
Community contributors list
Main updates for AutoMQ for Kafka
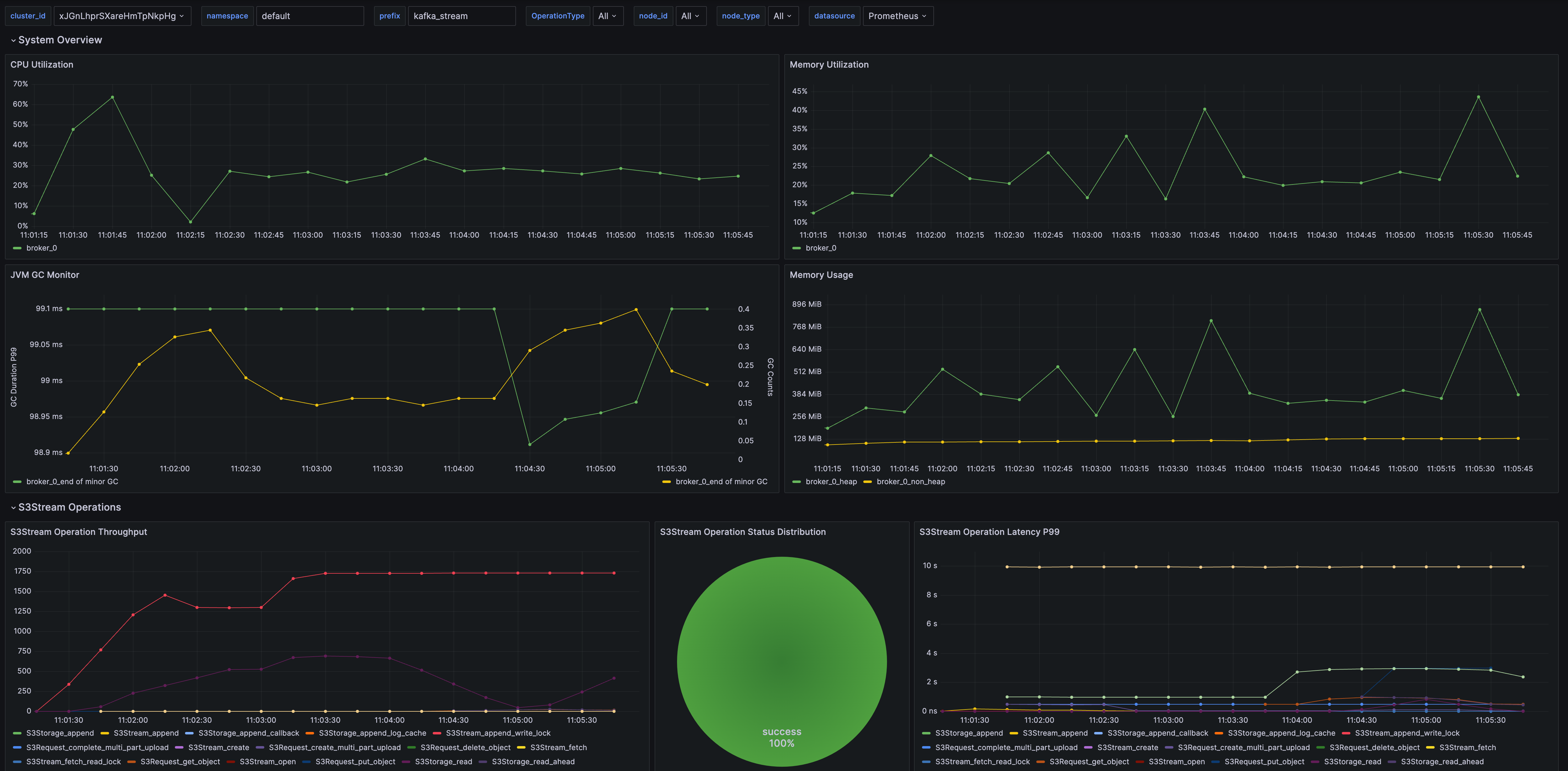
Comprehensive Metrics & Trace integration
#613 Added a one-click script for launching Prometheus and Grafana, and automatically importing the AutoMQ Kafka dashboard
#845 #848 Enriched Metrics for the storage layer
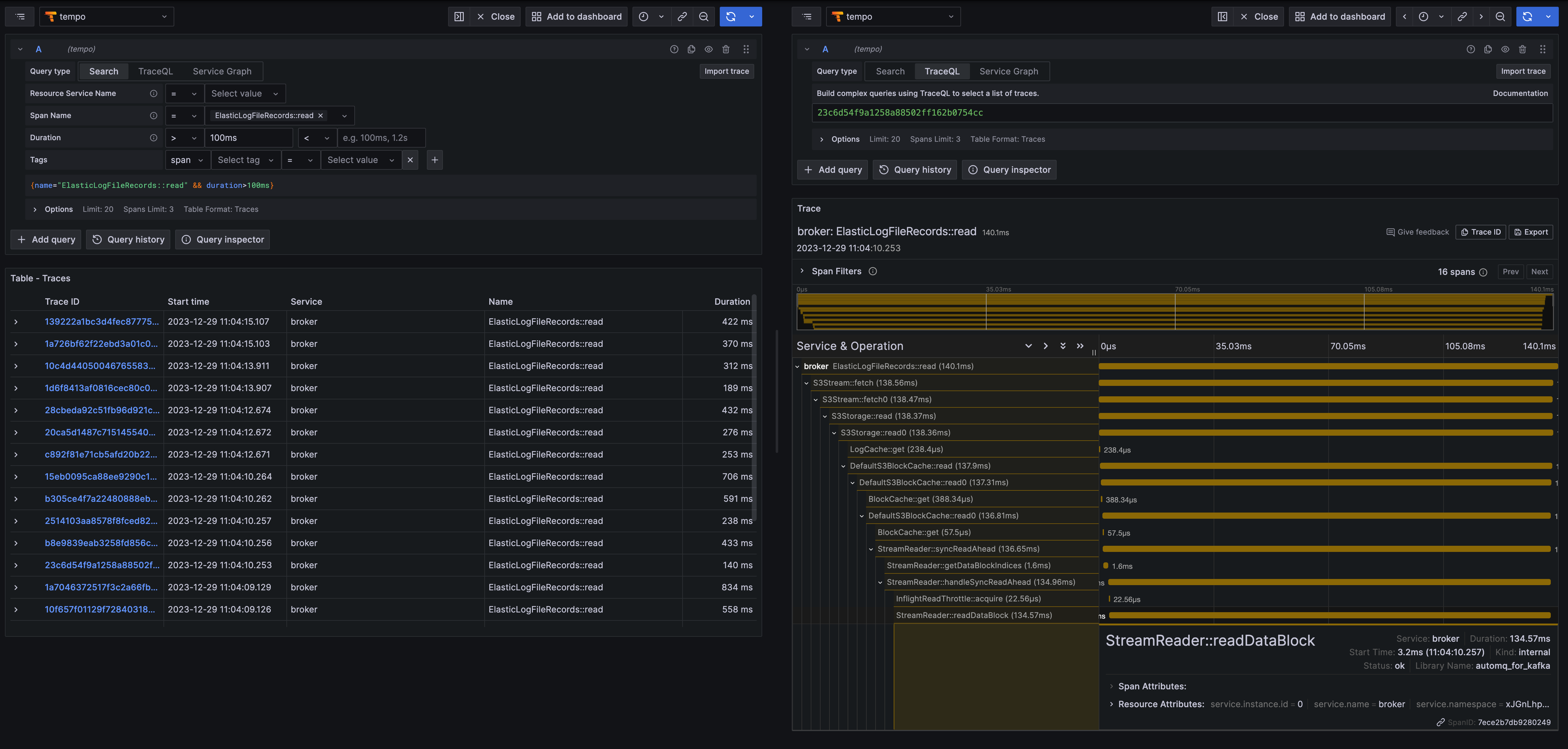
#866 #610 Core read/write link Trace support
Accelerated shutdown for large-scale single-machine partitions
#591 Parallel partition shutdown optimization: from original node shutdown timeout optimized to a 45s completion of shutdown.
#858 Stream shutdown acceleration: Refine the waiting for tasks uploading to S3 during shutdown, reducing the overall shutdown duration from 45s to 17s.
Through two optimizations, a total of 5000 partitions can now be shut down in just 17 seconds.
Accelerated recovery from abnormal shutdowns
#596 800MiB partition unclean shutdown recovery time improved from 19s to 1.5s
In the original Apache Kafka®, after an unclean shutdown, the partition recovery process involves clearing the indexes of all segments where segment.endOffset > recoverPoint, followed by extensive data reading from disk for index rebuilding. This leads to a prolonged recovery time due to the large volume of data involved.
AutoMQ Kafka optimizes the exception recovery process by starting recovery from the recoverPoint and enhancing it with more frequent checkpoints, limiting the data volume needed for single partition recovery after an unclean shutdown to within 50MiB, thereby achieving a predictable recovery time of 1.5 seconds.
Support for a cluster with 100,000 Partitions & 200TB of storage, PART1
#857 #612 Optimizing memory usage for Kraft metadata in large-scale partition clusters, resulting in an 80% reduction in metadata memory footprint, with an expected memory usage of 120MiB for a cluster with 100,000 Partitions & 200TB.