The integration of Apache Kafka with Kubernetes creates a powerful platform for scalable, resilient streaming applications. This comprehensive blog explores the deployment strategies, architectural considerations, and best practices for running Kafka on Kubernetes, drawing from industry expertise to address common challenges and optimize performance.
Understanding Kafka on Kubernetes Architecture
Apache Kafka has become a cornerstone for building robust, scalable, and reliable data streaming platforms. When deployed on Kubernetes, Kafka leverages the container orchestration capabilities to enhance its scalability and availability. The fundamental architecture of Kafka on Kubernetes involves several key components working together to ensure high performance and resilience.
At the core of this architecture are Kafka brokers, which are responsible for storing and managing data streams. Each broker receives and stores specific data partitions and serves them upon request. These brokers are typically deployed as StatefulSets in Kubernetes, which provide stable, unique network identifiers, persistent storage, and ordered deployment and scaling.
Traditionally, Kafka relied on ZooKeeper for metadata management and coordination. ZooKeeper maintains information about topics, brokers, partitions, and consumer groups. However, the introduction of KRaft (Kafka Raft) has simplified this architecture by integrating metadata coordination directly into Kafka brokers, eliminating the need for a separate ZooKeeper ensemble. This streamlined approach reduces operational overhead and improves efficiency.
The networking aspect of Kafka on Kubernetes requires special attention. Kubernetes distributes network traffic among multiple pods of the same service, but this approach doesn't work optimally for Kafka. Clients often need to reach the specific broker that hosts the leader of a partition directly. To address this, headless services are used to give each pod running a Kafka broker a unique identifier, facilitating direct communication.
Deployment Methods and Options
Using Helm Charts for Kafka Deployment
Helm charts provide a package manager approach for deploying Kafka on Kubernetes. They allow defining, installing, and managing complex Kubernetes applications using pre-configured packages called charts. The deployment process typically involves:
-
Setting up a Kubernetes cluster with sufficient resources
-
Installing Helm and adding the required repositories
-
Configuring deployment values
-
Deploying Kafka using the Helm chart
For example, to add Confluent's Helm repository:
helm repo add confluentinc <https://packages.confluent.io/helm> helm repo updateAnd to deploy Kafka using Bitnami's chart:
helm install my-kafka bitnami/kafkaUsing Kafka Operators
Operators take Kubernetes management to a higher level by incorporating domain-specific knowledge to automate complex operations. Unlike Helm charts which primarily handle installation, operators provide continuous management throughout the application lifecycle.
Several Kafka operators are available:
-
Strimzi Kafka Operator - An open-source Kubernetes operator for Apache Kafka
-
Confluent Operator - Provides enterprise-grade Kafka deployment and management
-
KUDO Kafka - Offers out-of-the-box optimized Kafka clusters on Kubernetes
Operators handle advanced tasks like broker failover, scaling, updates, and monitoring, reducing the operational burden significantly. For instance, the Strimzi operator can be deployed using Helm:
helm repo add strimzi <https://strimzi.io/charts/> helm install my-strimzi-operator strimzi/strimzi-kafka-operatorManual Deployment with Kubernetes Resources
For those who need more control, manual deployment using native Kubernetes resources is possible. This approach typically involves:
-
Creating network policies for Kafka communication
-
Deploying ZooKeeper as a StatefulSet
-
Creating ZooKeeper services
-
Deploying Kafka brokers as StatefulSets
-
Creating Kafka headless services
This method provides the most flexibility but requires deeper understanding of both Kafka and Kubernetes internals.
Best Practices for Kafka on Kubernetes
Using Separated Storage and Compute in Kafka for Better Operations and Scaling
Kubernetes is primarily designed for cloud-native stateless applications. The main challenge of running Kafka on Kubernetes lies in its architecture that couples compute and storage, with strong dependency on local disks. This makes Kafka difficult to manage and scale on Kubernetes. With the continuous evolution of the Kafka ecosystem, you can now choose next-generation storage-compute separated Kafka solutions like AutoMQ. AutoMQ is built entirely on S3, with complete separation of compute and storage. The stateless Broker significantly reduces the management complexity of Kafka on Kubernetes.
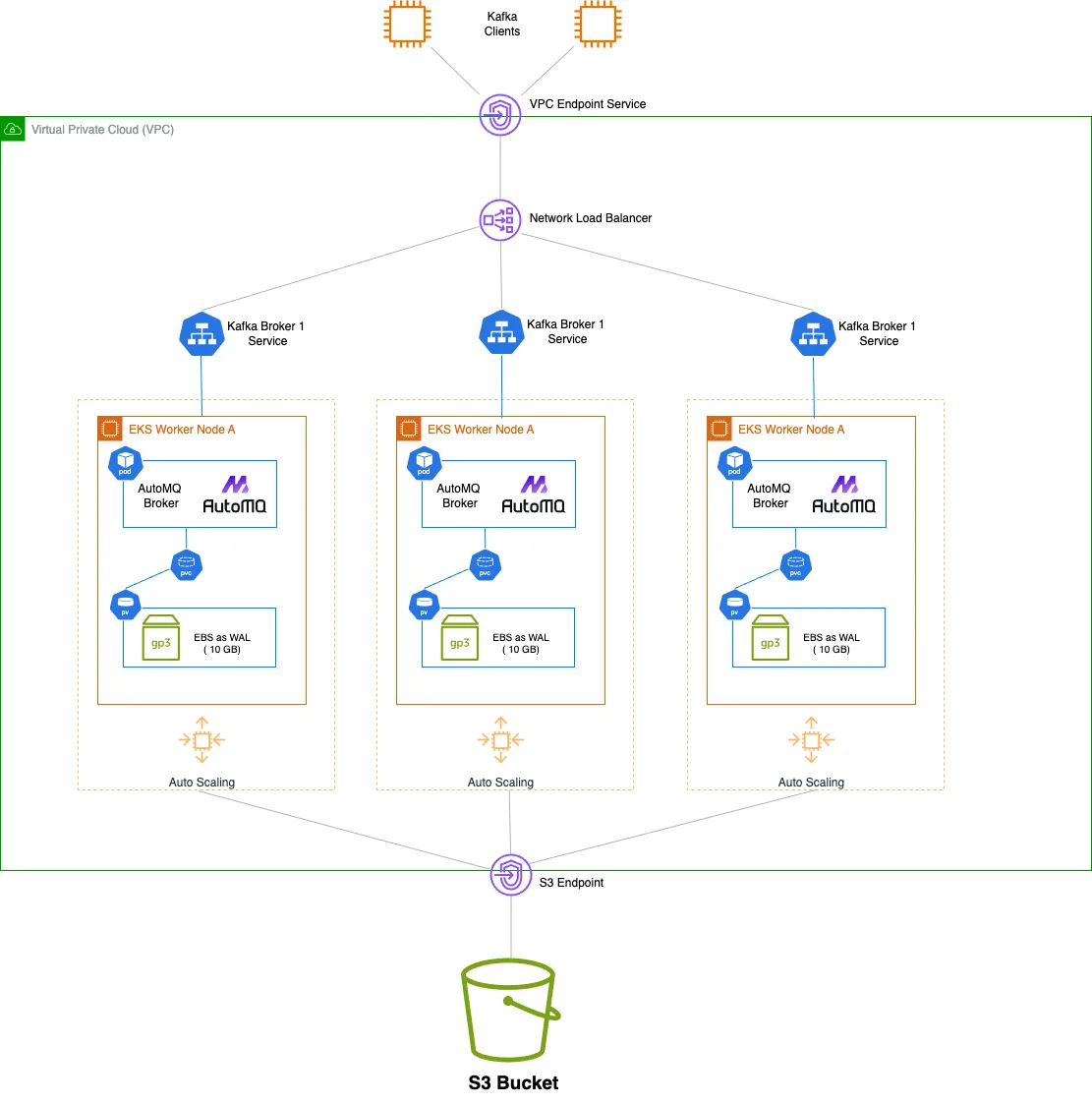
High Availability Configuration
For fault tolerance and high availability, several strategies should be implemented:
-
Deploy Kafka brokers across multiple availability zones to protect against zone failures
-
Configure a replication factor of at least 2 or more for each partition to ensure data durability
-
Use pod anti-affinity rules to distribute Kafka brokers across different nodes
-
Implement proper leader election strategies to minimize downtime during failures
Kubernetes adds an additional layer of availability by automatically recovering failed pods and placing them on new nodes. Configuring liveness and readiness probes, Horizontal Pod Autoscaler (HPA), and implementing cluster auto-scaling improves the durability of Kubernetes-based Kafka clusters even further.
Resource Management and Performance Tuning
Proper resource allocation is critical for Kafka performance on Kubernetes:
-
Set appropriate CPU and memory requests and limits in Kubernetes manifests to prevent resource contention
-
Configure JVM heap size according to available container memory (typically 50-70% of container memory)
-
Adjust producer settings like batch size, linger time, and compression to optimize throughput
-
Optimize consumer configurations including fetch size and max poll records
It's important to note that Kafka relies heavily on the filesystem cache for performance. On Kubernetes, where multiple containers run on a node accessing the filesystem, this means less cache is available for Kafka, potentially affecting performance.
Storage Configuration
Kafka's performance and reliability depend significantly on storage configuration:
-
Use persistent volumes for data retention to maintain data across pod rescheduling
-
Select appropriate storage class based on performance requirements
-
Consider volume replication for faster recovery after node failures
-
Implement proper storage monitoring to detect and address issues proactively
When a Kafka broker fails and moves to another node, access to its data is critical. Without proper storage configuration, the new broker might need to replicate data from scratch, resulting in higher I/O and increased cluster latency during the rebuild.
Network Configuration and Connectivity
Networking is perhaps the most challenging aspect of running Kafka on Kubernetes:
-
Use headless services for broker discovery within the cluster
-
Configure advertised listeners correctly for both internal and external communication
-
Address the "bootstrap server" challenge for external clients
-
Consider using NodePort or LoadBalancer services for external access
A common challenge occurs when a producer outside the Kubernetes cluster attempts to connect to Kafka brokers. The broker might return internal Pod IPs that aren't accessible externally, or return no IP at all. Solutions include properly configuring external access through services and correctly setting up advertised listeners.
Security Implementation
Security for Kafka on Kubernetes should be implemented at multiple levels:
-
Encrypt data in transit using TLS/SSL
-
Implement authentication using SASL or mutual TLS
-
Configure authorization with Access Control Lists (ACLs)
-
Use Kubernetes secrets for credential management
-
Implement network policies to control traffic flow
Kafka clusters should be isolated within private networks, with strict firewall rules limiting inbound and outbound traffic. Only necessary ports should be exposed, and all communication should be encrypted.
Common Challenges and Solutions
Running Apache Kafka directly on Kubernetes presents several challenges. To address these issues, we recommend following best practices and considering next-generation solutions like AutoMQ, which use storage-compute separation and shared storage architecture.
Managing Stateful Workloads on Kubernetes
Running stateful applications like Kafka on Kubernetes presents unique challenges:
-
Ensuring persistent identity and storage for Kafka brokers
-
Handling pod rescheduling without data loss
-
Managing upgrades without service disruption
To address these challenges, use StatefulSets and Headless services. StatefulSets provide stable identity for each pod, ensuring that if a pod is rescheduled, it gets the same IP as before. This is crucial because the address on which clients connect to brokers should remain consistent.
Handling Scaling Operations
Scaling Kafka on Kubernetes requires careful planning:
-
Properly configure partition reassignment during scaling to redistribute load
-
Manage leader rebalancing to prevent performance degradation
-
Plan for increased network traffic and disk I/O during scaling operations
When increasing or decreasing the number of brokers, ensure that partitions are redistributed evenly to maintain balanced load across the cluster.
Monitoring and Troubleshooting
Effective monitoring is essential for maintaining healthy Kafka clusters on Kubernetes:
-
Implement comprehensive metrics collection using tools like Prometheus and Grafana
-
Monitor key metrics including broker health, consumer lag, and partition status
-
Set up alerts for critical conditions
-
Collect and analyze logs for troubleshooting
Common troubleshooting areas include connectivity issues between Kafka and monitoring tools, configuration problems, and resource constraints.
Pod scheduling affects Kafka's performance
Apache Kafka's impressive throughput and performance rely heavily on its Page Cache implementation. Since containers don't virtualize the operating system kernel, when Pods move between Nodes, the Page Cache must be re-warmed, degrading Kafka's performance. This impact is particularly noticeable during peak business periods. As a result, Kafka users concerned about performance impacts on their business become reluctant to allow Kafka Broker Pods to move freely between Nodes. However, when Pods can't move quickly and freely between Nodes, it significantly reduces Kubernetes' scheduling flexibility and prevents full utilization of its orchestration advantages. The figure below illustrates how disk reads from an un-warmed Page Cache affect Kafka performance during Broker Pod movement.
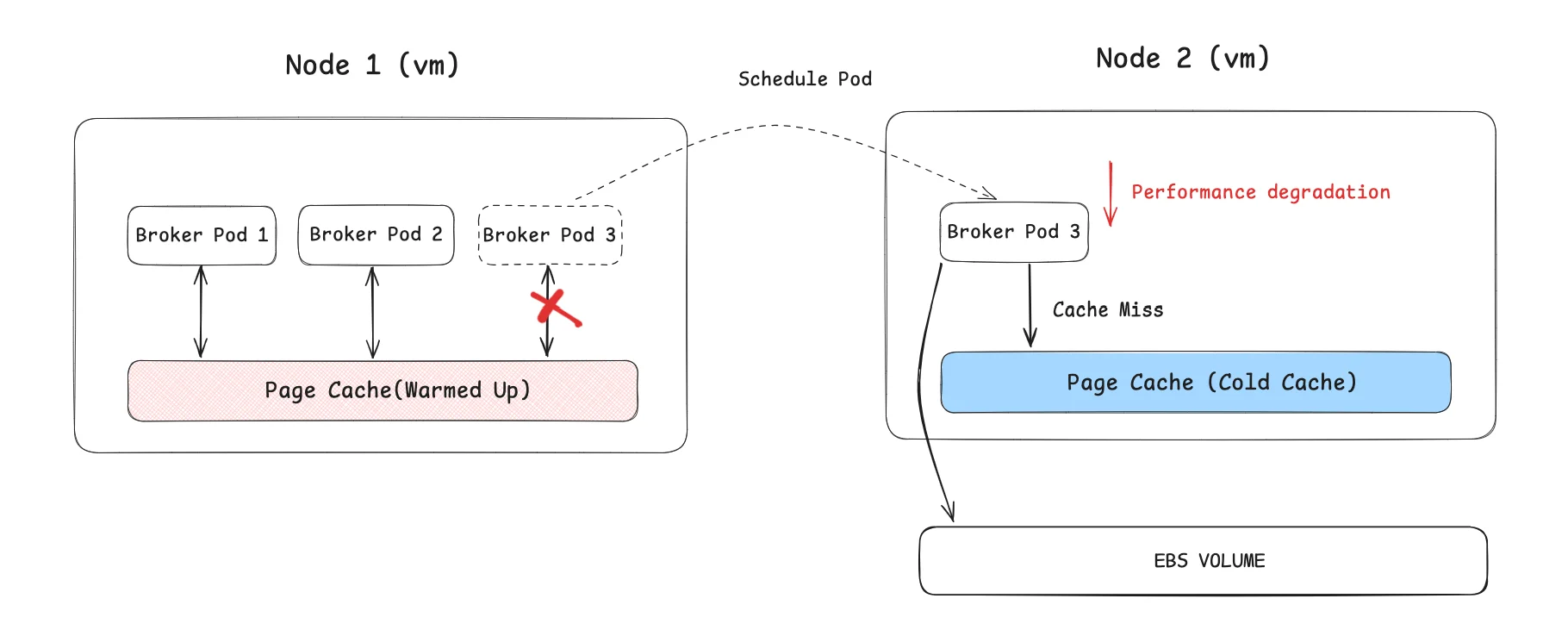
Conclusion: Choosing the Right Approach
Deploying Kafka on Kubernetes offers significant benefits in terms of scalability, resilience, and operational efficiency. However, it requires careful planning and consideration of various factors including deployment method, resource allocation, networking, and storage.
The choice between using Helm charts or operators depends on specific requirements:
-
Operators provide more sophisticated management with automation of day-to-day operations, making them suitable for production environments with complex requirements
-
Helm charts offer simplicity and flexibility, giving more control over the configuration but requiring more manual management
Regardless of the deployment method chosen, following best practices for high availability, performance tuning, and security will ensure a robust Kafka deployment that can handle the demands of modern streaming applications. By understanding the unique challenges of running Kafka on Kubernetes and implementing appropriate solutions, organizations can build reliable, scalable streaming platforms that drive their data-intensive applications.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


