Kafka consumer groups represent a fundamental concept in Apache Kafka's architecture that enables scalable and fault-tolerant data consumption patterns. They provide a flexible abstraction that bridges the gap between traditional messaging models, offering developers powerful ways to process streaming data in distributed applications. This report explores consumer groups in depth, covering their definition, configuration options, practical usage scenarios, and recommended best practices.
Understanding Kafka Consumer Groups
A Kafka consumer group is a collection of consumer instances that cooperate to consume data from one or more topics. Consumer groups allow multiple processes or machines to coordinate access to topics, effectively distributing the processing load among group members. This grouping mechanism represents Kafka's single consumer abstraction that generalizes both traditional queuing and publish-subscribe messaging models.
When consumers join the same group by using the same group.id, they collaborate to process messages without duplicating efforts. Each message published to a topic is delivered to only one consumer instance within each subscribing consumer group. This behavior enables parallel processing while ensuring that each message is processed exactly once within the group. The coordination happens automatically, with Kafka handling the complex details of assigning partitions to specific consumers and managing their lifecycle.
The consumer group concept is central to Kafka's design for scalability. It allows applications to easily scale horizontally by adding more consumer instances to a group, which automatically triggers redistribution of partitions among available consumers. This self-balancing mechanism ensures efficient resource utilization and supports elastic scaling based on processing demands.
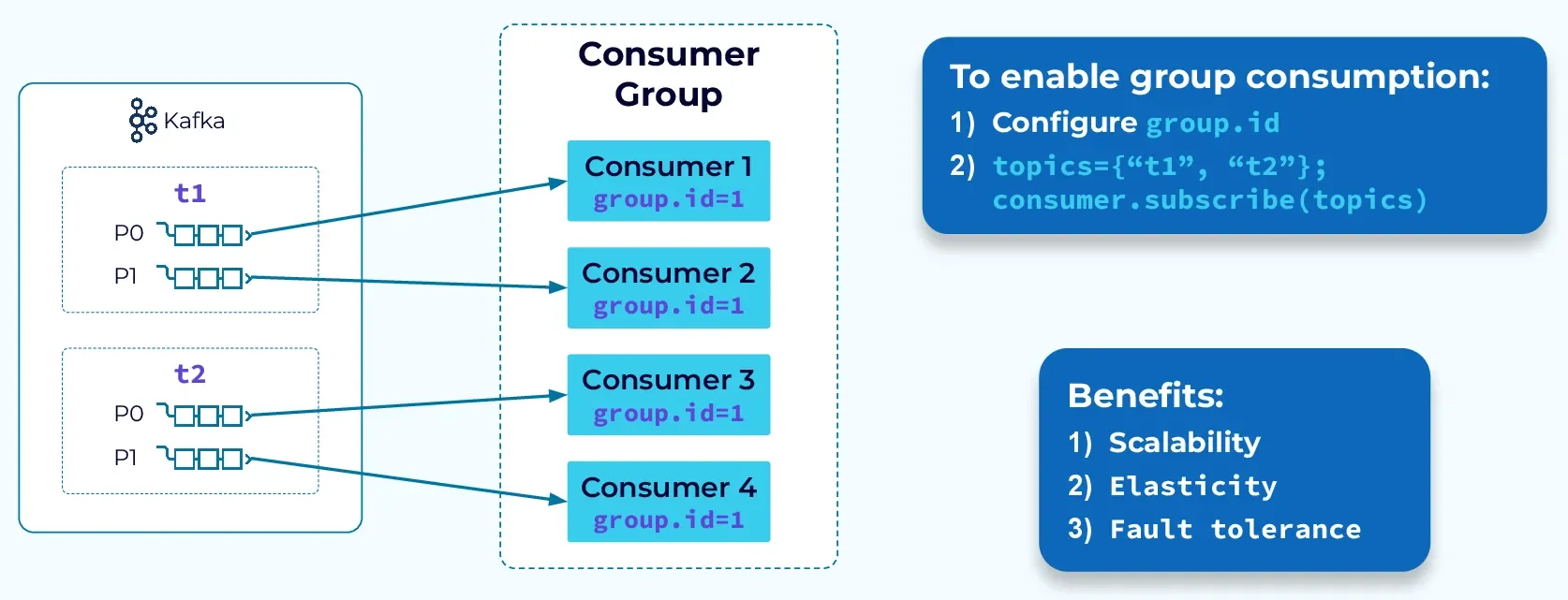
How Kafka Consumer Groups Work
Consumer groups operate on the principle of partition assignment, where Kafka divides the partitions of subscribed topics among the group's consumers. This distribution follows specific algorithms to ensure balanced workloads. When a consumer group contains only one consumer, that consumer receives messages from all partitions in the topic. However, when multiple consumers belong to the same group, each consumer is assigned a subset of partitions.
The partition assignment process is managed by a designated broker known as the group coordinator. One of the brokers in the Kafka cluster is designated as the coordinator for each consumer group and is responsible for managing the members of the group as well as their partition assignments. The coordinator is chosen from the leaders of the internal offsets topic (__consumer_offsets), which stores committed offsets for each consumer group.
Rebalancing occurs whenever group membership changes—when consumers join, leave, or fail. During rebalancing, Kafka redistributes partitions to ensure equitable workload distribution among remaining consumers. This automatic rebalancing is a key feature that provides fault tolerance, as the system can adapt to consumer failures by reassigning their partitions to healthy consumers.
It's important to understand that the parallelism of a consumer group is limited by the number of partitions in the subscribed topics. The maximum number of consumers that can actively process messages within a single consumer group cannot exceed the total number of partitions they're consuming. If there are more consumers than partitions, the excess consumers will remain idle, receiving no messages until the group composition changes.
Configuring Kafka Consumer Groups
Consumer groups are not explicitly created as standalone entities in Kafka. Instead, they come into existence when consumers are configured with a specific group identifier. Every Kafka consumer must belong to a consumer group, whether operating alone or as part of a collaborative processing group.
The fundamental configuration parameter for consumer groups is the group.id property, which assigns a unique identifier to distinguish one group from another. This ID must be unique within the Kafka cluster, as it's used by brokers to track consumption progress and coordinate partition assignments. When using the Kafka API, you must set this property to use essential consumer functions like subscribe\() or commit\() .
Configuration approaches vary by programming language and client libraries. In JavaScript using KafkaJS, the group ID is specified when creating the consumer:
const consumer = kafka.consumer({ groupId: 'my-group' })In Java applications, the configuration typically appears in a Properties object:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("group.id", "my-group");For Python consumers, the group ID is often set in a configuration file that's imported when creating the consumer. When using the Java-based Kafka Streams API, the APPLICATION_ID_CONFIG parameter serves as the consumer group ID.
For console-based consumers, you can specify the group ID using the --group parameter. Without this explicit setting, console consumers are automatically assigned to a group with the prefix "console-consumer" followed by a unique identifier like a process ID.
Practical Usage of Consumer Groups
Kafka consumer groups support various consumption patterns to meet different application requirements. The simplest pattern involves a single consumer group with multiple consumers processing messages in parallel. This configuration resembles a traditional queue model, where each message is delivered to exactly one consumer within the group.
For applications requiring independent processing of the same messages, multiple consumer groups can subscribe to the same topics. Each group receives a complete copy of all messages, enabling scenarios like maintaining separate views of the same data or implementing diverse processing pipelines on identical message streams. This approach resembles the publish-subscribe messaging model.
Consumer groups facilitate Kafka's standard processing flow: poll data, execute consumption logic, then poll again. This cycle allows consumers to control their pace of message processing, ensuring they don't receive more messages than they can handle. The polling mechanism also enables features like consumer timeouts and heartbeat monitoring.
For administering consumer groups, Kafka provides the kafka-consumer-groups tool, which supports various operations:
bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-groupThis command shows the current position of all consumers in the specified group, revealing details such as current offsets, log-end offsets, and consumer lag. The tool can also list all consumer groups, delete consumer group information, or reset consumer group offsets.
The output includes essential metrics like partition assignments, current offsets, and lag information:
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID my-topic 0 2 4 2 consumer-1-... /127.0.0.1 consumer-1 my-topic 1 2 3 1 consumer-1-... /127.0.0.1 consumer-1 my-topic 2 2 3 1 consumer-2-... /127.0.0.1 consumer-2
This information helps operators monitor consumer health and identify potential bottlenecks in message processing.
Best Practices for Kafka Consumer Groups
Based on industry experience and the provided references, several best practices emerge for effectively using Kafka consumer groups:
Meaningful Group Naming
Use descriptive and meaningful consumer group names that reflect the purpose of the consumer. This practice simplifies monitoring and troubleshooting by making it easier to identify specific consumer groups and their functions in complex systems. A clear naming convention also helps enforce separation of concerns among different application components.
Partition and Consumer Scaling
The number of partitions directly affects the maximum number of consumers that can be active within a group. Since each partition can only be consumed by one consumer in a group, the partition count establishes an upper limit on parallelism. When designing topics, consider future scaling needs and create enough partitions to accommodate anticipated growth in consumer instances.
While adding more consumers can increase throughput, there's no benefit to having more consumers than partitions, as the excess consumers will remain idle. Finding the optimal balance between partition count and consumer instances requires careful consideration of factors like message volume, processing complexity, and available resources.
Managing Rebalances
Frequent rebalances can significantly impact consumer performance. Rebalances typically occur when consumer heartbeats timeout due to high processing loads or network issues. To minimize disruptive rebalances, consider:
-
Adjusting heartbeat intervals and timeout thresholds based on expected processing patterns
-
Increasing consumption rates to prevent processing backlogs
-
Implementing graceful shutdown procedures for consumers to avoid triggering unnecessary rebalances
-
Monitoring consumer lag to identify potential processing bottlenecks before they cause timeouts
Consumer Group Strategy Selection
The choice between using a single consumer group with multiple consumers or multiple consumer groups depends on your specific use case. If you need multiple services to process the same messages independently (like separate services for customer address management and delivery notifications), use separate consumer groups. However, if you need to distribute processing load across multiple instances of the same service, use a single consumer group with multiple consumers.
For applications with varying processing requirements across different message types, consider using separate topics with dedicated consumer groups. This approach allows you to scale each processing pipeline independently based on its specific throughput needs.
Performance Optimization
To optimize consumer performance, consider these configuration adjustments:
-
Increase batch size and enable batching through the
fetch.min.bytesandfetch.max.wait.msparameters to improve throughput for high-volume scenarios -
Configure appropriate buffer sizes based on message volumes and processing patterns
-
Implement proper error handling with backoff strategies for transient failures
-
Monitor consumer lag regularly and adjust resource allocation based on observed patterns
-
Use idempotent consumers when possible to ensure exactly-once processing semantics
Monitoring and Observability
Implement comprehensive monitoring for consumer groups using tools like Confluent Control Center or Grafana. Key metrics to track include:
-
Consumer lag (difference between latest offset and consumer's current position)
-
Throughput (messages processed per second)
-
Error rates and types
-
Rebalance frequency and duration
-
Processing time per message
These metrics provide visibility into consumer health and help identify potential issues before they impact system performance.
Does AutoMQ also have the concept of a consumer group?
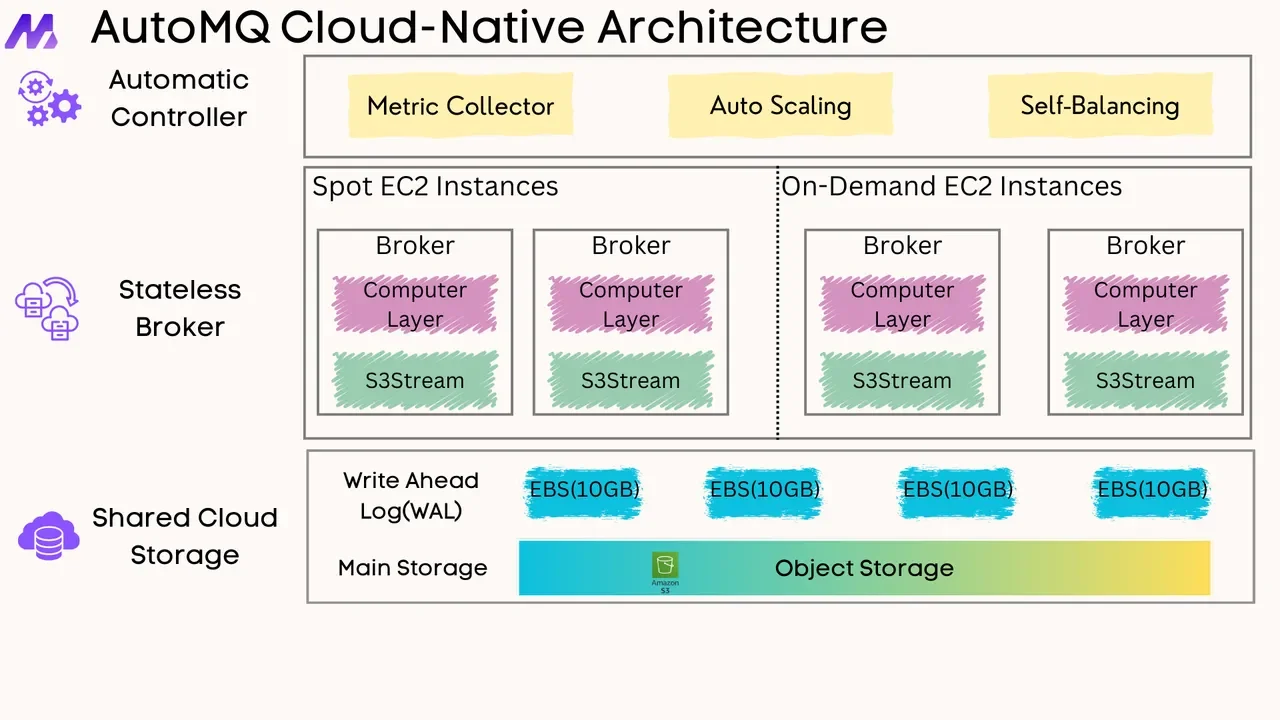
AutoMQ is a next-generation Kafka that is 100% fully compatible and built on top of S3. Thanks to AutoMQ's complete Kafka compatibility, you can use the same Kafka clients in various programming languages when working with AutoMQ—both for producers and consumers. This means your existing Kafka client code works without modification. Therefore, understanding Kafka consumer groups is equally important when using AutoMQ.
Check out the article: How AutoMQ makes Apache Kafka 100% protocol compatible? to understand how AutoMQ achieves 100% complete compatibility with Kafka.
Conclusion
Kafka consumer groups provide a powerful abstraction for scaling message consumption and building resilient stream processing applications. They enable flexible consumption patterns ranging from load-balanced queue-like processing to independent parallel processing streams. By understanding the core concepts, configuration options, and best practices outlined in this report, developers can effectively leverage consumer groups to build high-performance, scalable streaming applications.
The key to successful implementation lies in thoughtful configuration based on specific application requirements. This includes selecting appropriate partition counts, consumer scaling strategies, and monitoring approaches. By following the best practices discussed, organizations can build robust Kafka-based solutions that efficiently process large volumes of streaming data while maintaining reliability and performance.
As applications grow in complexity and scale, the proper management of consumer groups becomes increasingly important. Regular monitoring, performance tuning, and architectural reviews help ensure that consumer groups continue to meet evolving business requirements while maintaining optimal performance.


