Kafka is a leading modern data streaming system in data infrastructure. Its persistence, low latency, and high throughput make it widely used in real-time data processing and analysis applications. In the AI era, vast amounts of data are required for training and real-time inference. As a key product in data streaming, Kafka has become increasingly significant. However, Kafka's architecture, designed for traditional IDC scenarios, couples computation and storage, resulting in high maintenance costs in scenarios like scaling and partition migration. This has driven the development of the data streaming ecosystem, giving rise to new streaming systems.
This article compiles and organizes nearly all data streaming solutions available in the industry as of 2026, including newcomers like AutoMQ and BufStream. It aims to provide readers with a quick and comprehensive understanding of the strengths, weaknesses, and applicable scenarios of various streaming solutions.
Comparison Overview
| Product | Apache Kafka Compatibility | Type | Latency | Open Source Code |
|---|---|---|---|---|
| Apache Kafka | Native Kafka | Streaming | Low | ✅ |
| AutoMQ | Native Kafka | Streaming | Low | ✅ |
| Confluent | Native Kafka | Streaming | Low | ❌ |
| Redpanda | Kafka Protocol | Streaming | Low | ✅ |
| Apache Pulsar | Non-Kafka | Streaming & Messaing Queue | Low | ✅ |
| Amazon MSK | Native Kafka | Streaming | Low | ❌ |
| Amazon Kinesis | Non-Kafka | Streaming | Low | ❌ |
| Aiven Kafka | Native Kafka | Streaming | Low | ❌ |
| RabbitMQ | Non-Kafka | Messaging Queue | Low | ✅ |
| BufStream | Kafka Protocol | Streaming | High | ❌ |
| NATS | Non-Kafka | Messaging Queue | Low | ✅ |
| WarpStream | Kafka Protocol | Streaming | High | ❌ |
| Cloud Pub/Sub | Non-Kafka | Messaging Queue | Low | ❌ |
What is Apache Kafka
Apache Kafka is an open-source distributed stream processing platform designed for high-throughput, low-latency real-time data streaming scenarios. It uses a publish-subscribe model and supports the construction of large-scale data pipelines. Kafka is commonly used for log aggregation, event-driven architectures, and real-time analytics. It can persist data streams while ensuring fault tolerance and scalability. Kafka addresses the bottlenecks of traditional message queues in terms of scalability and real-time processing, making it a core infrastructure for modern data pipelines and real-time applications. It is widely adopted by companies like LinkedIn, Netflix, and Uber.
Key Features:
-
High Throughput and Low Latency : Kafka can handle millions of messages per second per cluster, supporting petabyte-scale data streams. It is ideal for real-time log aggregation, monitoring, and event sourcing.
-
Durability and Fault Tolerance : Kafka persists data to disk with configurable retention policies (time-based or size-based). It employs replication to achieve automatic failover, storing multiple replicas of data across brokers to ensure high availability.
-
Horizontal Scalability : Kafka clusters can seamlessly expand by adding brokers and partitions, supporting dynamic scaling to accommodate business growth.
-
Stream Processing : Kafka includes a lightweight stream processing library, Kafka Streams, which allows for filtering, aggregation, and transformation of data in motion without relying on external computing frameworks.
-
Ecosystem Integration : Kafka integrates seamlessly with big data tools like Hadoop, Spark, and Flink, and supports multiple language clients (Java, Python, Go, etc.).
| Pros | Cons |
|---|---|
| It has an extremely rich surrounding ecosystem like connectors and tools. | Computation and storage are coupled, making independent scaling impossible. |
| High performance and low latency. | Scaling up or down is very difficult and requires careful maintenance and handling of partition migrations. |
| Comprehensive learning materials. | Architectures that rely on local storage are very expensive in the cloud. |
| The code is open-source and highly customizable. | Self-managed services present significant management challenges. |
Confluent
Confluent is an enterprise-grade stream data platform built on Apache Kafka, created by the original development team of Kafka. It aims to extend Kafka's capabilities, providing a more comprehensive data stream processing solution. Its core products, Confluent Platform and Confluent Cloud, enhance the Kafka ecosystem by integrating features like the stream processing database ksqlDB, enterprise-grade connectors, Schema Registry, and support for multi-language development. Additionally, it offers elastic scalability and hybrid cloud deployment, while strengthening security controls (such as SSL and RBAC) and ensuring exactly-once processing semantics.
Key Features
-
Kafka Enhancements and Extensions
-
Provides a high-performance distributed messaging system (Kafka) that supports high throughput and low latency data transmission. It optimizes partitioning, replication, and fault tolerance mechanisms.
-
Compatible with the Apache Kafka ecosystem while offering enterprise extension features (e.g., Control Center) to simplify cluster monitoring and management.
-
-
Schema Registry : This registry manages the versioning and compatibility of data formats, supports Avro serialization to reduce storage space and improve serialization efficiency, and ensures seamless data parsing across different systems.
-
Kafka Connect : Offers out-of-the-box connectors (e.g., JDBC, HDFS, Elasticsearch) to integrate with external systems like databases and file systems, enabling bidirectional data synchronization.
-
KSQL (Streaming SQL Engine) : Uses SQL syntax to process Kafka data streams in real-time, supporting operations like filtering, aggregation, and joins, thereby simplifying the development of stream processing applications.
-
REST Proxy : Allows message production and consumption via HTTP interface, lowering the entry barrier for non-Java clients.
-
Control Center (Enterprise Edition): Provides visual monitoring of data pipelines, connector management, performance metrics analysis, and alerting capabilities.
-
Enterprise Features
-
Security: Supports SSL encryption, RBAC permissions control, and LDAP integration.
-
High Availability: Cross-data-center replication, automatic failover, and 99.95% SLA guarantees provided by cloud providers like Alibaba Cloud.
-
| Pros | Cons |
|---|---|
| Strong brand value and a large customer base | Essentially, it is a cloud-hosted version of Apache Kafka, inheriting all the drawbacks of Kafka architecture. For example, it faces challenges in scaling and suffers from degraded performance during cold reads. |
| A highly mature and comprehensive product suite and features | The pricing is extremely, extremely expensive. Newcomers like AutoMQ and WarpStream can offer similar services at just 10% of the cost. |
| Built-in stream processing, connectors, and enterprise-grade features | Due to serving numerous clients, support for small and medium-sized customers may be impacted. |
| 100% Compatible with Apache Kafka | - |
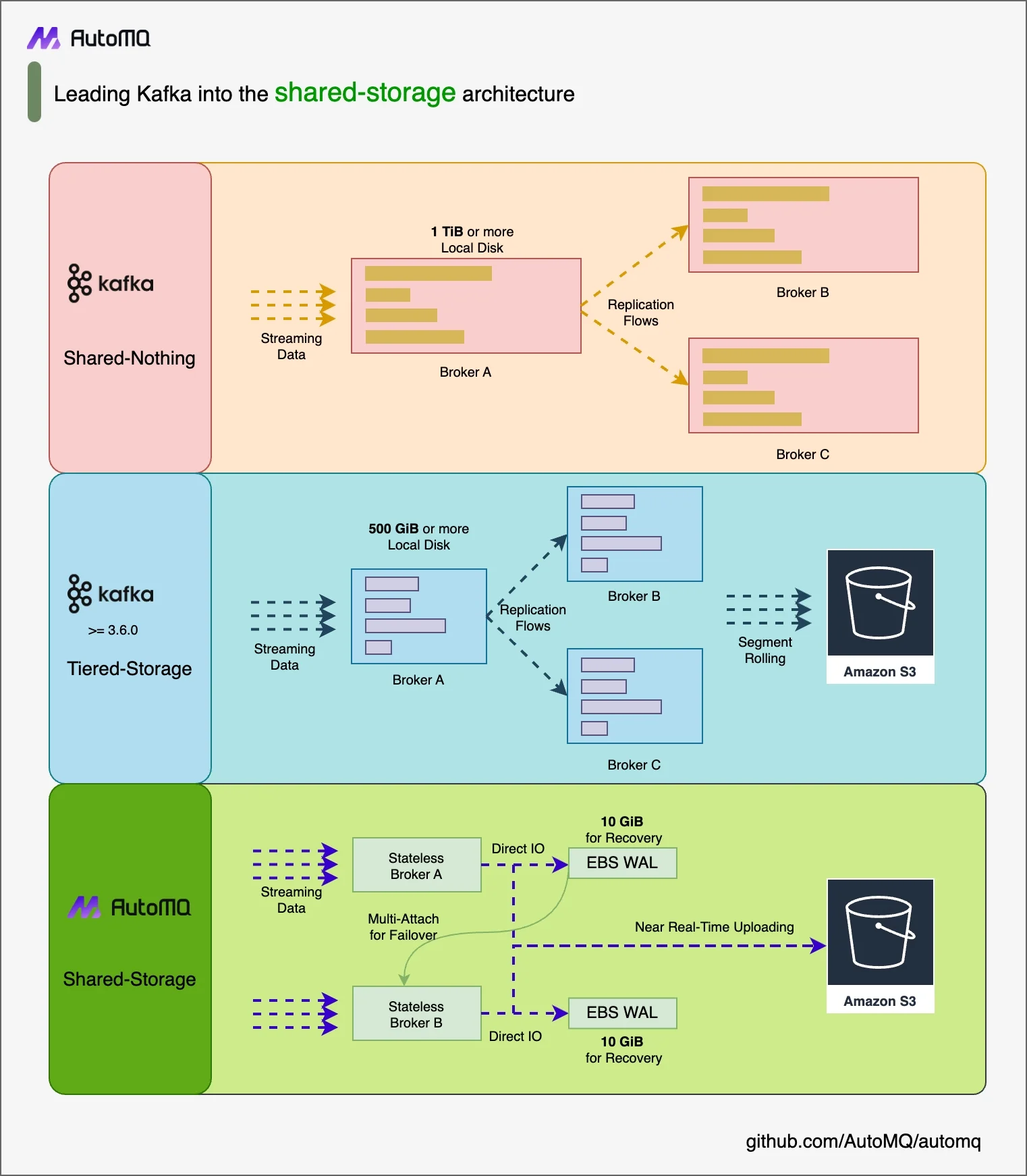
AutoMQ
AutoMQ is a next-generation Kafka built for the cloud. The source code for the community version is available on GitHub(https://github.com/AutoMQ/automq). With an innovative architecture based on S3 WAL and S3 shared storage, AutoMQ offers better cost efficiency, scalability, and performance compared to Kafka.
Key Features
-
10x More Cost-Efficient Than Kafka : AutoMQ leverages S3 object storage and innovative stream architecture to enable elastic clusters using spot instances while eliminating cross-AZ network traffic. This cloud-native approach reduces Kafka-related costs by 50-90% across workloads.
-
Instant Elastic Scaling : The stateless architecture enables cluster resizing in seconds through automated scaling operations. Unlike Kafka's manual scaling that risks service disruption, AutoMQ prevents resource over-provisioning through intelligent traffic-aware adjustments.
-
Superior Performance Profile : Maintains <10ms P99 write latency while delivering 2x Kafka's throughput on identical hardware. Its cold/hot data separation prevents page cache contamination during historical queries, achieving 5x Kafka's efficiency in cold-read scenarios.
-
Unified Stream-Table Architecture : Native integration with Apache Iceberg enables direct S3 storage of Kafka topics as analytics-ready tables. Supporting AWS's latest S3 Table feature, AutoMQ synchronizes stream/table lifecycles through managed metadata - eliminating Flink/Kafka Connect dependencies while delivering unified analytics.
| Pros | Cons |
|---|---|
| It reduces costs by 10x compared to traditional Kafka architecture. | Compared to traditional Kafka vendors like Confluent and Aiven, the brand influence is still insufficient. |
| The cluster can rapidly scale in seconds without impacting the business | - |
| It addresses a series of issues in the traditional Kafka architecture, such as complex maintenance, low efficiency of cold reads, and data hotspots. | - |
| Built-in schema registry and iceberg table support | - |
| 100% Compatible with Apache Kafka | - |
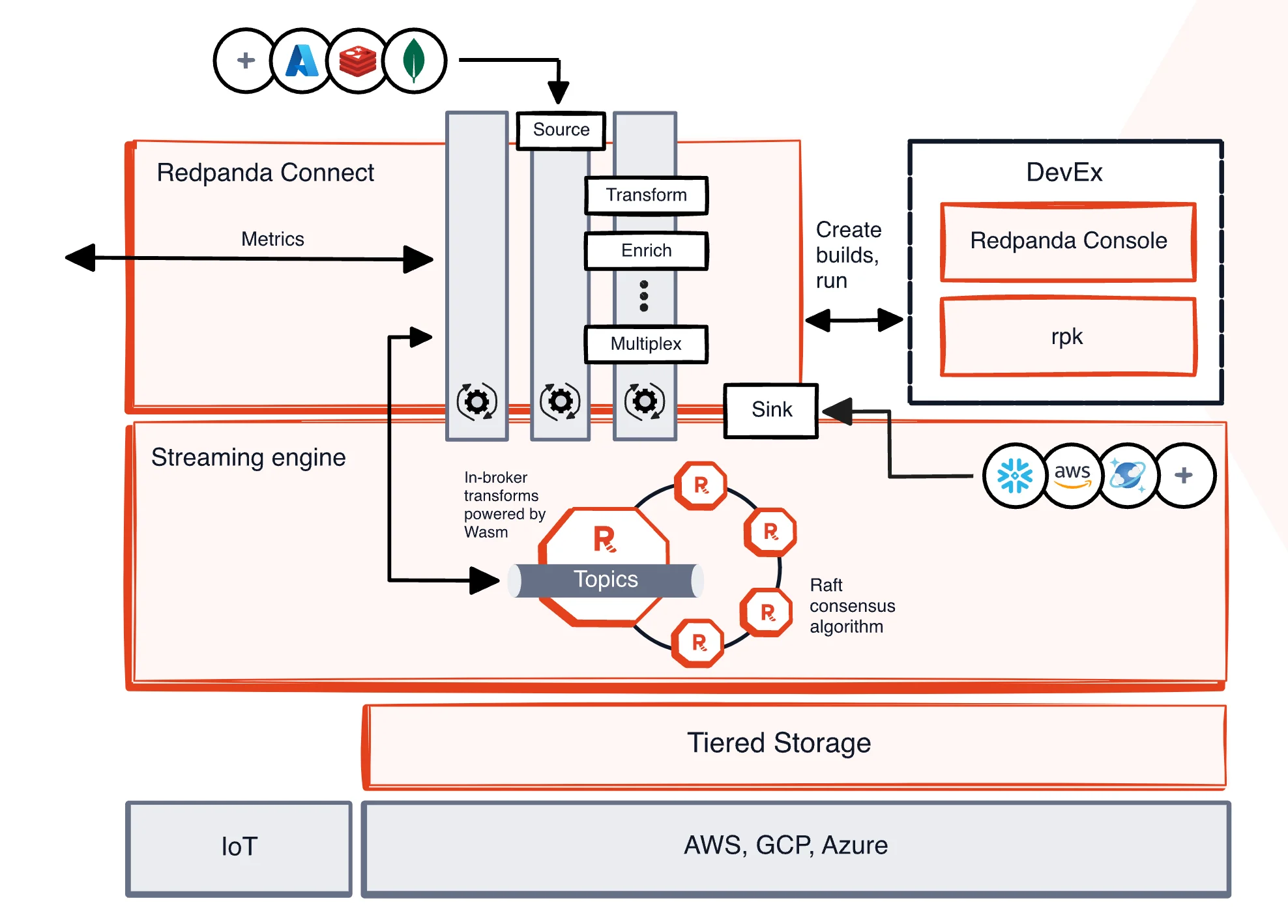
Redpanda
Redpanda is a stream data platform compatible with the Kafka API. Written in C++ and developed by Redpanda Data, it aims to achieve higher performance and simplified operations through modern architecture.
Key Features
-
Thread-Core Parallelism : Implements thread-per-core design with CPU core pinning, eliminating lock contention and context switching to enhance performance.
-
Lightweight Runtime :
-
C++ implementation removes JVM GC overhead
-
Raft consensus replaces ZooKeeper dependencies
-
Single-binary deployment simplifies operations
-
-
Predictable Resource Control :
-
Pre-allocated memory pools bypass OS page cache
-
Direct disk I/O management mirrors enterprise database strategies
-
-
Enterprise-Grade Consistency :
-
Raft-based replication groups ensure strong consistency
-
Solves Kafka's KIP-501 partition state anomalies
-
Eliminates pull-model synchronization risks
-
| Pros | Cons |
|---|---|
| Utilizing technologies like Thread-Per-Core and C++ implementation, it provides better latency performance compared to Kafka. Ideal for customers who are extremely sensitive to latency. | The Kafka API has become the de facto standard in the data streaming domain. Merely achieving protocol-level compatibility with the Kafka API poses significant challenges for Kafka users during migration. |
| - | AutoMQ and WarpStream, both leveraging cloud storage, offer significant advantages over redpanda’s tiered storage, which still depends on local disks. This dependency complicates cluster operations, scaling, and increases costs, making redpanda less efficient in dynamic cloud environments. |
Apache Pulsar
Apache Pulsar, a top-level project of the Apache Software Foundation, is positioned as a cloud-native distributed messaging and streaming platform. It integrates messaging, storage, and lightweight functional computing. Its core design employs a compute-storage separation architecture, supporting multi-tenancy, persistent storage, and cross-region data replication. Pulsar features strong consistency, high throughput (millions of messages per second), and low latency (end-to-end latency as low as 5ms).
Key Features
-
Compute-storage separation architecture : It adopts a separation design of Broker (compute layer) and BookKeeper (storage layer). The Broker is stateless and only handles message routing, while data persistence is managed by the distributed log storage system, BookKeeper. This architecture supports rapid horizontal scaling without the need for data migration during expansion, and it ensures short recovery times.
-
Multi-tenancy and flexible subscription model : It supports tenant-level resource isolation and namespace policy management, making it suitable for enterprise-level multi-team collaboration scenarios.
-
Unified model : It supports both queue and stream consumption semantics.
| Pros | Cons |
|---|---|
| The compute-storage separation architecture facilitates scalability. | You need to maintain and manage the storage layer yourself. Without official team support, operating and managing the cluster is challenging and complex. |
| Supports both queue and stream semantics. | It uses its own protocol, diverging from the mainstream Kafka ecosystem. Existing Kafka users find it difficult to migrate. Compared to native Kafka products, it carries the risk of vendor lock-in. |
| Open Source Project | Managing and maintaining the storage layer yourself is not cloud-native enough. |
Amazon MSK
Amazon MSK (Amazon Managed Streaming for Apache Kafka) is a fully managed Apache Kafka service provided by AWS. It offers a convenient UI for users to create and manage clusters, and integrates seamlessly with other AWS services.
| Pros | Cons |
|---|---|
| It integrates well with other AWS services, such as CloudWatch and MSK Connect, providing a seamless experience. | Essentially, it is a cloud-hosted version of Apache Kafka, inheriting all the drawbacks of Kafka architecture. For example, it faces challenges in scaling and suffers from degraded performance during cold reads. |
| It provides an easy-to-use UI for deploying on AWS. | Compared to solutions like WarpStream and AutoMQ built on S3, the costs are too high. |
| 100% Compatible with Apache Kafka | Vendor lock-in restricts usage to AWS only. |
Amazon Kinesis
Amazon Kinesis is a fully managed real-time data streaming service provided by AWS. It supports the real-time collection, processing, and analysis of streaming data from millions of devices or applications, such as logs, videos, and IoT sensor data. It is suitable for building low-latency streaming data pipelines and real-time analytics applications.
| Pros | Cons |
|---|---|
| Fully managed solution, no need to manage clusters yourself. | It has disadvantages in latency and throughput compared to Kafka. |
| It seamlessly integrates with other AWS services such as Data Firehose, Data Analytics, and Lambda for data analysis and applications. | It is subject to some service-level usage limits under large-scale loads. |
| - | More expensive even than MSK |
| - | Vendor lock-in restricts usage to AWS only. |
Aiven Kafka
Aiven is a comprehensive open-source service provider that focuses on delivering managed open-source products on public clouds. In addition to providing cloud-managed open-source Kafka, it also offers other managed open-source services like PostgreSQL. Aiven Kafka is somewhat similar to Amazon MSK, as both are cloud-managed Kafka services. However, compared to cloud vendors, Aiven is more actively involved in the open-source community, offering neutral, vendor-lock-in-free managed open-source services.
| Pros | Cons |
|---|---|
| Managed Open Source Kafka Solution | Essentially, it is a cloud-hosted version of Apache Kafka, inheriting all the drawbacks of Kafka architecture. For example, it faces challenges in scaling and suffers from degraded performance during cold reads. |
| Compared to open-source Kafka, it offers a user-friendly UI and some feature enhancements, such as tiered storage. | Compared to solutions like WarpStream and AutoMQ built on S3, the costs are still too high. |
| It integrates well with other open-source services on the Aiven platform. | - |
| - | - |
RabbitMQ
RabbitMQ is an open-source message-oriented middleware implemented in Erlang, utilizing the Advanced Message Queuing Protocol (AMQP). Initially developed for financial systems, it is designed to store and forward messages in distributed environments. As a low-latency message queue system, RabbitMQ is well-suited for microservice communication scenarios where lower throughput and minimal data persistence are required.
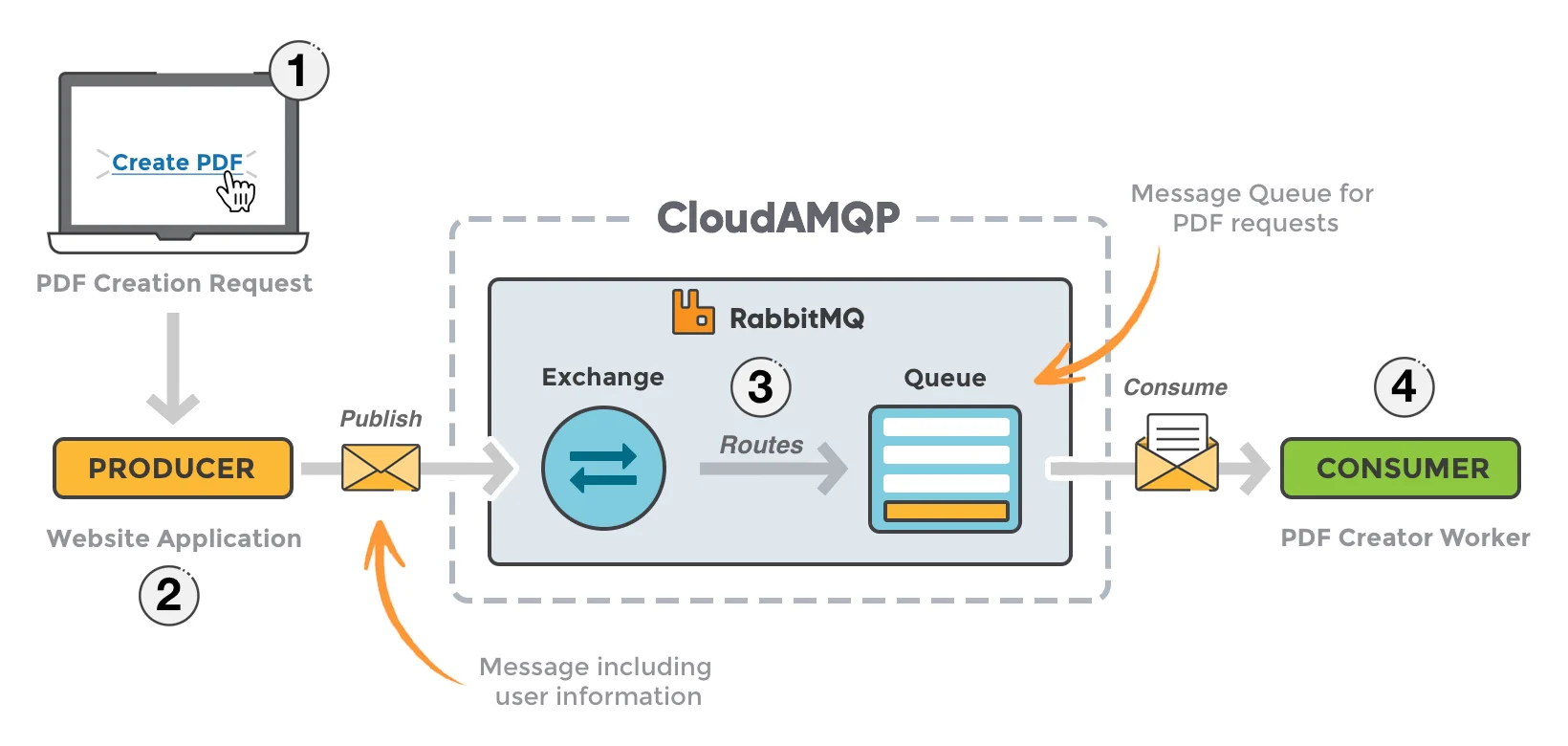
| Pros | Cons |
|---|---|
| Message-oriented middleware with a mature open-source community | The use cases for message queues are much fewer compared to streaming. |
| - | Building stable and efficient production services based on open-source software requires significant manpower and cost. |
BufStream
BufStream is a new project created by Buf Company in 2024, implemented in Golang. The core idea is to build a stream system entirely on object storage like S3, treating schema as a first-class citizen. It also provides compatibility with the Kafka API.
| Pros | Cons |
|---|---|
| Similar to WarpStream and AutoMQ, an architecture based on shared storage can significantly reduce Kafka's costs. | As a newly reimplemented project in Golang, it provides prioritized support for the Kafka API only. |
| Built-in schema registry and iceberg table support | As a new project, the product lacks some industry benchmark cases to enhance its persuasiveness. |
| - | Latency in the range of hundreds of milliseconds makes it difficult to handle some real-time stream analysis and processing scenarios. |
NATS
NATS is an open-source, lightweight, high-performance distributed messaging middleware. It achieves high scalability and an elegant publish/subscribe model and is developed in Golang. It is suitable for IoT, edge devices, and microservices scenarios but is not ideal for high-throughput environments.
| Pros | Cons |
|---|---|
| A CNCF cloud-native project. It can be seen as a lightweight version of RabbitMQ, suitable for simple publish/subscribe scenarios, such as edge devices and microservices. | Not suitable for event streaming scenarios. |
| - | Not suitable for high-throughput scenarios. |
WarpStream
A streaming system compatible with the Kafka API, fully built on S3. Written in Golang. Based on a zero-disk architecture, it offers better elasticity and cost advantages compared to Apache Kafka.
| Pros | Cons |
|---|---|
| Performs well in non-real-time streaming scenarios such as logging and offline analysis. | Offers limited compatibility with the Kafka API, which hinders the migration of existing Kafka systems. |
| - | Has significantly higher latency compared to Apache Kafka, making it unsuitable for low-latency scenarios. |
| - | After being acquired by Confluent, the prices increased, reducing cost-effectiveness. |
Cloud Pub/Sub
Pub/Sub is a fully managed messaging service provided by GCP. Compared to Apache Kafka, it has higher latency and lower throughput performance.
| Pros | Cons |
|---|---|
| Fully managed cloud service, ready to use out of the box. | Throughput and latency are not as good as Kafka. |
| Integrates well with other cloud services on GCP. | Has significantly higher latency compared to Apache Kafka, making it unsuitable for low-latency scenarios. |
| - | Much more expensive compared to other Kafka alternatives. |
Conclusion
In recent years, the rapid development and innovation within the Kafka ecosystem have been impressive. The S3 API and Kafka API have become de facto standards in the object storage and streaming domains. Against this backdrop, a series of new products like AutoMQ, Redpanda, and WarpStream have emerged. Each product has its own unique advantages and features. By evaluating these Kafka alternatives, you can find the most suitable data streaming solution that balances performance, cost, and operational complexity.


