Overview
Exactly Once Semantics (EOS) represents one of the most challenging problems in distributed messaging systems. Introduced in Apache Kafka 0.11 (released in 2017), EOS provides guarantees that each message will be processed exactly once, eliminating both data loss and duplication. This feature fundamentally changed how stream processing applications handle data reliability and consistency. The implementation of EOS in Kafka demonstrates how sophisticated distributed systems can overcome seemingly impossible theoretical constraints.
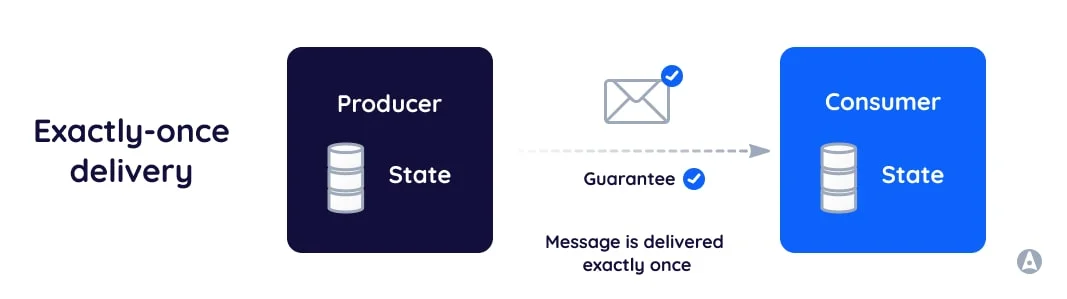
Understanding Messaging Semantics in Distributed Systems
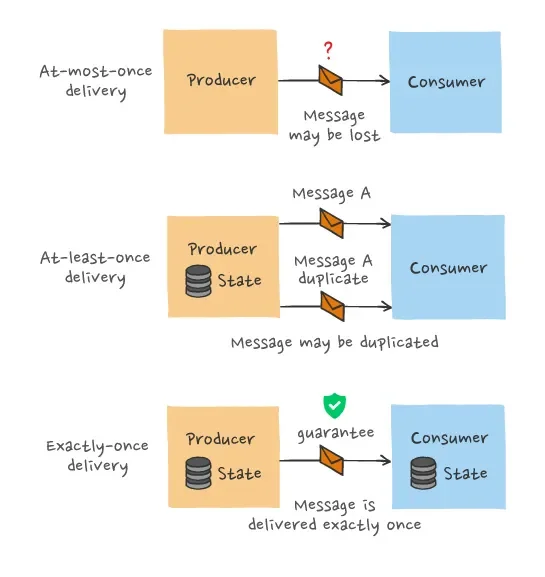
Before diving into Kafka's specific implementation, it's important to understand the spectrum of delivery guarantees in messaging systems:
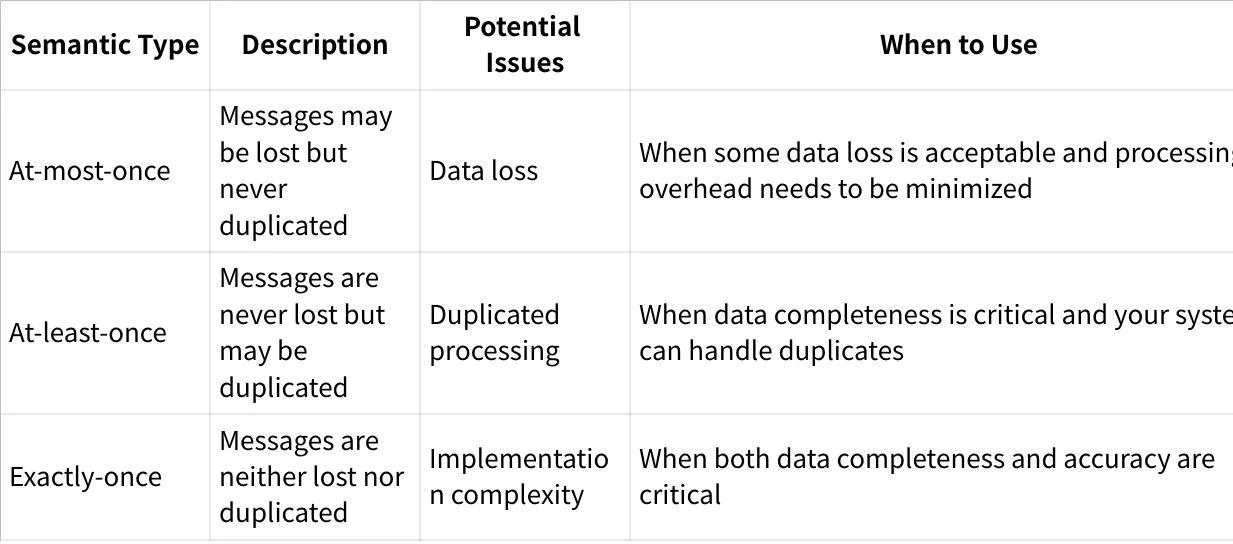
In distributed systems like Kafka, failures can occur at various points: a broker might crash, network partitions may happen, or clients could fail. These failures create significant challenges for maintaining exactly-once semantics.
As noted by experts like Mathias Verraes, the two hardest problems to solve in distributed systems are guaranteeing message order and achieving exactly-once delivery. Prior to version 0.11, Kafka only provided at-least-once semantics with ordered delivery per partition, meaning producer retries could potentially cause duplicate messages.
What Exactly-Once Semantics Really Means in Kafka
Contrary to common misunderstanding, Kafka's EOS is not just about message delivery. It's a combination of two properties:
-
Effective Once Delivery : Ensuring each message appears in the destination topic exactly once
-
Exactly Once Processing : Guaranteeing that processing a message produces deterministic state changes that occur exactly once
For stream processing, EOS means that the read-process-write operation for each record happens effectively once, preventing both missing inputs and duplicate outputs.
How Kafka Implements Exactly Once Semantics
Kafka achieves exactly-once semantics through several interconnected mechanisms:
Idempotent Producers
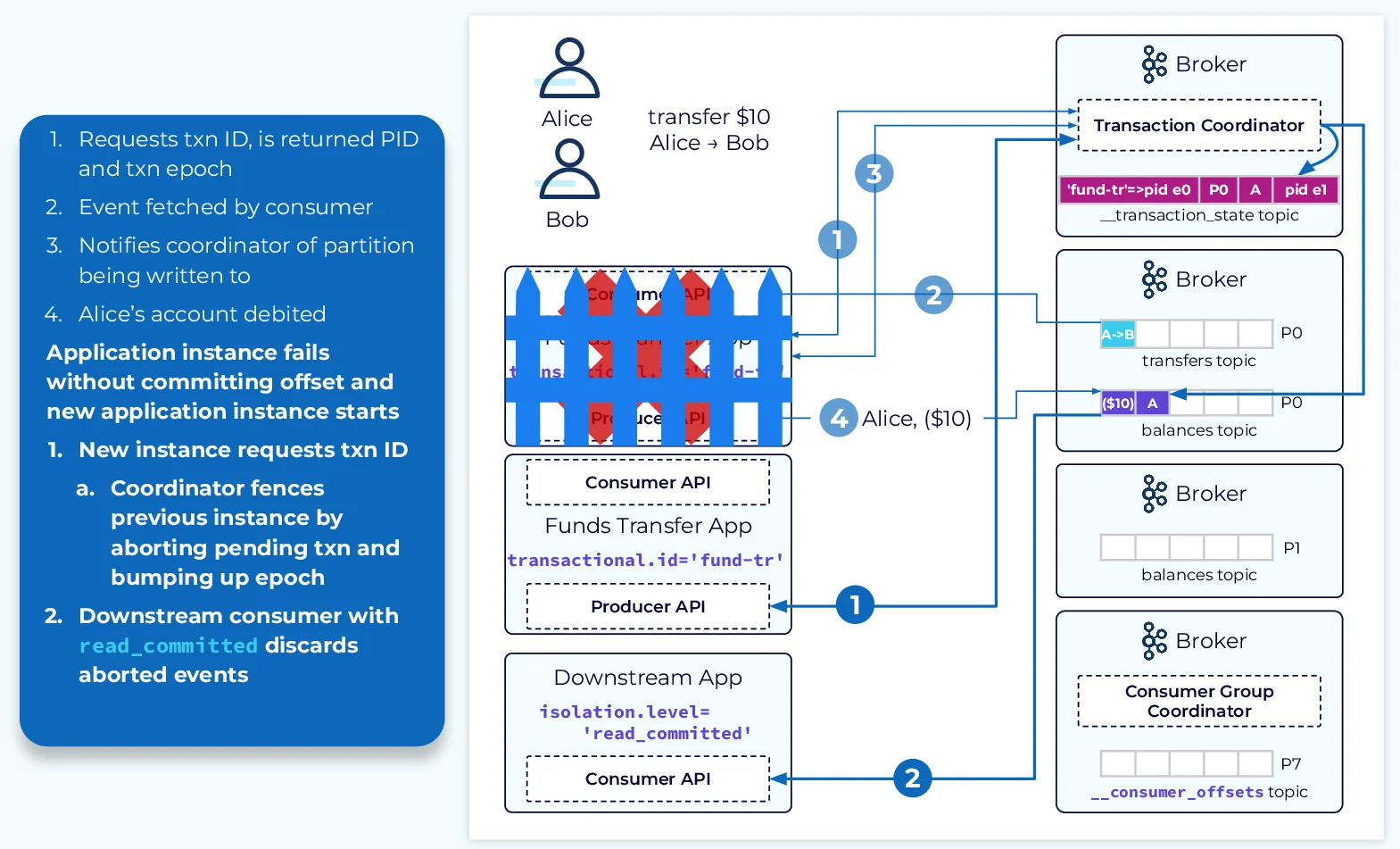
The idempotent producer is the foundation of EOS, upgrading Kafka's delivery guarantees from at-least-once to exactly-once between the producer and broker. When enabled, each producer is assigned a unique producer ID (PID), and each message is given a sequence number. The broker uses these identifiers to detect and discard duplicate messages that might be sent during retries.
Transactions
Kafka transactions allow multiple write operations across different topics and partitions to be executed atomically. This is essential for stream processing applications that read from input topics, process data, and write to output topics.
A transaction in Kafka works as follows:
-
The producer initiates a transaction using a specific API or method.
beginTransaction\() -
Messages are produced to various topics/partitions
-
The producer issues a commit or abort command
Transaction Coordinator
The transaction coordinator is a module running inside each Kafka broker that maintains transaction state. For each transactional ID, it tracks:
-
Producer ID: A unique identifier for the producer
-
Producer epoch: A monotonically increasing number that helps identify the most recent producer instance
This mechanism ensures that only one producer instance with a given transactional ID can be active at any time, enabling the "single-writer guarantee" required for exactly-once semantics.
Consumer Read Isolation
On the consumer side, Kafka provides isolation levels that control how consumers interact with transactional messages:
-
read_uncommitted: Consumers see all messages regardless of transaction status -
read_committed: Consumers only see messages from committed transactions
When configured for exactly-once semantics, consumers use the read_committed isolation level to ensure they only process data from successful transactions.
Conclusion
Kafka transactions provide robust guarantees for atomicity and exactly-once semantics in stream processing applications. By understanding their underlying concepts, configuration options, common issues, and best practices, developers can leverage Kafka's transactional capabilities effectively. While they introduce additional complexity and overhead, their benefits in ensuring data consistency make them indispensable for critical applications.
This comprehensive exploration highlights the importance of careful planning and monitoring when using Kafka transactions, ensuring that they align with application requirements and system constraints.
Still struggling with skyrocketing Kafka bills and the "ops tax" of manual disk management? It's time to stop babysitting your clusters. Try AutoMQ Cloud for Free and experience how diskless architecture slashes costs and automates scaling—no credit card required. See how others made the switch in our case studies or explore the project on GitHub.


