.png)
Kafka Architecture: Concepts and Components
Apache Kafka is a distributed event streaming platform designed for high-performance data pipelines and streaming analytics. It operates as a "distributed commit log," providing a durable record of events to build a system's state consistently. Kafka supports mission-critical use cases with guaranteed message ordering, zero message loss, and exact-once processing. Below, we delve into Kafka's architecture, exploring its key components and design principles.
Key Components of Kafka Architecture
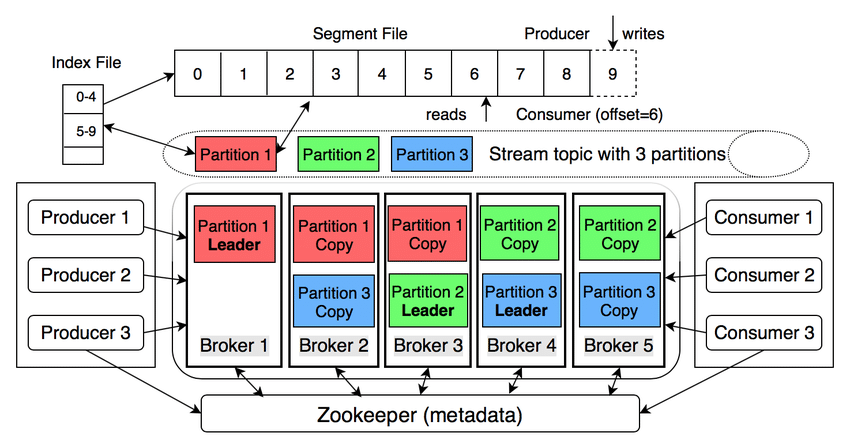
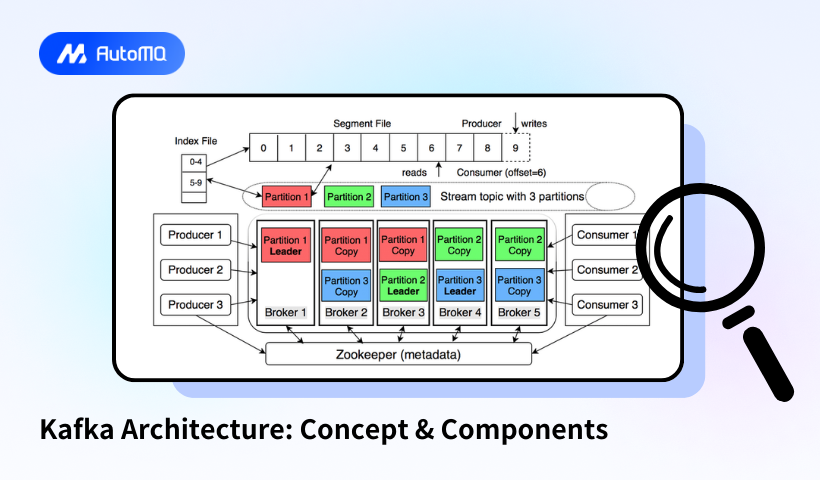
1. Broker
Description : A Kafka broker is a server that receives messages from producers, assigns offsets, and writes them to disk storage. It also services consumers by responding to fetch requests for partitions.
Role : Brokers operate in a cluster, with one broker acting as the cluster controller , responsible for administrative tasks like partition assignment and monitoring broker failures.
2. Producer
Description : Producers are client applications that publish data to Kafka topics. They use the Kafka client library to manage message serialization and transmission.
Functionality : Producers decide which partition a message should be sent to based on the message key.
3. Topic
Description : A topic is a logical grouping of events stored as an ordered sequence of messages (event log). Multiple applications can write to and read from the same topic.
Characteristics : Topics are append-only, meaning messages cannot be modified once written. They are durable and retained on disk for a configurable period.
4. Partition
Description : Topics are divided into partitions, which are append-only, ordered log files. Each partition can be hosted on a different broker, enabling parallel processing and efficient data management.
Functionality : Partitions ensure redundancy through replication. A single broker acts as the leader for a partition, while others are followers .
5. Consumer
Description : Consumers are applications that subscribe to topics and read messages in the order they were produced for each partition.
Functionality : Consumers work in groups to share processing loads. Each partition is assigned to one consumer in a group, but a consumer can read from multiple partitions.
6. Consumer Group
Description : A consumer group is a logical grouping of consumers subscribing to the same topic. This allows for horizontal scaling and fault tolerance.
Functionality : If a consumer fails, the remaining members reassign partitions to maintain processing continuity.
7. Zookeeper (Legacy) / KRaft
Description : Initially, ZooKeeper was used for coordination and configuration management, but it is being phased out in favor of Kafka's built-in KRaft consensus protocol.
Role : KRaft handles leader elections, manages metadata, and ensures data consistency directly in Kafka brokers, simplifying cluster management.
Design Principles
Distributed and Fault-Tolerant : Kafka is designed to handle large data volumes reliably across multiple nodes.
Scalability : Kafka scales horizontally by adding more brokers or partitions.
Decoupling : Producers and consumers operate independently, allowing for flexible application design.
Real-World Use Cases
User Activity Tracking : Kafka is used to track user actions like page views or searches, enabling real-time analytics.
Log Aggregation : Kafka provides a robust framework for collecting and processing log data with strong durability guarantees.
Metrics Collection : Kafka aggregates operational data from distributed systems for centralized monitoring.
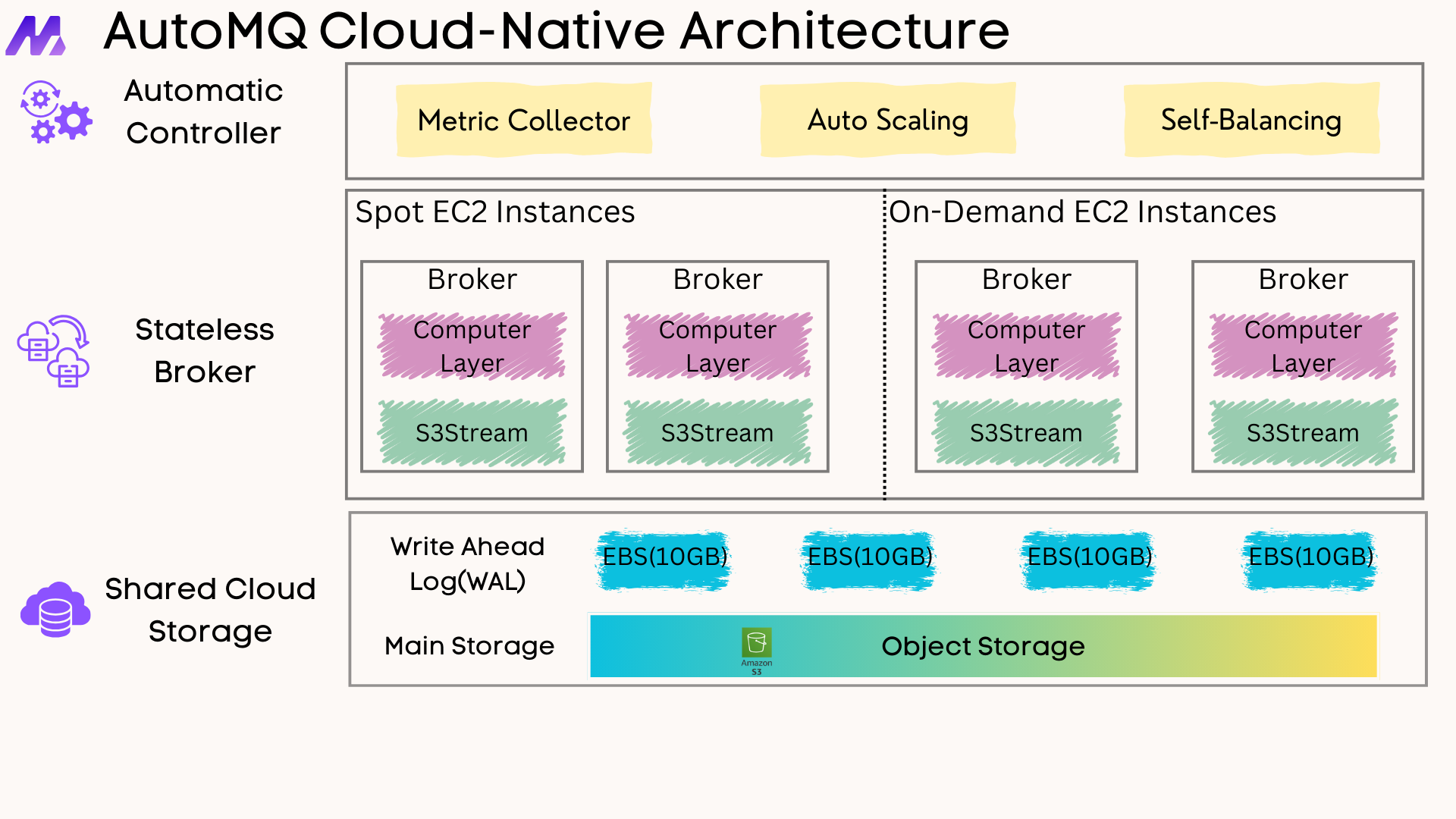
Innovations in Kafka's storage architecture
With Kafka API becoming the de facto standard in the data streaming domain, since 2020, we have witnessed the flourishing development and continuous innovation of the Kafka technology ecosystem. In the era of cloud computing, numerous innovative Kafka-based technology solutions have emerged, opening up new possibilities for data stream processing. Notably, the shared storage architecture exemplified by AutoMQ has increasingly gained industry recognition and is regarded as a key direction for the next generation of cloud-native Kafka storage architecture.
AutoMQ is a next-generation streaming data platform product that is fully compatible with the Kafka protocol, optimized specifically for cloud environments, and built on S3 object storage. AutoMQ innovatively adopts a layered architecture design that combines WAL (Write-Ahead Log) with object storage, achieving a perfect balance between high performance and high reliability. This streaming storage engine architecture fully leverages the unique advantages of different cloud storage media, significantly reducing the operational complexity and infrastructure costs of traditional Kafka clusters while ensuring data security, enabling enterprises to focus more on creating business value rather than managing infrastructure. If you are looking for a more cost-effective, easier-to-manage, and powerful Kafka alternative product for your enterprise, you can refer to this comprehensive comparison guide: Top 12 Kafka Alternative 2025 Pros & Cons
Conclusion
Kafka's architecture is built around a robust, distributed design that supports high-throughput data processing and streaming analytics. By understanding its components and principles, developers can leverage Kafka to build scalable and resilient data pipelines for a wide range of applications.