TL;DR
Diskless Kafka is an evolution of Apache Kafka's architecture that decouples the compute layer (brokers) from the storage layer. It replaces the brokers' local disks with a shared, elastic cloud object storage like Amazon S3, fundamentally changing the platform's cost and scalability profile.
-
Massive Cost Reduction: It slashes storage costs by over 90% and nearly eliminates the expensive cross-zone network fees that plague traditional Kafka deployments.
-
True Cloud Elasticity: Brokers become stateless, allowing them to be scaled up or down almost instantly without slow data rebalancing, which enables the use of heavily discounted Spot Instances.
This blog detailed the architecture and core benefits of diskless Kafka, from cost savings to elasticity, and how AutoMQ leverages this modern design to deliver a 100% compatible, cloud-native Kafka solution that achieves dramatic cost savings and true elasticity.
What Is Diskless Kafka?
Diskless Kafka is an architectural pattern that represents a significant evolution for data streaming platforms. In a traditional Kafka setup, data is tightly coupled with the broker, stored and replicated on local disks. A diskless architecture, by contrast, decouples data storage from the brokers by offloading it to a remote, durable object storage, such as those offered by cloud providers. This means brokers no longer need to maintain a full copy of data on their own disks. While proposals like KIP-1150 aim to bring this capability to the official Apache Kafka project, the concept itself is not new and has been a key feature in other Kafka-alternative platforms for some time, driven by the need for greater efficiency in modern cloud environments.
Why It Has Become More Important?
The importance of the diskless architecture has surged as it directly solves the primary cost and scalability challenges of running Kafka in the cloud. It dramatically reduces expenses by replacing costly local disks with economical object storage, a change that also eliminates steep cross-zone data replication fees. This design unlocks further efficiencies like rapid broker scaling and the use of cheaper compute options like Spot Instances. The significance of this shift is highlighted by a clear industry trend; Kafka alternatives like AutoMQ successfully pioneered this cloud-native model long before the official Apache Kafka project considered it, proving its viability and pushing the entire ecosystem towards a more flexible and cost-effective future.
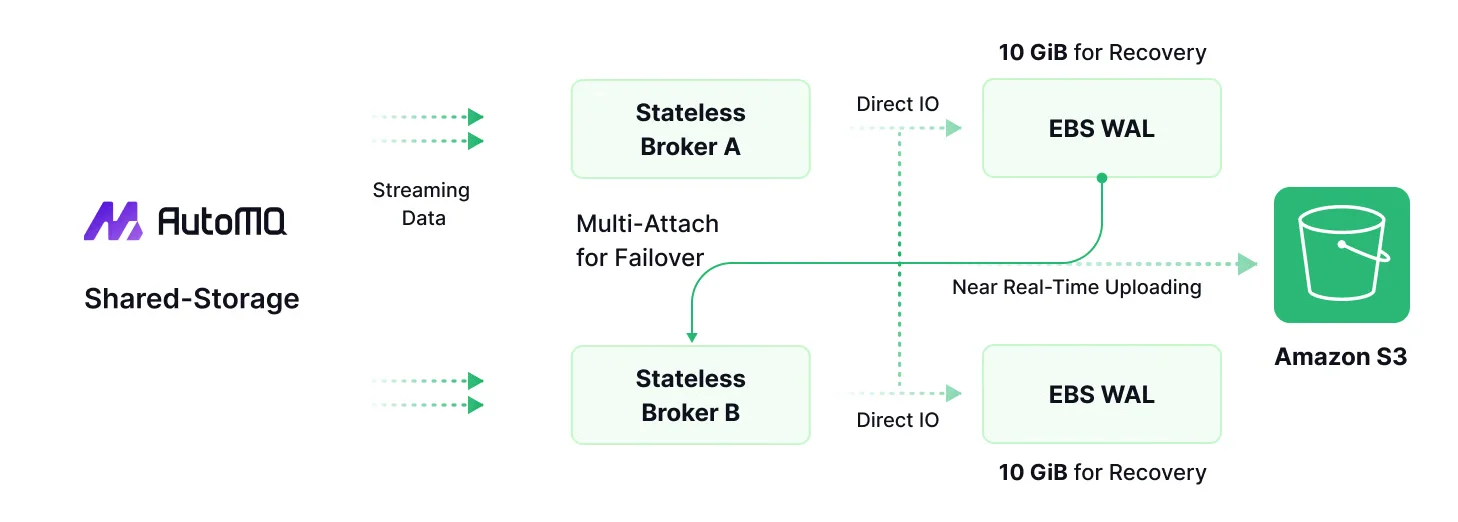
Drastic Reduction in Cross-Zone Costs
The High Cost of Data Replication in Traditional Kafka
A key financial and architectural advantage of a diskless Kafka architecture is the drastic reduction in cross-availability zone (cross-AZ) data transfer costs. Traditional Kafka deployments require brokers in multiple AZs for high availability, leading to significant networking expenses on major cloud platforms.
These high costs stem from Kafka's core replication design. For data durability, every piece of data written to a partition leader is replicated to follower brokers. In a typical high-availability setup with a replication factor of three, this creates multiple cross-zone transfers. First, a producer in one AZ might send data to a leader broker in another. Second, that leader replicates the data to two follower brokers located in different AZs. This replication traffic is the primary cost driver, generating at least 2 GB of cross-zone traffic for every 1 GB of data produced, often accounting for up to 80% of a Kafka cluster's total operational cost.
How Diskless Architecture Eliminates Costs
A diskless architecture, like that used by AutoMQ, nearly eliminates these cross-zone costs by re-architecting data persistence and routing. This is accomplished in two ways:
-
Data replication is offloaded to a cloud-native object storage such as Amazon S3. Instead of brokers replicating data across AZs, a broker writes each message once to the shared, inherently multi-AZ object storage. This removes the expensive broker-to-broker replication traffic, which is the largest contributor to cross-zone costs.
-
Producer traffic is localized to prevent it from crossing AZ boundaries. In AutoMQ's zone-aware architecture, a producer always communicates with a broker within its own availability zone. This local broker writes the data directly to the object storage and sends only a small metadata message via an RPC call to the partition's leader, which may be in another AZ. This "write-proxy" approach ensures the large data payload does not traverse costly cross-AZ network links.
Together, these mechanisms transform a major operational expense into a negligible one, making highly available streaming data pipelines significantly more cost-effective in the cloud.

Lower and More Elastic Storage Costs
Diskless architecture fundamentally changes the storage economics of running Apache Kafka, moving from expensive, fixed-capacity block storage to highly elastic and cost-effective cloud object storage. This shift addresses one of the most significant cost drivers in large-scale Kafka deployments, especially those requiring long-term data retention.
The Advantages of Object Storage Over Block Storage
The advantages of using cloud object storage, like Amazon S3, over traditional block storage (e.g., Amazon EBS) are threefold:
-
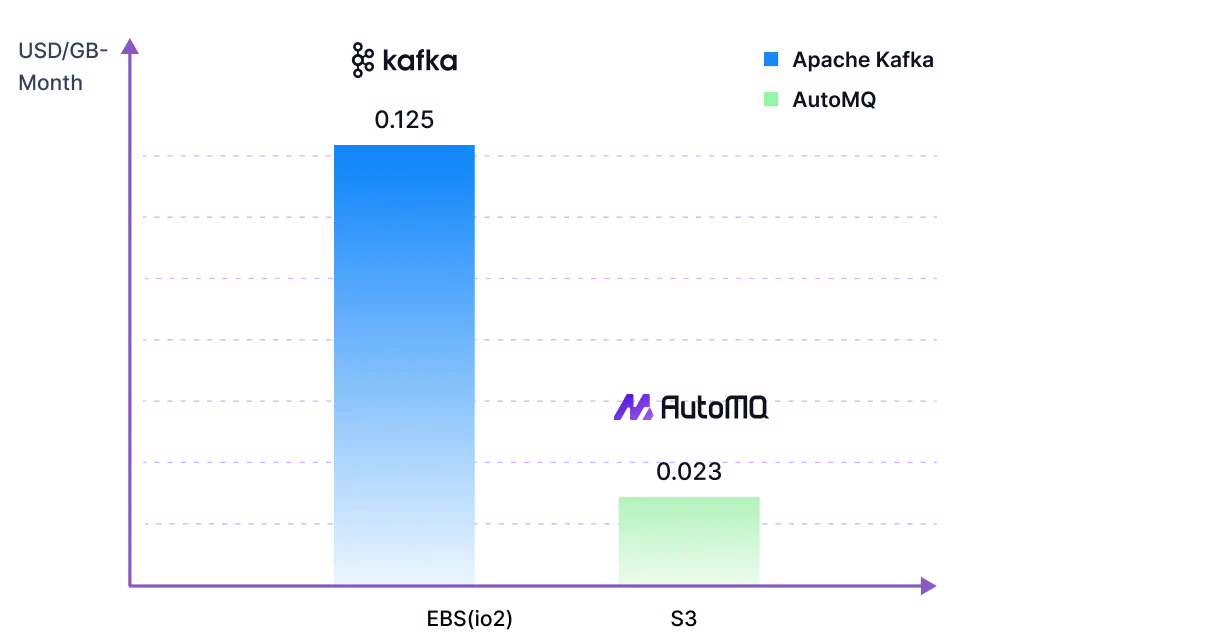
Object storage is significantly cheaper than the high-performance block storage volumes required to run a traditional Kafka broker. For example, the price of AWS S3 Standard is roughly 67% less than that of a standard EBS gp3 volume, making it vastly more economical for storing large datasets.
-
Object storage offers virtually unlimited capacity and you only pay for the storage you actually use. This eliminates the need for complex capacity planning and costly over-provisioning. In a traditional Kafka setup, administrators must provision block storage volumes for peak data retention, meaning they continuously pay for allocated but unused disk space.
-
Leading object storage services are designed for extreme durability (often "11 nines") and automatically replicate data across multiple Availability Zones by default. Achieving similar multi-AZ resilience with block storage would require manually provisioning multiple volumes and managing the costly data replication between them.
AutoMQ's Hybrid Implementation and Cost Impact
By leveraging these benefits, a diskless architecture can drastically reduce storage costs. AutoMQ, for example, implements this by using a small, fixed-size EBS volume as a high-performance write buffer, while offloading all historical topic data to Amazon S3. This hybrid approach delivers low-latency writes while capitalizing on the superior economics of object storage for the vast majority of the data. The impact is substantial; for a scenario involving 10 TiB of data, a traditional 3-replica Kafka cluster using EBS can be over 11 times more expensive in terms of pure storage costs compared to AutoMQ's S3-based model. This architectural shift not only cuts costs but also makes retaining data in Kafka for months or even years economically feasible, something that is often prohibitively expensive with a traditional block storage-based deployment.
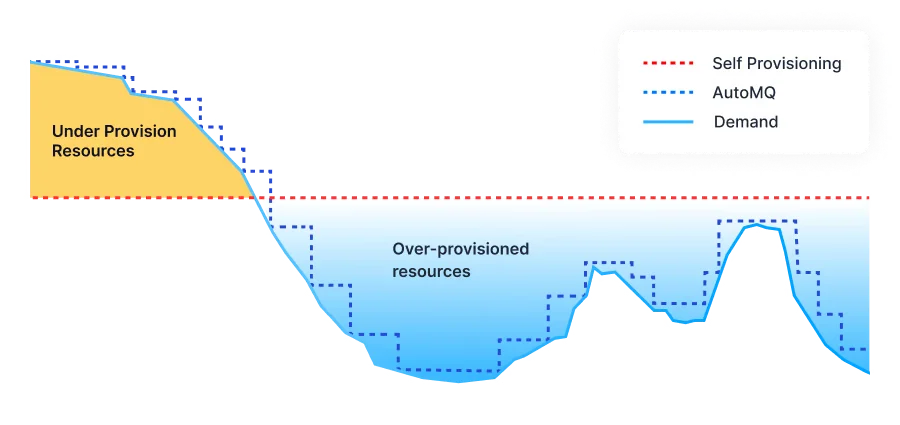
True and Rapid Elasticity
One of the most transformative benefits of a diskless architecture is the introduction of true, rapid elasticity for the broker fleet. This refers to the ability to quickly and efficiently scale the cluster's compute resources up or down in response to workload changes, a task that is notoriously slow, costly, and disruptive in traditional Kafka deployments.
The Scaling Challenge with Stateful Brokers
In a conventional Kafka cluster, brokers are "stateful" because compute and storage are tightly coupled. When a new broker is added to the cluster, a massive and lengthy data rebalancing process must begin. The new broker needs to copy huge volumes of partition data from existing brokers, a process that consumes immense network bandwidth (incurring high cross-zone transfer costs), places a heavy I/O load on the cluster, and can take hours or even days to complete. This inherent friction makes it impractical to scale traditional Kafka clusters dynamically in response to fluctuating demand.
Stateless Brokers: The Elasticity Solution
A diskless architecture fundamentally solves this by decoupling compute (brokers) from storage (the object storage). With data residing in a shared object storage, brokers become largely stateless. This architectural shift enables:
-
New brokers can be added to the cluster and become operational almost instantly. Because they do not store data locally, there is no need for any replica synchronization or data rebalancing. A new broker can immediately start processing streams and serving traffic, as all historical data is readily accessible in the central object storage.
-
Removing a broker is just as simple. It can be terminated without any risk of data loss or a complex data migration process, as all persisted data is already safe and durable in the object storage. This allows operators to confidently reduce cluster resources during quiet periods to save costs.
Furthermore, by transforming brokers into stateless processing units, this architecture unlocks powerful cloud-native capabilities. For instance, as demonstrated by AutoMQ, this design makes it feasible to run the broker fleet on cost-effective AWS Spot Instances. These instances offer steep discounts but can be terminated with little warning. In a diskless model, the preemption of a Spot Instance is not a critical failure; an auto-scaling group can launch a replacement broker that is ready to serve traffic almost immediately, providing a resilient and highly cost-efficient compute layer that is simply not viable with a stateful, traditional Kafka architecture.
Seamless Upgrade and Ecosystem Compatibility
A critical concern for any organization considering a new technology is the migration path and its impact on the existing ecosystem. A key advantage of modern diskless Kafka solutions is that they are engineered for a non-disruptive upgrade, preserving years of investment in existing applications, data pipelines, and connector configurations.
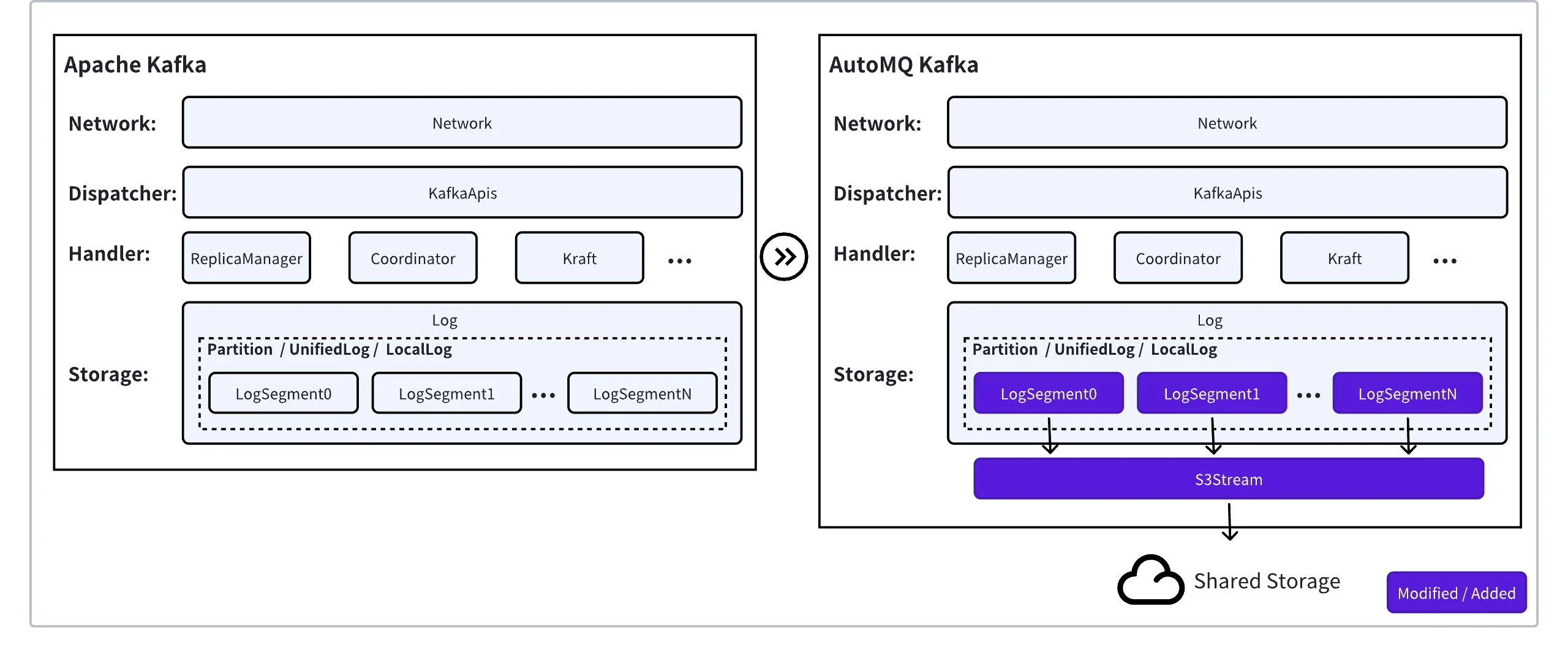
The reason a seamless transition is possible is that these architectures fundamentally re-engineer the internal storage layer while leaving the public-facing computational and protocol layers untouched. The Kafka wire protocol is the API that producers and consumers use to communicate with the brokers. Since diskless solutions don't alter this protocol, all existing applications, services, and integrated tools (like Spark, Flink, and various Kafka connectors) continue to function without modification. From the client's perspective, it is still communicating with a standard Kafka cluster.
100% Compatibility with AutoMQ
AutoMQ serves as a clear example of this design philosophy. It guarantees 100% compatibility with the Apache Kafka protocol by reusing the vast majority (~98%) of Apache Kafka's original compute-layer source code, including the critical modules that handle API requests. Their innovation lies in replacing Kafka's local log storage system with a cloud-native storage engine built on services like Amazon S3. This new storage layer was carefully designed to expose the exact same internal abstractions that Kafka's upper layers expect. To validate this compatibility, AutoMQ has passed the complete suite of Apache Kafka's own system tests. The result is that organizations can switch to this highly efficient diskless solution from a traditional deployment seamlessly, often requiring no code changes and little more than updating the bootstrap server URL in their existing client configurations.
Embracing the Future of Kafka
The emergence of diskless architecture marks a pivotal evolution for Apache Kafka, addressing the fundamental challenges of cost and scalability in modern cloud environments. By decoupling compute from storage and leveraging the power of cloud object storages, diskless Kafka eliminates the burdensome costs of data replication and fixed block storage, while unlocking true operational elasticity. This paradigm shift transforms Kafka from a powerful but often expensive system into a lean, cloud-native platform fit for a new era of data streaming.
As we've seen, AutoMQ provides a compelling, real-world implementation of the diskless vision. By building on this architecture, AutoMQ delivers substantial benefits: near-100% reduction in cross-zone data transfer costs, storage expenses that are over 10 times lower than traditional setups, and the rapid elasticity needed to leverage cost-effective Spot Instances. Critically, it achieves all this while maintaining 100% compatibility with the Kafka protocol, ensuring a seamless and non-disruptive migration path for existing users.
Experiencing these benefits is the best way to appreciate their impact. AutoMQ offers a free trial, providing a great opportunity to get hands-on with a next-generation diskless Kafka solution. It's a risk-free chance to explore how this technology can redefine the cost and performance of your data streaming infrastructure.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


