.png)
Overview
In January 2025, China's AI company DeepSeek released a new generation of open-source large language model, DeepSeek-R1, which created a global sensation. Its training cost is only 10% of traditional models, and its inference cost has been reduced to less than 15% of similar models. This breakthrough, known as the "DeepSeek Moment," signifies the maturity of low-cost LLM (Large Language Model) technology and heralds a shift in AI infrastructure from "resource-intensive" to "efficiency-first." This technological innovation not only lowers the barriers to AI applications but also imposes higher demands on the efficiency and cost of data processing infrastructure.
Building on DeepSeek's technological breakthrough, AutoMQ, a pioneering force in the stream processing field, has achieved a more than tenfold increase in cost efficiency using Apache Kafka through innovative technology. In an era marked by an explosion of AI data, reducing the end-to-end costs of data processing and model services through technological advancements has become a widely accepted goal in the industry. This article will explore how to integrate DeepSeek's LLM engine with AutoMQ's stream processing system to create a cost-effective AI data infrastructure.
DeepSeek's revolutionary technology
The core innovation of DeepSeek-R1 lies in its use of reinforcement learning to enhance the reasoning capabilities of large language models (LLMs) . This approach significantly reduces both training and inference costs, challenging the traditional Scaling Law.

DeepSeek-R1 trains AI models by simulating the human problem-solving process and leveraging reinforcement learning. Its core innovations include:
Simulating the Problem-Solving Process : Similar to how students solve math problems, the model gradually forms a clear problem-solving approach through continuous attempts, mistakes, and corrections.
Reinforcement Learning Mechanism : The model attempts to answer complex questions, with the system automatically checking the answers and rewarding correct processes while not rewarding incorrect ones. Through thousands of training cycles, the model adopts efficient reasoning strategies.
No Human Demonstration : In the initial training phase, the model relies entirely on self-exploration. The base model (DeepSeek-V3-Base) directly enters reinforcement learning, forming DeepSeek-R1-Zero, which exhibits strong problem-solving skills.
Expression Adjustment : To address the issue of R1-Zero's answers being difficult to understand, researchers conducted two additional guided adjustments: providing basic Q&A examples and collecting excellent problem-solving examples to retrain the model, enhancing its fluency and knowledge scope.
DeepSeek avoids stacking computational power and instead combines reinforcement learning during training, incorporating various optimization techniques to significantly reduce the training costs of large language models (LLMs).

AutoMQ's innovations for Kafka
Kafka has become a crucial component of modern AI data infrastructure. AutoMQ fully embraces the Apache Kafka ecosystem, ensuring 100% compatibility while striving to provide the best cloud-based Kafka solution for users. Like DeepSeek, AutoMQ continuously innovates with Kafka to significantly reduce the usage and maintenance costs for users. AutoMQ employs a shared storage architecture with separated computing and storage. Unlike Apache Kafka, which relies on local SSDs, AutoMQ uses EBS as WAL and stores all data in object storage like S3, creating a truly cloud-native Kafka architecture.

AutoMQ primarily reduces the usage and maintenance costs of Kafka through the following technological innovations:
AutoScaling in Seconds : AutoMQ's brokers are stateless. During cluster scaling, partition reassignment operations do not require data replication. This allows broker nodes to scale in or out within seconds. Consequently, users do not need to reserve resources based on peak throughput, significantly reducing resource cost wastage due to over-provisioning.
Maximizing Low-Cost S3 Storage : AutoMQ supports all object storage services compatible with the S3 API. By combining EBS WAL with storing all data on inexpensive object storage, Kafka's storage costs are greatly reduced without sacrificing latency.
No Cross-AZ Traffic Fees : When deploying Kafka across multiple AZs on AWS, GCP, and other clouds, cross-AZ network fees are incurred.
Self-Balancing to Enhance Cluster Utilization : AutoMQ's Self-Balancing Controller continuously monitors the cluster's state and dynamically schedules all partitions within the cluster. This prevents resource wastage due to data hotspots and uneven data distribution.
Data Processing Requirements in the AI Era
In the rapidly evolving AI landscape, the emergence of technologies like DeepSeek has significantly reduced the costs associated with training large language models (LLMs). Traditionally, building more powerful LLMs heavily relied on stacking computational power. However, the focus has now shifted towards meticulous optimization of the training processes. This paradigm shift underscores the importance of constructing low-cost, high-performance AI data infrastructures.
As the costs of AI training and inference continue to decrease, more data will be funneled into AI systems for real-time analysis. This trend necessitates robust and efficient data processing frameworks. Kafka, serving as the backbone of enterprise data streams, is poised to play a crucial role in this cost-reduction journey. By efficiently managing data flow and ensuring seamless integration with AI systems, Kafka will enable organizations to leverage real-time data analytics without incurring prohibitive costs.
In this new era, data engineers and developers must prioritize the creation of scalable, cost-effective data pipelines. Embracing tools and techniques that optimize the AI training process will be key to staying competitive and unlocking the full potential of AI-driven insights.
DeepSeek x AutoMQ: Building Modern Low-Cost AI Data Infrastructure
Kafka, as a low-latency, high-throughput stream processing system, can help enterprises effectively build Retrieval-Augmented Generation (RAG) mechanisms to improve the accuracy of large language models (LLMs). General LLMs are typically trained on public data from the internet, which allows them to handle a wide range of questions. However, they often lack the domain-specific knowledge needed to provide accurate answers in specialized contexts, sometimes leading to so-called "hallucinations." Retraining an LLM is costly, making RAG a low-cost and efficient solution.
RAG improves the quality of LLM responses in specific fields by retrieving relevant expert documents or data before generating answers. Kafka plays a crucial role in this process. It can process and transmit large volumes of data in real time, ensuring that the retrieved information is up-to-date and quickly fed back to the LLM, resulting in more accurate and reliable responses.

Specifically, Kafka can enhance RAG in the following ways:
Real-time Data Stream Processing : Kafka can handle real-time data streams from various sources, which is particularly important for retrieval systems that require the latest information. For example, in the financial sector, the timeliness of market data directly impacts the accuracy of analysis and decision-making.
High Throughput and Low Latency : Kafka's high throughput and low latency characteristics ensure that the system can respond quickly even under a large number of query requests. This is crucial for application scenarios that require frequent retrieval functions.
Data Integration and Distribution : Kafka can easily integrate various data sources and distribute processed data to different downstream systems. This flexibility allows enterprises to use RAG in multiple application scenarios, enhancing the quality of LLM responses.
By leveraging these advantages of Kafka, enterprises can build an efficient, low-cost RAG system, significantly improving the accuracy and reliability of LLMs in specific domains without retraining them. This not only saves resources but also enables the rapid deployment of higher-quality generative AI applications.
DeepSeek, as the most cost-effective LLM, combined with the equally cost-effective AutoMQ, allows us to build a low-cost, high-performance GenAI application using the following architecture. By replacing the LLM services and Kafka services in your GenAI data infrastructure with AutoMQ and DeepSeek, you can immediately achieve a low-cost, high-performance GenAI infrastructure.
This architecture leverages the strengths of both DeepSeek and AutoMQ to optimize performance and reduce costs:
DeepSeek : As a cost-effective LLM, DeepSeek provides the necessary computational power and efficiency to handle large-scale language processing tasks without the high expenses typically associated with LLMs.
AutoMQ : Serving as a more affordable alternative to Kafka, AutoMQ ensures efficient, low-latency data streaming and processing, maintaining high throughput while reducing operational costs.
By integrating DeepSeek and AutoMQ, you can streamline your GenAI data infrastructure, resulting in significant cost savings and enhanced performance. This combination allows for scalable, real-time data processing and analysis, enabling the rapid deployment of high-quality generative AI applications.

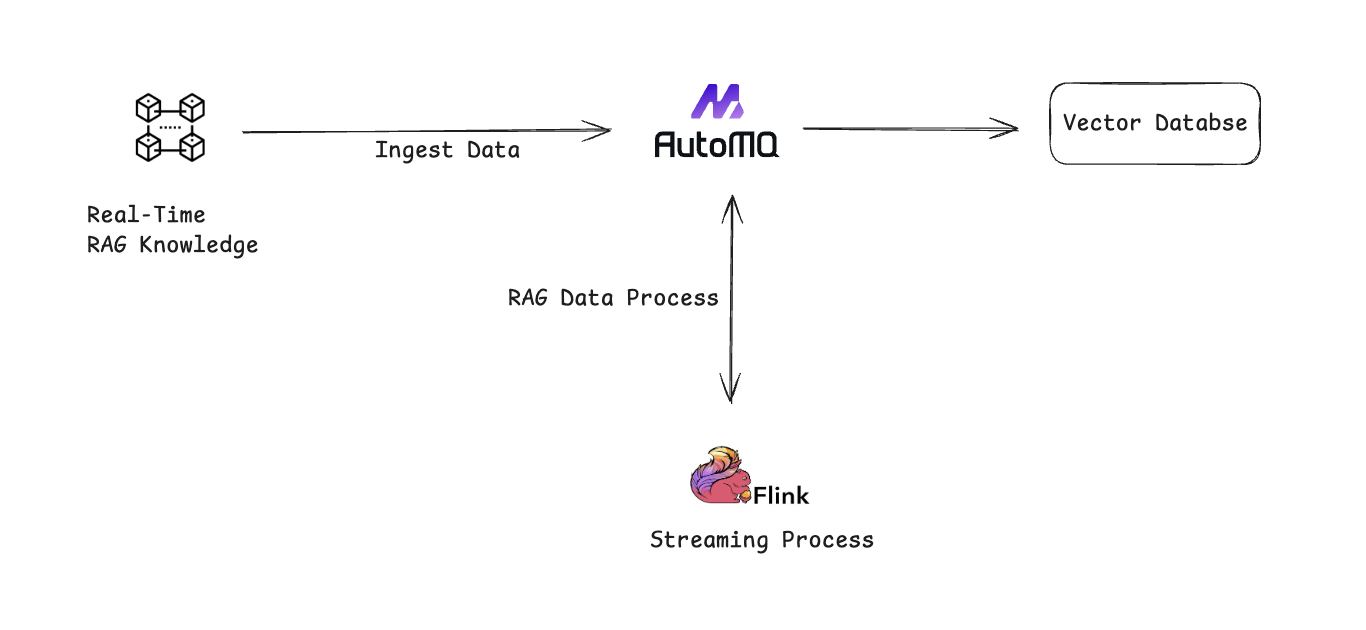
To construct more accurate and real-time RAG, you can use AutoMQ with stream processing engines like Apache Flink. This combination ingests raw data to build RAG in real-time, as shown in the diagram below. For insights on using Kafka and AI in production environments, refer to Airy's presentation at the Confluent Current .