AutoMQ is a next-generation Kafka distribution redesigned based on cloud-native principles and compatible with Apache Kafka®. This article will elaborate on the Kafka Linking feature provided by AutoMQ and explain how to use Kafka Linking to reassign business from Apache Kafka® or other Kafka distributions to AutoMQ.
Reassignment Scenarios
AutoMQ is compatible with Apache Kafka®, enabling Kafka Linking to seamlessly reassign Kafka distributions provided by other vendors. Details are listed below:
Source Cluster
| Target Cluster
| Reassignment Support
|
|---|
Apache Kafka
| AutoMQ
| Support
Kafka Linking is compatible with Apache Kafka® versions >= 0.11.
|
AWS MSK
| Support
Kafka Linking does not currently support MSK IAM Role authentication mode and only supports the native ACL authentication mode.
|
Confluent Platform
| Supported
|
Alibaba Cloud Kafka
| Supported
|
If the current Kafka release version you are using is not listed above, please contact us immediately for support and assistance.
Overview of Kafka Linking
AutoMQ Cloud provides users with the Kafka migration tool Kafka Linking, offering seamless migration from Apache Kafka® or other Kafka distributions to AutoMQ.
The Kafka Linking migration tool has the following advantages:
-
Non-Stop Reassignment: Unlike MirrorMaker2, which requires client downtime for switching, Kafka Linking is equipped with a built-in traffic proxy component that ensures the switching process for Producers does not require downtime.
-
Byte to Byte Copy: Unlike MirrorMaker2, which alters message positions post-copy, Kafka Linking supports Byte to Byte Copy. Data from all partitions in the source cluster is replicated to the new cluster with unchanged offset information, ensuring computation engines like Flink Job, which maintain position information, can switch seamlessly.
-
Synchronized Consumption Progress: Kafka Linking supports synchronized source cluster consumption progress, allowing consumers to resume consumption from the target cluster post-migration with consistent position information.
-
Elastic Scaling on Demand: Kafka Linking requires no separate deployment and scales with the AutoMQ cluster on demand, reducing operational complexity during reassignment.
-
High Kafka Compatibility: Kafka Linking supports most historical versions of Apache Kafka (version >=0.11) as well as other commercial editions, allowing seamless transitions to AutoMQ.
Kafka Linking Terminology and Concepts
Kafka Linking defines a series of terms, listed as follows:
Kafka Link
A Kafka Link is a data synchronization and proxy task for a set of Topics from an external Apache Kafka cluster to an AutoMQ Kafka instance, including the configuration required for data synchronization, real-time operational status, and traffic proxy control.
Source Cluster
The Source Cluster is an abstract configuration defined in Kafka Linking for the migration source cluster. The Source Cluster is described by AutoMQ’s console-provided Kafka integration, containing configuration information such as the source cluster’s access point, ACL rules, alias, etc.
Sink Cluster
The Sink Cluster is an abstract configuration defined in Kafka Linking for the migration target cluster. The Sink Cluster specifically refers to an AutoMQ instance (currently Kafka Linking only supports AutoMQ instances as Sink Clusters), containing configuration information such as the target cluster’s access point, ACL rules, alias, etc.
Mirror Topic
Mirror Topic is the basic unit used in Kafka Linking to synchronize and reassign a Topic from the source cluster to the target cluster. Each Mirror Topic corresponds to a specific Topic in the source cluster and serves as the unique representation of that Topic in the target cluster.
Source Topic
Source Topic is the expression of the Topic in the source cluster for Kafka Linking. In each Kafka Link, the Source Topic and Mirror Topic correspond one-to-one.
Consumer Group
Kafka Linking supports copying consumption progress information from the source cluster’s Consumer Group and synchronizing it to the target cluster. Users can specify the Source Cluster’s Consumer Group and configure it to the Sink Cluster’s designated Consumer Group.
Kafka Linking Architecture
Unlike MirrorMaker2, which implements data synchronization based on Connectors, the Kafka Linking reassignment tool reconstructs two paths: Byte-to-Byte replication path and Producer proxy path:
-
Byte-to-Byte Replication Path: This is used for synchronizing data from the Source Cluster to the Sink Cluster, ensuring data integrity and position consistency.
-
Producer Proxy Path: Traditional MirrorMaker2 requires Producers to be completely shut down before switching to the target cluster to avoid data disorder caused by simultaneous writing to both clusters. AutoMQ Kafka Linking provides a Producer proxy path that supports traffic proxying back to the source cluster during the switching process and subsequent unified switching, enabling zero-downtime switching.
Byte-to-Byte Replication Path
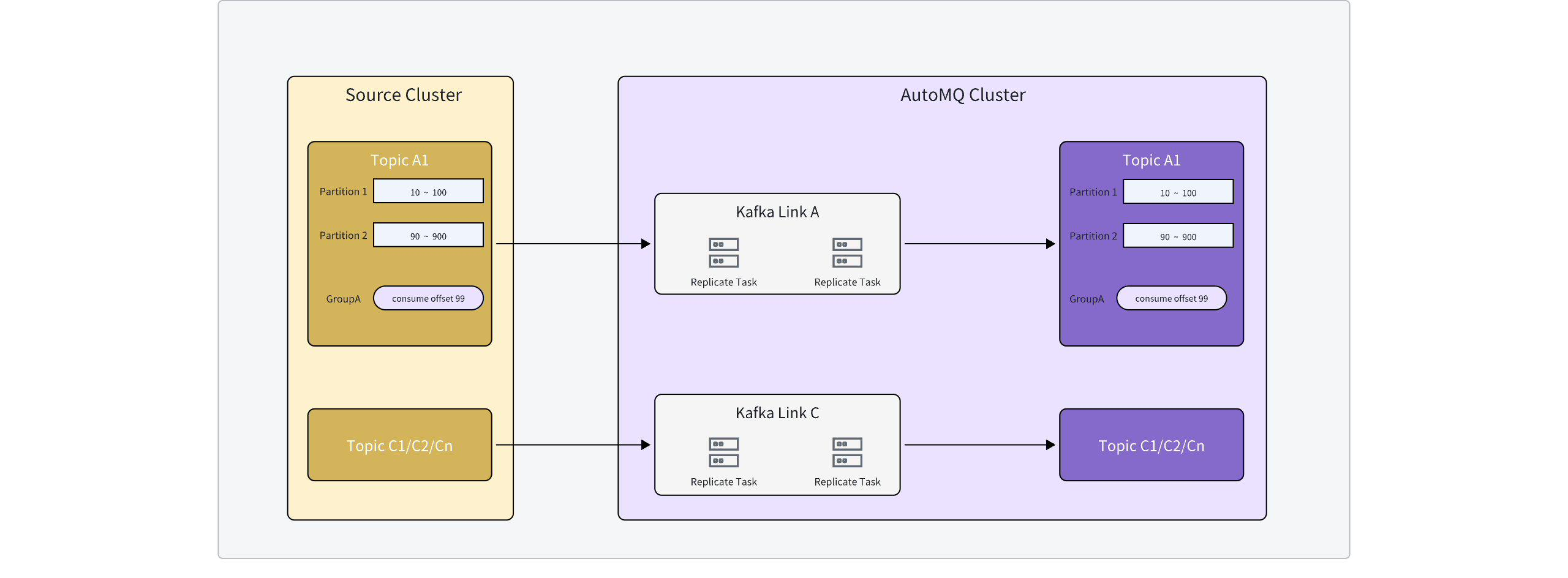 Kafka Linking’s data synchronization links can achieve the following effects:
Kafka Linking’s data synchronization links can achieve the following effects:
-
Topic partition numbers are completely consistent.
-
Message full synchronization, with offsets exactly aligned with the source cluster.
-
Consumer offsets are synchronized; the specific partitions’ consumer offsets for specific Consumer Groups in the source cluster are fully synchronized to the target cluster, maintaining consistency.
Producer Proxy Link
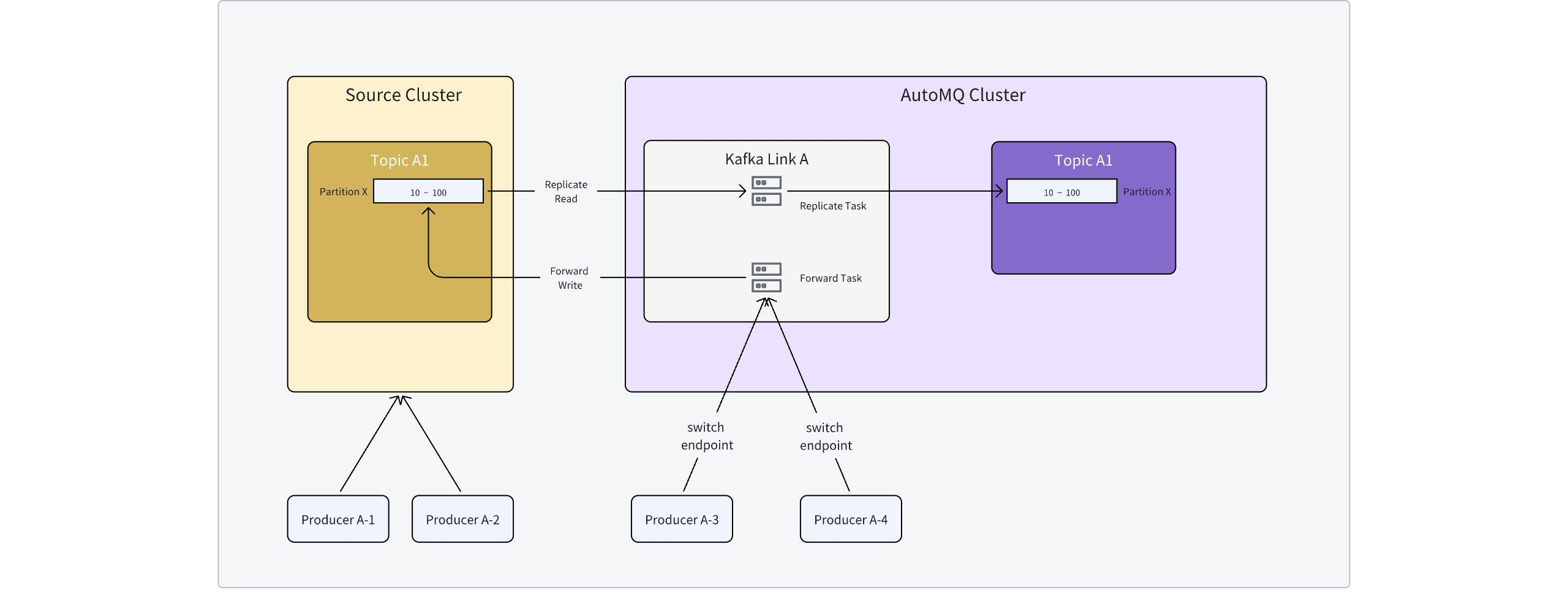 Producer proxy link provided by Kafka Linking has the following capabilities:
Producer proxy link provided by Kafka Linking has the following capabilities:
-
Supports Producer rolling-switch access point reassignment, with no downtime during the switch, ensuring no disruption to writing processes.
-
Supports normal read/write operations on the source cluster during reassignment, with no impact, allowing applications to switch as needed.
Next Steps
To understand the background and functionality of Kafka Linking, it is recommended to follow this sequence:
-
Prerequisites sorting: Identify the characteristics of the source cluster and business relationships that need reassignment, plan the reassignment batches, and check prerequisite resources. Prerequisites▸
-
Executing reassignment plan: After completing the prerequisites sorting, implement the reassignment plan step by step as per the scheme. Executing Migration▸
