跳转到主要内容目前,业界有很多适配了 Apache Kafka 协议的产品,例如 Redpanda 和 Kafka on Pulsar,AutoMQ 认为从 0 开始适配 Kafka 协议的技术方案很难事无巨细地做到完全兼容,同时也会带来大量重复的,没有必要性的脑力工作。
目前 Kafka 协议有 113 个 ErrorCode、68 个 API,仅 Fetch API 就有 15 个版本,去实现 Kafka 协议和语义的 100% 兼容是极其困难的。并且后期随着 Apache Kafka 的发展,如何持续保持和 Kafka 协议的兼容也是一大挑战。
Kafka 的协议和语义的兼容性是用户选择 Kafka 产品的一个重要的考量,因此 AutoMQ 架构设计的前提就是必须 100% 兼容 Apache Kafka 的协议和语义,并且能持续的跟进和对齐 Apache Kafka。
Apache Kafka 协议现状
Apache Kafka 已经经过 10 多余年的发展,由 1000+ Contributors 共同贡献了 1059 个 KIP[1],整个代码库包含数十万行代码,沉淀了大量的功能特性、优化和修复。如果要从零开始构建一个 API 协议和语义兼容的 Kafka 不仅开发工作量大,并且极易出错。Apache Kafka 架构由计算层和存储层构成:
-
计算层:代码总量的 98%,承载了 Kafka 的 API 协议和功能特性。同时,计算层面向流存储有大量的系统性优化,比如端到端的 Batch 设计,零拷贝机制等,通过 2 核 CPU 就能支撑 1GiB/s 的流量;
-
存储层:代码总量的 2%,负责消息的高可靠存储。Apache Kafka 作为流处理管道会长期存储大量数据,Apache Kafka 集群成本的大部分是由数据存储成本和存算一体部署的机器成本组成。
AutoMQ 原生支持 Kafka 协议
AutoMQ 的目标是通过存算分离的架构将 Apache Kafka 升级为共享存储的架构,最优的解决方案就是替换 Kafka 的存储层,保留 Kafka 原生的计算层,这样做的优势在于:
-
既可以复用 98% Apache Kafka 计算层代码,保障 API 的协议 & 语义兼容和功能对齐;
-
又可以将存储层替换为云原生的存储服务,兑现共享存储和云原生的技术和成本红利。
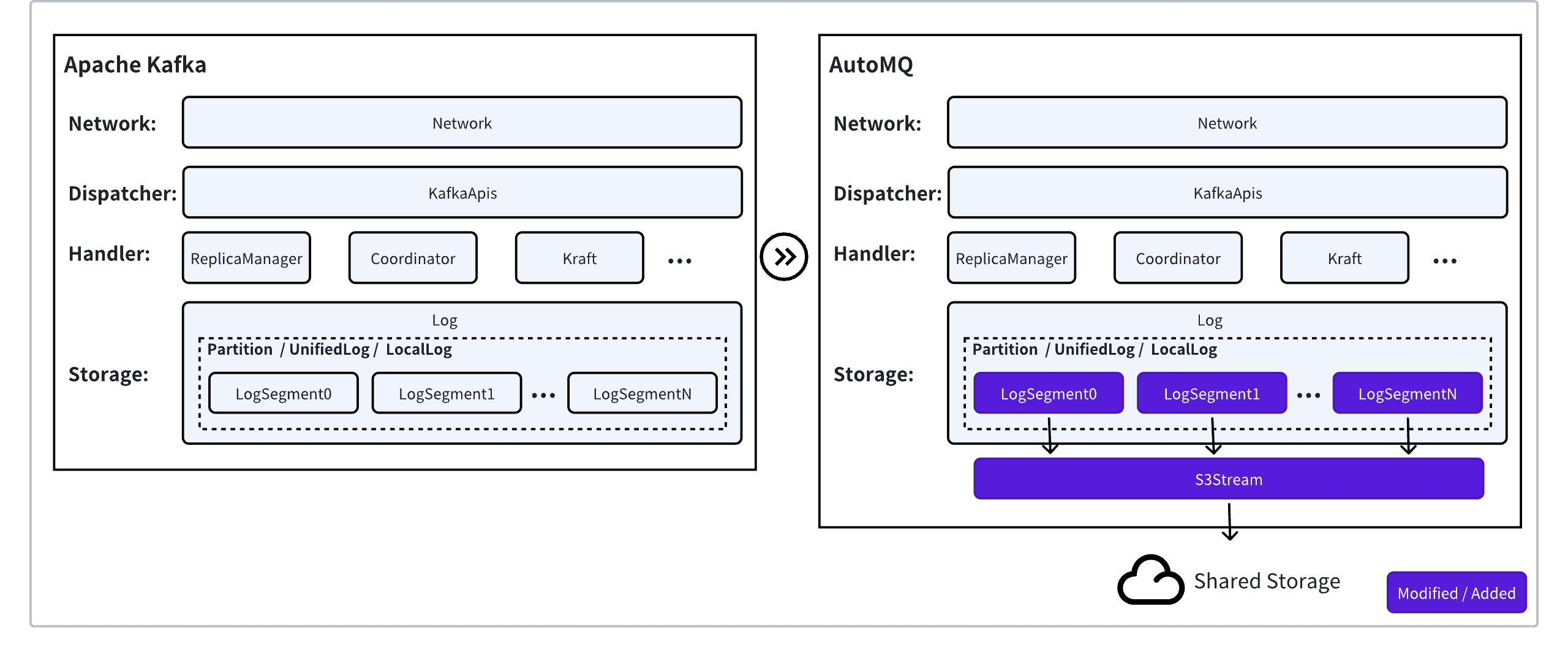 虽然 Apache Kafka 对业务逻辑层暴露的是以 Partition 为模型的流抽象,但 Kafka 内部的 Log 恢复、事务索引、时间戳索引和读取都是基于 Log Segment 来操作的。也就是说,Log Segment 是 Kafka 存储的最小操作单元。
因此 Segment 是实现 AutoMQ 存算分离架构最佳的切面,只需要基于 S3Stream 实现共享的 Segment 语义就能复用上层 LocalLog、LogCleaner 和 Partition 的逻辑,最大程度复用 Apache Kafka 的代码。
AutoMQ 除了在架构设计层面从理论上做到了原生支持 Kafka 协议外,还通过 Apache Kafka 的 500+ 的系统测试用例集(KRaft 模式)。该用例集覆盖了 Kafka 功能(消息收发、消费者管理、Topic Compaction 等)、客户端兼容性(>= 0.9 )、运维(分区迁移、滚动重启等)、Stream 和 Connector 等各个方面的测试,从实际运行层面确保了 AutoMQ 的 100% 协议和语义兼容。
[1]. Apache Kafka KIP 列表:https://cwiki.apache.org/confluence/display/kafka/kafka+improvement+proposals
虽然 Apache Kafka 对业务逻辑层暴露的是以 Partition 为模型的流抽象,但 Kafka 内部的 Log 恢复、事务索引、时间戳索引和读取都是基于 Log Segment 来操作的。也就是说,Log Segment 是 Kafka 存储的最小操作单元。
因此 Segment 是实现 AutoMQ 存算分离架构最佳的切面,只需要基于 S3Stream 实现共享的 Segment 语义就能复用上层 LocalLog、LogCleaner 和 Partition 的逻辑,最大程度复用 Apache Kafka 的代码。
AutoMQ 除了在架构设计层面从理论上做到了原生支持 Kafka 协议外,还通过 Apache Kafka 的 500+ 的系统测试用例集(KRaft 模式)。该用例集覆盖了 Kafka 功能(消息收发、消费者管理、Topic Compaction 等)、客户端兼容性(>= 0.9 )、运维(分区迁移、滚动重启等)、Stream 和 Connector 等各个方面的测试,从实际运行层面确保了 AutoMQ 的 100% 协议和语义兼容。
[1]. Apache Kafka KIP 列表:https://cwiki.apache.org/confluence/display/kafka/kafka+improvement+proposals