Kafka Streams is a powerful client library that enables developers to build applications and microservices where both input and output data reside in Apache Kafka clusters. Unlike traditional stream processing systems that require separate processing clusters, Kafka Streams integrates directly within Java applications and standard microservices architectures, making it highly accessible for developers already working within the Kafka ecosystem.
At its foundation, Kafka Streams operates on several fundamental concepts that form the basis of its architecture and functionality.
Streams and Tables
Streams in Kafka Streams represent a sequence of data records, where each record constitutes a self-contained datum in an unbounded dataset. Streams are particularly effective for representing events or changes occurring over time, enabling applications to process data continuously as it arrives. For example, in an IoT scenario, sensor readings create a continuous flow of data that can be processed as a stream.
Tables, on the other hand, function as snapshots that capture each key's latest value at any given moment. They act like continuously updated records of the most current state of each key, analogous to a database table but backed by Kafka topics that store the table's change log. This duality allows Kafka Streams to handle both real-time data streams and maintain the current state of data objects.
Stream-Table Duality
The stream-table duality is a core concept that recognizes the complementary nature of streams and tables. Every stream can be viewed as a table, and every table can be viewed as a stream of changes. This duality creates a flexible framework for data handling and processing that accommodates various use cases and processing patterns.
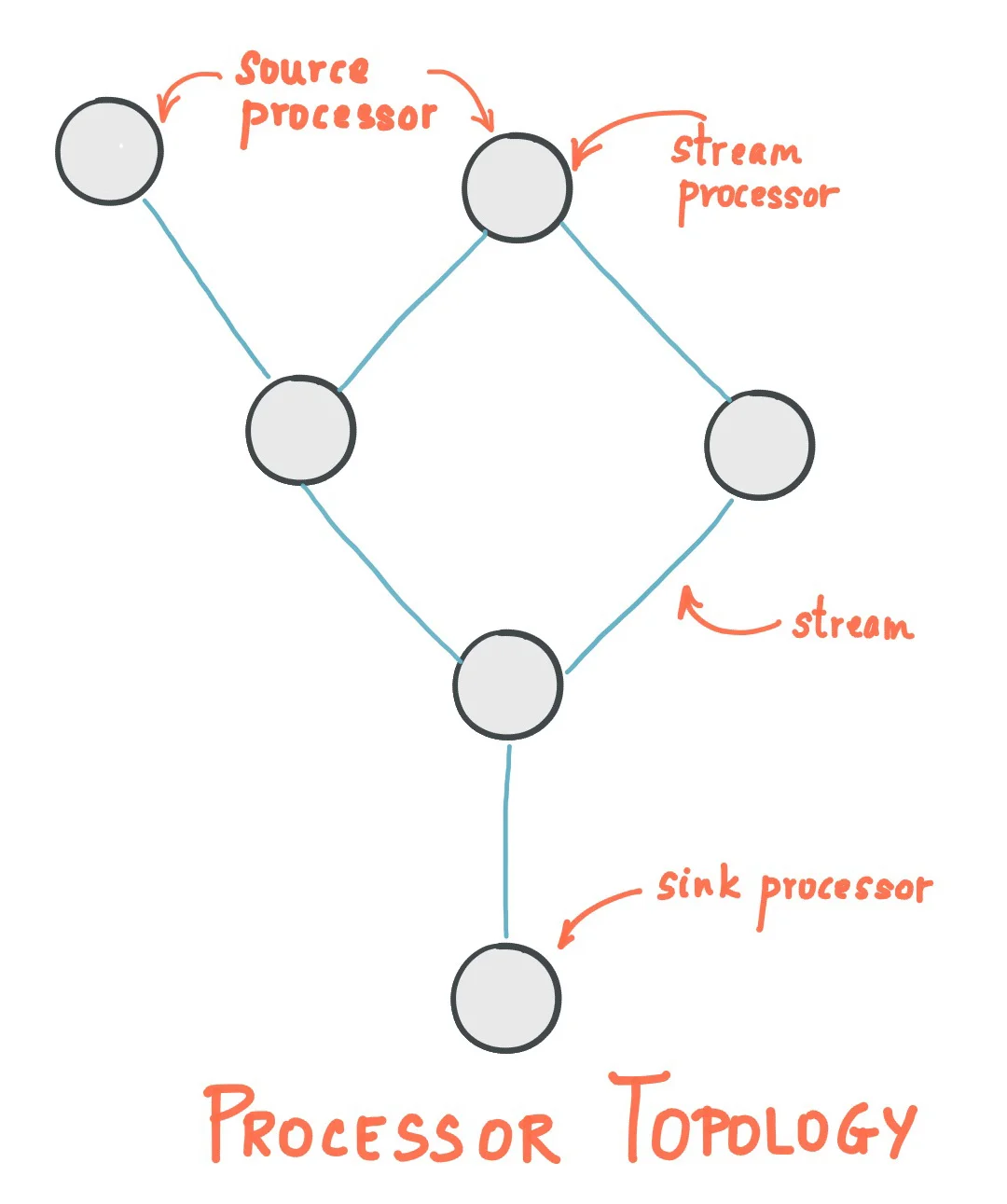
Processor Topology
A processor topology defines the stream processing computational logic for an application, specifying how input data transforms into output data. A topology is essentially a graph of stream processors (nodes) connected by streams (edges). There are two special types of processors within any topology:
-
Source Processors: Special processors without upstream processors that produce input streams from one or multiple Kafka topics.
-
Sink Processors: Special processors without downstream processors that send records from upstream processors to specified Kafka topics.
Kafka Streams offers several distinguishing features that make it a powerful tool for stream processing.
Time Windowing and Aggregation
Kafka Streams supports windowing operations to group data records by time intervals, which is essential for time-based aggregations and processing. It offers various window types including tumbling windows, hopping windows, and session windows, each serving different use cases.
Session windows, for example, are dynamically sized windows created based on periods of activity. They close when there is a timeout of inactivity, making them ideal for analyzing user activity sessions within applications.
Stateful Operations
Kafka Streams maintains local state stores for stateful processing without requiring external dependencies. This enables complex operations like joins, aggregations, and windowed computations to be performed efficiently within the application.
Fault Tolerance and Scalability
Kafka Streams automatically handles failures and supports scaling out of the box, ensuring data is processed reliably in a distributed manner. The architecture is designed to recover from failures gracefully, resuming processing from where it left off using Kafka's built-in mechanisms.
Exactly-Once Processing
Kafka Streams guarantees that each record will be processed exactly once, which is crucial for accurate computations and analytics. This is achieved through Kafka's transactional capabilities and the careful management of processing state.
Kafka Streams simplifies application development by building on the Apache Kafka producer and consumer APIs while leveraging Kafka's native capabilities to offer data parallelism, distributed coordination, fault tolerance, and operational simplicity.
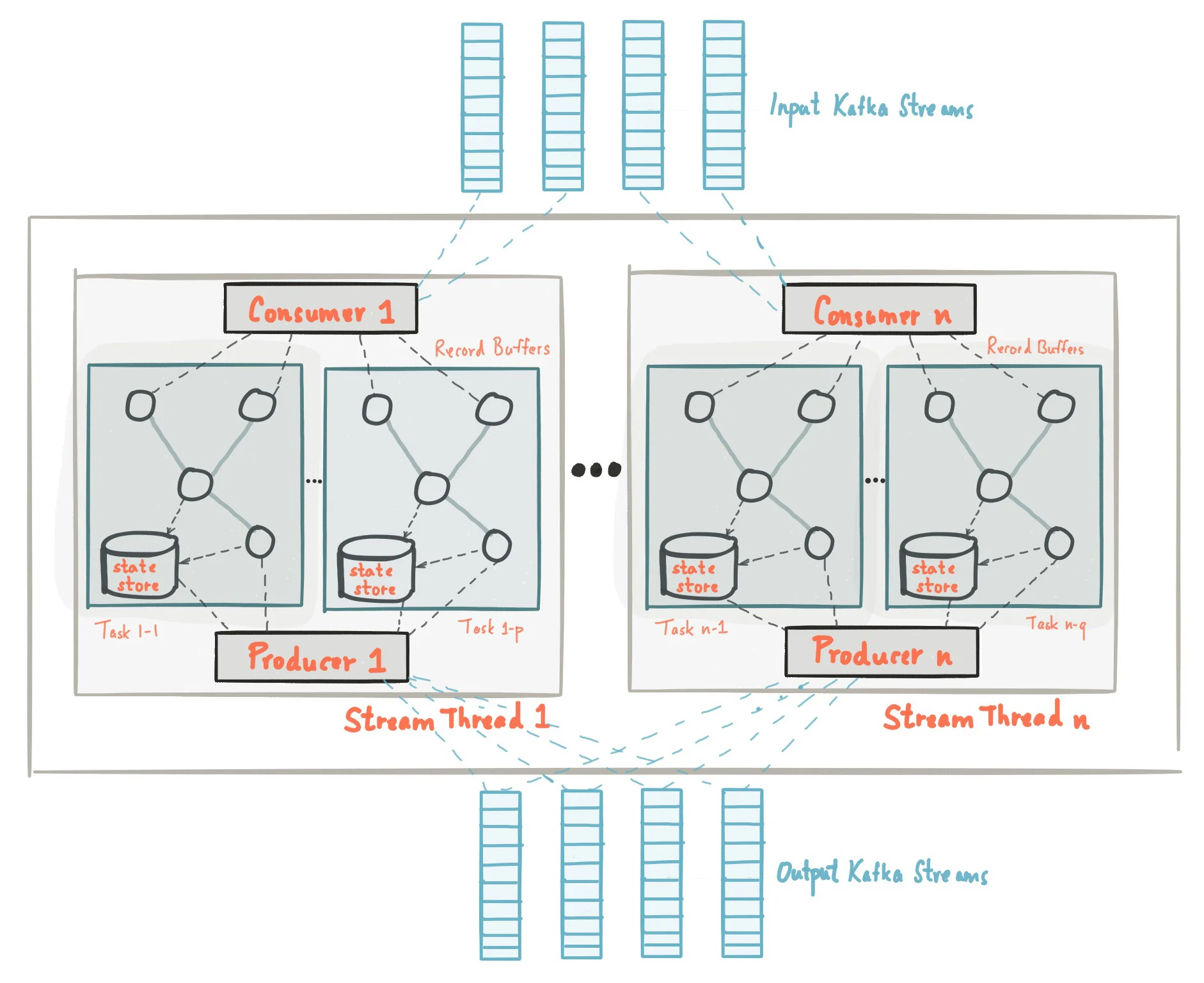
Architecture Overview
A Kafka Streams application contains multiple stream threads, each containing multiple stream tasks. The processor topology defines how these components interact to process data.
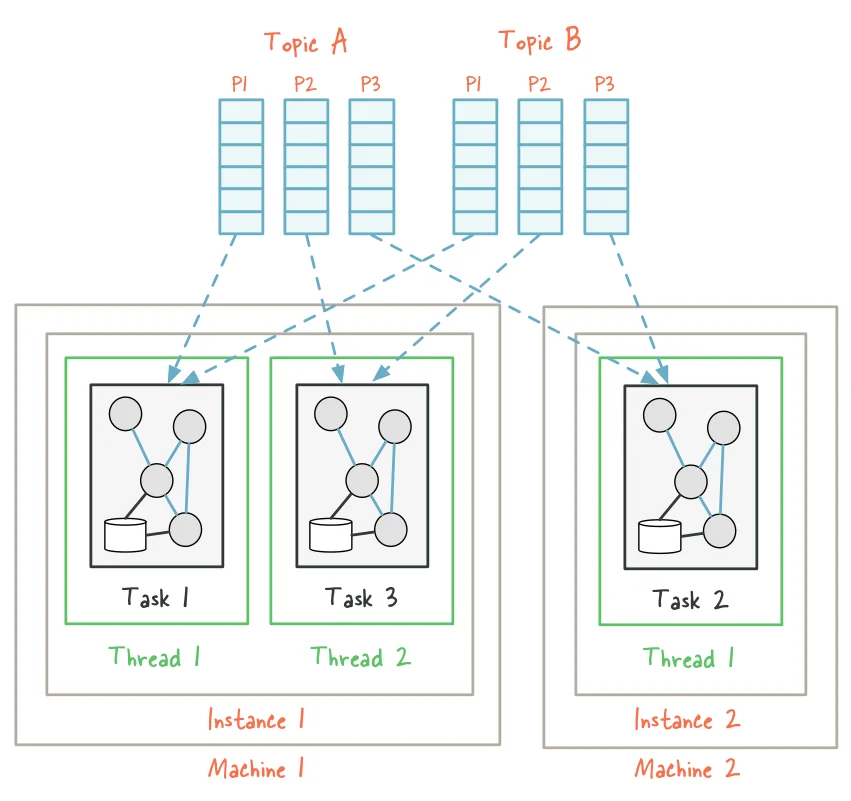
Parallelism Model
Kafka Streams achieves parallelism through its architecture, where stream processors are distributed across multiple instances of an application. Each instance processes a subset of the partitions, allowing for horizontal scaling as demand increases.
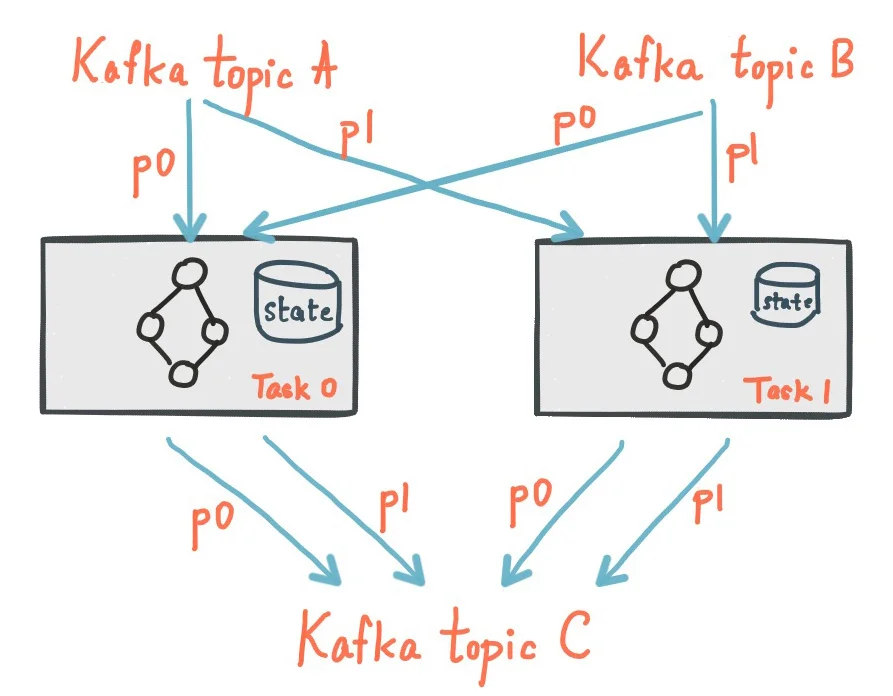
State Management
State in Kafka Streams is maintained locally for performance but is backed by changelog topics in Kafka for durability and fault tolerance. This dual approach ensures that state can be quickly accessed during normal operation while allowing for recovery in case of failures.
Setting up Kafka Streams requires configuring several key parameters to ensure optimal performance and reliability.
Essential Configuration Parameters
-
application.id: An identifier for the stream processing application that must be unique within the Kafka cluster. It serves as the default client-id prefix, group-id for membership management, and changelog topic prefix. -
bootstrap.servers: A list of host/port pairs for establishing the initial connection to the Kafka cluster. -
num.stream.threads: Determines the number of threads available for parallel processing. Increasing this value can improve throughput by allowing the application to process multiple partitions concurrently. -
state.dir: Specifies the directory location for state stores. This path must be unique for each streams instance sharing the same underlying filesystem. -
cache.max.bytes.buffering: Controls the maximum number of memory bytes to be used for buffering across all threads.
Performance-Related Settings
-
commit.interval.ms: Determines how frequently the processor commits its state. Lower values provide more frequent updates but may impact performance. -
batch.sizeandlinger.ms: For producers, these control the batching of records for improved throughput. -
rocksdb.config.setter: Allows customization of RocksDB, the default state store used by Kafka Streams, for performance optimization.
Implementing best practices can significantly enhance the performance, reliability, and maintainability of Kafka Streams applications.
State Store Management
Customize the configuration of RocksDB to improve performance by adjusting parameters like cache size and write buffer. Consider using in-memory state stores for smaller datasets to achieve faster access and lower latency.
Stream Thread Management
Increase the number of stream threads to parallelize processing by setting the num.stream.threads property. This allows the application to process multiple partitions concurrently. Additionally, consider isolating critical streams or processes into separate threads to ensure heavy processing loads do not impact the entire application.
Serde Optimization
Implement custom serialization and deserialization (Serde) for complex data types to reduce serialization overhead. Where possible, reuse Serde instances across the application to save on the overhead of Serde initialization.
Effective Partitioning
Design topics with scalability in mind by choosing a partition count that supports throughput requirements without over-partitioning, which can lead to unnecessary resource usage. Use repartitioning carefully, as it allows for greater parallelism but introduces additional overhead and complexity in the data flow.
Error Handling
Kafka Streams provides native capabilities for handling exceptions from deserialization errors. You can configure the application to use one of three handlers:
-
LogAndContinueExceptionHandler: Logs the error and continues processing the next records. -
LogAndFailExceptionHandler: Logs the error and fails (default behavior). -
Custom DLQ Handler: Sends erroneous records to a Dead Letter Queue topic for later analysis and processing.
Even with best practices in place, Kafka Streams applications may encounter several common issues.
Performance Optimization
If a Kafka Streams application is performing slowly, consider these remedies:
-
Adjust batch sizes and linger time to balance throughput and latency requirements.
-
Implement compression to reduce data size and improve network utilization.
-
Review and optimize partitioning strategies for even data distribution.
-
Tune the
cache.max.bytes.bufferingsetting to control memory usage.
Graceful Shutdown and Recovery
Implementing proper shutdown and recovery mechanisms is crucial for maintaining data integrity:
-
Handle shutdown signals appropriately by intercepting shutdown hooks and calling the
KafkaStreams.close\()method. -
Configure proper recovery settings to ensure the application can resume processing from where it left off after a restart.
-
Set up appropriate monitoring to detect and respond to failures quickly.
Monitoring and Alerts
Effective monitoring is essential for identifying issues before they become critical:
-
Monitor consumer lag to detect processing delays.
-
Track resource utilization (CPU, memory, disk) to identify bottlenecks.
-
Set up alerts for critical metrics exceeding thresholds.
-
Use tools like Conduktor for comprehensive monitoring and visualization6.
Kafka Streams can be applied to various real-world scenarios:
Word Count and Analysis
A classic example involves counting word occurrences in text streams, useful for analytics and natural language processing applications.
Fraud Detection
Streaming applications can analyze transaction data in real-time to identify potentially fraudulent activities based on patterns and anomalies.
IoT Data Processing
IoT sensors generate vast amounts of data that can be processed, filtered, and analyzed in real-time using Kafka Streams.
User Activity Tracking
Session windows allow for analysis of user behavior within applications, providing insights into engagement patterns and potential improvements.
Integration with Other Technologies
Kafka Streams integrates well with:
-
Spring Boot: For building microservices that process streaming data.
-
Redpanda: An Apache Kafka API-compatible system that offers performance improvements over traditional Kafka setups.
-
Confluent Platform: Provides additional enterprise features and support for Kafka Streams applications.
Kafka Streams offers a powerful, flexible framework for building real-time stream processing applications integrated directly within your application code. By understanding its core concepts, configuration options, and best practices, developers can create robust, scalable solutions for a wide range of use cases.
As organizations continue to adopt event-driven architectures, Kafka Streams provides a streamlined approach to building applications that process and react to data as it arrives, without the complexity of managing separate processing clusters. With its strong integration with the broader Kafka ecosystem, it remains a compelling choice for developers working with streaming data.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


