在一个线上 Apache Kafka 集群中,流量的波动、Topic 的创建和删除、Broker 的消亡和启动都无时无刻不在发生,而这些变化可能导致流量在集群各个节点间分布不均,从而导致资源浪费、影响业务稳定。此时则需要主动将 Topic 的不同分区在各个节点间移动,以达到平衡流量和数据的目的。
开源方案面临的挑战
Apache Kafka 一直以来在数据自平衡方面都面临了很大的挑战,社区有两种解决方案:
-
Apache Kafka 官方提供了分区迁移工具,但具体的迁移计划则需要运维人员自行决定,而对于动辄成百上千个节点规模的 Kafka 集群来说,人为监控集群状态并制定一个完善的分区迁移计划几乎是不可能完成的任务,
-
社区也有诸如 Cruise Control[1] 这类第三方外置插件用于辅助生成迁移计划。但由于 Apache Kafka 的数据自平衡过程中涉及到大量变量的决策(副本分布、Leader 流量分布、节点资源利用率等等),以及数据自平衡过程中由于数据同步带来的资源抢占和小时甚至天级的耗时,现有解决方案复杂度较高、决策时效性较低,在实际执行数据自平衡策略时,还需依赖运维人员的审查和持续监控,无法真正解决 Apache Kafka 数据自平衡带来的问题
AutoMQ 的架构优势
得益于 AutoMQ 对云原生能力的深度应用,我们将 Apache Kafka 的底层存储完全基于云的对象存储进行了重新实现,彻底从 Shared Nothing 架构升级为了 Shared Storage 架构,支持了秒级的分区迁移能力。因此,分区迁移计划的决策因素得到了极大的简化:
-
无需考虑节点的磁盘资源。
-
无需考虑分区的 Leader 分布和副本分布。
-
分区的迁移不涉及数据同步和拷贝。
故我们有机会在 AutoMQ 内部实现一个内置的、轻量化的数据自动平衡组件,持续监控集群状态,自动执行分区迁移。
AutoMQ 数据自平衡实现
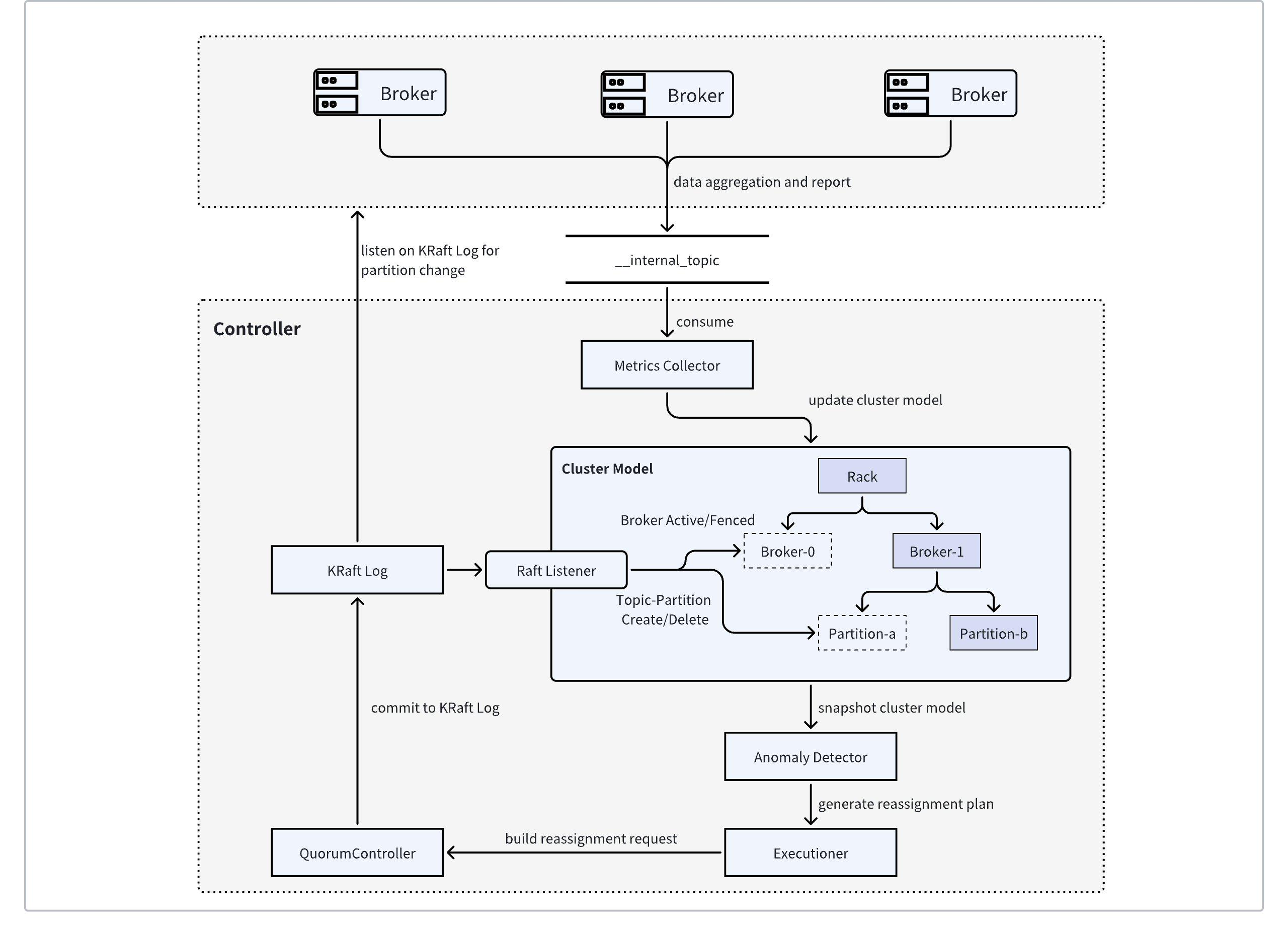 上图是 AutoMQ 内置的 Auto Balancing 组件的架构图,该架构通过收集集群的指标,自动做出分区迁移计划,持续性地平衡整个集群的流量。
AutoMQ 实现了 Apache Kafka 的 MetricsReporter 接口,监听 Apache Kafka 内置的所有指标信息,并定期对感兴趣的指标(如网络进出口流量、CPU 利用率等)进行采样,并在 Broker 侧完成指标的预聚合,将聚合后的指标序列化成一条 Kafka 消息,发送至指定的内部 Topic 中。
AutoMQ Controller 在内存中维护了一个集群状态模型用以描述当前集群状态,包括 Broker 状态、Broker 资源容量、各 Broker 管理的 Topic-Partition 流量信息等。通过监听 KRaft Log 的事件信息,集群状态模型可以及时感知到 Broker 和 Topic-Partition 的状态变更并对模型进行更新,从而与真实集群状态保持一致。
同时,AutoMQ Controller 中的指标收集器会实时从内部 Topic 中消费消息,将消息反序列化后解析成具体指标,并更新到集群状态模型,从而构建出数据自平衡所需的所有前置信息。
AutoMQ Controller 的调度决策器会周期性获取集群状态模型的快照,并根据预定义的各个“目标”,识别出流量过高或过低的 Broker, 并尝试移动或交换分区来完成流量自平衡。
上图是 AutoMQ 内置的 Auto Balancing 组件的架构图,该架构通过收集集群的指标,自动做出分区迁移计划,持续性地平衡整个集群的流量。
AutoMQ 实现了 Apache Kafka 的 MetricsReporter 接口,监听 Apache Kafka 内置的所有指标信息,并定期对感兴趣的指标(如网络进出口流量、CPU 利用率等)进行采样,并在 Broker 侧完成指标的预聚合,将聚合后的指标序列化成一条 Kafka 消息,发送至指定的内部 Topic 中。
AutoMQ Controller 在内存中维护了一个集群状态模型用以描述当前集群状态,包括 Broker 状态、Broker 资源容量、各 Broker 管理的 Topic-Partition 流量信息等。通过监听 KRaft Log 的事件信息,集群状态模型可以及时感知到 Broker 和 Topic-Partition 的状态变更并对模型进行更新,从而与真实集群状态保持一致。
同时,AutoMQ Controller 中的指标收集器会实时从内部 Topic 中消费消息,将消息反序列化后解析成具体指标,并更新到集群状态模型,从而构建出数据自平衡所需的所有前置信息。
AutoMQ Controller 的调度决策器会周期性获取集群状态模型的快照,并根据预定义的各个“目标”,识别出流量过高或过低的 Broker, 并尝试移动或交换分区来完成流量自平衡。
AutoMQ 数据自平衡示例
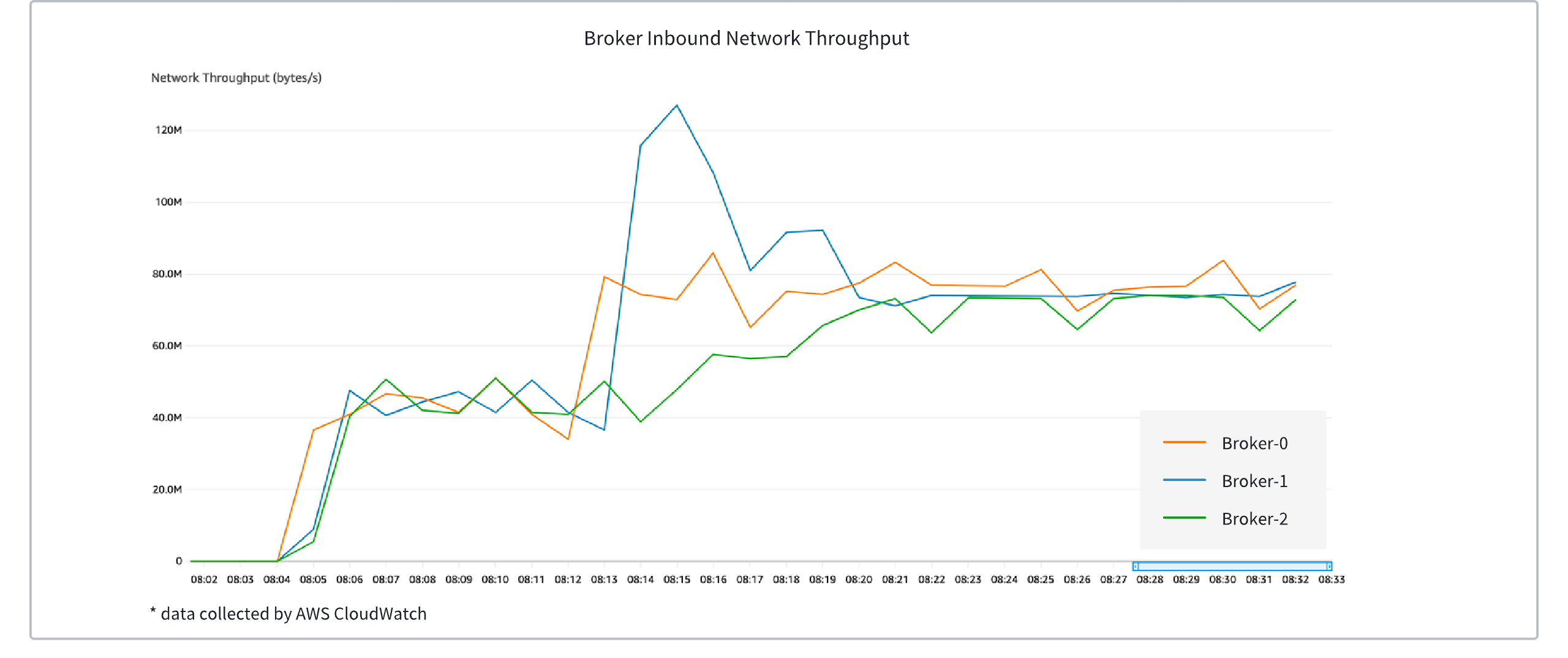 以一个三节点的 AutoMQ 集群为例,一开始为三个节点均衡地产生 40MiB/s 左右的写入流量,在第二个阶段,增加 Broker-0 流量至约 80MiB/s,Broker-1 流量至约 120MiB/s,Broker-2 保持 40MiB/s 。如上图所示,在第二阶段触发了自动负载均衡,三台 Broker 流量逐步收敛至均衡范围。
以一个三节点的 AutoMQ 集群为例,一开始为三个节点均衡地产生 40MiB/s 左右的写入流量,在第二个阶段,增加 Broker-0 流量至约 80MiB/s,Broker-1 流量至约 120MiB/s,Broker-2 保持 40MiB/s 。如上图所示,在第二阶段触发了自动负载均衡,三台 Broker 流量逐步收敛至均衡范围。
NOTE:在该场景中,为便于观测,人为增加了分区调度冷却时间,在使用默认配置的情况下,流量均衡时间约为 1 分钟左右
快速体验
参考 示例:持续数据自平衡▸ 体验 AutoMQ 的持续数据自平衡能力。
[1]. LinkedIn 开源的 Cruise Control 工具:https://github.com/linkedin/cruise-control