Prerequisites
This document provides examples for deploying a 5-node AutoMQ cluster. In this setup, 3 nodes will run both the Controller and Broker, while the other 2 nodes will run only the Broker. Please ensure the following conditions are met:- Prepare a Kubernetes cluster with at least 5 nodes, recommending network-optimized virtual machines with 4 cores and 16GB of RAM for subsequent Pod creation and other operations.
- Helm chart requires version v3.8.0 or later. Refer to the Helm Chart Quickstart.
- Utilize the Bitnami Helm repository. AutoMQ is fully compatible with Bitnami’s Helm Charts, enabling you to customize the AutoMQ Kubernetes cluster using Bitnami’s values.yaml.
- Prepare 2 object storage buckets: one for storing message data and another for storing system logs and metric data.
Deploy AutoMQ Cluster
Step 1: Edit the Configuration File
Create an emptyautomq-values.yaml file, edit it, and add specific parameters. For guidance, refer to demo-values.yaml and check recommended configuration examples for different scenarios in its subdirectories. For more details, consult the README.md.
-
Substitute
${ops-bucket},${data-bucket},${region}, and${endpoint}with specific values for object storage. For more details, refer to Object Storage Configuration▸. -
Replace
${access-key}and${secret-key}with the actual values. You can also choose alternative authorization methods such as IAM Role. - For production-grade deployments, it is recommended to use dedicated nodes for AutoMQ (to avoid network bandwidth and other resource competition with other Pods). It is advisable to match using node affinity (nodeAffinity) and tolerations tags.
-
For multi-availability zone deployments, you can use the
topologySpreadConstraintsparameter to ensure Pods are evenly distributed across the specified availability zones.
- To avoid cross Availability Zone traffic,
brokerRackAssignmentwill ultimately set the AutoMQ Broker’sbroker.rack. Clients need to be configured accordingly to eliminate cross-Availability Zone traffic costs. For example, the following configuration can be used in AWS EKS:
- Several other server-side parameters can be set as needed in
controller.extraConfigandbroker.extraConfig. For more details, please refer to: Broker And Controller Configuration▸.
Step 2: Install AutoMQ
Install or upgrade the AutoMQ Helm Chart using a custom YAML file: It is recommended to use the--version flag to specify the Bitnami Helm Chart version 31.x.x (31.1.0 ~ 31.5.0) when installing AutoMQ.
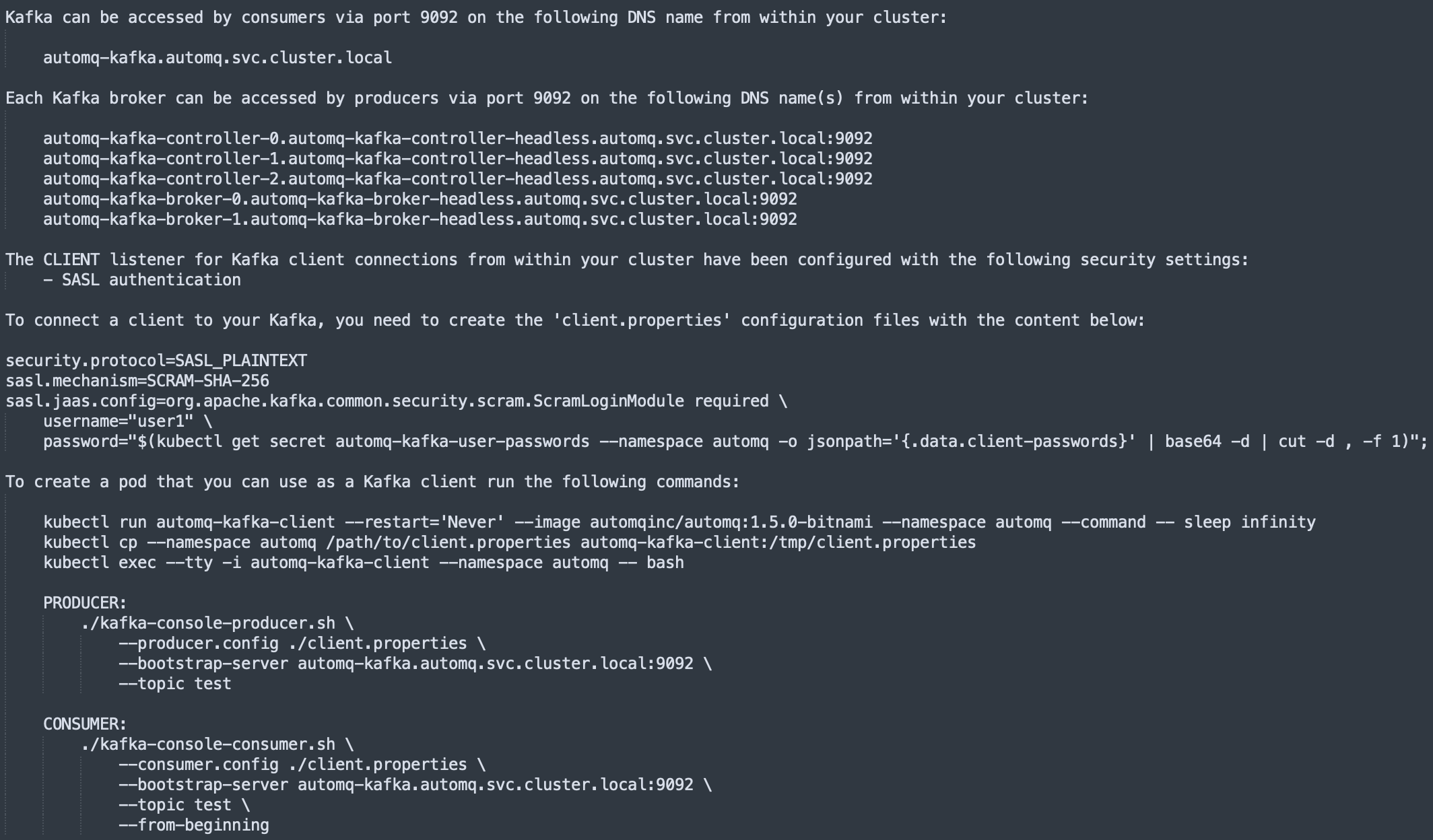
Test Message Sending and Receiving:
After the Helm execution is complete, the access address for the cluster and the commands for testing message sending and receiving will be displayed. This allows you to perform Topic message sending and consumption tests usingkafka-console-producer.sh and kafka-console-consumer.sh.
Stop and Uninstall the AutoMQ Cluster:
- After completing the tests, AutoMQ clusters can be stopped and uninstalled using
helm uninstall.
- If historical data is no longer needed, it’s necessary to delete the cluster’s PVC and Bucket data altogether to prevent leftover data from affecting the next deployment.
Precautions for Production Environment
Lock Chart Version
To avoid unexpected changes during deployment, it is recommended to lock the Helm Chart version. Locking the version means specifying an exact version at deployment instead of using the latest or unspecified version. Locking the Helm Chart version aids in:- Ensure Compatibility: Make sure the application’s performance in the deployed environment aligns with its behavior during testing, even if new Chart versions are released.
- Prevent Unintended Updates: Prevent automatic updates that may introduce changes incompatible with your current deployment or operational practices.
Name Override
When deploying multiple instances of the same Helm Chart within a Kubernetes cluster, name conflicts may occur. UsenameOverride and fullnameOverride to distinguish between different instances. For example, using distinct names for your production and staging environments can help avoid confusion.
-
Using
nameOverride, the StatefulSet name will be<release-name>-<nameOverride>. -
Using
fullnameOverride, the StatefulSet name will be<fullnameOverride>.
Docker Image
Bitnami provides the Docker image for AutoMQ deployment, with the default image beingbitnami/kafka:latest. You should replace it with a custom AutoMQ image specifying a particular version:
Scheduling Strategy
For AutoMQ, a refined scheduling strategy in Kubernetes can be implemented using node affinities and tolerations. We suggest that a production-level AutoMQ operates exclusively without co-locating with other applications. It is advisable to tailor label matching rules based on node types:Tolerance
It is recommended to add a taint to the Kubernetes node group:key: "dedicated", operator: "Equal", value: "automq", effect: "NoSchedule".
Node Affinity
Override the default values in the controller/broker configuration to match the node labels (e.g.,node-type: m7g.xlarge):
Pod Anti-affinity
Ensure that the controller component and the broker component are not scheduled on the same node by using thepodAntiAffinity parameter:
Scaling
Controller
The number of instances is configured throughcontroller.replicas, which supports horizontal scaling. By default, the cluster deploys 3 Controller Pods, but users can customize the number of Controller replicas.
Note: Once the cluster deployment is complete, adjusting the replicas for the Controller is not recommended to avoid unexpected risks.
Broker
The number of instances is configured throughbroker.replicas, which supports horizontal scaling.
AutoScaling (HPA)
HPA is disabled by default. To enable it, you can configure parameters inbroker.autoscaling.hpa:
Note: We do not recommend configuring Controller HPA because the Controller in Kafka KRaft mode relies on the Raft protocol to maintain metadata consistency, which does not support automated Raft membership changes. Therefore, configuring Controller HPA could lead to quorum failure or make the cluster unavailable.
Resource Configuration
It is recommended that each Pod for AutoMQ runs on resources of 4Core16GB. Adjust resource parameters through the following configurations:Security and Authentication
Each listener configured in Kafka can have a different authentication protocol. For instance, you can usesasl_tls authentication for client communications and tls for inter-Controller and Broker communications. The table below lists available protocols and their security features (see more details in Kafka Security Authentication):
| Method | Authentication Method | Encrypted via TLS |
|---|---|---|
| plaintext | None | No |
| tls | None | Yes |
| mtls | Yes (Mutual Authentication) | Yes |
| sasl | Yes (via SASL) | No |
| sasl_tls | Yes (via SASL) | Yes |