Introduction
In the landscape of the modern data stack, open-source tools have become first-class citizens, empowering engineering teams to build powerful, customized data platforms. A foundational challenge in any such platform is capturing and moving data in real time. For teams committed to an open-source path, two names frequently emerge for this task: Debezium and Airbyte.
At first glance, they seem to solve a similar problem. Both can capture changes from a production database and replicate them elsewhere. However, this superficial similarity masks a fundamental difference in philosophy, architecture, and purpose. Choosing between them is not about picking the "better" tool; it's about understanding a critical architectural trade-off: do you need a specialized, low-level Change Data Capture (CDC) engine, or a high-level, end-to-end data integration platform?
This blog post provides a deep, technical comparison from an engineer's perspective to help you make an informed decision between these two exceptional open-source projects.
Understanding Debezium: The CDC Specialist
Debezium is a distributed platform whose primary and sole function is to be an exceptionally reliable and detailed Change Data Capture engine . It is not a complete, standalone application but rather a powerful component designed to be embedded within a larger data streaming architecture. Its job is to tail the transaction logs of source databases, produce a highly detailed stream of all row-level changes (inserts, updates, and deletes), and publish these change events to a message broker.
Core Architecture and Operation
To understand Debezium, you must first understand its relationship with Apache Kafka and the Kafka Connect framework. Debezium is implemented as a set of source connectors for Kafka Connect, a tool for scalably and reliably streaming data between Apache Kafka and other systems . The workflow is as follows:
-
Capture: A Debezium connector for a specific database (e.g.,
connector-for-postgresql) is deployed to a Kafka Connect cluster. It establishes a connection to the source database and begins reading its write-ahead log (WAL) or transaction log from a specific position. -
Event Generation: For every committed row-level change it observes, Debezium generates a structured change event message. This message is rich with metadata, including the before and after state of the row, the source table and database, the operation type (
cfor create/insert,ufor update,dfor delete), and the log position. -
Publishing: The event is serialized (typically as JSON or Avro) and published to a dedicated Kafka topic. By convention, topics are often named after the source system, schema, and table, providing a logical organization for the change streams.
The key takeaway is that Debezium's job ends once the event is securely published to Kafka. It does not concern itself with where the data goes from there; that is the responsibility of downstream consumers.
![the Architecture of a Change Data Capture Pipeline Based on Debezium [5]](/blog/debezium-vs-airbyte-open-source-data-integration/1.webp)
Key Strengths
-
Low-Latency Streaming: By reading directly from transaction logs, Debezium captures changes as they are committed, enabling true sub-second, real-time streaming.
-
Detailed and Reliable Events: Debezium provides a comprehensive, structured view of every change, guaranteeing that you never miss a deletion or an intermediate update. This makes it ideal for building audit logs and other applications that require high-fidelity data.
-
Decoupled Architecture: By publishing to a message broker like Kafka, Debezium decouples the source database from the consumers of the data, allowing multiple applications to react to the same change events independently.
Understanding Airbyte: The Full-Stack Integrator
Airbyte is a broad, open-source data integration platform designed to automate the movement of data from nearly any source to any destination . Its goal is to commoditize data integration by providing a massive library of pre-built connectors and a simple, UI-driven experience to manage Extract, Load, and Transform (ELT) pipelines.
While Airbyte can connect to hundreds of SaaS APIs, files, and other sources, it uses CDC for its database sources to enable efficient, incremental replication. Critically, for many of its most popular database connectors, Airbyte leverages Debezium internally to power its CDC capabilities, abstracting away the complexity of managing it directly.
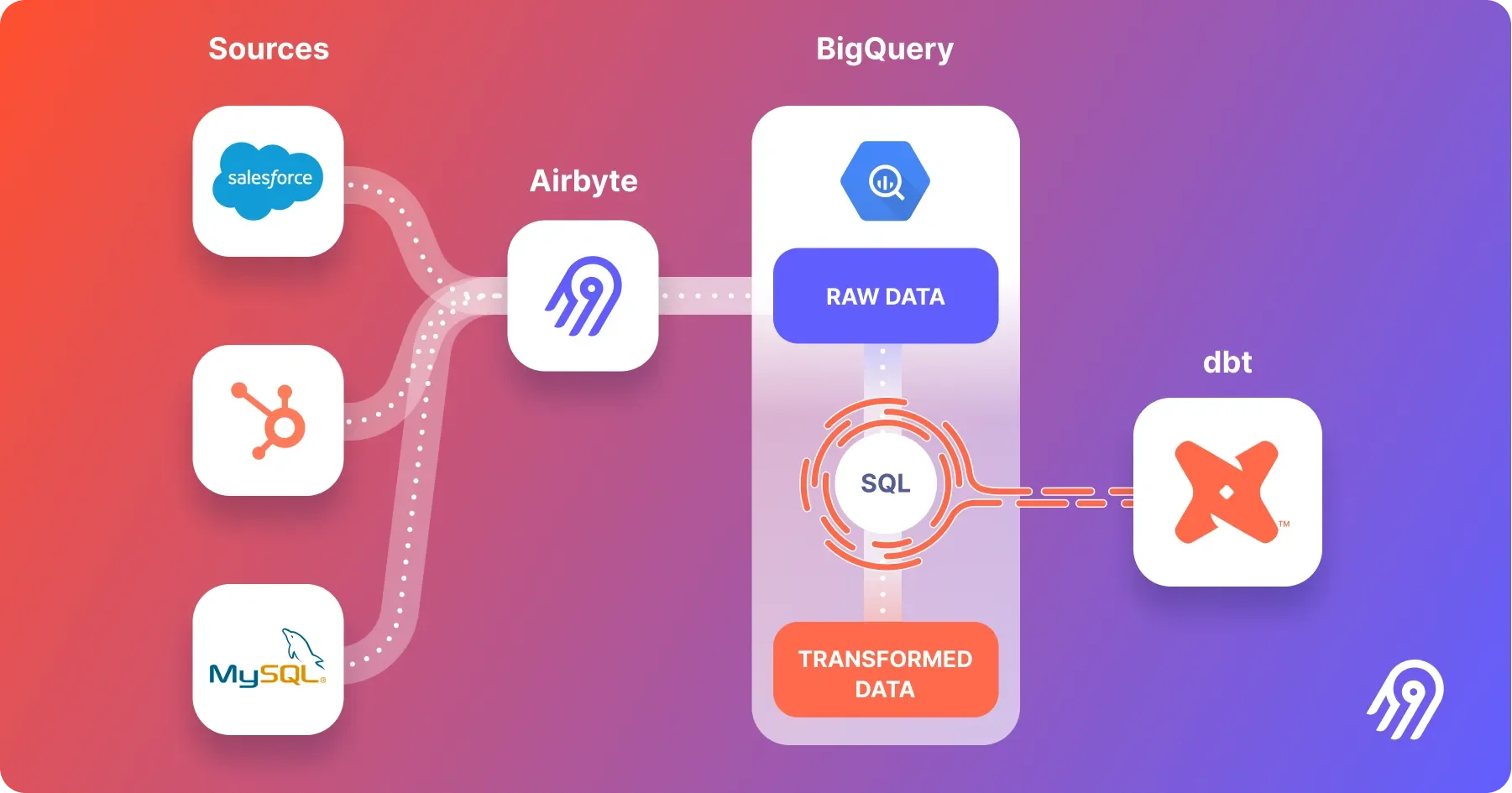
Core Architecture and Operation
Airbyte's architecture is built around the concept of source and destination connectors running in Docker containers. The platform manages the entire pipeline lifecycle:
-
Connection Setup: A user selects a source (e.g., a Postgres database) and a destination (e.g., Snowflake) from the Airbyte UI and provides the necessary credentials.
-
Sync Execution: Airbyte schedules and runs a "sync." For a CDC-enabled source, the underlying source connector will read changes from the database's transaction log.
-
Batching and Loading: Unlike Debezium, which streams individual events, Airbyte operates on a micro-batch basis. It periodically checks for new changes, collects them into a batch, and loads them into a raw table in the destination warehouse. This cycle typically runs every one to five minutes.
-
Normalization (Transformation): After loading the raw data, Airbyte can optionally trigger a dbt Core project to transform and normalize the data into clean, queryable production tables (the "T" in ELT).
Airbyte's primary function is to ensure that a table in a destination system is a reliable replica of a table in a source system, handling the entire end-to-end process.
Key Strengths
-
Massive Connector Library: With over 350 connectors and growing, Airbyte can connect to a vast array of sources and destinations, far beyond just databases .
-
Ease of Use: It can be deployed with a single command and managed through a clean UI, making it accessible to a much broader audience than just distributed systems experts.
-
End-to-End Automation: It manages scheduling, state, error handling, and basic transformations, providing a complete out-of-the-box solution for data movement.
Head-to-Head Comparison: A Feature-by-Feature Analysis
Understanding their core philosophies reveals that Debezium and Airbyte are designed for different jobs.
Functionality & Scope
-
Debezium is a specialized component. Its scope is narrowly and expertly focused on CDC. It is designed to be one part of a larger, composable architecture. You choose Debezium when you need the event stream itself as the final product to feed other applications.
- Typical Use Cases: Building event-driven microservices, real-time cache invalidation, creating detailed audit logs, and feeding streaming analytics engines.
-
Airbyte is a complete platform. Its scope is the entire data pipeline. It uses CDC as a means to an end: getting data loaded into a destination for analytics. You choose Airbyte when you need a replica of your source data in a target system.
- Typical Use Cases: Replicating production databases to a data warehouse (e.g., Postgres to BigQuery), consolidating data from multiple SaaS applications for business intelligence, and automating ELT workflows.
Technical Stack and Operational Overhead
-
Debezium has a high operational overhead. To run Debezium in production, you must deploy, manage, and monitor a distributed Java ecosystem: Apache Kafka, Kafka Connect, and a schema registry. This requires significant engineering expertise in distributed systems and JVM tuning.
-
Airbyte has a low operational overhead. The open-source version is packaged to run via a single
docker-composecommand. It abstracts away the complexity of its internal components. While you are responsible for the host machine, you do not need to be a Kafka expert to use it. Its cloud offering removes operational overhead entirely.
Latency and Data Model
-
Debezium is true real-time streaming. Events are captured and published to Kafka as they are committed to the source database, enabling sub-second latencies. Its data model is an immutable log of individual change events.
-
Airbyte is near real-time batch. Even when using CDC, it polls for changes on a schedule (e.g., every minute). It collects all changes from that interval into a batch and loads them together. This is perfectly acceptable for analytics but is not suitable for applications that require instantaneous event processing. Its data model is a mutable, replicated table in a destination.
Transformation
-
Debezium does not perform transformations. It delivers the raw, unaltered change event. The responsibility for transforming, filtering, or enriching the data lies with downstream consumer applications, which can be built using tools like Apache Flink, Spark Streaming, or any custom code that can read from a message broker.
-
Airbyte integrates transformations. It is designed to work seamlessly with dbt Core, the de facto standard for in-warehouse transformation. Airbyte handles the "EL" and then passes control to dbt for the "T," creating a clean, end-to-end ELT workflow.
How to Choose: A Practical Decision Framework
The choice between Debezium and Airbyte becomes clear when you define your primary goal.
You should choose Debezium if:
-
Your destination is an application, not a data warehouse. You need to programmatically react to individual data changes.
-
You are building an event-driven or streaming architecture. Debezium provides the foundational event stream to power these systems.
-
Sub-second latency is a hard requirement. Your use case cannot tolerate waiting minutes for a batch of updates.
-
You need a high-fidelity audit trail of every single change. The detailed event payload from Debezium is perfect for this.
-
You already have a mature Kafka ecosystem and the in-house expertise to manage it.
You should choose Airbyte if:
-
Your destination is a data warehouse, data lake, or database. Your goal is to run analytics or have a replicated dataset available for querying.
-
You want a simple, fast, and automated setup. You prefer a UI-driven experience over configuring distributed system components.
-
You need to connect to a wide variety of sources, including SaaS applications and files, not just databases.
-
A data freshness of a few minutes is acceptable for your needs. Batch updates are sufficient for your BI dashboards and analytical queries.
-
You want to standardize on a single platform for all your ELT data movement, not just database replication.
It is also important to note that these tools are not mutually exclusive. A large organization might use Airbyte as its standard platform for moving data into its central data warehouse, while a separate product team uses a dedicated Debezium and Kafka stack to power a real-time feature in their customer-facing application.
Conclusion
Debezium and Airbyte are both titans of the open-source data world, but they operate on different planes of the data engineering stack.
Debezium is a low-level, specialized engine. It is a tool for developers building bespoke, real-time streaming systems. It offers unparalleled power, detail, and low latency, but it demands significant engineering investment to operate.
Airbyte is a high-level, all-in-one platform. It is a tool for data engineers and analysts tasked with populating data warehouses and lakes. It offers tremendous breadth, simplicity, and end-to-end automation, making data integration accessible to everyone.
The right choice depends on whether your project's goal is to consume a stream of events or to replicate a table of data. By answering that one question, you will find a clear path to the open-source tool that is perfectly engineered for your job.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


