
前置条件
腾讯云环境使用 AutoMQ Table Topic 功能,需要满足如下条件:- 版本约束: 要求 AutoMQ 实例版本 >= 1.4.1。
- 实例约束: 必须在创建 AutoMQ 实例时开启 Table Topic 特性,后续才可使用 Table Topic。实例一旦创建完成,后续无法再开启 Table Topic 功能。
- 资源要求: 在腾讯云上使用 Table Topic 必须提供可用的 Hive Catalog 服务。用户可以购买腾讯云托管的 EMR HMS 服务。
操作步骤
步骤 1:配置 Hive Catalog 服务
腾讯云上配置 Hive Catalog 可以自行搭建 Hive Metastore 服务,也可以购买腾讯云 EMR 托管的 HMS 服务。本文档以腾讯云托管的 EMR HMS 服务 为例,介绍配置方法。- 前往腾讯云 EMR 产品,购买集群,并开启 Kerberos 身份认证。
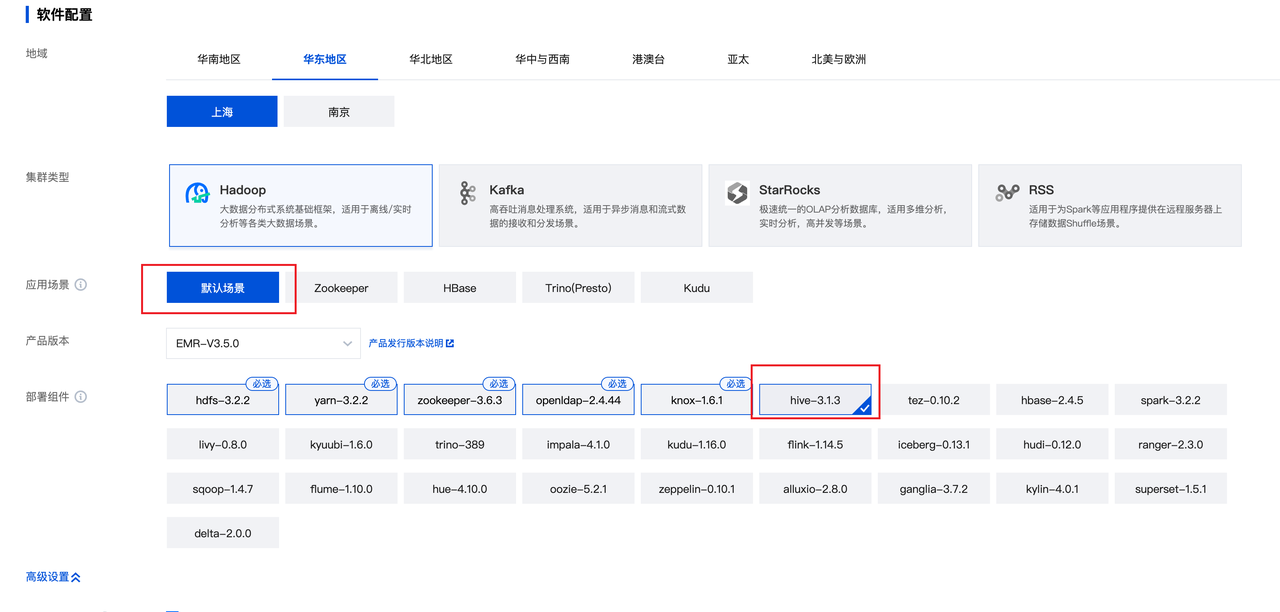
- 配置 HMS 环境变量设置脚本 hive-env.sh ,添加访问对象存储的 Jar。
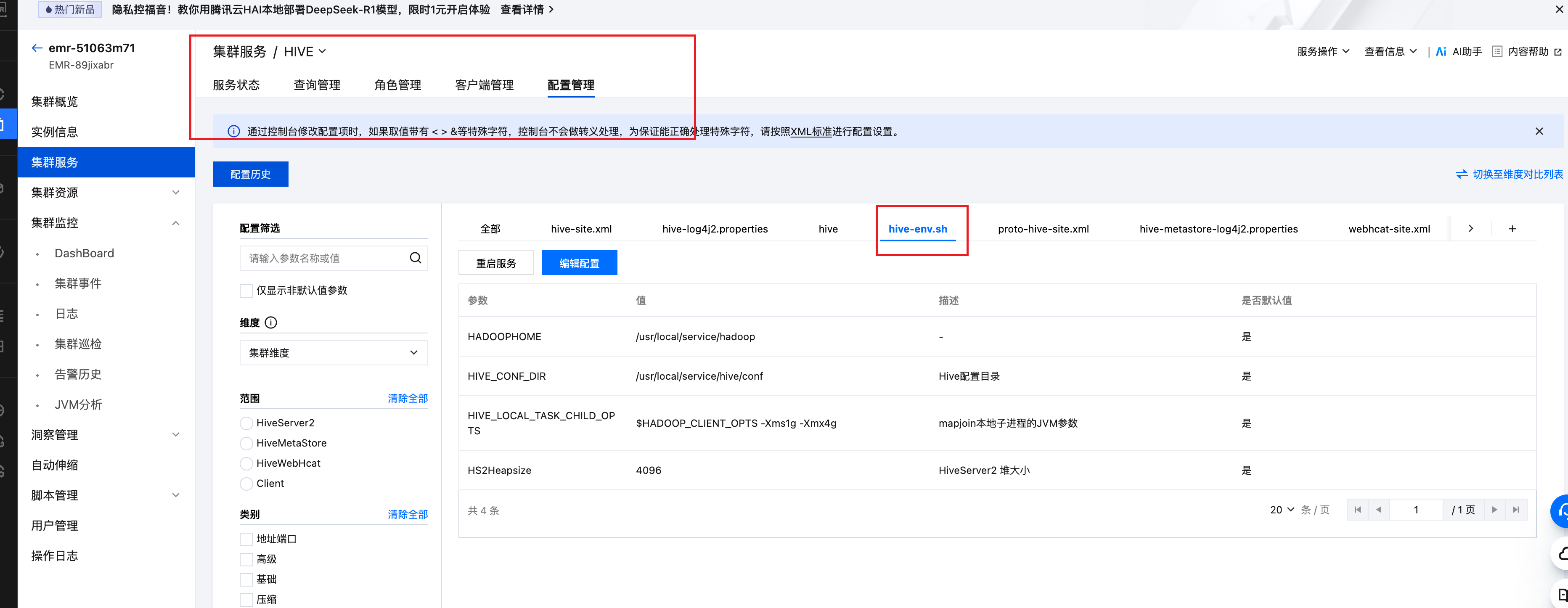
- 变更 hive-site.xml,添加以下对象存储访问相关配置。
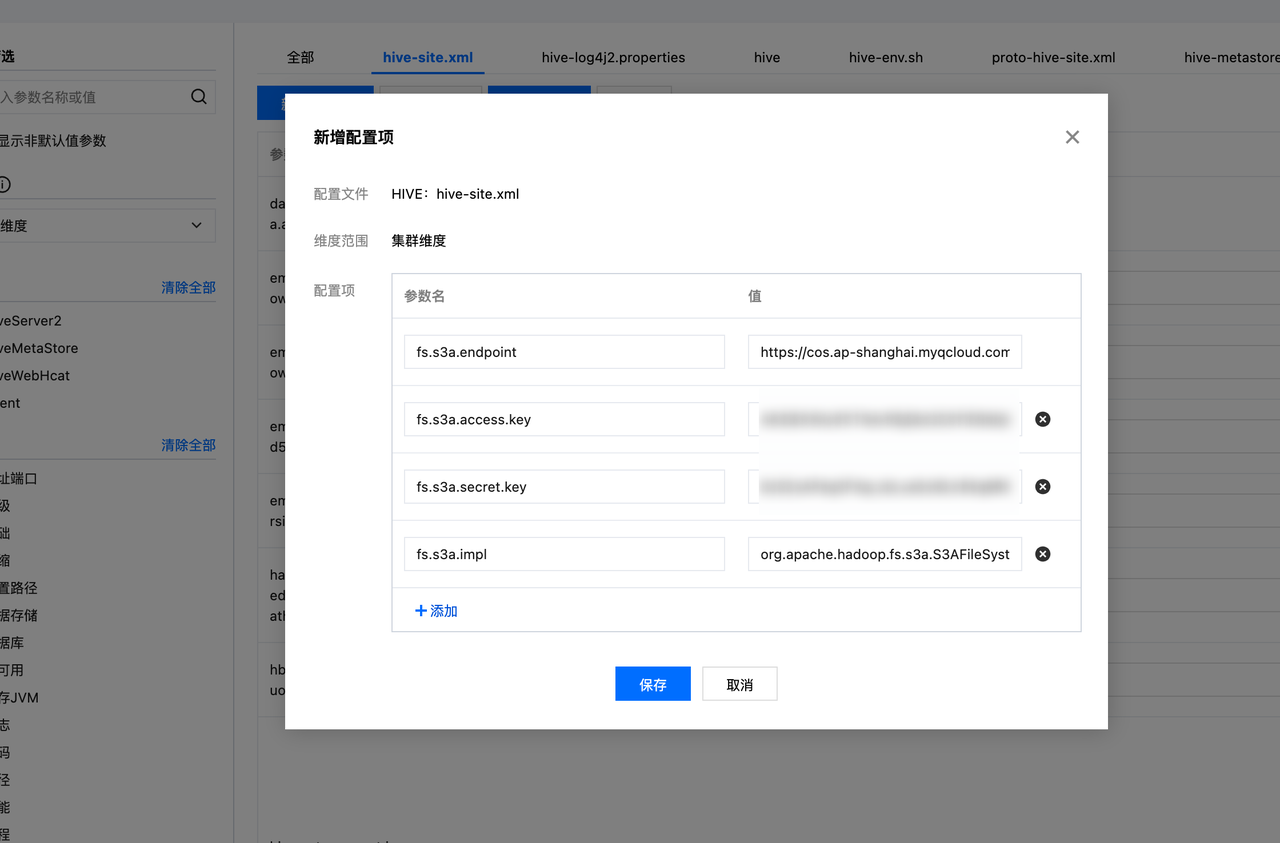
- 参数配置完成后,重启 Hive Metastore 服务,使得变更生效。
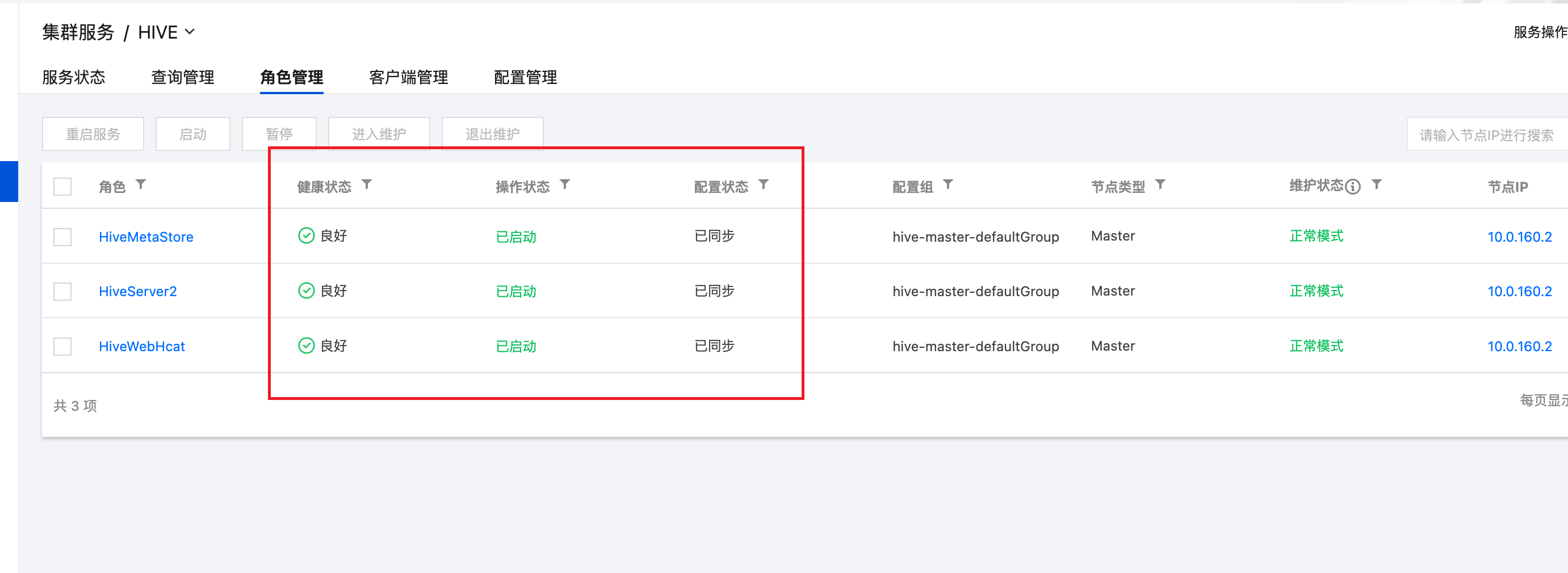
- (若未开启 Keberos 身份认证,则可跳过此步骤)添加 Keberos 用户,并导出身份认证相关配置。登录到 EMR Master 机器,并以 root 身份运行以下命令,生成身份鉴权相关配置文件。
-
(若未开启 Keberos 身份认证,则可跳过此步骤)进入 Hive 服务的配置管理页面,从
hive-site.xml文件中获取如下配置项的值:-
hive.metastore.uris,作为后续步骤中的 User Principal。 -
hive.metastore.kerberos.principal,作为后续步骤中的 Kerberos Principal。
-
步骤 2:创建 Hive Catalog 集成
Hive Catalog 服务创建完成后,需要前往 AutoMQ 控制台创建 Hive Catalog 集成,用于录入步骤 1 中配置的 Catalog 信息。操作说明如下:- 登录 AutoMQ 控制台,点击集成 菜单。
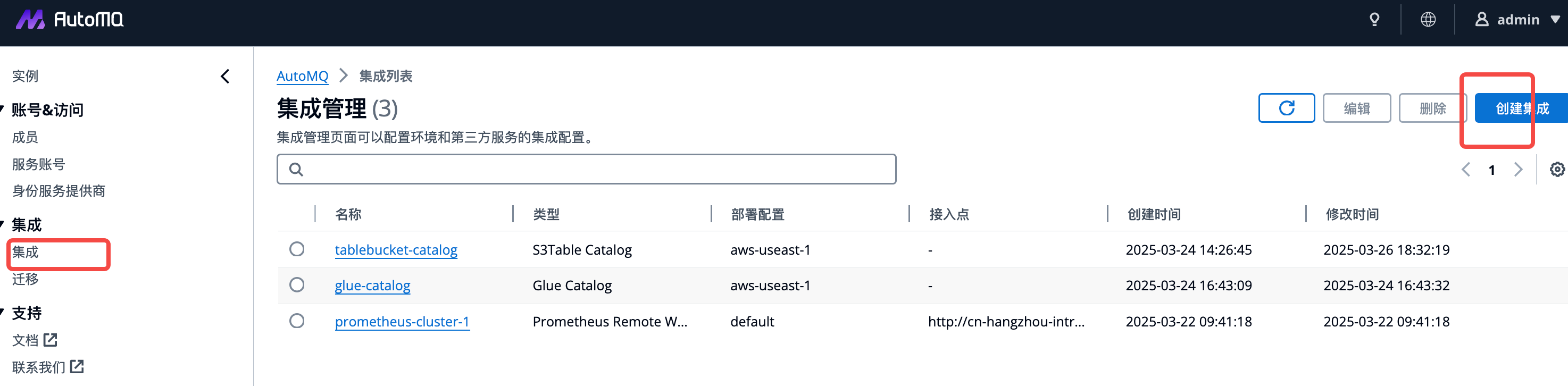
-
选择创建 Hive Catalog 集成 ,填写如下信息:
- 名称: 填写有区分度的集成配置名称。
- 部署配置: 选择集成归属的部署配置,需要后续创建实例保持一致。
- Hive Metastore 接入点: 配置 Hive Metastore 接入点,后续 AutoMQ 会访问该接入点查询 Data Catalog。
- 鉴权类型: 根据实际需求,选择 不鉴权 或者 Kerberos 鉴权。
- KeyTab 文件: 如果开启 Kerberos 鉴权,需要上传步骤 1 生成的 KeyTab 文件。
- Krb5.conf 文件: 如果开启 Kerberos 鉴权,需要上传步骤 1 生成的 Krb5.conf 文件。
- Kerberos User Principal: 如果开启 Kerberos 鉴权,需要填写步骤 1 获取的 User Principal。
- Kerberos Principal: 如果开启 Kerberos 鉴权,需要填写步骤 1 获取的 Kerberos Principal。
- Warehouse :填写数据湖使用的对象存储 Bucket,该 Bucket 用于长期存储数据。
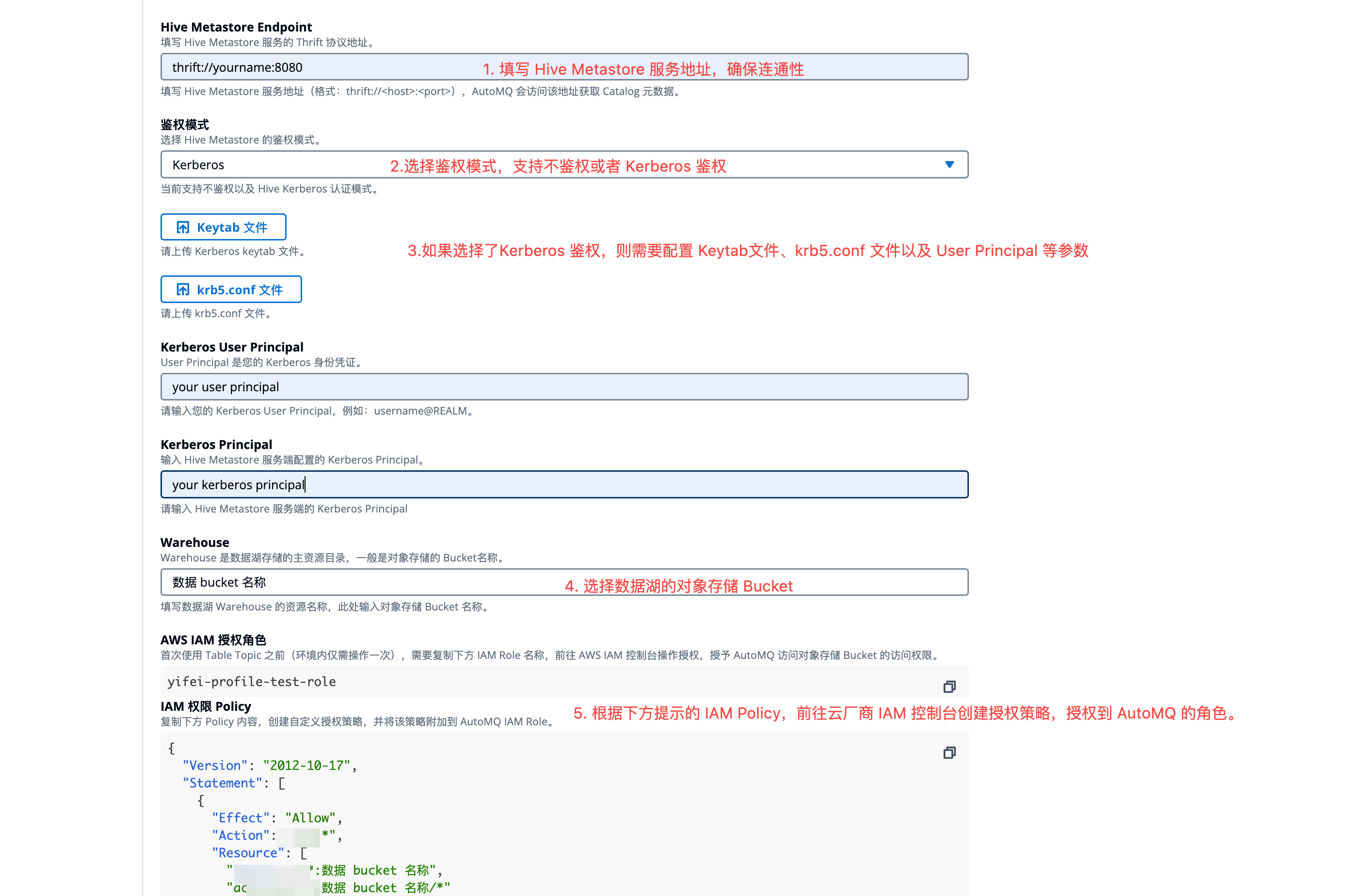
- 填写 Warehouse 参数后,AutoMQ 会生成访问该 Bucket 所需的 CAM Policy,并展示 AutoMQ 实例当前使用的 IAM Role。请前往云厂商 IAM 控制台,参考该 Policy 创建授权。
- 创建授权完成后,即可点击创建 Hive Catalog 集成。
步骤 3:创建 AutoMQ 实例,开启 Table Topic 功能
使用 AutoMQ Table Topic 功能需要在创建实例时提前开启,后续才可实现数据流式入湖。因此创建实例时需要参考下方说明配置: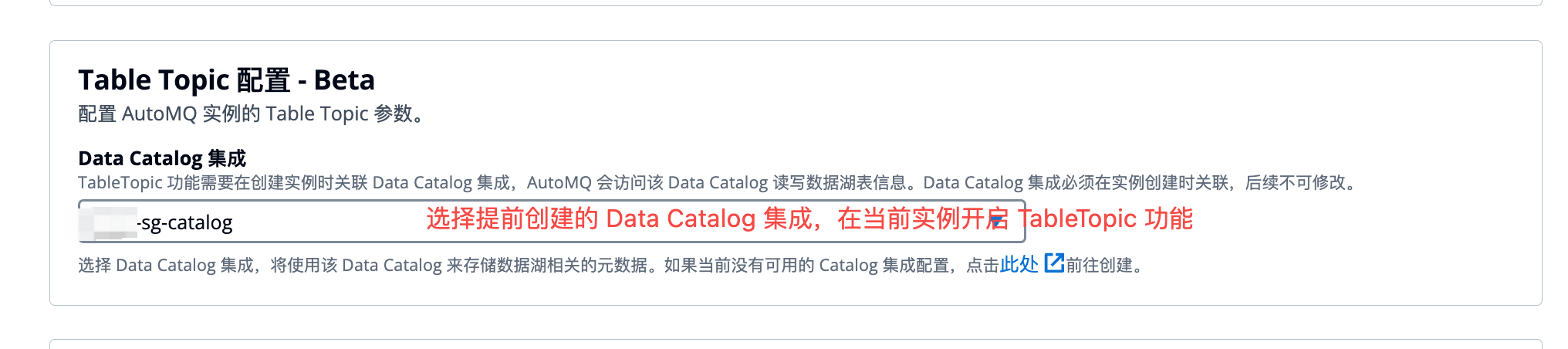
步骤 4:创建 Topic,并配置流转表
AutoMQ 实例开启 Table Topic 功能后,即可在创建 Topic 时按需配置流转表。具体操作如下:- 进入步骤 3 的实例,Topic 列表,点击创建 Topic 。
-
创建 Topic 的配置中,开启 Table Topic 转换,并配置如下参数:
- 命名空间: 命名空间用于隔离不同的 Iceberg 表,对应 Data Catalog 中的 Database。建议根据业务归属设置相应的参数值。
- Schema 约束类型: 设置 Topic 消息是否遵守 Schema 约束。如果选择Schema 则启用 Schema 约束,需要向 AutoMQ 内置 SchemaRegistry 注册消息 Schema,后续发送消息时严格按照 Schema,后续 Table Topic 会使用该 Schema 的字段填充 Iceberg 表;如果选择Schemaless ,则代表消息内容无明确 Schema 约束,此时会将消息 Key 和 Value 作为整体字段填充 Iceberg 表。
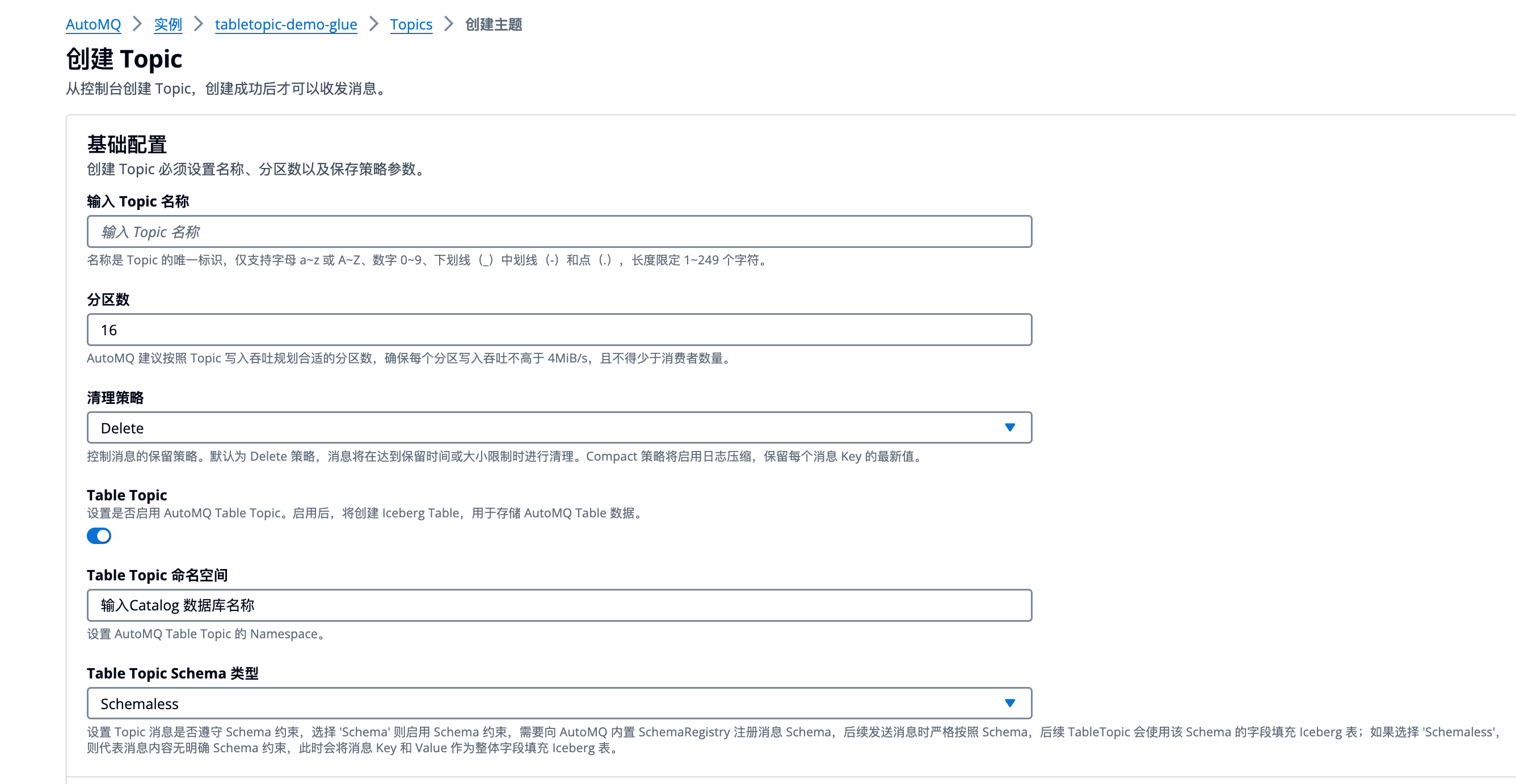
- 点击确定 ,创建支持流转表的 Topic。
步骤 5: 生产消息,通过 Spark-sql 查询 Iceberg 表数据
完成 AutoMQ 实例配置以及 Table Topic 创建后,即可测试生产数据,并在 Iceberg 表查询数据。- 点击进入 Topic 详情,生产消息 Tab,输入测试的消息 Key 和消息 Value,发送消息。
- 新增Spark组件,然后登陆到 EMR 集群的 Master 节点,切换到 hadoop 用户。
- 执行如下命令,进入 spark-sql。
- 执行SQL, 进行查询。可以看到 AutoMQ 实时将 Kafka 消息转换成对应数据表的数据记录。用户也可以使用其他查询引擎进行分析和计算。
