Kafka Connect, it uses Connectors to replicate Topic data, configurations, ACLs, and Consumer group offsets, while fitting into the Connect worker model for scaling and monitoring. For long-running replication tasks, it remains a natural choice in the Kafka ecosystem.
It works well for several clear scenarios:
- Geo-replication and disaster recovery: Continuously replicate data from one cluster to another Region for DR, audit, or downstream analytics.
- Data aggregation: Bring data from multiple business clusters into a central cluster for offline or real-time analytics.
- Hybrid cloud synchronization: Keep data synchronized across self-managed Kafka, managed Kafka services, and different cloud providers.
- Read-side expansion: Move some read workloads to a target cluster so every downstream system does not hit the primary production cluster.
These use cases share the same goal: make sure another cluster has a usable copy of the data. As long as data replicates, lag is observable, and failures can be retried, MirrorMaker 2 can deliver value. Kafka migration is different because the target cluster must become the new production cluster at a specific point in time, not merely hold a standby copy.
Replication Complete Is Not Migration Complete
A MirrorMaker 2 migration looks straightforward on paper: create a target cluster, start replication, wait until the target catches up, and switch clients to the new cluster. The first half often feels manageable. The replication task is running, lag is dropping in dashboards, and the team can easily feel that the migration is almost done.
The pressure starts when Producers move. As long as the source cluster continues to accept new writes, the target cluster must keep catching up. If some Producers write to the source cluster while others write to the target cluster, the two clusters can diverge. To avoid that split, teams often stop writes, wait until replication lag reaches zero, and then point Producers to the target cluster. At that point, "migration" becomes a maintenance window: whether the business can stop, how long it can stop, who confirms lag is truly zero, and how to roll back if the switch fails.
Consumer cutover is not just an address change either. Kafka consumption progress is organized by Topic, Partition, and Offset. A migration tool must answer a concrete question: from which offset should the same Consumer group resume on the target cluster? If offsets on the target cluster are not consistent with the source cluster, the team needs offset translation. That translation already requires care for normal consumer applications. It becomes sharper with Flink or Spark Streaming, where consumption position may be embedded in checkpoints or application state. The application may not trust Kafka's internal Consumer group offset at all. It trusts the position stored in its own state.
The most dangerous illusion in Kafka migration is confusing "the target cluster has data" with "the business can safely move." The first is replication state. The second is production state.
This is where MirrorMaker 2's boundary shows up. It is designed around the replication path, not around business cutover. A replication path can tell you data moved from A to B. A migration system must also tell you when writes move, when reads are allowed, how offsets remain valid, and where the rollback boundary is.
Why MirrorMaker 2 Offsets Increase Migration Risk
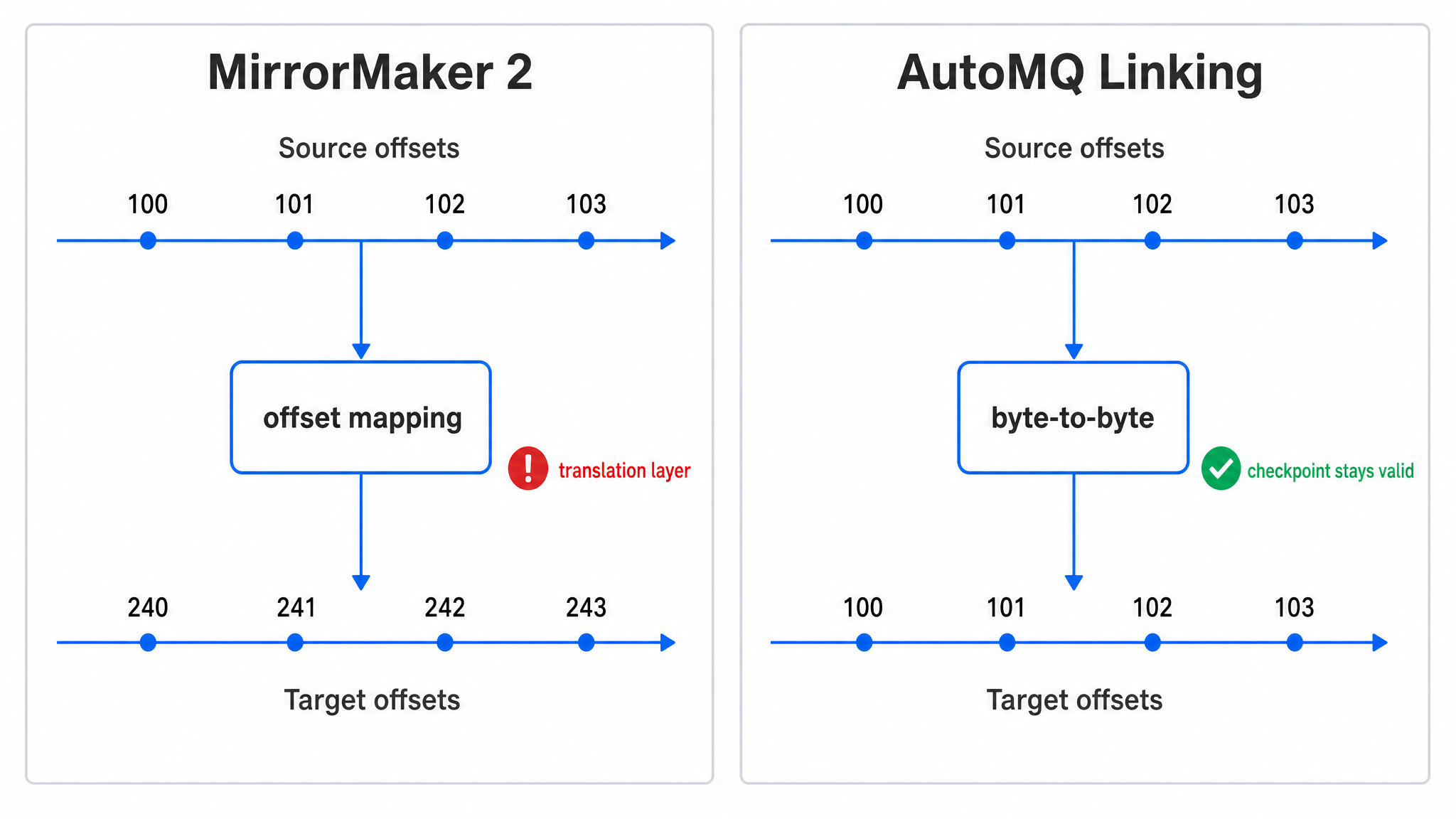
Kafka offsets look like simple increasing numbers, but in a migration they carry business continuity semantics. A Consumer is not reading "the Nth message" in the abstract. It is continuing after a specific offset in a specific Topic Partition. If offsets change after migration, even when the data itself is identical, the consumer system needs a mapping layer to know where to resume.
MirrorMaker 2 can synchronize Consumer group offsets and maintain offset mappings between the source and target clusters. This design fits cross-cluster replication because the target log is not an in-place continuation of the source log. Replication may involve topic aliases, metadata updates, and independent log append on the target side. But once the task becomes migration, offset mapping becomes a translation layer on the recovery path. The closer a translation layer sits to recovery, the more nervous operators become.
That translation layer introduces several practical risks:
- Cutover timing becomes harder: Consumer group offset synchronization has intervals and conditions. During the migration window, the team must confirm source progress, target mapping, and replication progress at the same time.
- Duplicate or skipped consumption becomes harder to diagnose: When post-migration behavior is wrong, the team has to inspect source offsets, target offsets, offset sync topics, and application state together.
- External state systems may not fit the model: Flink, Spark Streaming, and similar applications may store Kafka positions in their own checkpoint or state. Kafka internal Consumer group offset synchronization does not automatically fix that external state.
- Rollback becomes fragile: If new data is written to the target cluster after cutover, source and target offsets and data boundaries must be reconciled before rollback can be clean.
This is not a quality problem in MirrorMaker 2's implementation. It is a design-goal mismatch. MirrorMaker 2 serves cross-cluster replication, where the target cluster can have its own log positions and a mapping connects the two sides. Zero-downtime migration aims for something different: make the target cluster look as much as possible like a continuous extension of the source cluster, so clients and stateful systems do not need to understand that a cluster replacement happened.
Kafka Migration Needs a Cutover Plane
A migration has at least two paths. The first is the data replication path: how historical and incremental data moves from the source cluster to the target cluster. The second is the business traffic path: where Producers write, where Consumers read, and how traffic returns if something fails. Many migration incidents are not caused by a total replication failure. They are caused by a lack of systematic control over business traffic.
A migration tool needs to answer questions like these:
- Can Producers move in batches instead of stopping all writes at once?
- Can writes from already-migrated Producers still be consumed by Consumers that remain on the source cluster?
- Before a Consumer group is fully migrated, can the target cluster prevent duplicate consumption?
- Can Topic Partition offsets stay 1:1 between the source and target clusters?
- Can Flink checkpoints and Spark state remain valid after cutover?
- If migration fails, is there a clear rollback boundary instead of manual data repair?
Only part of this is "replication." The rest is the cutover plane: coordinated control over write paths, read paths, consumption progress, and rollback paths during migration. MirrorMaker 2 can be part of a replication path, but it does not turn those cutover actions into a complete migration protocol.
Once you use that standard, the question becomes whether the target cluster can play an intermediate role during migration. It needs to accept writes from migrated Producers while still preserving complete data for Consumers that remain on the source cluster. It needs to copy historical data while keeping offsets recognizable to stateful applications. It also needs to support phased migration instead of concentrating all risk into one outage window.
AutoMQ Linking Adds This Migration Coordination Layer
AutoMQ Linking is designed around that problem. It targets migration from Apache Kafka or Kafka-compatible distributions to AutoMQ. Instead of splitting migration into "replicate first, stop and switch later," it brings the data path and traffic path into one migration workflow. Application code does not need to change, and clients can move in rolling batches.
The first layer is byte-to-byte replication. Messages from the source Topic Partitions are copied to the target cluster while keeping offsets aligned. The target cluster does not need to create a separate set of offsets and translate back to the source. For systems that rely on Kafka offsets to restore state, this difference is practical. For Flink jobs that store positions in checkpoints, it affects whether existing state can continue to be used instead of resetting or reprocessing history.
The second layer is the Producer proxy path. When migrating Producers, teams can move Producer access addresses to AutoMQ in batches. After a migrated Producer writes to AutoMQ, AutoMQ proxies the write back to the source cluster during the migration phase. Consumers still running on the source cluster can see the complete stream of new writes, while Producers that have not moved continue writing to the source. The business does not have to stop writes to avoid divergence.
The Consumer side cannot be reduced to an address change either. If the target cluster immediately allows new Consumers to read before the whole Consumer group has moved, duplicate consumption can occur alongside the old Consumers on the source cluster. AutoMQ Linking coordinates Consumer groups during migration: after a Consumer group leaves the source cluster and completes the switch, it synchronizes consumption progress and then allows target-side consumption. This step is not flashy, but it is critical. Many "replication is done" migrations fail precisely here.
MirrorMaker 2 vs. AutoMQ Linking in a Migration Context
The boundary is clearer when the comparison starts from the migration goal.
| Dimension | MirrorMaker 2 | AutoMQ Linking |
|---|---|---|
| Core positioning | Cross-cluster replication, DR, aggregation, synchronization | Zero-downtime Kafka migration to AutoMQ |
| Data path | Kafka Connect-based replication path | Byte-to-byte replication with offset alignment |
| Producer cutover | Often requires stopping writes, waiting for lag, or building custom dual-write coordination | Supports rolling Producer cutover and proxies writes back to the source during migration |
| Consumer cutover | Relies on Consumer group offset synchronization and offset translation | Synchronizes consumption progress and coordinates Consumer groups to avoid duplicate consumption |
| Flink / Spark state | External state positions may not be covered by Kafka offset sync | 1:1 offset consistency improves the feasibility of preserving state continuity |
| Rollback | If new writes occur on the target after cutover, teams must manually reconcile source and target differences | During migration, writes can still be proxied back to the source, keeping rollback boundaries clearer |
| Operations model | Requires deploying and operating Connect workers, Connectors, and internal topics | Provided by AutoMQ as a migration capability managed with the target cluster |
MirrorMaker 2 still belongs in replication, disaster recovery, and synchronization. Once the task becomes "move production Kafka workloads to a new cluster with minimal business impact," the object under management changes from a data copy to production traffic. If the tool boundary is misread, downtime windows, offset validation, and rollback plans all fall back into manual procedures.
When MirrorMaker 2 Still Makes Sense
The decision should return to the migration goal. If your goal is to keep a second cluster continuously populated for disaster recovery, analytics, aggregation, or read-only consumption, MirrorMaker 2 remains reasonable. Its ecosystem is mature, its deployment model is well understood, and many teams already have operational experience with Kafka Connect. In those scenarios, the main concerns are capacity planning, replication latency, and operational stability, not business cutover semantics.
But if the goal is production cluster migration, especially when several of the following conditions are true, MirrorMaker 2 should no longer be the default plan:
- The business cannot accept a single write-stop window, and Producers must move in rolling batches.
- There are many Consumer groups, and large amounts of manual offset validation are unacceptable.
- Stateful consumers such as Flink, Spark Streaming, or Kafka Streams are involved.
- The team needs fast rollback after migration, not a "once cut over, only move forward" path.
- Migration needs to proceed by Topic or Consumer group instead of as one big-bang switch.
These conditions are common in production. Kafka often sits at the center of data pipelines. Upstream services, stream processing jobs, monitoring systems, user behavior analytics, and risk-control pipelines may all depend on it. The more central a Kafka cluster is, the less acceptable it is to base migration on "find a quiet window, stop writes for a while, and hope everything works."
The Migration Model Is What Needs to Change
MirrorMaker 2's issue is not that it cannot replicate. The issue is that Kafka migration can no longer be modeled as only replication. Replication tools focus on how data gets to the other side. Migration tools must focus on how the business moves to the other side. The former cares about lag. The latter also cares about write paths, consumption progress, state recovery, and rollback.
"Do not use MirrorMaker for Kafka migration" does not mean MirrorMaker 2 has no value. It means Kafka migration should not default to a replication path plus a maintenance-window cutover. That model may work for small, low-dependency clusters. In production environments with stateful processing, many Consumer groups, continuous writes, and strict availability requirements, it leaves the hardest part to manual coordination.
Production Kafka migration needs data replication, Producer cutover, Consumer coordination, offset continuity, and rollback paths in the same workflow. MirrorMaker 2 can keep doing what it does well: replication. Production migration should use a tool designed for migration.
If your team is evaluating a move from Apache Kafka, MSK, or Confluent to AutoMQ, start by validating AutoMQ Linking with a small set of non-critical Topics and Consumer groups, then bring core workloads into the plan gradually. To see how this works in your own Kafka environment, start with AutoMQ and validate rolling Producer cutover, Consumer group coordination, and offset continuity with a real migration task.


