Overview
Kafka offsets are a fundamental component of Apache Kafka's architecture, enabling reliable and fault-tolerant data processing while ensuring message delivery guarantees. This comprehensive guide explores the concept of Kafka offsets, their importance, management strategies, and best practices based on authoritative industry sources.
What are Kafka Offsets?
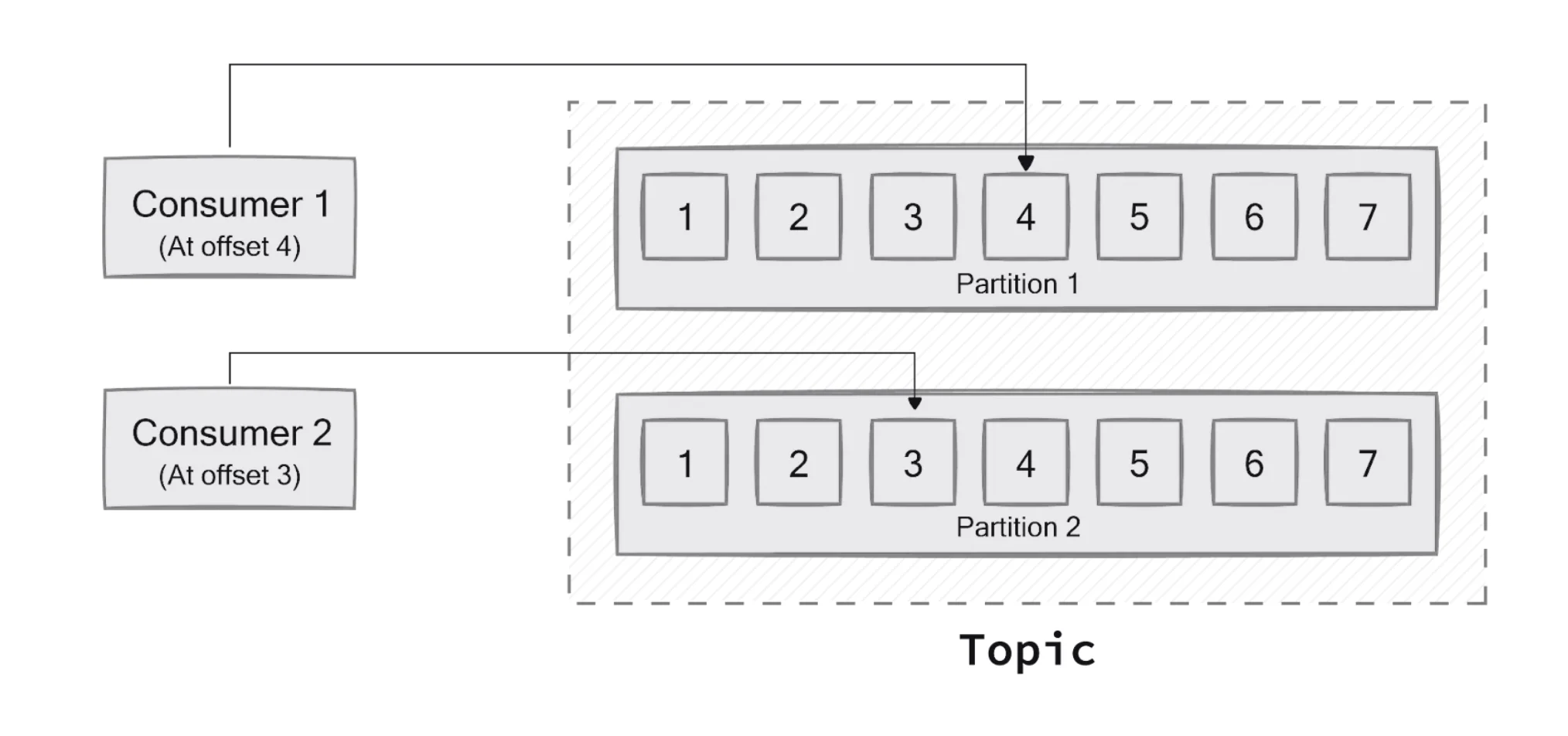
A Kafka offset is a sequential identifier assigned to each message within a partition of a Kafka topic. It marks the position up to which a consumer has read in a particular partition, acting as a unique identifier for each record within that partition. Essentially, the offset allows consumer event processing to start or continue from where it left off, serving as a bookmark that tracks a consumer's progress through the data stream.
In Kafka's architecture, topics are divided into partitions, and each message in a partition receives a unique, sequential offset number. This offset starts at 0 by default, though it can be manually specified to start at a different value. The offset position of a consumer represents the offset of the next record that will be provided to the application, which is typically one larger than the highest offset the consumer has processed in that partition.
The Importance of Offsets in Kafka
Offsets play a crucial role in Kafka's reliability, scalability, and fault-tolerance mechanisms. They enable consumers to resume reading from where they left off in case of failures or restarts, ensuring that no message is processed more than once or missed entirely. This capability is essential for implementing exactly-once processing semantics, which is critical for many business applications.
By maintaining offset information, Kafka ensures reliable data processing even in distributed environments where failures are inevitable. If a consumer application experiences an outage, the offset allows it to selectively process only the events that occurred during the downtime. This mechanism contributes significantly to Kafka's reputation as a durable and reliable messaging system.
Furthermore, offsets facilitate scalability and parallelism in Kafka by allowing multiple consumers to process messages concurrently. Each consumer maintains its own offset for each partition, enabling independent processing. This distributed approach allows for horizontal scaling, where additional consumers can be added to increase processing capacity while ensuring workload is evenly distributed.
How Kafka Manages Offsets
Storage Mechanisms
Kafka has evolved its approach to storing consumer offsets over time:
-
Zookeeper Storage (Pre-0.9) : In older versions of Kafka (pre-0.9), offsets were exclusively stored in Zookeeper.
-
Kafka Topic Storage (0.9 and later) : In newer versions, offsets are stored by default in an internal Kafka topic called
__consumer_offsets. This approach offers several advantages:-
Reduces dependency on Zookeeper
-
Simplifies the overall architecture by having clients communicate only with brokers
-
Improves scalability for large deployments with many consumers
-
Provides better performance as committing offsets is the same as writing to a topic
-
-
External Storage : Offsets can also be managed in external systems such as databases, offering more control over the offset management process but requiring additional synchronization logic.
The __consumer_offsets topic is compacted, meaning Kafka periodically removes old records to maintain only the most recent offset values for each partition. The brokers also cache the offsets in memory to serve offset fetches quickly.
Consumer Groups and Offset Tracking
Kafka organizes consumers into consumer groups, where each group collectively processes messages from one or more topics. Within a group, each consumer is assigned a unique set of partitions, and offsets are managed per partition to ensure parallel processing without overlap.
The group coordinator (a designated broker for each consumer group) manages the offset commits and stores them in the __consumer_offsets topic. When a consumer group sends an OffsetCommitRequest, the coordinator appends the request to this special topic and responds with success only after all replicas have received the offsets.
Offset Commit Strategies
Kafka provides two primary strategies for committing offsets:
Automatic Offset Commits
The automatic commit strategy is the simplest setup, where offsets are committed automatically at regular intervals specified by the auto.commit.interval.ms property (default: 5000ms). While convenient, this approach can lead to potential data loss if the consumer fails before the commit occurs, as messages processed after the last commit would be processed again upon restart.
For example, if a consumer processes 100 messages but crashes before the next automatic commit, those 100 messages would be reprocessed when the consumer restarts.
Manual Offset Commits
Manual commits offer greater control by allowing the consumer to decide precisely when to commit offsets, reducing the chance of data loss or duplicate processing. There are two primary methods for manual commits:
-
Synchronous Commits (
commitSync\()): Blocks the consumer until the commit succeeds or fails, providing stronger guarantees but potentially impacting throughput. -
Asynchronous Commits (
commitAsync\()): Non-blocking, allowing the consumer to continue processing while the commit happens in the background, improving throughput at the cost of potentially weaker consistency guarantees.
Manual offset management is generally recommended for production environments where data loss must be minimized. By committing offsets only after successfully processing messages, applications can ensure at-least-once message delivery semantics.
Offset Reset Behavior
When a consumer starts up and has no initial offset or when an existing offset is out of range (for example, if the data has been deleted due to retention policies), Kafka needs to determine where to start reading messages. This behavior is controlled by the auto.offset.reset configuration parameter, which accepts the following values:
-
earliest : Instructs the consumer to start reading from the beginning of the topic (the earliest available offset). This is useful for data recovery or reprocessing scenarios.
-
latest : Directs the consumer to start reading only new messages that arrive after it starts. This is the default setting.
-
none : Throws an exception to the consumer if no previous offset is found, requiring explicit handling.
Understanding this setting is crucial, especially for new consumer groups or when recovering from failures, as it directly impacts which messages will be processed.
Offset Retention and Expiration
Kafka maintains offsets for consumer groups for a configurable period, after which they expire and are removed. The default retention period for consumer offsets is controlled by the offsets.retention.minutes broker configuration, which was changed from 1 day (1440 minutes) in Kafka 2.0 to 7 days (10080 minutes) in later versions.
If a consumer group has no active consumers for the duration of this retention period, its offsets will be removed. When the consumer group restarts after its offsets have been deleted, it will behave as if it has no previous offsets and will follow the auto.offset.reset policy.
This behavior can lead to unexpected situations where consumers either reprocess old messages or miss messages entirely, depending on the configured reset policy.
Managing and Resetting Offsets
There are several approaches to managing and resetting consumer offsets:
Command Line Tools
The kafka-consumer-groups.sh tool provides a straightforward way to view and reset offsets from the command line:
kafka-consumer-groups --bootstrap-server <kafkahost:port> --group <group_id> --topic <topic_name> --reset-offsets --to-earliest --executeThis command resets all offsets for the specified consumer group to the earliest available offsets.
Consumer API
The Kafka Consumer API offers programmatic control over offsets through methods like seek() , which allows positioning the consumer at a specific offset within a partition.
Management Interfaces
Tools like Confluent Control Center and Conduktor provide graphical interfaces for managing offsets:
-
Stop the applications running on the consumer group
-
Select the desired reset strategy (earliest, latest, specific timestamp, etc.)
-
Apply the changes
-
Restart the applications
Monitoring Consumer Lag
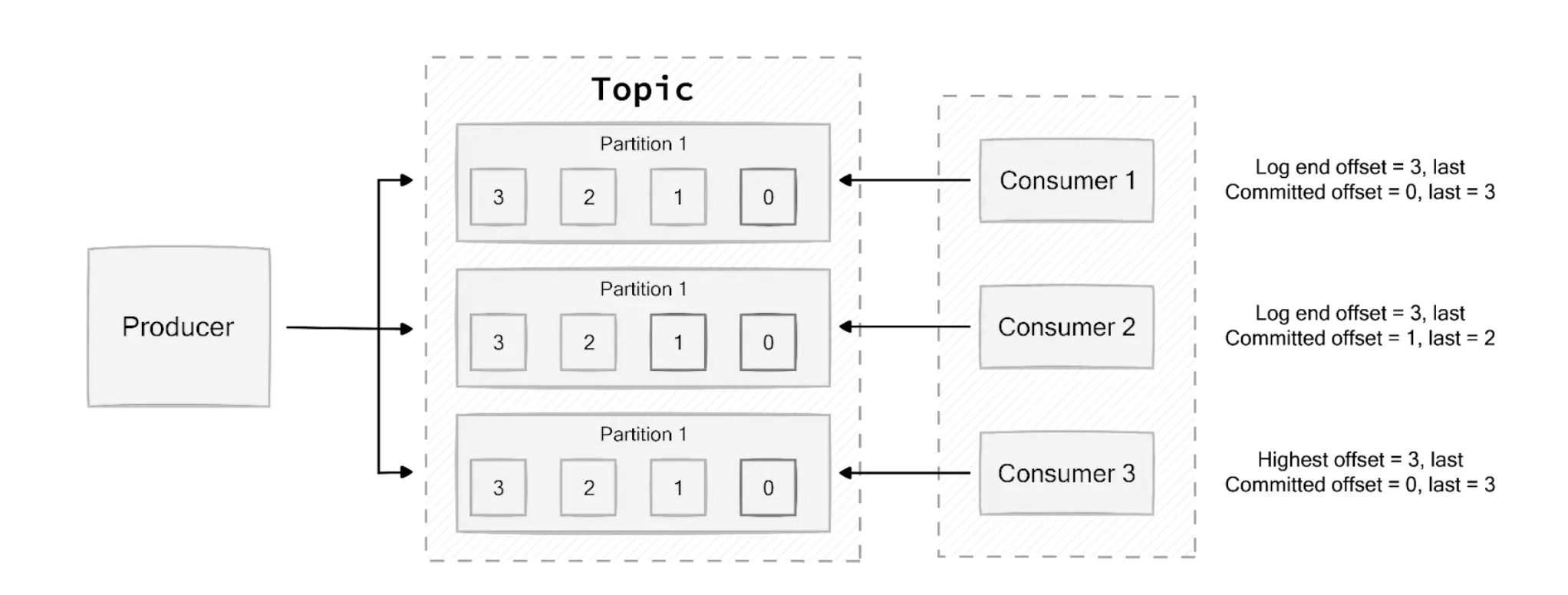
Consumer lag is a critical metric that indicates the delay between message production and consumption. It represents the number of messages that are waiting to be consumed and is calculated as the difference between the latest offset in a partition and the last committed offset for a consumer group.
High consumer lag can indicate performance issues, misconfigured consumers, or insufficient consumer resources. Monitoring this metric is essential for ensuring the smooth operation of a Kafka cluster.
Tools for monitoring consumer lag include:
-
JMX Metrics : Kafka exposes consumer lag metrics through JMX, which can be collected by monitoring tools like Prometheus.
-
Confluent Control Center : Provides visualizations of consumer lag and latency.
-
Burrow : An open-source tool designed specifically for monitoring Kafka consumer lag.
-
Kafka Consumer Groups Tool : The command-line utility provides information about consumer groups, including lag:
kafka-consumer-groups.sh --bootstrap-server <broker> --describe --group <group-id>Common Offset-Related Issues and Troubleshooting
OffsetOutOfRangeException
This exception occurs when a consumer tries to fetch messages from an offset that doesn't exist in the partition. This can happen if:
-
The offsets requested have been deleted due to retention policies
-
The topic was recreated, resetting all offsets
-
The consumer is incorrectly configured
To resolve this issue, reset the consumer group offsets to a valid position or adjust the auto.offset.reset configuration.
Offset Commit Failures
Commit failures can occur due to network issues, broker unavailability, or rebalancing operations. When using manual commits, it's important to handle these failures appropriately, potentially with retry logic for synchronous commits or callbacks for asynchronous commits.
Lost Offsets After Broker Restart
When restarting a Kafka broker, it's important to understand that simply restarting isn't enough to remove offsets. The backing volume that stores the contents of the __consumer_offsets topic must also be deleted if a complete reset is desired.
Best Practices for Offset Management
Production Environment Recommendations
-
Disable Auto-Commit in Critical Applications : For applications where data loss is unacceptable, disable auto-commit (
enable.auto.commit=false) and implement manual commit strategies after successful processing. -
Commit Frequency Considerations : Balance commit frequency based on your requirements. Too frequent commits may impact performance, while infrequent commits increase the risk of reprocessing in case of failures.
-
Error Handling : Implement robust error handling for offset commits, especially when using manual commit strategies.
-
Monitoring : Continuously monitor consumer lag to identify potential issues early and ensure smooth operation.
Configuration Best Practices
-
Appropriate
auto.offset.resetValue : Choose based on your application requirements -earliestfor data completeness,latestfor processing only new data. -
Sufficient
offsets.retention.minutes: Ensure the retention period is appropriate for your recovery needs, especially for consumers that run periodically rather than continuously. -
Tune
max.poll.records: Set this value based on your processing capacity to optimize throughput without causing excessive lag. -
Consider
max.poll.interval.ms: Increase this value for applications that take longer to process batches to prevent unnecessary rebalances.
Conclusion
Kafka offsets are a cornerstone of Apache Kafka's architecture, enabling reliable, scalable, and fault-tolerant data processing. They provide the mechanism for consumers to track their progress through the data stream, ensuring exactly-once processing semantics even in the face of failures.
Understanding how offsets work, how they're stored, and how to manage them effectively is crucial for building robust Kafka-based applications. By implementing the best practices outlined in this guide and carefully configuring offset-related parameters, you can ensure optimal performance, reliability, and data integrity in your Kafka deployment.
Whether you're implementing simple streaming applications or complex event-driven architectures, mastering Kafka offsets is essential for harnessing the full power of this distributed streaming platform.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


