Kafka latency is the time delay between when a message is produced and when it's consumed. This critical performance metric directly impacts real-time data processing capabilities and application responsiveness. In today's data-driven environments where milliseconds matter, understanding and optimizing Kafka latency has become essential for maintaining competitive advantage.
Kafka latency is the time it takes a message to be published by a producer and then delivered to a consumer. In performance-critical applications such as financial trading, real-time monitoring, or fraud detection, minimizing this delay is crucial. Low latency enables near-real-time data processing and analysis, making it possible to make decisions based on the most current information available3.
When discussing Kafka performance, it's important to distinguish between latency and throughput. While related, these metrics represent different aspects of system performance. Throughput measures the rate at which Kafka can process messages, typically expressed as messages per second or megabytes per second. Latency measures the delay experienced by individual messages. The relationship between these metrics is often inversely proportional – optimizing for maximum throughput might increase latency, while optimizing for minimum latency might reduce throughput313.
Understanding Kafka Latency Components
End-to-end latency in Kafka comprises several distinct components that occur sequentially as a message travels through the system:
-
Producer Latency : The time it takes for a producer to send a record to a broker and receive an acknowledgment. This includes the produce, publish, and (potentially) commit times1.
-
Broker Processing Time : Includes time spent in the request queue and the actual processing by the leader broker6.
-
Storage Time : The period a message waits in Kafka storage before being fetched by a consumer6.
-
Consumer Latency : How long it takes to send a fetch request to the broker and for the broker to return the response to the consumer1.
-
Consumer Processing Time : The time required by the application to process the consumed message6.
Looking deeper at producer latency, it can be further broken down into:
-
Produce Time : Time to send the message to the broker
-
Publish Time : Time for the leader broker to write the message to its local log
-
Commit Time : Time for followers to replicate the message (if acks=all)1
Understanding these components is crucial for identifying bottlenecks and optimizing specific areas of your Kafka deployment.
Performance Analysis
Benchmarking Kafka Latency
Benchmarking is essential for understanding how Kafka performs under different conditions and for comparing different configurations or alternatives.
Benchmark Tools and Methodologies
Several tools are commonly used for benchmarking Kafka:
-
The Linux Foundation's OpenMessaging Benchmark : A standardized way to measure messaging system performance5
-
Kafka's own performance tools : Built-in tools for measuring producer and consumer performance
-
Confluent's Performance Testing Tool : Specialized tools from Kafka's commercial distributor
-
JMeter and custom applications : For more specialized testing scenarios8
When benchmarking, it's important to collect various metrics:
-
End-to-End Latency : Total time from production to consumption
-
Producer Latency : Time for message production acknowledgment
-
Consumer Latency : Time for message consumption
-
Percentile Latencies : p50, p95, p99, and p99.9 to understand tail latencies
AutoMQ's Kafka Benchmark Tool(Recommended)
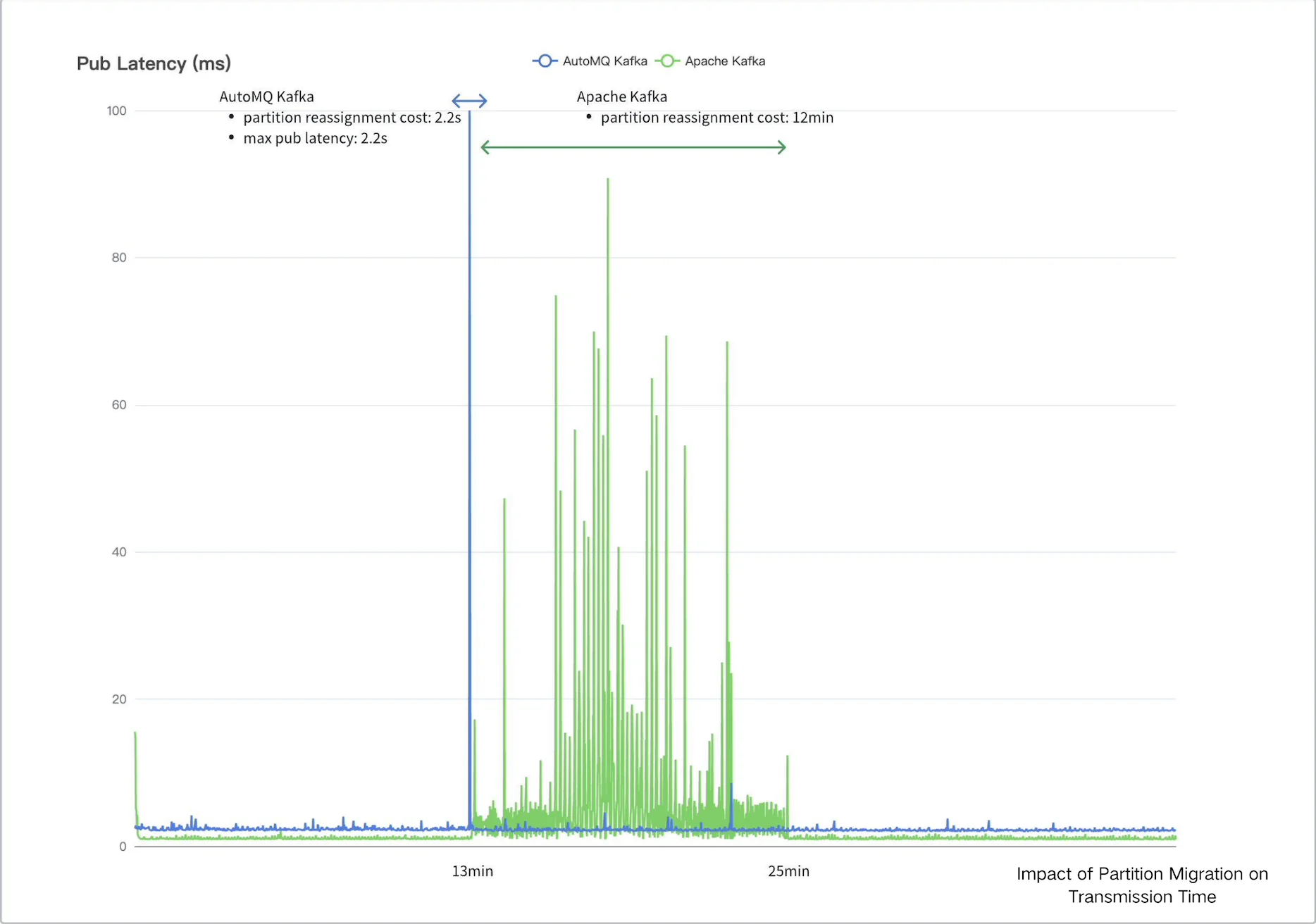
AutoMQ provides a Benchmark tool based on OpenMessaging. It is easier to use and get started with compared to OpenMessaging. For details, you can refer to their article: "How to Perform a Performance Test on AutoMQ".
Since AutoMQ and Apache Kafka are 100% fully compatible, this OpenMessaging-optimized testing tool is also applicable to other Kafka-compatible systems.
Conducting comprehensive and accurate performance tests is a challenging task. You can refer to the "AutoMQ vs. Apache Kafka Benchmark Report" to learn how to perform performance testing on Kafka.

Optimization Strategies
Optimizing Kafka for Low Latency
Broker Configuration
Kafka brokers can be tuned significantly to optimize latency:

It's important to note that many of Kafka's default settings are already optimized for latency by minimizing artificial delays1.
Producer Configuration
Producer settings have a significant impact on latency:
-
linger.ms: By default, this is set to 0, meaning messages are sent as soon as possible. While this minimizes latency for individual messages, setting it to a small value (5-10ms) can sometimes reduce tail latencies by improving batching without significantly affecting average latency19.
-
batch.size : Controls the amount of memory used for batching. Smaller batches lead to lower latency but may affect throughput. The default is 16 KB9.
-
acks : The acknowledgment level. "acks=1" provides a balance between performance and data durability. "acks=all" increases latency but provides stronger durability guarantees9.
A Confluent experiment showed that increasing linger.ms from 0 to just 5ms significantly improved batching (requests decreased from 2,800 to 1,100) and had a dramatic impact on the 99th percentile latency, with smaller but still notable improvements to the median latency1.
Consumer Configuration
Consumer settings also affect end-to-end latency:
-
fetch.min.bytes : Determines the minimum amount of data the server should return. Higher values reduce network requests but may increase latency. The default is 1 byte, which prioritizes latency9.
-
fetch.max.wait.ms: Maximum time the server will block before answering the fetch request if there isn't sufficient data. Lower values reduce latency but increase network requests9.
-
max.poll.records : Limits the maximum number of records returned in a single call to poll(). Adjusting this can help balance processing time and latency9.
Hardware and OS Optimization
Hardware choices significantly impact Kafka latency:
-
Storage : SSDs offer substantially better latency than HDDs, especially for random access patterns10.
-
CPU : Faster CPUs with higher clock speeds often benefit latency-sensitive workloads more than adding cores2.
-
Network : High-bandwidth, low-latency networking is crucial for Kafka clusters.
OS-level optimizations include:
-
Adjusting JVM garbage collection settings to minimize pause times
-
Optimizing file system caches
-
Configuring network parameters like TCP buffer sizes9
Troubleshooting
Common Latency Issues and Solutions
High Consumer Lag
Problem : Consumers falling behind producers, leading to delayed processing.
Solutions :
-
Adjust fetch settings (increase fetch.min.bytes, lower fetch.max.wait.ms)
-
Scale consumers by adding more to the consumer group
-
Monitor consumer lag in real-time and set up alerts1011
Under-Replicated Partitions
Problem : Replicas not in sync with leaders, potentially causing increased commit times.
Solutions :
-
Check for broker overload or network issues
-
Increase replication bandwidth if necessary
-
Consider scaling cluster resources or redistributing partitions10
Broker Overload
Problem : Overloaded brokers leading to high CPU usage, memory pressure, and disk I/O bottlenecks.
Solutions :
-
Ensure even partition distribution
-
Optimize JVM settings
-
Monitor and upgrade resources as needed10
Network Issues
Problem : Network congestion or poor configuration leading to increased latency.
Solutions :
-
Optimize network infrastructure
-
Ensure sufficient bandwidth between components
-
Configure appropriate TCP settings
Best Practices and Recommendations
Balance Durability and Latency
Durability requirements directly impact latency. Higher replication factors increase durability but add replication overhead to latency and increase broker load1.
The replication factor defines how many copies of data exist in the cluster. Higher replication factors allow for greater fault tolerance but impact performance:
-
RF=1: Minimal latency, weakest durability
-
RF=3: Recommended for production, balances durability and performance
Understand Batching Benefits
While batching is typically associated with throughput optimization, properly configured batching can actually improve tail latencies by reducing per-record overhead. Confluent's experiments showed that with multiple producers, a small linger.ms value (5-10ms) significantly improved the 99th percentile latency1.
Monitor Key Metrics
Regular monitoring is essential for maintaining low latency:
-
Consumer Lag : The difference between the latest produced offset and the consumer's current position.
-
Request Queue Time : How long requests wait in the broker's queue before processing.
-
Request Processing Time : How long the broker takes to process requests.
-
Garbage Collection Metrics : Especially important for detecting JVM pauses that can cause latency spikes.
Scale Appropriately
Proper scaling helps maintain low latency as demand grows:
-
Partition Scaling : Ensure enough partitions to distribute load, but not so many that overhead becomes problematic.
-
Broker Scaling : Add brokers when existing ones approach resource limits.
-
Consumer Scaling : Ensure consumer groups have enough instances to handle the workload without falling behind.
Conclusion
Optimizing Kafka for low latency requires a comprehensive understanding of its components, careful configuration, and ongoing monitoring. While Kafka was traditionally associated with high-throughput use cases, it can be effectively tuned for low-latency applications as well.
The key takeaways for maintaining low-latency Kafka deployments are:
-
Understand the tradeoffs between latency, throughput, and durability
-
Configure producers, consumers, and brokers appropriately for your use case
-
Choose the right hardware and optimize at the OS level
-
Monitor performance continuously and address issues proactively
-
Scale intelligently as demands grow
By following these guidelines and best practices, organizations can achieve reliable, low-latency performance from their Kafka deployments, enabling real-time data processing capabilities essential for modern data-driven applications.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


