

Founded in 2010, FunPlus is a global interactive entertainment company known for high-quality games and distinctive art styles, with a strong following among players in Europe, North America, and other regions. The company has offices in Switzerland, China, Spain, Portugal, and other locations, bringing together 2,000 employees from approximately 20 countries and regions; its localized operations support more than 20 languages, and its products have reached over 100 million players worldwide. Guided by its goal of delivering premium entertainment experiences to players globally through high-quality products, FunPlus focuses on core interactive entertainment markets, using games and broader entertainment products to deepen connections among global users, partners, and diverse cultures. Its business spans game development, global publishing, and esports ecosystem development, with a portfolio of benchmark titles across multiple genres, including Foundation: Galactic Frontier, Tiles Survive, DC: Dark Legion, State of Survival, King of Avalon, and Guns of Glory.
Player logins, in-game events, and real-time operational decisions all depend on a data pipeline running behind the scenes. FunPlus uses Apache Kafka® as the backbone for two core systems:
- Game observability platform: Processes server-side logs, performance metrics, and alerts in real time to ensure game service stability across multiple global regions
- Real-time analytics platform: Powers player behavior analysis, operational dashboards, and in-game recommendations to drive real-time decision-making for operations teams
These pipelines process billions of messages per day. Any disruption directly impacts the player experience. When Kafka cluster costs started spiraling out of control, the FunPlus infrastructure team had to rethink their architecture choices.
The Hidden Cost Buried in the Bill
FunPlus originally ran Kafka clusters in the AWS us-west-2 region. On the surface, the Kafka infrastructure costs looked straightforward: compute, storage, and related cloud resources were itemized and within budget. But when the infrastructure team conducted a cost audit and dug into the AWS billing structure, they uncovered a surprising fact: cross-Availability Zone (AZ) data transfer fees accounted for a significant portion of the Kafka cloud bill.
This cost had gone unnoticed because it did not appear as a Kafka-specific line item. AWS categorizes cross-AZ traffic fees under "EC2-Other" or "Data Transfer," lumped together with network costs from dozens of other services in the account. Isolating how much Kafka contributed was nearly impossible.
How do cross-AZ traffic costs accumulate? Kafka's replica replication, producer writes, and consumer reads all transfer data between different AZs. AWS charges $0.02/GB for each cross-AZ transfer. With FunPlus's clusters processing roughly seven billion messages per day, these three sources of cross-AZ traffic added up fast—making it the single largest line item. For a detailed breakdown and calculation of cross-AZ traffic costs, see our earlier article The Hidden Cloud Cost You Never Noticed in Your Kafka Bill.
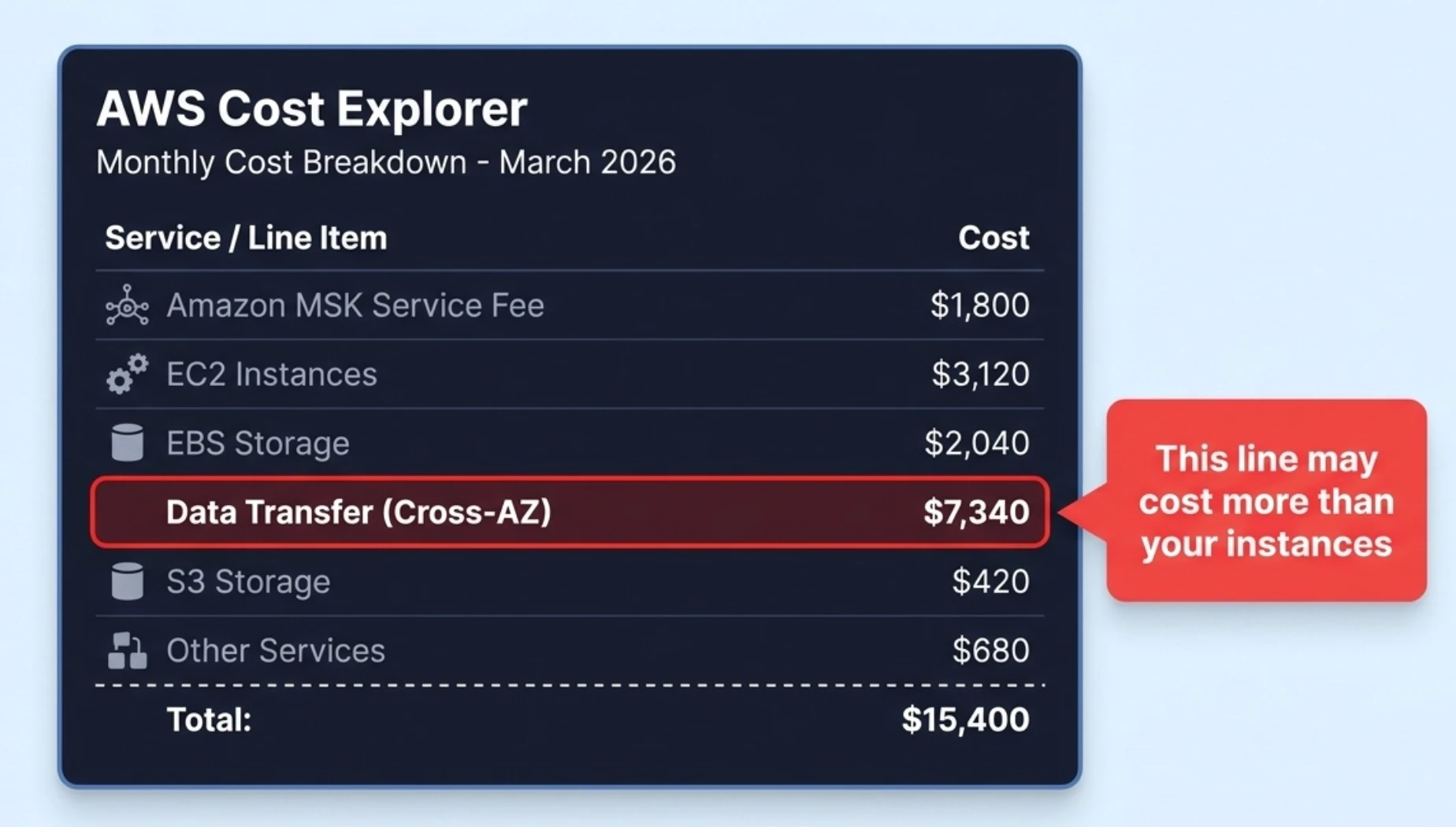
The gaming industry amplifies this problem: high-throughput data pipelines, mandatory multi-AZ deployments for player experience, and global multi-region operations all multiply cross-AZ costs. The team tried configuration optimizations like Fetch from Follower to reduce consumer-side traffic, but producer writes and replica replication account for the bulk of cross-AZ transfers—a consequence of Kafka's storage architecture that no configuration change can solve. Worse, every new game launch and every wave of player growth increased cross-AZ costs proportionally. FunPlus needed a fundamentally different approach.
Why AutoMQ
When evaluating alternatives, FunPlus had two non-negotiable requirements:
- Significantly reduce Kafka costs through an architecture upgrade with no side effects
- Zero impact on production workloads during migration—a cluster processing seven billion messages per day leaves no room for error
AutoMQ met both. On the architecture side, AutoMQ's Diskless architecture moves data persistence from local Elastic Block Store (EBS) on brokers to S3, eliminating broker-to-broker replica replication and removing cross-AZ traffic costs at the root (see Diskless Engine Technical Deep Dive). Storage costs also dropped dramatically—from three EBS replicas to a single copy in S3.
On the migration side, AutoMQ Linking provides zero-downtime migration with byte-level replication and 1:1 offset consistency. Migration can proceed topic by topic, and any stage rolls back without data loss. For a large-scale cluster like FunPlus's—requiring coordination with multiple business teams—this meant migration no longer had to be a company-wide mobilization effort.
AutoMQ also maintains 100% Kafka protocol compatibility. FunPlus's existing producers, consumers, Flink jobs, analytics pipelines, and observability systems all continued working without a single line of code change.
The architecture solves the cost problem. AutoMQ Linking solves the migration risk. Protocol compatibility ensures zero changes upstream and downstream. With all three conditions met, FunPlus decided to move forward.
Migration: The Step Harder Than Choosing the Technology
Teams across the industry are well aware of Kafka's cost problem and know better architectures exist. What stops them is the migration itself.
A production Kafka cluster isn't an isolated component. It's a collection of dozens—sometimes hundreds—of topics, each connected to a different business team. Real-time risk controls, data lake ingestion, player behavior tracking—each topic has a different owner and a different tolerance for disruption. Migration means coordinating with every stakeholder: When does your topic switch? Will messages be lost during the cutover? Will consumer offsets survive? Will Flink checkpoints break?
These questions can't be answered by the infrastructure team alone. They require cross-team coordination, impact assessment for each topic, and rollback plans. Often, the effort of mapping out "which topics can move first and which absolutely can't fail" is enough to shelve the migration plan for months.
Traditional migration approaches make these concerns entirely justified. MirrorMaker2 is the most common community tool, but it has three hard limitations:
- Offsets aren't preserved: MirrorMaker2 re-serializes messages, so offsets on the target cluster don't match the source. All consumer offsets become invalid after migration, Flink checkpoints are voided, and historical data must be reprocessed. For a cluster handling seven billion messages per day, this cost is unacceptable
- "Stop-the-world" cutover: All clients must switch during a single maintenance window, requiring every business team to coordinate downtime. For a 24/7 gaming service, finding a window everyone agrees on is a negotiation in itself
- Rollback is extremely costly: If something goes wrong after the switch, returning to the source cluster means performing another reverse migration—and newly produced data will be lost
It's not that teams don't want to migrate. They can't.
AutoMQ Linking: Turning Migration into a Routine Deployment
FunPlus used AutoMQ Linking, a built-in zero-downtime migration product. This isn't an external tool—it's a productized migration capability within AutoMQ, designed to solve the "can't migrate" and "afraid to migrate" problems described previously. This capability has been battle-tested in production at numerous leading enterprises, consistently earning strong feedback and significantly lowering the barrier for customers migrating to AutoMQ.
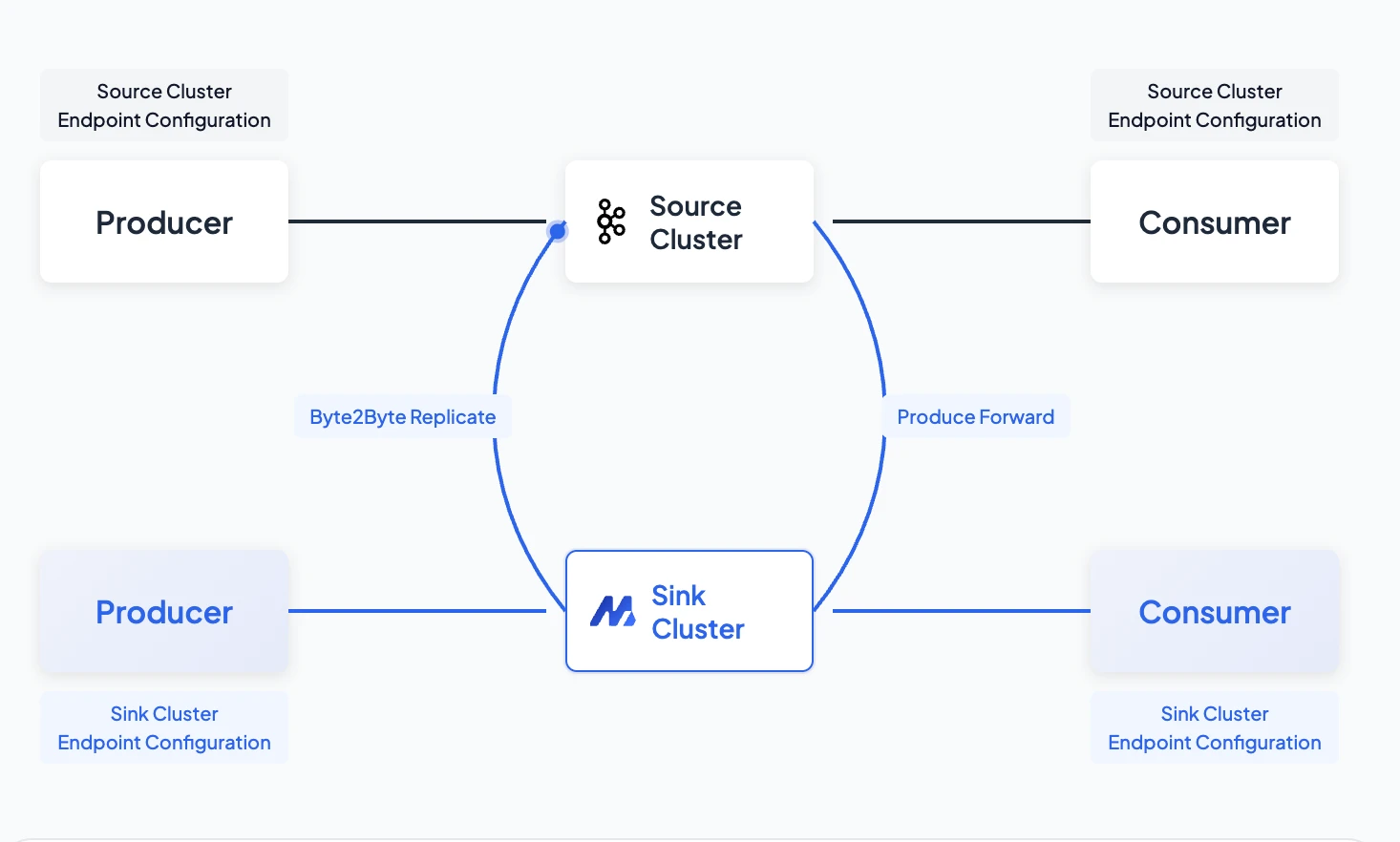
AutoMQ Linking's core design goal is to address the real pain points of Kafka migration—eliminating the concerns teams worry about most:
| Stakeholder concern | AutoMQ Linking's answer | How it works |
|---|---|---|
| "Will offsets change?" | Strict 1:1 consistency | Replicates the raw byte stream from the source cluster without re-serialization—offsets remain identical, with no impact on existing Flink, Spark, or other offset-dependent jobs |
| "Can we roll back if something goes wrong?" | Lossless rollback at any stage | Smart write-forwarding mechanism—during the transition period, writes to the new cluster are transparently proxied back to the source cluster |
| "Will there be duplicate consumption or lost messages?" | Ordered handoff, guaranteed | Consumer coordination logic prevents new consumers from fetching data until old consumers have disconnected |
| "Will the business notice the switch?" | Transparent to the business | Producers and consumers roll over gradually—true zero-downtime migration |
| "Do we have to switch everything at once?" | One topic at a time | Supports topic-level and consumer group-level granularity |
| "Does it depend on external migration components?" | No external dependencies | Built into AutoMQ, fully managed |
These six capabilities together minimize migration risk. Consistent offsets mean Flink, Spark, and other offset-dependent jobs are unaffected. Zero-downtime rolling cutover means business teams notice nothing. Topic-level granularity means teams can proceed at their own pace. Lossless rollback at any stage means no one has to "bet the farm." From the business team's perspective, the Kafka cluster before and after migration looks identical—only the underlying infrastructure has changed.
Phased Migration: Test the Waters, Then Push Forward
With topic-level granularity, FunPlus's migration didn't require an all-or-nothing gamble or simultaneous coordination with every business team. The team adopted a phased approach:
- Migrate non-critical workloads first: Monitoring and logging topics moved to AutoMQ first to validate data integrity and latency. If anything went wrong, the blast radius was contained
- Gradually migrate core pipelines: After the first batch ran stably, real-time analytics and player behavior data pipelines were switched over in stages—each batch followed by an observation period before proceeding
- Rolling client updates: Upstream producers and downstream consumers switched through standard rolling updates, with no coordinated downtime window required
Throughout the transition, AutoMQ Linking provided a critical safety net: if a producer had already switched to the new cluster and started writing, but other components had not yet migrated, those writes were automatically proxied back to the source cluster. This kept data consistent between old and new clusters at all times. If an issue surfaced at any stage, the team cut back to the source cluster immediately—no data loss, and business teams wouldn't even notice the switch had happened.
The entire migration completed with zero downtime and zero app changes. No "stop-the-world" cutover, no 3 AM maintenance window, no ten-team meeting to coordinate switch timing.
Looking back, the biggest change wasn't technical—it was psychological. When offsets are guaranteed to stay the same, rollback is available at any time, and migration can proceed one topic at a time, it transforms from a company-wide mobilization into a routine deployment that teams can execute at their own pace.
Production Results
FunPlus's AutoMQ cluster runs in AWS us-west-2, powering both the game observability platform and the real-time analytics platform across its global game portfolio.

The 60%+ cost reduction is driven by two architectural factors (based on FunPlus production data):
- Elimination of cross-AZ data transfer costs—previously the largest single cost item, now reduced to near zero because there is no broker-to-broker replication
- Storage model shift—from three EBS replicas to a single S3 copy, significantly reducing storage costs
This isn't a one-time saving from downsizing or reserved instances—it's structural, and it scales with the cluster. Downstream systems (Flink jobs, analytics pipelines, observability systems, and all game client integrations) continue running as before, connected to what looks—from their perspective—like a standard Kafka cluster.
Future Outlook
With Kafka infrastructure costs decoupled from business growth, FunPlus can confidently scale its data pipelines to support new game launches and growing player bases. The team is exploring further optimizations enabled by AutoMQ's stateless brokers architecture, including using Spot Instances to reduce compute costs.
For any team running mid-to-large-scale Kafka clusters on AWS or GCP—whether in gaming, e-commerce, fintech, or SaaS—cross-AZ traffic costs are worth a close look at the bill. The number hidden under "EC2-Other" is often larger than expected.
Multiple leading gaming companies have deployed AutoMQ at scale in production. If you are evaluating Kafka infrastructure cost optimization, contact us to learn more about gaming industry deployments.


