.png)
Overview
In the world of modern data engineering, the challenge is no longer just about storing large volumes of data, but about efficiently moving it from a multitude of sources into a centralized system for analysis. Extract, Load, and Transform (ELT) has emerged as the standard paradigm for this task, giving rise to a new generation of powerful tools designed to automate and simplify data integration.
Among the leading solutions in this space are Airbyte and Hevo Data. While both aim to solve the core problem of data movement, they do so with fundamentally different philosophies, architectures, and feature sets. As a senior software engineer, I've seen firsthand how choosing the right tool can be the difference between a seamless, scalable data platform and one plagued by maintenance headaches and spiraling costs.
This blog post provides a comprehensive technical comparison of Airbyte and Hevo Data. We will move beyond marketing claims to dissect their underlying architecture, compare their core features, and outline practical use cases to help you make an informed decision for your team and your data stack.
What is Airbyte?
Airbyte is an open-source data integration platform designed for flexibility and extensibility. It entered the market with a developer-first approach, aiming to commoditize data integration by making connectors accessible to everyone. Its core identity is built around its open nature, which has fostered a large and active community [1].
Architecturally, Airbyte is built on a modular system where every component, including each connector, runs as a separate Docker container. This containerized approach allows connectors to be developed in any programming language and ensures that they operate in isolated environments, preventing a failure in one connector from affecting the entire system.
Airbyte offers two primary deployment models:
Airbyte Open-Source: A free, self-hostable version that gives teams maximum control over their infrastructure, security, and data. It can be deployed on anything from a single machine with Docker Compose to a scalable Kubernetes cluster.
Airbyte Cloud: A fully managed service that handles the infrastructure, scaling, and maintenance, allowing teams to use Airbyte's capabilities without the operational overhead. This version operates on a credit-based pricing model.
The key appeal of Airbyte is its Connector Development Kit (CDK), which standardizes the process of building new connectors. This has led to a massive, rapidly growing library of connectors for a vast array of sources and destinations, including many long-tail or niche services not supported by other platforms.
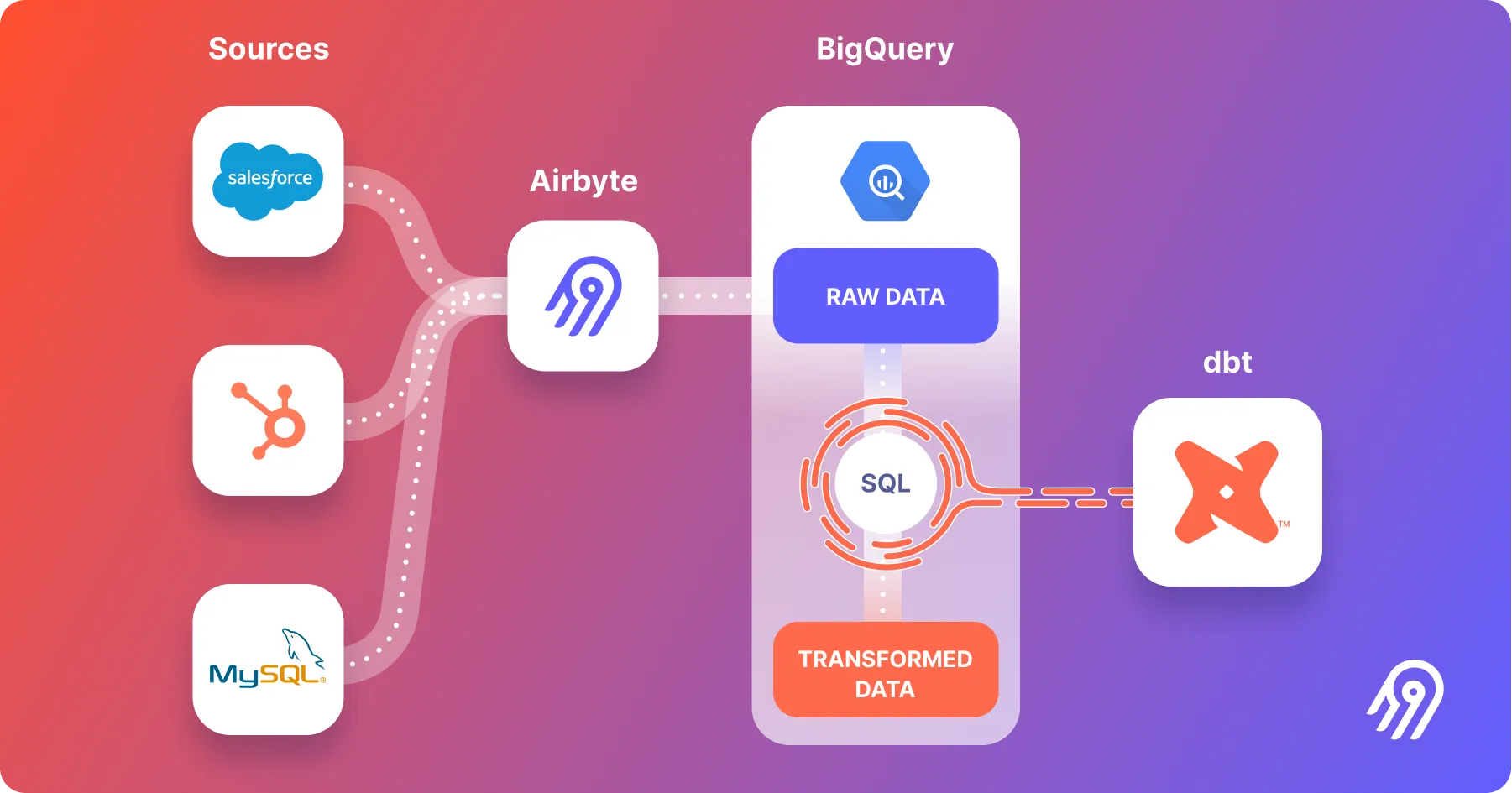
What is Hevo Data?
Hevo Data (often called Hevo) is a fully managed, no-code data pipeline platform. It is designed for ease of use and speed, targeting teams that want to set up reliable data pipelines quickly without dedicating significant engineering resources. Its platform is built to be intuitive, allowing both technical and non-technical users to move data effectively.
Under the hood, Hevo's architecture is built for real-time data movement. It uses a streaming-first approach, which enables it to capture and replicate data with very low latency. This is a key differentiator, making it well-suited for use cases that require fresh, up-to-the-minute data for operational analytics or real-time dashboards [2].
Unlike Airbyte, Hevo is a closed-source, fully managed SaaS platform. Its core value proposition is providing a "zero-maintenance" experience. Hevo handles all the complexities of pipeline management, from schema drift detection and handling to error recovery and scaling.
One of Hevo's most significant features is its support for pre-load transformations. While most ELT tools focus on loading raw data into the warehouse for later transformation (typically with a tool like dbt), Hevo allows you to clean, enrich, and structure data before it gets loaded. This can be done through an intuitive drag-and-drop interface or by writing custom Python scripts directly within the Hevo UI [3].
![Data Flow with Hevo Platform [5]](https://static-file-demo.automq.com/6809c9c3aaa66b13a5498262/68f5ebb746ec9b819bd25fe0_67480fef30f9df5f84f31d36%252F685e629da37c4346fb88cee5_npQm.png)
Feature-by-Feature Comparison
Let's break down the critical differences between these two platforms across several key areas.
Connectors: Extensibility vs. Reliability
The approach each platform takes to connectors is a primary point of divergence.
Airbyte prioritizes breadth and extensibility. With over 350 connectors, its library is one of the largest available. This is a direct result of its open-source model and CDK, which empowers the community to contribute connectors for niche APIs and databases. However, this also means the quality and maintenance level of these connectors can vary. Airbyte addresses this by categorizing connectors as "Certified" (maintained by the Airbyte team) or "Community" (maintained by contributors), so teams know what level of reliability to expect.
Hevo Data focuses on reliability and curation. It offers a smaller, more focused library of over 150 connectors [3]. Each of these connectors is built and maintained by the Hevo team, ensuring a consistent level of quality, performance, and reliability. If you need a connector that isn't on their list, the Hevo team may build it for you, but you lose the immediate ability to build it yourself that Airbyte provides.
Summary: If your primary need is to connect to a wide range of standard, popular SaaS tools and databases with guaranteed reliability, Hevo's curated approach is excellent. If you need to connect to long-tail, obscure, or internal custom-built services, Airbyte's open and extensible ecosystem is unmatched.
Transformations: Pre-Load vs. Post-Load
This is arguably the most significant architectural difference between the two platforms.
Hevo Data offers robust pre-load transformation capabilities. This allows you to perform lightweight data cleaning, filtering, masking, and enrichment before the data ever touches your data warehouse. This can be immensely valuable for a few reasons:
Compliance: You can remove or hash personally identifiable information (PII) before it is stored.
Cost Savings: By filtering out unnecessary rows or columns, you reduce the amount of data being processed and stored in your warehouse, which can lower costs.
Simplicity: It allows analysts to work with cleaner, analytics-ready data from the moment it arrives.
Airbyte adheres more strictly to the traditional ELT paradigm, where transformations happen post-load inside the data warehouse. Its primary transformation strategy revolves around a tight integration with dbt. Airbyte can trigger dbt Cloud jobs or run dbt Core projects after a data sync is complete, orchestrating the entire workflow. It does offer some very basic normalization out of the box, but it is not designed for the kind of pre-load data manipulation that Hevo excels at.
Summary: If your use case involves significant data cleaning, PII removal, or other manipulations that are best done before loading, Hevo provides a powerful and integrated solution. If your team has a strong dbt practice and prefers the flexibility of performing all transformations in the warehouse, Airbyte's approach is clean and fits perfectly into the modern data stack.
Architecture, Scalability, and Performance
Hevo Data's streaming architecture gives it a distinct advantage in real-time performance. For use cases like replicating production databases for operational analytics, Hevo can provide near-instantaneous data movement. As a fully managed platform, scalability is handled entirely by Hevo. You don't need to worry about provisioning or managing the underlying infrastructure; the platform scales automatically to handle data spikes.
Airbyte's performance and scalability are dependent on its deployment model.
In Airbyte Cloud, scalability is managed for you.
In the self-hosted open-source version, you are in complete control. You can achieve massive scale by deploying Airbyte on a Kubernetes cluster with auto-scaling workers, but this requires significant engineering expertise to set up and maintain. Its batch-based scheduling for syncs means it is generally not considered a real-time tool in the same way as Hevo, with sync frequencies typically ranging from every five minutes to once every 24 hours.
Summary: For true low-latency, real-time data replication, Hevo has the clear architectural advantage. For batch-oriented ELT jobs, both platforms perform well, but Airbyte gives you the ultimate control over the performance and cost trade-offs if you are willing to manage the infrastructure yourself.
Ease of Use and Maintenance
Hevo Data is built for simplicity and minimal maintenance. Its no-code UI is incredibly intuitive. Setting up a new pipeline is a matter of a few clicks: you authenticate your source and destination, choose your replication settings, and the data starts flowing. Schema drift is handled automatically. It is a tool that can be confidently handed over to less technical users, such as data analysts or business intelligence professionals.
Airbyte presents a mixed picture. Airbyte Cloud is also designed to be user-friendly and abstracts away most of the maintenance. However, the open-source version has a steeper learning curve. While the UI is straightforward, the initial setup, configuration, monitoring, and especially upgrading of a self-hosted instance requires dedicated engineering time. It is a powerful tool, but not a "set it and forget it" one in its open-source form.
Summary: If the primary goal is to empower non-engineers and minimize engineering overhead, Hevo is the superior choice. If your data team has the engineering capacity and wants deep control over the tool's configuration and lifecycle, the self-hosted version of Airbyte is a compelling option.
How to Choose: A Decision Framework
Choosing between Airbyte and Hevo Data comes down to your team's priorities, skills, and specific use case. Ask yourself the following questions:
How important is real-time data?
If your use case requires data latency measured in seconds or minutes (e.g., for fraud detection or real-time operational dashboards), Hevo's streaming architecture is built for this purpose. If your analytics needs are met with hourly or daily batch updates, either tool will suffice.
What is your team's technical expertise?
If you have a lean data team or want to enable business users to create their own pipelines, Hevo's no-code, fully managed platform is ideal. If you have a strong data engineering team that is comfortable with Docker, Kubernetes, and managing infrastructure, Airbyte Open-Source offers unparalleled power and control.
Do you need to connect to long-tail or custom sources?
Scour the connector lists for both platforms. If you need to pull data from a niche SaaS tool, an internal database, or a custom-built API, there is a high probability that Airbyte either has a community connector for it or gives you the tools to build one quickly.
Where do you want to handle data transformations?
If you want to clean, filter, or mask data before it enters your warehouse for security, compliance, or cost reasons, Hevo's pre-load transformation feature is a significant advantage. If you are committed to an ELT philosophy and have standardized on dbt for all transformations, Airbyte's seamless dbt integration provides a clean and powerful workflow.
What is your budget and pricing preference?
If you want to minimize direct software costs and have the engineering capacity to self-host, Airbyte Open-Source is free. For managed services, you need to compare models. Hevo's event-based pricing is often seen as more predictable. Airbyte Cloud's credit-based model can be very cost-effective, but it's worth modeling out your expected usage to avoid surprises [4].
Conclusion
Both Airbyte and Hevo Data are exceptional tools that represent the best of the modern data integration landscape. They are not direct competitors in a zero-sum game; rather, they are two different solutions for two different sets of priorities.
Hevo Data is the streamlined, fully managed, real-time data pipeline for teams that value speed, ease of use, and minimal operational overhead. It empowers a wider range of users and is purpose-built for use cases that demand fresh data.
Airbyte is the flexible, extensible, open-source powerhouse for engineering teams that demand control, customization, and a solution for the long tail of data sources. It provides the building blocks for a truly bespoke and cost-effective data integration platform.
The right choice is not the one that is objectively "better," but the one that aligns most closely with your team's culture, your technical resources, and the strategic goals of your data platform.
If you find this content helpful, you might also be interested in our product AutoMQ. AutoMQ is a cloud-native alternative to Kafka by decoupling durability to S3 and EBS. 10x Cost-Effective. No Cross-AZ Traffic Cost. Autoscale in seconds. Single-digit ms latency. AutoMQ now is source code available on github. Big Companies Worldwide are Using AutoMQ. Check the following case studies to learn more:
Grab: Driving Efficiency with AutoMQ in DataStreaming Platform
Palmpay Uses AutoMQ to Replace Kafka, Optimizing Costs by 50%+
How Asia’s Quora Zhihu uses AutoMQ to reduce Kafka cost and maintenance complexity
XPENG Motors Reduces Costs by 50%+ by Replacing Kafka with AutoMQ
Asia's GOAT, Poizon uses AutoMQ Kafka to build observability platform for massive data(30 GB/s)
AutoMQ Helps CaoCao Mobility Address Kafka Scalability During Holidays
JD.comx AutoMQ x CubeFS: A Cost-Effective Journey at Trillion-Scale Kafka Messaging