Introduction
AutoMQ is a newly designed Kafka distribution based on cloud storage, offering a tenfold cost advantage and second-level elasticity compared to traditional Apache Kafka. To help users seamlessly transition from their existing Kafka clusters to AutoMQ, we released Kafka Linking in version 5.0—a fully managed cross-cluster data synchronization feature with zero downtime. Current tools for Kafka cluster synchronization that commonly used in industry, such as MirrorMaker 2 [1], Confluent Cluster Linking [2], and WarpStream Orbit [3], require a three-step process of "shutdown," "wait," and "restart" for both the producer and the consumer. This approach is not only time-consuming but also complicates migration risk assessment due to uncontrollable wait times, further degrading the user experience. In contrast, with AutoMQ Kafka Linking for cluster migration, clients need only to perform a single rolling upgrade to redirect their clients from the original Kafka cluster to the AutoMQ cluster, significantly reducing the manual operation costs associated with current solutions. This article will explain how to use AutoMQ Kafka Linking to migrate from a Kafka cluster to AutoMQ with zero-downtime and the technical principles behind Kafka Linking.
Challenges of Current Solutions
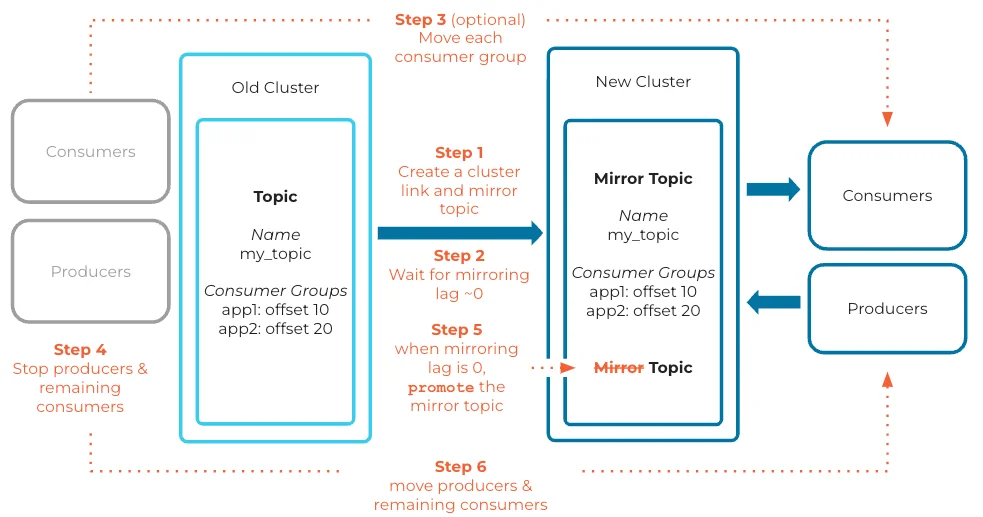
Let's take Confluent as an example. Below is the process for cluster migration using Confluent Cluster Linking [4]:
*ref:*https://docs.confluent.io/cloud/current/_images/cluster-link-migrate-cc.png
During the migration process, the first step involves stopping the producer in the source cluster. After ensuring the mirroring lag is zero, the Mirror Topic is promoted (i.e., synchronization is stopped), and then the producer is restarted and directed to the target cluster. This procedure can lead to several minutes of downtime. Other industry solutions like MM2 and Orbit follow similar migration processes, as they all use one-way synchronization architecture. To prevent message divergence, it is crucial to ensure perfect data alignment and no new data between the source and target clusters during client migration. AutoMQ enhances one-way synchronization by offering backward forwarding, allowing simultaneous writes to both the source and target clusters while maintaining write consistency. Consequently, migration can be completed with just a single rolling upgrade.
Migrating clusters using Kafka Linking
This section will detail how to migrate from any cluster that supports the Kafka protocol to an AutoMQ cluster. Below is an overview of the migration steps:
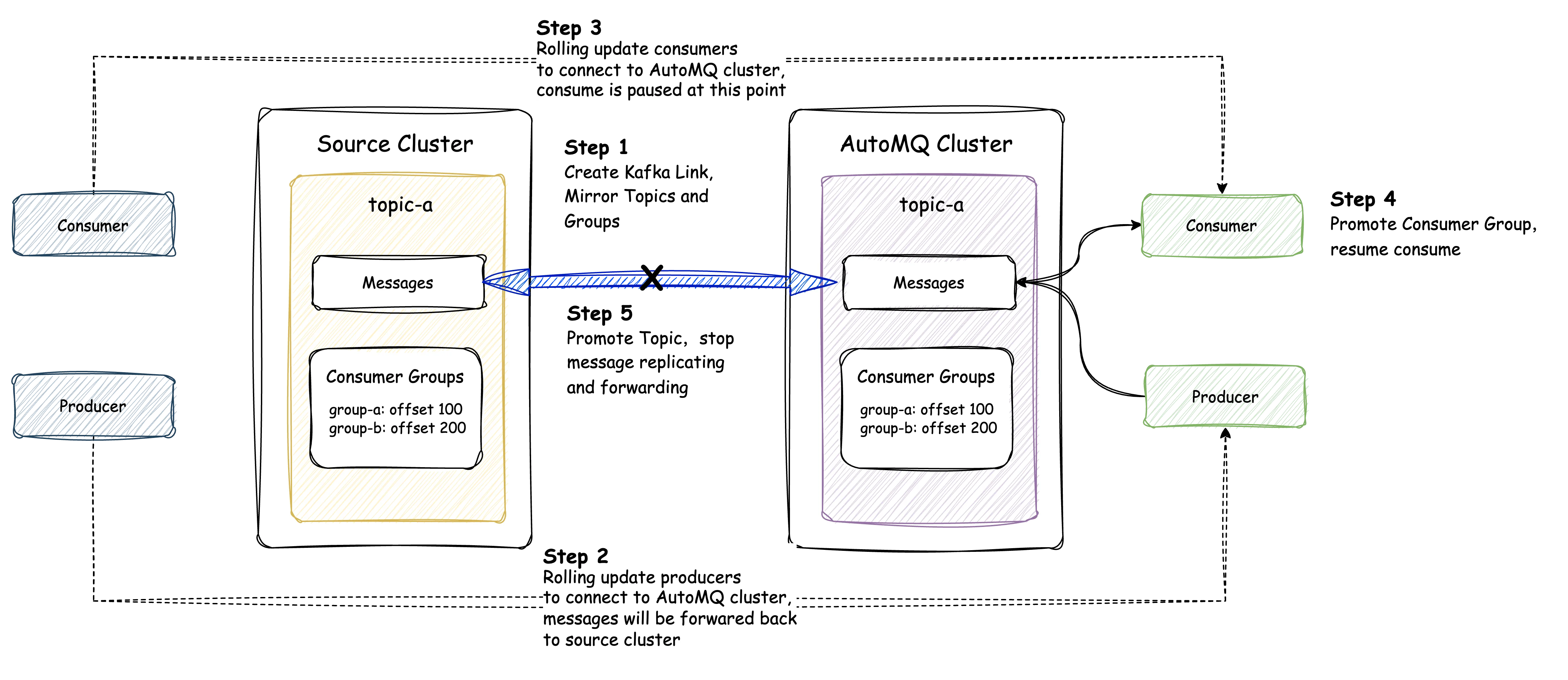
Create a Kafka Link
A Kafka Link is a synchronization link from a source cluster to an AutoMQ cluster. It is the smallest unit that manages a set of topics and consumer groups to be reassigned. Creating a Kafka Link involves only persisting the source cluster information to AutoMQ, without generating additional resources or request operations at this stage.
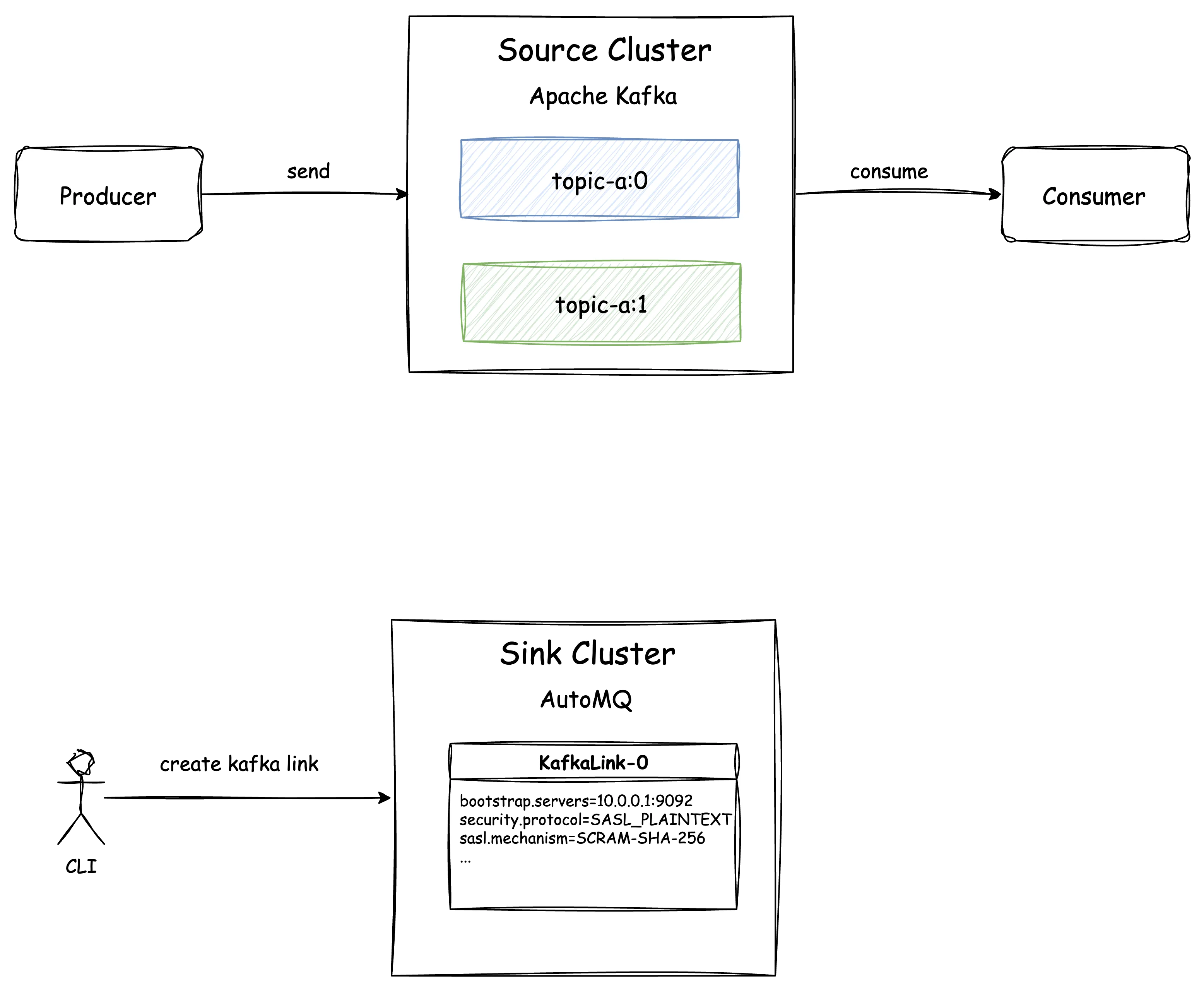
Once the Kafka Link creation is complete, AutoMQ records the configuration information of the source cluster corresponding to the Kafka Link. This configuration information will be used later to establish a connection with the source cluster.
Create Mirror Topic
For all the source cluster topics that need to be migrated, users need to corresponding mirror topics in the AutoMQ cluster to initiate data synchronization. Mirror topics in AutoMQ have the same read and write capabilities as regular topics, with additional functionality of data synchronization and forwarding. As illustrated in the figure below, a topic with the same name and two partitions as the source cluster is created in the AutoMQ cluster. Once the topic creation is complete, data synchronization begins, and messages sent from the producer are effectively written to both the source and target clusters.
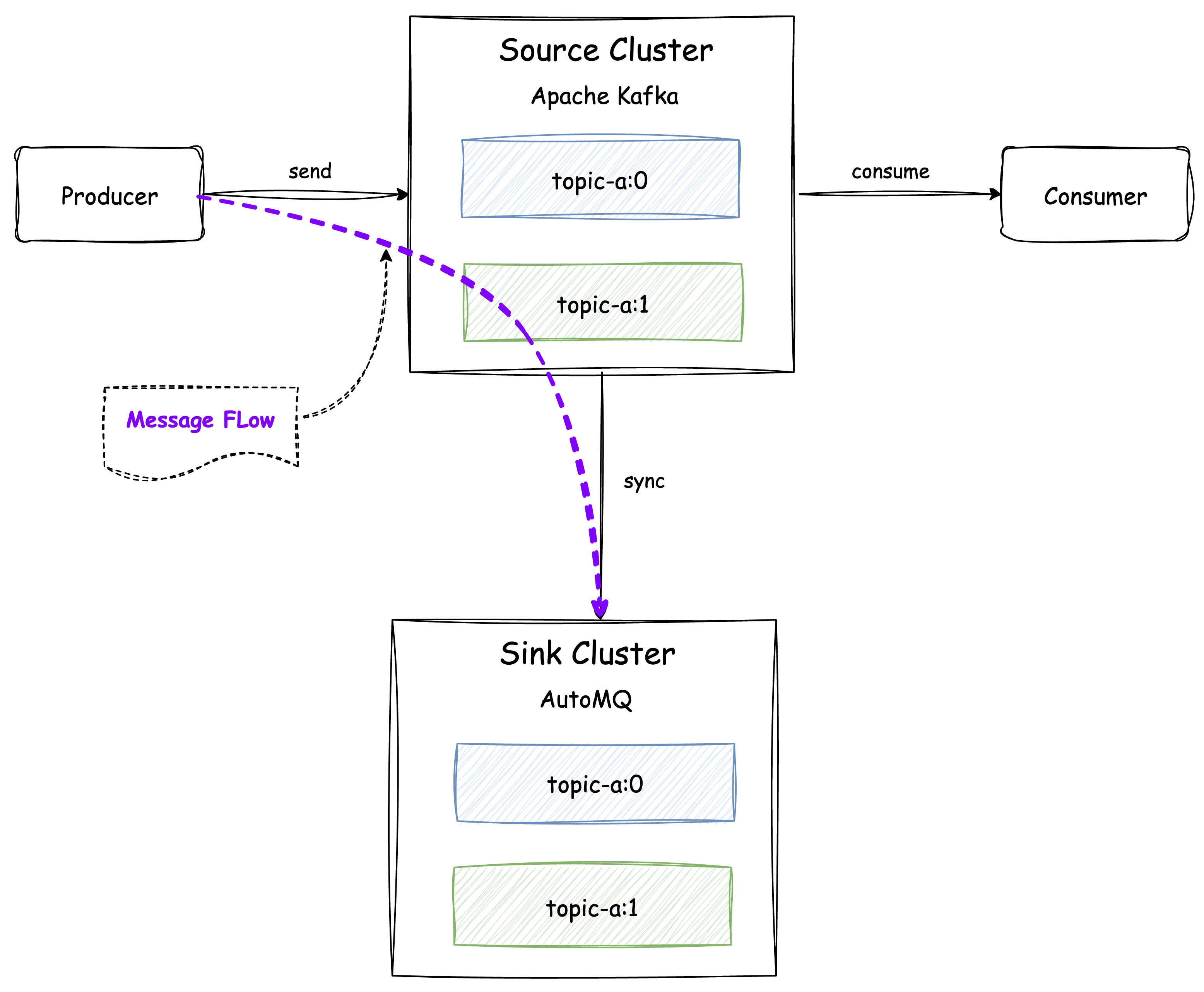
Create Mirror Consumer Group
For all consumer groups that require migration, create corresponding mirror consumer groups in the AutoMQ cluster. This step is a preparatory measure for synchronizing consumer offsets later, and no offset synchronization is performed at this stage.
Migrate Producers
After completing the resource creation, proceed directly with the migration of the Producer. Since AutoMQ Kafka Linking has message forwarding capabilities, users can simply direct the Producer to the AutoMQ cluster through a single round of rolling updates. At this point, all messages sent to the AutoMQ cluster will be directly forwarded back to the source cluster. This ensures uninterrupted message transmission, allowing the source cluster's Consumers to continuously consume the latest messages.
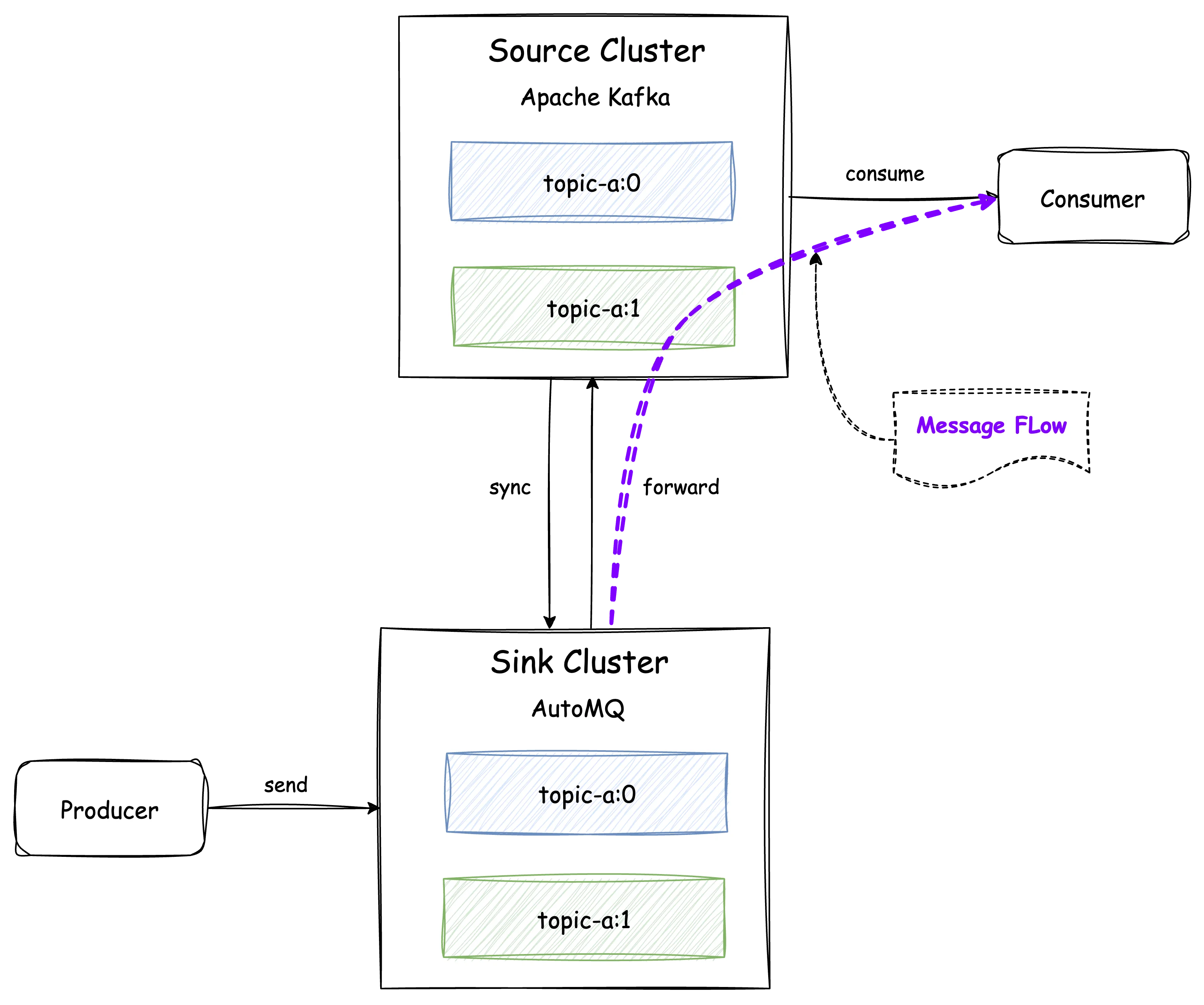
Migrate Consumers
Similar to the producer migration, users only need to perform a rolling update to point the Consumer to the AutoMQ cluster. It is essential to note that to avoid overlapping consumption offsets, which could cause duplicate consumption during the migration process—when the same Consumer Group consumes from both the source and AutoMQ clusters—AutoMQ will disable reading for Consumers connected to the AutoMQ cluster. Once the Consumer migration is complete and all Consumers are directed to AutoMQ, a Promote of the Consumer Group is required. Promoting a Consumer Group indicates that the user has confirmed all Consumers from the source cluster are offline (Note: When using the AutoMQ Console UI for migration, AutoMQ can automatically detect source cluster Consumers and perform Group Promotion without manual intervention from the user). At this stage, the AutoMQ cluster will synchronize the consumer offset of that Consumer Group from the source cluster and enable reading. Consumers pointing to the AutoMQ cluster can then continue to consume using the source cluster's offset.
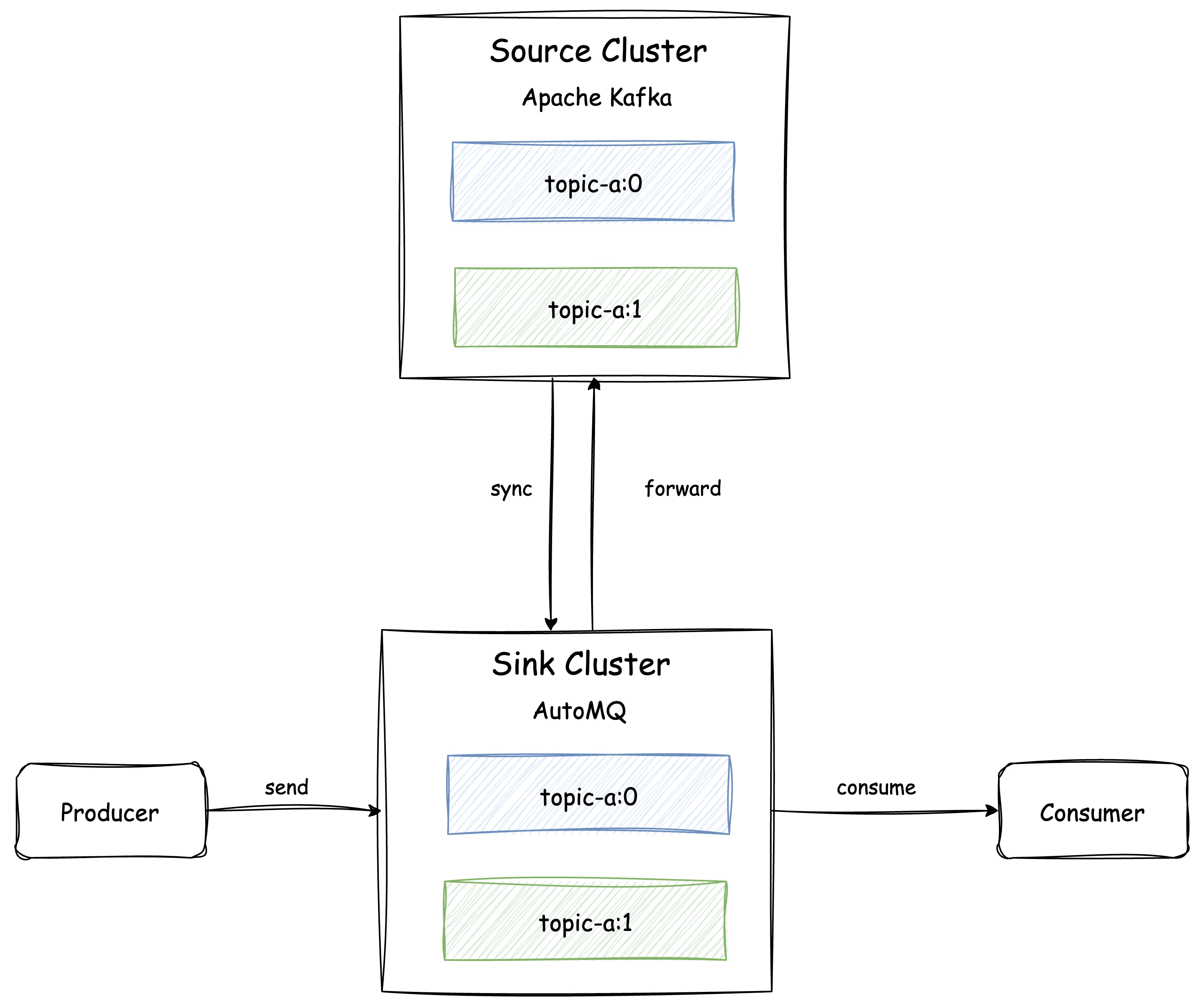
Promote Topic
Once both Producers and Consumers have completed the migration, users can manually Promote the Topic to disconnect the link between the source cluster and the AutoMQ cluster. After the promotion, no new messages will be forwarded back to the source cluster, and the AutoMQ cluster will no longer synchronize messages from the source cluster.
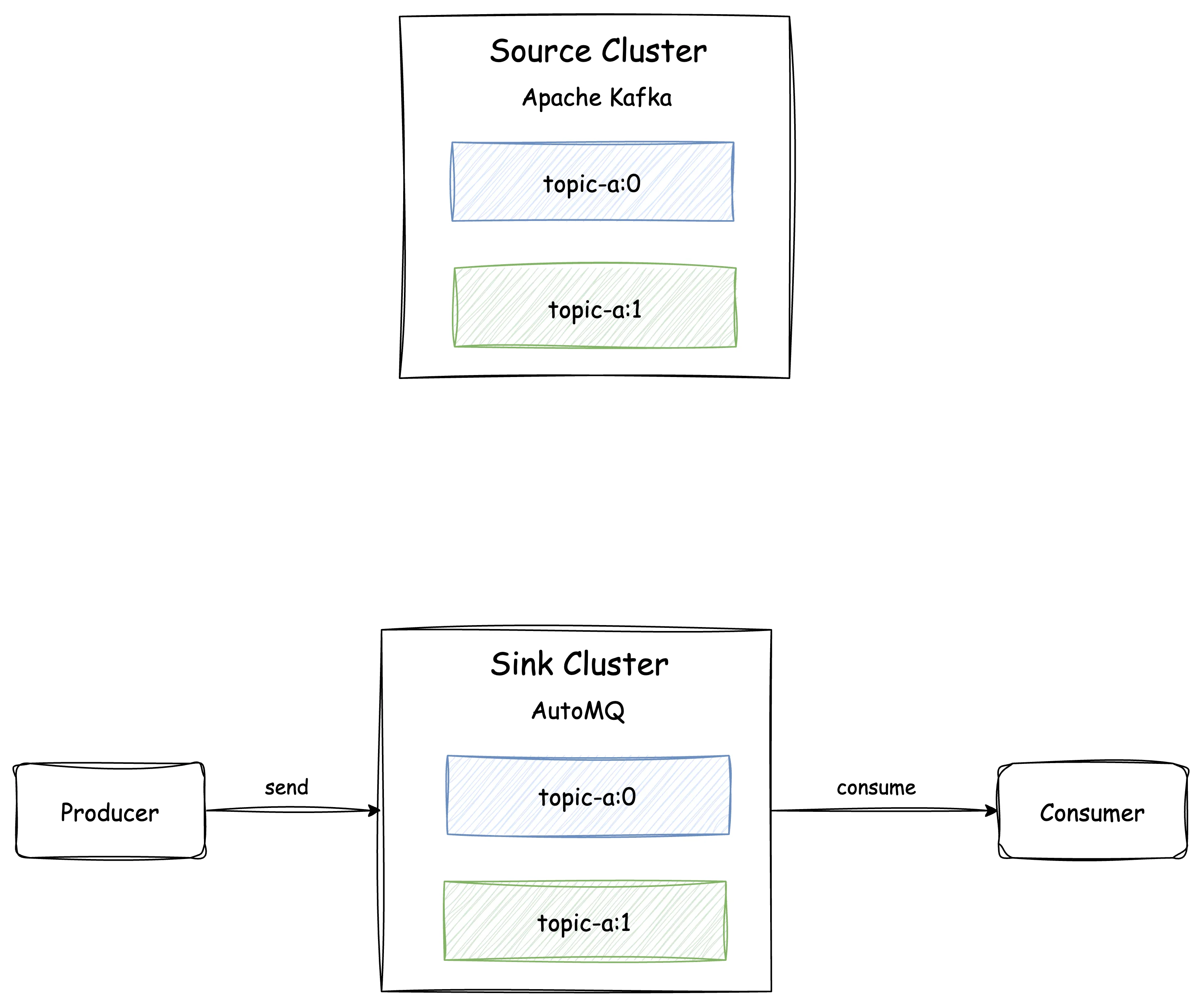
At this point, the migration of "topic-a" from the source cluster to the AutoMQ cluster is complete. For other Topics in the source cluster, the above steps can be repeated to complete the migration in batches.
Things Behind Kafka Linking
This section will introduce the technical details behind Kafka Linking, following the lifecycle of a mirror topic from the creation to promotion.
Mirror Topic Awareness and Pre-processing
Just like the Apache Kafka ReplicaFetcherManager, which handles data replication, Kafka Linking monitors changes in the Metadata Image. Upon detecting a partition leader change, the partition is placed into the pre-processing queue. The Kafka Linking Manager then asynchronously takes the partition from the queue to conduct the following pre-processing:
-
Filter the partitions by examining partition metadata to identify which ones need synchronization.
-
Obtain the Kafka Link ID for partition ownership and index it to the configuration information of the source cluster corresponding to Kafka Link.
-
Establish a connection with the source cluster using the source cluster configuration to retrieve the source cluster's metadata.
-
Utilize the source cluster metadata to determine the distribution of the leader and replicas for the partition within the source cluster.
-
Select the target node for data synchronization connections based on the Rack-aware priority principle, choosing the leader as the target node for forwarding data.
-
Route the partition to various Fetchers and Routers based on the partition, the chosen target node, and concurrency limits.
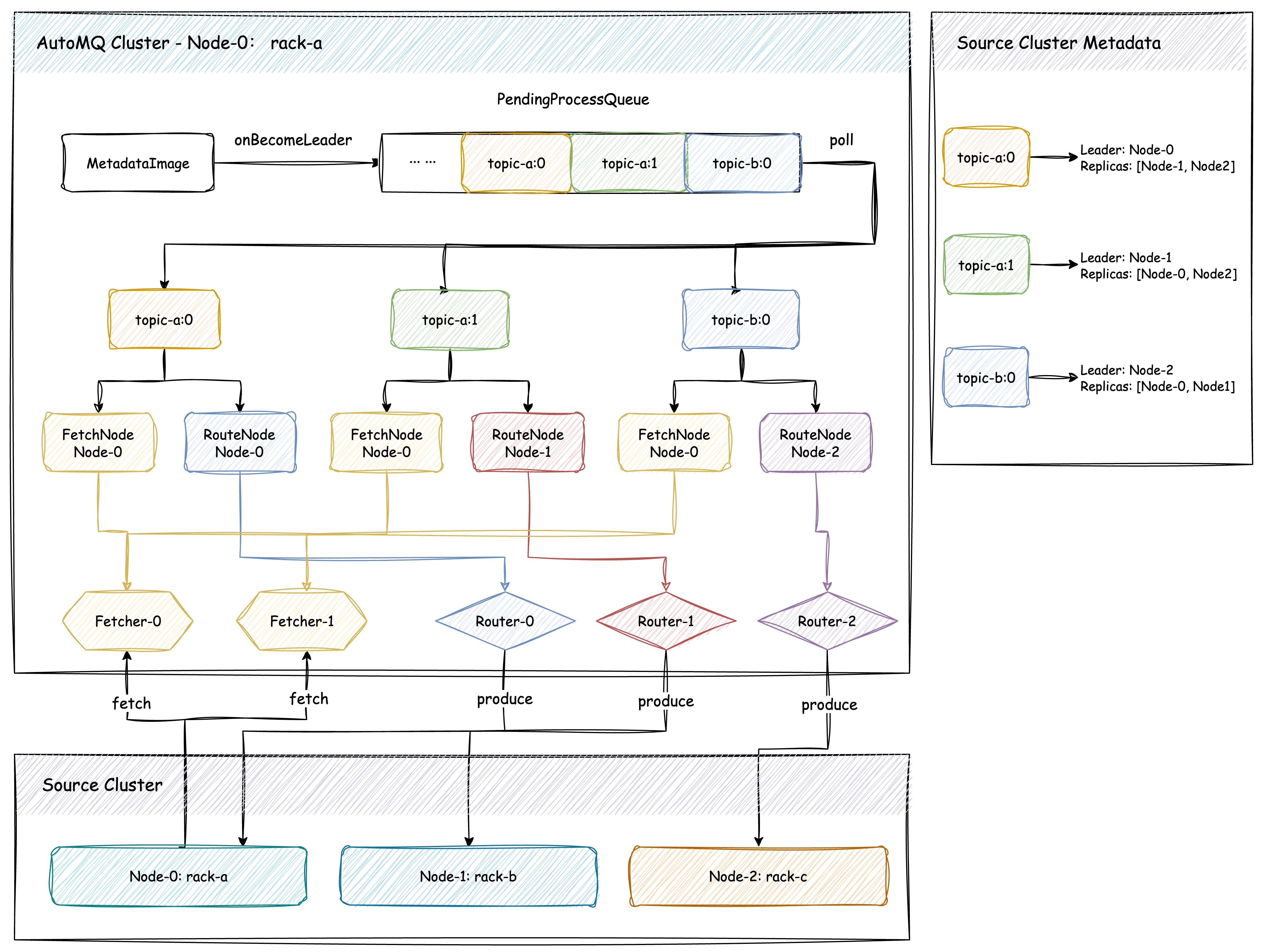
In the illustration above, three partitions (topic-a:0, topic-a:1, topic-b:0) are assigned to Node-0 in the AutoMQ cluster, while in the source cluster, these partitions are spread across three different nodes. As per the preprocessing flow described, partitions first select nodes within the same Rack as data synchronization nodes and choose the node where the leader resides as the data forwarding node. In the diagram, the Fetcher pulls data from the data synchronization node and writes it locally, whereas the Router sends the received messages to the data forwarding node. In the illustration, all three partitions select Node-0, located in the same Rack, as the synchronization node. Meanwhile, based on the concurrency configuration (assuming synchronization concurrency is 2), they are routed to two Fetchers. Since the forwarding nodes are different, they are sent to three different routers.
Data Synchronization
As noted in the previous subsection, each partition is eventually directed to a unique Fetcher. The Fetcher's data synchronization process is as follows:
-
Determine the start offset: When a new partition has been added to a Fetcher, the initial fetch offset of the partition will be calculated based on partition metadata:
-
If the partition is created for the first time, obtain the partition offset from the source cluster based on the partition starting offset time configuration (options include: latest, earliest, or determined by timestamp).
-
If the partition isn't created for the first time, use the log end offset of the partition as the starting fetch offset.
-
-
Partition offset correction: If the partition is created for the first time, truncate the partition based on the starting fetech offset.
-
Request construction: Similar to the Apache Kafka consumer, the Fetcher also constructs incremental fetch requests via FetchSessionHandler to minimize redundant network traffic.
-
Response Handling: After the Fetcher receives a request response, it processes it based on the type of response error:
-
partition error exists: Depending on the specific error type, it may update the partition metadata, remove the partition, reassign the Fetcher, or apply backoff and retry.
-
No partition error: After making necessary metadata corrections to the response data, it appends the data to local storage.
-
-
Status Update: Once a response for a fetch request is processed, the Fetcher updates the next fetch offset for each partition based on the append result and then repeats steps 3 to 5 to ensure continuous data synchronization.
Data Forwarding
Each partition is assigned to a unique Router. All produce requests that the partition receives are directed to the Router for rebatching and forwarding. The main process of message forwarding includes the following steps:
-
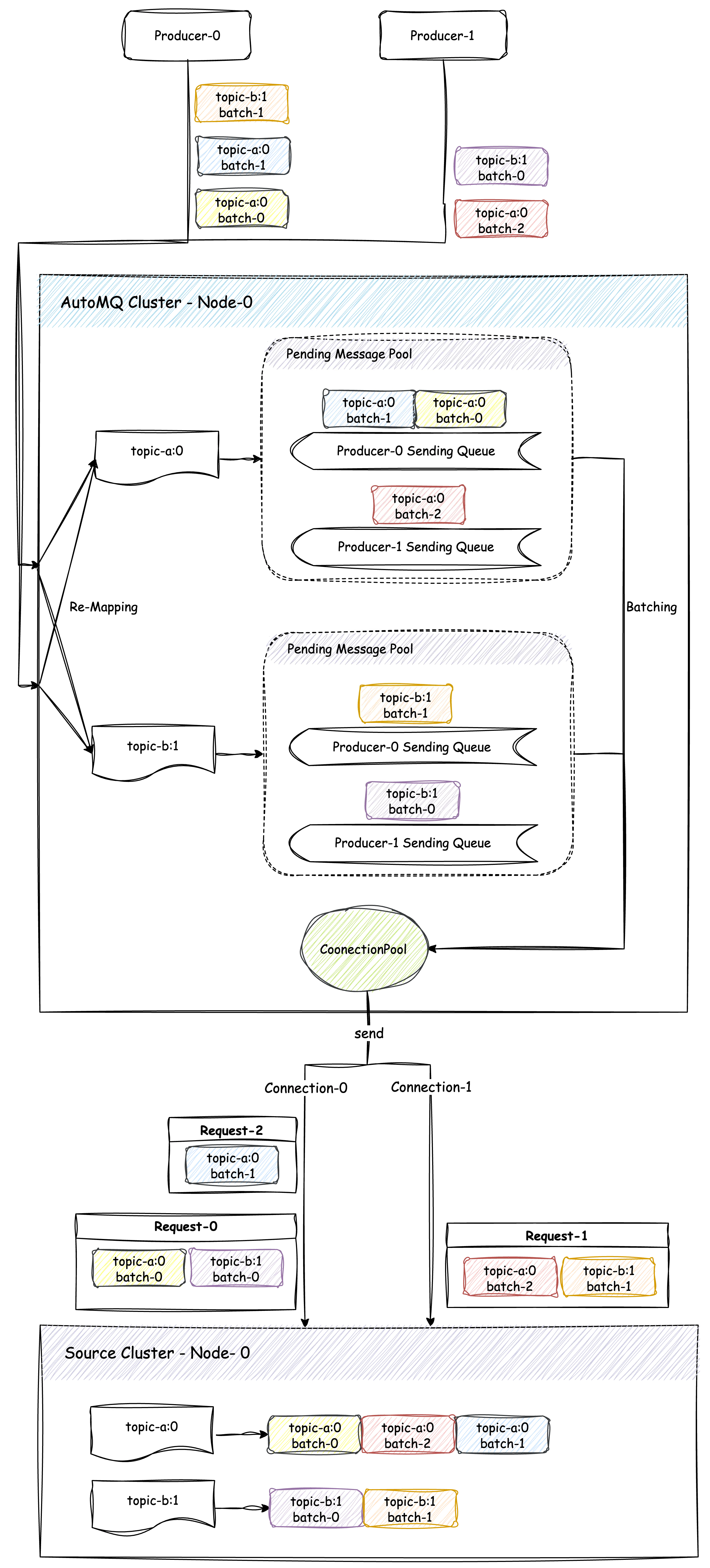
Message Remapping: All messages routed to the Router are remapped to an in-memory message map. The key is topic-partition, and the value is an message pool containing all messages pending dispatch for that partition. Within the message pool, messages are further grouped by their source producer to ensure they are sent in FIFO order from the same producer.
-
Request Aggregation: Since the messages received by the Router have already been aggregated into batches by the producer, the Router does not re-aggregate batches for the same partition. Instead, when constructing each send request, it selects a single batch from each partition's message pool to include in the send request.
-
Request Sending: When the Router completes constructing a sending request, it selects an appropriate client from the connection pool for asynchronous dispatch and immediately begins constructing the next sending request. This is how requests can be sent concurrently.
-
Response Handling: Once a request successfully receives the response, the Router places the sending queue of the producer corresponding to the partition into the message pool. This allows the remaining messages from that producer to be dispatched in the next request.
As illustrated below, there are two producers, Producer-0 and Producer-1, each sends message from batch-0 to batch-2 and batch-0 to batch-1 to partitions topic-a:0 and topic-b:1, respectively. After being reaggregated by the Router, these 5 messages are consolidated into 3 sending requests. Messages from Producer-0 are sent strictly in order to ensure sequence, while messages from different Producers are sent concurrently to increase forwarding throughput.
Topic Promote
Topic promotion is the final step of cluster migration. When topic promotion is triggered, AutoMQ is prepared to stop synchronization and forwarding with the source cluster. The main process is as follows:
-
When Fetcher constructs a fetch request, it iterates through all partitions to be fetched and marks the request as Full-Fetch upon discovering partitions flagged with promote status (i.e., forcefully returning results for all requested partitions in the response, even if the results are empty).
-
After the Fetcher receives the response, it determines whether the offset lag of the promoted partition is sufficiently small:
-
Insufficiently small lag: This indicates that data is still catching up, and the Fetcher will continue to synchronize data from source cluster.
-
Sufficiently small lag: This triggers the fence operation on the Router where the partition is assigned. The Router halts the forwarding of subsequent produce requests for the partition, preventing the source cluster partition from continuing to receive new messages. It then waits for all in-flight forwarding requests to be fully responded to before marking the partition state. At this point, it can be confirmed that the corresponding partition in the source cluster has no new messages in transit.
-
-
When the next fetch request is constructed, it is marked as a Full-Fetch again. When the offset lag is 0, it signifies that all data in the partition has been fully synchronized. At this point, the partition is marked as "Promote Complete", and it is removed from both the Fetcher and Router. Subsequent new messages are written directly into the local AutoMQ cluster.
The state machine transitions of a partition in the Fetcher are as follows:

Conclusion
This article has introduced how to use AutoMQ Kafka Linking for cluster migration, as well as the technical details behind Kafka Linking. Kafka Linking not only facilitates efficient cluster migration with zero-downtime, but in the future, AutoMQ will continue to iterate on it to support enterprise capabilities like disaster recovery, active-active setups, and cross-cluster data sharing based on Kafka Linking.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


