.png)
TL;DR
Apache Kafka KIP-1150, known as "Diskless Topics", is a major proposal to re-architect how Kafka handles data in the cloud. It suggests allowing topics to store their data directly in object storage, like Amazon S3, instead of on broker-local disks.
The Problem It Solves: KIP-1150 directly targets the largest cloud expenses for Kafka users: the high cost of network traffic from replicating data across different availability zones, and the reliance on expensive, provisioned block storage.
The Proposed Solution: It introduces a "leaderless" architecture where any broker can write data to a shared object store, bypassing the traditional replication process and its associated costs.
The Core Concerns: The community has raised significant concerns about this fundamental architectural change, highlighting the complexity of supporting critical features like transactions and the potential for a long-term maintenance burden by creating two parallel systems within Kafka.
The blog also discusses AutoMQ as an alternative leader-based diskless approach, detailing how it achieves the same cost-saving goals while ensuring 100% Kafka compatibility. This solution has been used in production by many leading companies, formally proposed to the Kafka community for discussion as KIP-1183: Unified Shared Storage.
What is KIP-1150?
Apache Kafka Improvement Proposal (KIP) 1150, titled "Diskless Topics," introduces a new architectural approach for data management within Apache Kafka. The central idea is to allow for the creation of topics that store their data directly in an external object storage system, such as Amazon S3 or Google Cloud Storage, rather than on the local disks of individual Kafka brokers.
This proposal describes a fundamental shift from Kafka's traditional replication model. Instead of brokers replicating data amongst themselves, a broker that receives a message for a diskless topic would be responsible for writing it to the shared object store. This process would function alongside the existing disk-based topic model, allowing users to select the appropriate topic type on a case-by-case basis within the same cluster.
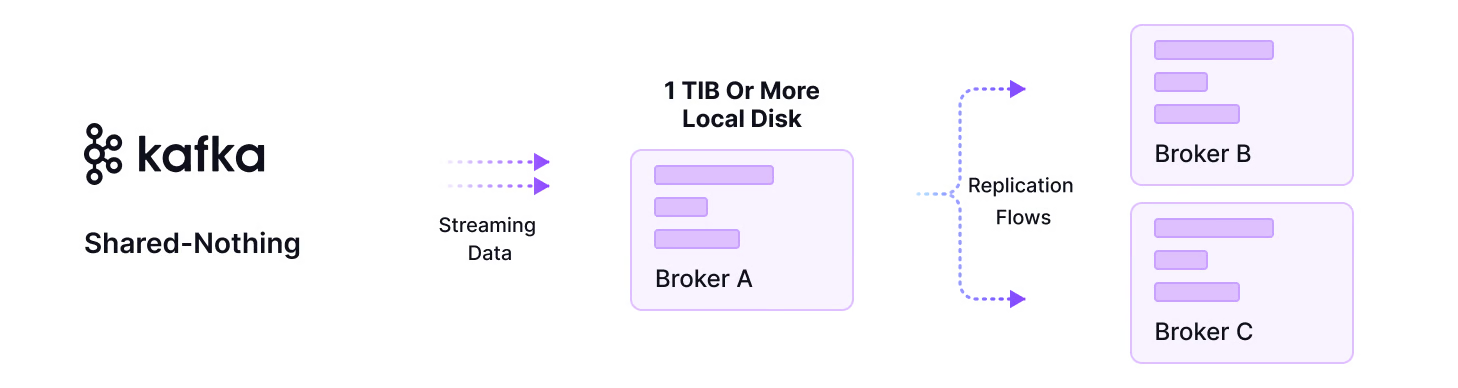
To support this new data flow, the KIP outlines a "leaderless" model for diskless topic partitions. In this model, any broker can accept writes for a partition, differing from the standard model where a single leader broker handles all incoming messages. To maintain strict message ordering, the proposal introduces a new component known as the "Batch Coordinator." This component would act as a sequencer, assigning official offsets to batches of data after they have been durably persisted in the object store

What Problem Does This Proposal Try to Solve?
The central goal of KIP-1150, or "Diskless Topics," is to address the high operational cost of running Apache Kafka in cloud environments. The proposal targets specific architectural aspects that are misaligned with cloud pricing models, and in solving them, it also introduces other operational benefits.
Reducing Core Infrastructure Costs
Kafka's traditional design leads to two primary cost centers in the cloud, both of which KIP-1150 aims to resolve.
Problem: High Network and Storage Expenses
For fault tolerance, Kafka replicates data across brokers in different Availability Zones (AZs), incurring substantial network fees for this traffic. It also requires expensive block storage (like Amazon EBS) for active data logs. While the existing Tiered Storage (KIP-405) offloads old data, it doesn't solve these costs for new, active data.
Proposed Solution: Lowering Costs with Object Storage
By writing data directly to cheaper object storage (e.g., Amazon S3), the proposal allows active data to reside on a more economical storage tier. This action also eliminates the costly inter-AZ data replication traffic, as data is written once to a central location, directly targeting Kafka's largest cloud expenses.
Improving Operational Agility
Beyond direct cost savings, the diskless architecture proposes changes that enhance cluster management.
Faster Elasticity and Scaling: With storage decoupled from compute, new brokers can be added almost instantly. They do not need to copy large data sets, allowing clusters to scale processing capacity rapidly in response to demand.
Simpler Cluster Management: The architecture simplifies operations like data rebalancing, which becomes much faster. The proposed leaderless model can also mitigate "hot partition" issues by distributing the write load more effectively across brokers.
What Are the Community's Concerns?
While the cost-saving potential of KIP-1150 is acknowledged, the proposal has raised several concerns within the Apache Kafka community, primarily centered on its fundamental architectural changes and the potential long-term consequences.
Architectural Divergence: Leaderless vs. Leader-Based
The most prominent concern is the shift from Kafka's established leader-based architecture to a new leaderless model. For years, the concept of a single, authoritative leader for each partition has been the cornerstone of Kafka's design, providing the foundation for data consistency and ordering. Introducing a parallel, leaderless system for diskless topics raises fears of creating a "fork" within the project, effectively requiring developers and operators to manage two distinct systems.
Impact on Core Kafka Features
This architectural divergence leads to critical questions about supporting existing features. Many of Kafka’s essential functionalities are deeply intertwined with the partition leader model. These include:
Transactions: The atomicity guarantees of Kafka transactions rely on coordination through the partition leader.
Idempotent Producers: Ensuring exactly-once, in-order delivery per producer is also managed by the leader.
The community has expressed apprehension about the complexity of re-implementing these guarantees in a leaderless world and whether they can be supported with the same semantics.
Long-Term Development and Maintenance Burden
A significant practical concern is the potential for a long-term maintenance burden. If every new feature or bug fix in Kafka needs to be designed and tested for both leader-based and leaderless topics, it could drastically slow the project's overall pace of innovation and increase the complexity for contributors.
Metadata Scalability and Complexity
Finally, there are concerns regarding the proposed metadata management system. The KIP introduces a new, potentially large metadata layer to track data batches in object storage, which may need to be managed by a separate database-like component. Community members have questioned the operational complexity and scalability of this new system, which adds another moving part to the Kafka ecosystem.
AutoMQ: Achieving Diskless Benefits with a Leader-Based Model
The community's concerns about KIP-1150's disruptive leaderless design highlight a fundamental tension: how to evolve Kafka for the cloud without breaking the architectural principles that made it successful. While the proposal's cost-saving goals are important, the risks associated with such a dramatic change have led to reservations. This situation, however, creates an opportunity for alternative approaches that can deliver similar benefits with less disruption.
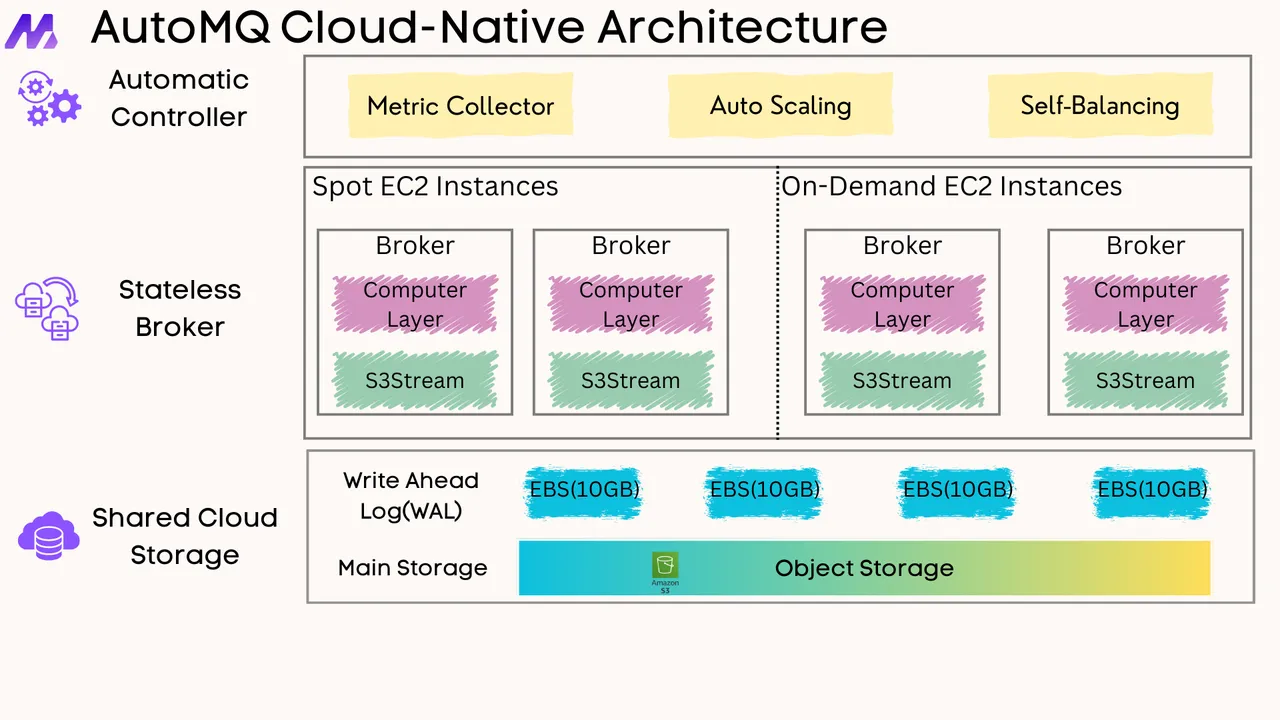
One such alternative is presented by AutoMQ, a cloud-native messaging and streaming platform designed to be a drop-in replacement for Kafka. AutoMQ's core innovation is its ability to deliver a diskless architecture while retaining Kafka's trusted leader-based model. Instead of brokers writing to local disks, they write to a shared, durable log layer built on top of cloud object storage like Amazon S3.
By preserving the leader-based paradigm, AutoMQ aims to provide the best of both worlds. It unlocks the primary benefits of a diskless approach—dramatically lower costs by eliminating inter-zone replication traffic and using cheaper storage, plus massive elasticity by decoupling compute and storage. At the same time, it avoids the architectural conflicts and feature-support challenges of KIP-1150. This strategy allows existing Kafka applications and tools to migrate seamlessly, gaining cloud-native advantages without the risk of adopting a fundamentally different and unproven replication model.
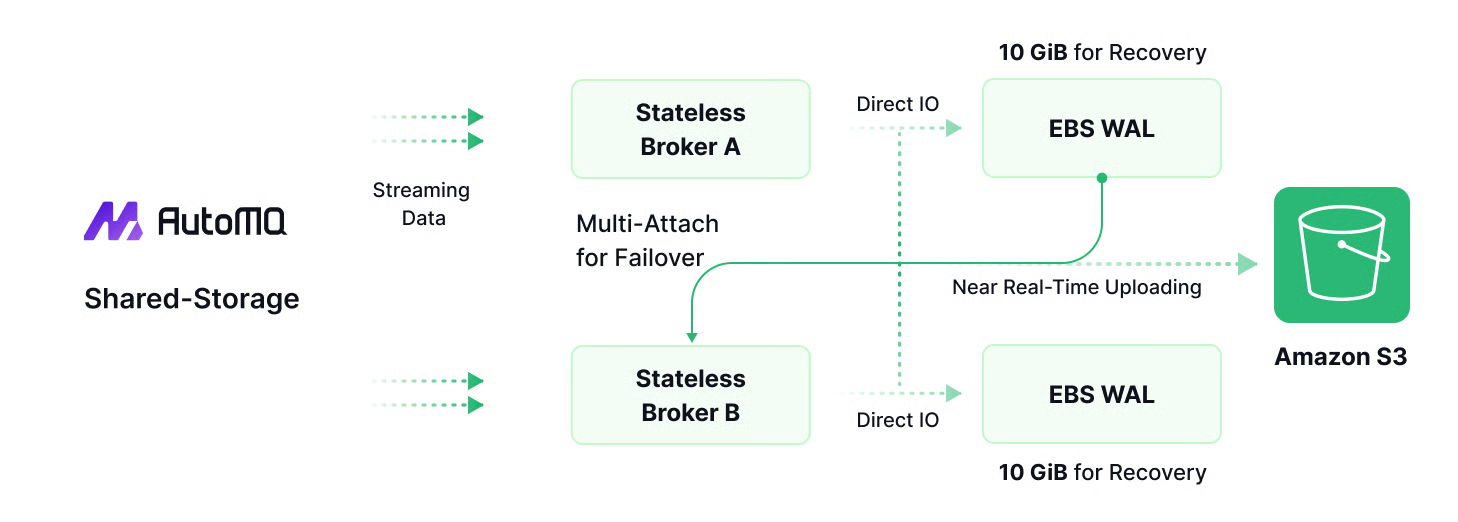
Compatibility by Design: How AutoMQ Stays 100% Kafka-Native
AutoMQ achieves 100% compatibility with the Apache Kafka protocol by strategically reusing the vast majority of Kafka's original source code, while replacing only the storage layer with a cloud-native implementation. This approach ensures that from a client's perspective, AutoMQ is indistinguishable from a standard Kafka cluster—a claim validated by its ability to pass the full suite of Apache Kafka protocol test cases.
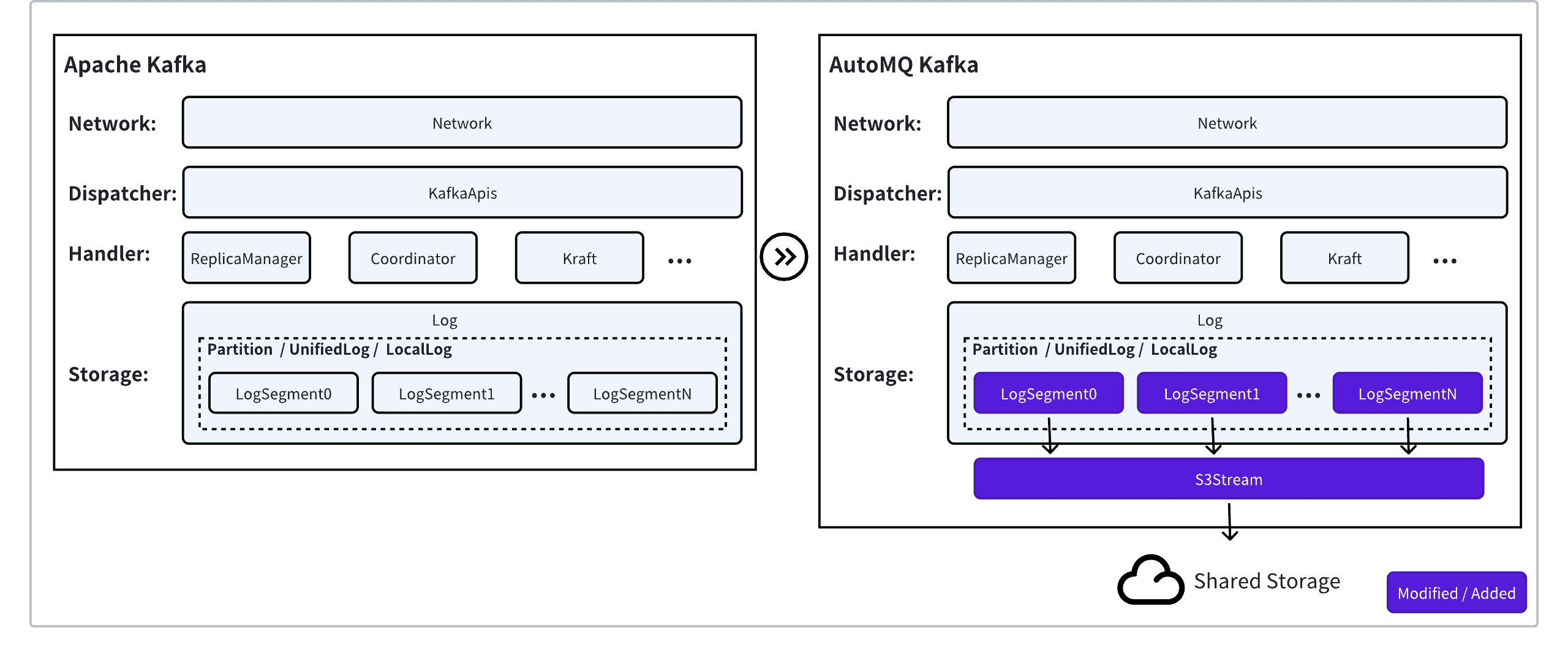
Here's how this compatibility is maintained:
Reusing Kafka's Protocol and Application Layers
Instead of rewriting the complex logic that handles client requests, AutoMQ directly incorporates over 98% of Apache Kafka's battle-tested kafka-server module. This includes all the code responsible for processing network requests, managing metadata with Kraft, coordinating consumer groups, and handling APIs for producers and consumers. By using Kafka's own code for these functions, AutoMQ guarantees that it behaves exactly as Kafka does, supporting all protocol versions, features, and nuanced semantics that clients expect.
A Pluggable, Cloud-Native Storage Engine
The core innovation lies in how AutoMQ replaces Kafka's local disk-based storage. It introduces a custom storage engine built around an abstraction called S3Stream . This engine is designed to use cloud object storage (like Amazon S3) as its primary data store. Crucially, this new storage layer exposes the exact same Partition interface that Kafka's upper layers are designed to work with. This plug-and-play approach means the components responsible for replication ( ReplicaManager ), API handling ( KafkaApis ), and other core logic don't need to be changed; they simply interact with what appears to be a standard Kafka partition, while the data is actually being streamed to and from the cloud.
This method ensures that AutoMQ is not just wire-compatible but fully semantically compatible, inheriting Kafka's features, bug fixes, and future updates with minimal effort.
Slashing Your TCO: AutoMQ vs. Kafka Cost Breakdown
If you run Kafka in the cloud, you know the story: powerful but expensive. Your cloud bill climbs relentlessly, but it doesn't have to be that way. A diskless architecture, like AutoMQ's, directly attacks the three main sources of that cost.
Storage
Traditional Kafka forces you onto expensive block storage (EBS), where you pay for 3x data replication and for overprovisioned capacity you don't even use. It's a model that guarantees waste. AutoMQ flips this by using standard object storage (S3). You pay a fraction of the price per GB on a pure pay-as-you-go basis—no replication tax, no paying for empty space. This alone can slash your storage bill by up to 90%.
Network
That "Inter-AZ Data Transfer" line item on your bill is Kafka's replication tax. For every 1 GB of data you write, you pay a network fee to transfer 2 GB across different cloud zones for durability. AutoMQ's shared storage architecture eliminates this completely. Data is written once to a central, regional store, and the costly replication traffic simply vanishes.
Compute
Stateful Kafka brokers chain compute to storage, making scaling inefficient and using Spot Instances risky. When a stateful Spot broker disappears, you're facing a slow, performance-killing data recovery. AutoMQ's stateless brokers break these chains. You can scale compute instantly with smaller, cheaper instances and safely leverage Spot Instances for massive savings. If a broker vanishes, a new one is online and productive in seconds, not hours. This is the cloud elasticity you were always meant to have.
The Future of Kafka: Navigating a Cloud-Native Path
The need to adapt Apache Kafka to the economic realities of the cloud has spurred critical innovation aimed at solving its high operational costs. The official KIP-1150 proposal offers a bold solution—a leaderless, diskless architecture—that promises huge savings but raises valid community concerns about its complexity and architectural risks.
Meanwhile, solutions like AutoMQ provide an alternative path that has been formally proposed to the Kafka community for discussion as KIP-1183. This approach achieves similar cloud-native efficiency and cost reduction while preserving Kafka's trusted, leader-based design to ensure 100% compatibility.
This evolution towards a "diskless" Kafka is vital. The ongoing debate and the emergence of different architectural philosophies ultimately benefit the entire ecosystem, giving users more powerful choices to optimize their deployments for cost, performance, and risk in the cloud era.
Interested in our diskless Kafka solution AutoMQ? AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. See how leading companies leverage AutoMQ in their production environments by reading our case studies. The source code is also available on GitHub.
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging