Enable Inter-Zone Routing
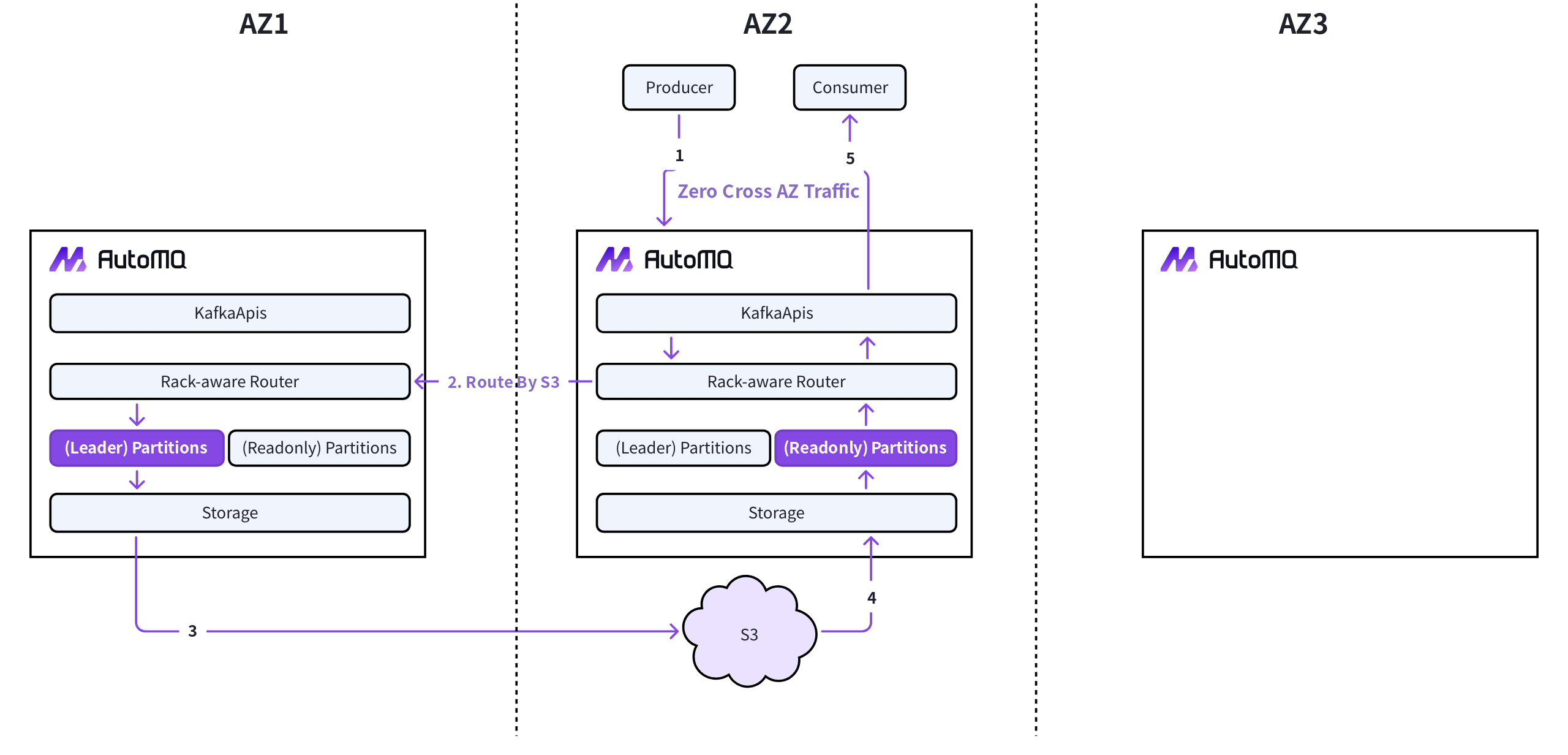
In clouds that charge fees for Inter-Zone traffic (such as AWS), configureautomq.zonerouter.channels to enable Inter-Zone routing functionality. Once this feature is enabled, clients will connect only to AutoMQ nodes within the same zone for Produce and Consume operations. For example, in the diagram below, assume that a client in AZ2 wants to consume a partition located in AZ1:
- For Producers: AutoMQ in AZ2 will act as a proxy node for AutoMQ in AZ1, forwarding the Produce request via the Rack-Aware Router to AutoMQ in AZ1.
- For Consumers: AutoMQ in AZ2 will directly read the already written data from S3 and return it to the client.
automq.zonerouter.channels is as follows:
- Channel connection details:
$bucket?region=$region[&endpoint=$endpoint][&pathStyle=$enablePathStyle][&authType=$authType][&accessKey=$accessKey][&secretKey=$secretKey]bash - Channel Batching Settings: By default, the Proxy node batches Produce requests every 250ms (
batchInterval=250) or when 8MiB (maxBytesInBatch=8388608) of data is accumulated, routing them to the Main node. Increasing the configured value reduces the cost of S3 API calls but increases Inter-Zone write latency. Conversely, setting a smaller value increases S3 API call costs but decreases Inter-Zone write latency.
Configuration Mapping Rules to Identify the Originating CIDR of the Client in the Rack
Due to the limitations of the Kafka protocol, the server cannot detect the specific rack a client belongs to. To address this issue and prevent cross-availability zone production and consumption, AutoMQ offers Client Configuration▸ as well as server-based rack configuration options. This section introduces a server-based dynamic configuration method,automq.zone.cidr.blocks.
The configuration format for automq.zone.cidr.blocks is as follows:
-
Configurations for different zones are separated by
< >. -
Each zone’s configuration starts with the zone identifier, followed by
@as a delimiter, and then the current zone’s CIDR list. CIDRs in the list are separated by,.
kafka-config.sh. A sample command is as follows:
automq.zone.cidr.blocks is ideal for situations where:
- The Zones where Clients reside have distinct CIDR ranges.
- Computational engines such as Flink, Spark, Presto, etc., face challenges in setting different Client configurations based on the Zone handling the load.
client.id > automq.zone.cidr.blocks > Consumer client.rack.